bigbird
1.0.0
Не официальный продукт Google.
Bigbird-это трансформатор на основе редкого внимания, который расширяет модели на основе трансформаторов, такие как BERT, до гораздо более длинных последовательностей. Более того, Bigbird сопровождается теоретическим пониманием возможностей полного трансформатора, с которым может справиться редкая модель.
В результате возможности обрабатывать более длительный контекст, Bigbird значительно повышает производительность в различных задачах NLP, таких как ответ на вопрос и суммирование.
Более подробную информацию и сравнения можно найти в нашей презентации.
Если вы найдете это полезным, пожалуйста, процитируйте наши Neurips 2020 Paper:
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
Самый важный каталог - core . В core есть три основных файла.
Быстрая демонстрация тонкой настройки для классификации текста представлена в Imdb.ipynb
Пожалуйста, сначала создайте проект и создайте экземпляр в зоне, в которой есть квота следующим образом
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
Для иллюстрации мы использовали название экземпляра bigbird и Zone europe-west4-a , но не стесняйтесь менять их. Более подробную информацию о создании Google Cloud TPU можно найти в онлайн -документациях.
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .Вы можете найти предварительные и тонкие контрольные точки в нашем ведре Google Cloud Storage.
При желании вы можете скачать их, используя gsutil в качестве
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/Ведро для хранения содержит:
bigbr_base ) и большого размера ( bigbr_large ). Это соответствует моделям Encoder только Bert/Roberta, похожих на энкодера. Следуя оригинальной реализации Bert и Roberta, они являются трансформаторами с постнормализацией, IE Layer Norm происходит после слоя внимания. Тем не менее, после Rothe et al. Мы можем частично использовать их в моде Encoder-Decoder, связывая параметры Encoder и Decoder, как показано в сценарии запуска Bigbird/Summarization/Roberta_base.sh.bigbp_large ). Снова после оригинальной реализации Pegasus они являются трансформаторами с пренормализацией. Они имеют полный набор отдельных весов энкодера-декодера. Также для наборов данных о суммировании длинных документов мы преобразовали контрольные точки Pegasus ( model.ckpt-0 ) для каждого набора данных, а также предоставили тонкие контрольные точки ( model.ckpt-300000 ), который работает на более длинных документах.tf.SavedModel для суммирования длинного документа, который можно напрямую использовать для прогнозирования и оценки, как показано в Nootebook Colab. Для быстрого начала с Bigbird можно начать с запуска кода эксперимента по классификации в каталоге classifier . Чтобы запустить код, просто выполнить
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.shЧтобы непосредственно использовать энкодер вместо того, чтобы сказать BERT Model, мы можем использовать следующий код.
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)Это может легко заменить энкодер Берта.
В качестве альтернативы, можно также попытаться играть со слоями энкодера Bigbird
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...) Все флаги и конфигурация объясняются в core/flags.py . Здесь мы объясняем некоторые из важных параметров конфигурации.
attention_type используется для выбора типа внимания, которое мы будем использовать. Установка его на block_sparse Запускает модуль внимания Bigbird.
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size используется для определения размера блоков, тогда как num_rand_blocks используется для установки количества случайных блоков. В настоящее время код использует размер окна 3 блока и 2 глобальных блока. Текущий код поддерживает только статические тензоры.
Важные моменты, чтобы отметить:
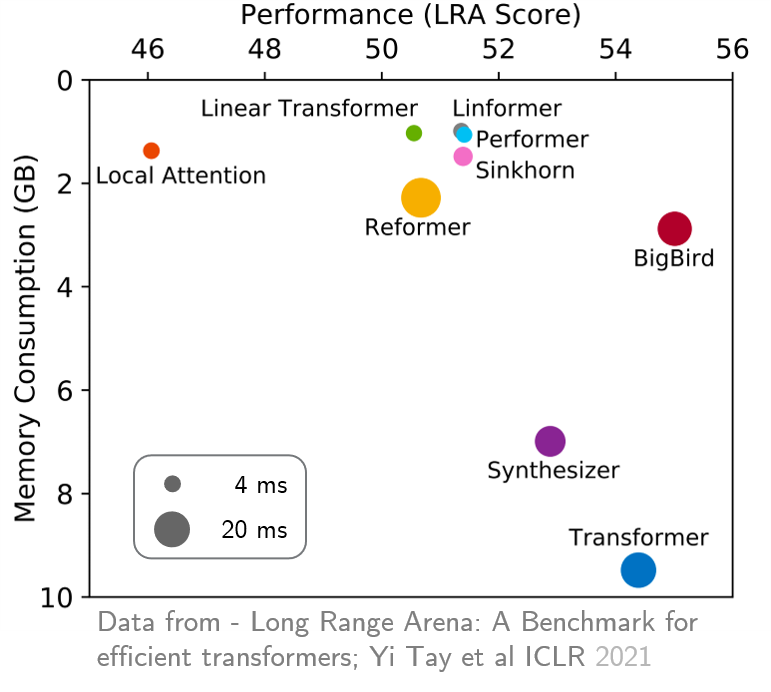
original_full , так как нет пользы в использовании редкого внимания Bigbird. Недавно Long Drange Arena предоставила эталон из шести задач, которые требуют более длительного контекста, и провели эксперименты для сравнения всех существующих трансформаторов дальнего расстояния. Результаты показаны ниже. Модель Bigbird, в отличие от его аналогов, четко снижает потребление памяти, не жертвуя производительностью.