bigbird
1.0.0
No es un producto oficial de Google.
Bigbird, es un transformador basado en atención escasa que extiende modelos basados en transformadores, como Bert a secuencias mucho más largas. Además, Bigbird viene con una comprensión teórica de las capacidades de un transformador completo que el modelo disperso puede manejar.
Como consecuencia de la capacidad de manejar un contexto más largo, BigBird mejora drásticamente el rendimiento en varias tareas de PNL, como la respuesta y el resumen de preguntas.
Se pueden encontrar más detalles y comparaciones en nuestra presentación.
Si encuentra esto útil, cite nuestro papel Neurips 2020:
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
El directorio más importante es core . Hay tres archivos principales en core .
Se proporciona una demostración rápida de ajuste para la clasificación de texto en imdb.ipynb
Cree primero un proyecto y cree una instancia en una zona que tenga una cuota de la siguiente manera
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
Para la ilustración, utilizamos el nombre de instancia bigbird y Zone europe-west4-a , pero no dude en cambiarlos. Se pueden encontrar más detalles sobre la creación de la TPU de Google Cloud en documentaciones en línea.
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .Puede encontrar puntos de control previos a los petróleo y sintonizados en nuestro cubo de almacenamiento en la nube de Google.
Opcionalmente, puede descargarlos usando gsutil como
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/El cubo de almacenamiento contiene:
bigbr_base ) y grande ( bigbr_large ). Corresponde a los modelos de codificador solo Bert/Roberta. Después de la implementación original de Bert y Roberta, son transformadores con post-normalización, la norma de capa de IE está ocurriendo después de la capa de atención. Sin embargo, siguiendo a Rothe et al, podemos usarlos parcialmente en la moda del decodificador del codificador acoplando los parámetros del codificador y el decodificador, como se ilustra en BigBird/Summarization/Roberta_Base.sh Script.bigbp_large ). Nuevamente después de la implementación original de Pegasus, son transformadores con prensorales. Tienen un conjunto completo de pesos separados del codificador del codificador. También para conjuntos de datos de resumen de documentos largos, hemos convertido los puntos de control de Pegasus ( model.ckpt-0 ) para cada conjunto de datos y también proporcionamos puntos de control ajustados ( model.ckpt-300000 ) que funciona en documentos más largos.tf.SavedModel ajustado para un resumen de documentos largos que se pueden usar directamente para la predicción y la evaluación como se ilustra en el COLAB NooTebook. Para comenzar rápidamente con BigBird, uno puede comenzar ejecutando el código de experimento de clasificación en el directorio classifier . Para ejecutar el código simplemente ejecutar
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.shPara usar directamente el codificador en lugar de decir el modelo Bert, podemos usar el siguiente código.
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)Puede reemplazar fácilmente al codificador de Bert.
Alternativamente, también se puede intentar jugar con capas de Bigbird Coder
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...) Todos los banderas y la configuración se explican en core/flags.py . Aquí explicamos algunos de los parámetros de configuración importantes.
attention_type se usa para seleccionar el tipo de atención que usaríamos. Configurarlo en block_sparse ejecuta el módulo de atención BigBird.
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size se usa para definir el tamaño de los bloques, mientras que num_rand_blocks se usa para establecer el número de bloques aleatorios. El código actualmente utiliza el tamaño de la ventana de 3 bloques y 2 bloques globales. El código actual solo admite tensores estáticos.
Puntos importantes a tener en cuenta:
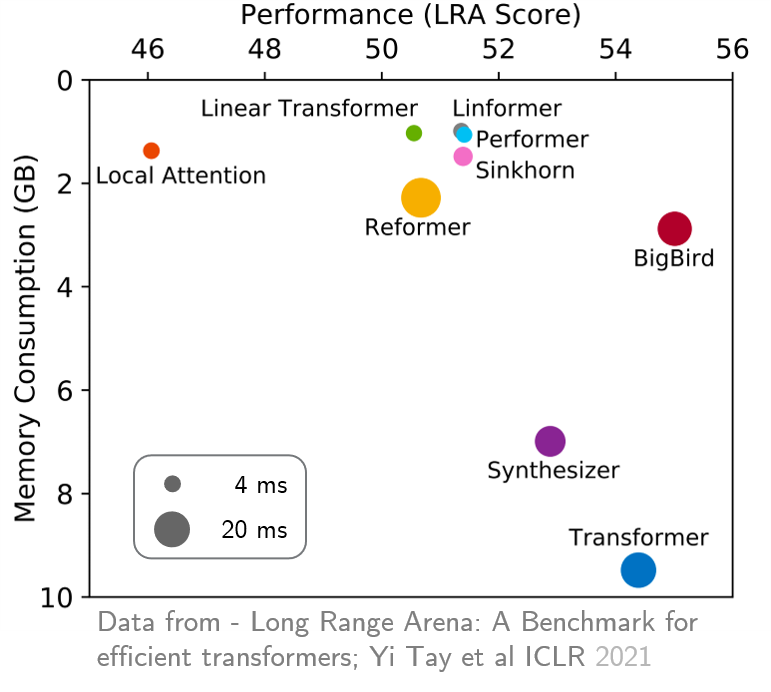
original_full , ya que no hay beneficio en el uso de la atención de bigbird disperso. Recientemente, Long Range Arena proporcionó un punto de referencia de seis tareas que requieren un contexto más largo y realizaron experimentos para comparar todos los transformadores de largo alcance existentes. Los resultados se muestran a continuación. El modelo Bigbird, a diferencia de sus contrapartes, reduce claramente el consumo de memoria sin sacrificar el rendimiento.