bigbird
1.0.0
Bukan produk Google resmi.
Bigbird, adalah transformator berbasis perhatian yang jarang yang memperluas model berbasis transformator, seperti Bert ke urutan yang lebih lama. Selain itu, Bigbird hadir dengan pemahaman teoretis tentang kemampuan transformator lengkap yang dapat ditangani oleh model yang jarang.
Sebagai konsekuensi dari kemampuan untuk menangani konteks yang lebih lama, Bigbird secara drastis meningkatkan kinerja pada berbagai tugas NLP seperti menjawab pertanyaan dan ringkasan.
Rincian dan perbandingan lebih lanjut dapat ditemukan dalam presentasi kami.
Jika Anda menemukan ini berguna, silakan kutip kertas Neurips 2020 kami:
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
Direktori terpenting adalah core . Ada tiga file utama dalam core .
Demonstrasi penyempurnaan cepat untuk klasifikasi teks disediakan di IMDB.IPYNB
Harap buat proyek terlebih dahulu dan buat contoh di zona yang memiliki kuota sebagai berikut
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
Untuk ilustrasi kami menggunakan nama instance bigbird dan Zone europe-west4-a , tetapi jangan ragu untuk mengubahnya. Rincian lebih lanjut tentang membuat Google Cloud TPU dapat ditemukan dalam dokumentasi online.
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .Anda dapat menemukan pos pemeriksaan pretrained dan fine-tuned di Google Cloud Storage Bucket kami.
Secara opsional, Anda dapat mengunduhnya menggunakan gsutil sebagai
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/Bucket penyimpanan berisi:
bigbr_base ) dan ukuran besar ( bigbr_large ). Ini sesuai dengan model Encoder Bert/Roberta saja. Mengikuti implementasi Bert dan Roberta asli mereka adalah transformator dengan pasca-normalisasi, yaitu norma layer terjadi setelah lapisan perhatian. Namun, mengikuti Rothe et al, kita dapat menggunakannya sebagian dalam mode encoder-dekoder dengan menggabungkan parameter encoder dan decoder, seperti yang diilustrasikan dalam skrip peluncuran Bigbird/Summarisasi/Roberta_Base.sh.bigbp_large ). Sekali lagi mengikuti implementasi asli Pegasus, mereka adalah transformator dengan pra-normalisasi. Mereka memiliki set lengkap bobot enkoder-dekoder yang terpisah. Juga untuk dataset ringkasan dokumen yang panjang, kami telah mengonversi pos pemeriksaan Pegasus ( model.ckpt-0 ) untuk setiap dataset dan juga menyediakan pos pemeriksaan yang disesuaikan ( model.ckpt-300000 ) yang berfungsi pada dokumen yang lebih panjang.tf.SavedModel yang disempurnakan untuk peringkasan dokumen panjang yang dapat langsung digunakan untuk prediksi dan evaluasi seperti yang diilustrasikan dalam Colab Nootebook. Untuk memulai dengan cepat dengan Bigbird, orang dapat mulai dengan menjalankan kode percobaan klasifikasi di direktori classifier . Untuk menjalankan kode cukup jalankan
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.shUntuk secara langsung menggunakan encoder alih -alih mengatakan Model Bert, kita dapat menggunakan kode berikut.
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)Ini dapat dengan mudah menggantikan encoder Bert.
Atau, seseorang juga dapat mencoba bermain dengan lapisan encoder Bigbird
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...) Semua bendera dan konfigurasi dijelaskan dalam core/flags.py . Di sini kami menjelaskan beberapa paramater konfigurasi penting.
attention_type digunakan untuk memilih jenis perhatian yang akan kami gunakan. Mengaturnya ke block_sparse menjalankan modul perhatian BigBird.
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size digunakan untuk menentukan ukuran blok, sedangkan num_rand_blocks digunakan untuk mengatur jumlah blok acak. Kode saat ini menggunakan ukuran jendela 3 blok dan 2 blok global. Kode saat ini hanya mendukung tensor statis.
Poin penting untuk dicatat:
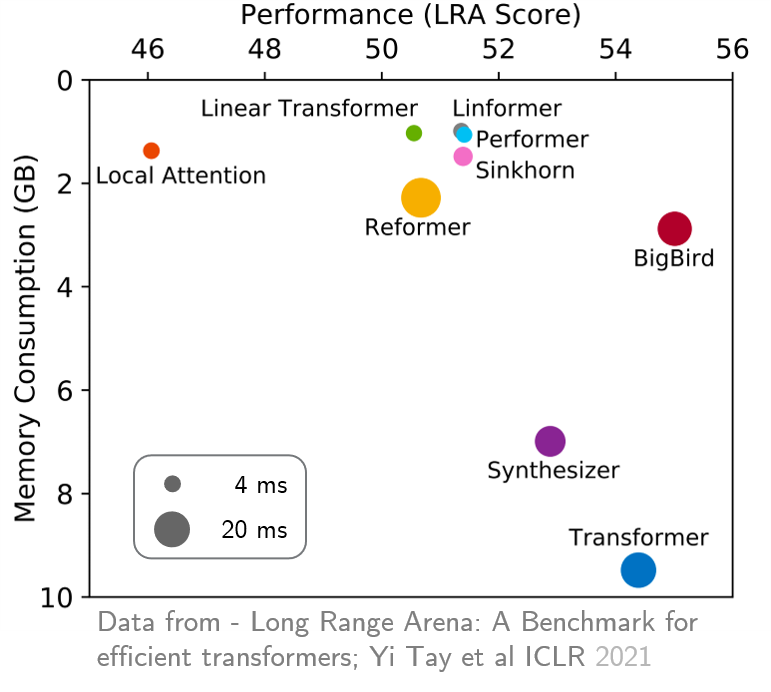
original_full disarankan karena tidak ada manfaat dalam menggunakan perhatian besar Bigbird. Baru -baru ini, Long Range Arena memberikan tolok ukur enam tugas yang membutuhkan konteks yang lebih lama, dan melakukan percobaan untuk membandingkan semua transformator jarak jauh yang ada. Hasilnya ditunjukkan di bawah ini. Model Bigbird, tidak seperti rekan -rekannya, jelas mengurangi konsumsi memori tanpa mengorbankan kinerja.