bigbird
1.0.0
Pas un produit Google officiel.
Bigbird, est un transformateur basé sur l'attention clairsemée qui étend des modèles basés sur le transformateur, tels que Bert à des séquences beaucoup plus longues. De plus, Bigbird s'accompagne d'une compréhension théorique des capacités d'un transformateur complet que le modèle clairsemé peut gérer.
En raison de la capacité de gérer le contexte plus long, Bigbird améliore considérablement les performances de diverses tâches PNL telles que la réponse aux questions et la résumé.
Plus de détails et de comparaisons peuvent être trouvés dans notre présentation.
Si vous trouvez cela utile, veuillez citer notre papier Neirips 2020:
@article{zaheer2020bigbird,
title={Big bird: Transformers for longer sequences},
author={Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
Le répertoire le plus important est core . Il y a trois fichiers principaux dans core .
Une démonstration de réglage fin rapide pour la classification du texte est fournie dans imdb.ipynb
Veuillez créer un projet d'abord et créer une instance dans une zone qui a un quota comme suit
gcloud compute instances create
bigbird
--zone=europe-west4-a
--machine-type=n1-standard-16
--boot-disk-size=50GB
--image-project=ml-images
--image-family=tf-2-3-1
--maintenance-policy TERMINATE
--restart-on-failure
--scopes=cloud-platform
gcloud compute tpus create
bigbird
--zone=europe-west4-a
--accelerator-type=v3-32
--version=2.3.1
gcloud compute ssh --zone " europe-west4-a " " bigbird "
Pour l'illustration, nous avons utilisé le nom d'instance bigbird et Zone europe-west4-a , mais n'hésitez pas à les changer. Plus de détails sur la création de Google Cloud TPU peuvent être trouvés dans les documents en ligne.
git clone https://github.com/google-research/bigbird.git
cd bigbird
pip3 install -e .Vous pouvez trouver des points de contrôle pré-entraînés et affinés dans notre godet de stockage Google Cloud.
Éventuellement, vous pouvez les télécharger à l'aide de gsutil comme
mkdir -p bigbird/ckpt
gsutil cp -r gs://bigbird-transformer/ bigbird/ckpt/Le seau de stockage contient:
bigbr_base ) et grande taille ( bigbr_large ). Il correspond aux modèles d'encodeur de type Bert / Roberta uniquement. Après la mise en œuvre originale de Bert et Roberta, ce sont des transformateurs avec post-normalisation, c'est-à-dire que la norme de couche se produit après la couche d'attention. Cependant, après Rothe et al, nous pouvons les utiliser partiellement de manière encodeur-décodeur en couplant les paramètres de codeur et de décodeur, comme illustré dans le script de lancement Bigbird / Summarization / Roberta_Base.sh.bigbp_large ). À nouveau après la mise en œuvre originale de Pegasus, ce sont des transformateurs avec pré-normalisation. Ils ont un ensemble complet de poids de coder-décodeur séparés. Également pour les ensembles de données de résumé de documents longs, nous avons converti les points de contrôle Pegasus ( model.ckpt-0 ) pour chaque ensemble de données et avons également fourni des points de contrôle affinés ( model.ckpt-300000 ) qui fonctionne sur des documents plus longs.tf.SavedModel ajusté pour un long résumé de documents qui peut être directement utilisé pour la prédiction et l'évaluation, comme illustré dans le Colab Nootebook. Pour commencer rapidement avec Bigbird, on peut commencer par exécuter le code d'expérience de classification dans le répertoire classifier . Pour exécuter le code, exécutez simplement
export GCP_PROJECT_NAME=bigbird-project # Replace by your project name
export GCP_EXP_BUCKET=gs://bigbird-transformer-training/ # Replace
sh -x bigbird/classifier/base_size.shPour utiliser directement l'encodeur au lieu de dire le modèle Bert, nous pouvons utiliser le code suivant.
from bigbird . core import modeling
bigb_encoder = modeling . BertModel (...)Il peut facilement remplacer l'encodeur de Bert.
Alternativement, on peut également essayer de jouer avec des couches de Bigbird Encodeur
from bigbird . core import encoder
only_layers = encoder . EncoderStack (...) Tous les drapeaux et la configuration sont expliqués dans core/flags.py . Ici, nous expliquons certains des paramètres de configuration importants.
attention_type est utilisé pour sélectionner le type d'attention que nous utiliserions. Le définir sur block_sparse exécute le module d'attention Bigbird.
flags . DEFINE_enum (
"attention_type" , "block_sparse" ,
[ "original_full" , "simulated_sparse" , "block_sparse" ],
"Selecting attention implementation. "
"'original_full': full attention from original bert. "
"'simulated_sparse': simulated sparse attention. "
"'block_sparse': blocked implementation of sparse attention." ) block_size est utilisé pour définir la taille des blocs, tandis que num_rand_blocks est utilisé pour définir le nombre de blocs aléatoires. Le code utilise actuellement la taille de la fenêtre de 3 blocs et 2 blocs globaux. Le code actuel ne prend en charge que les tenseurs statiques.
Points importants à noter:
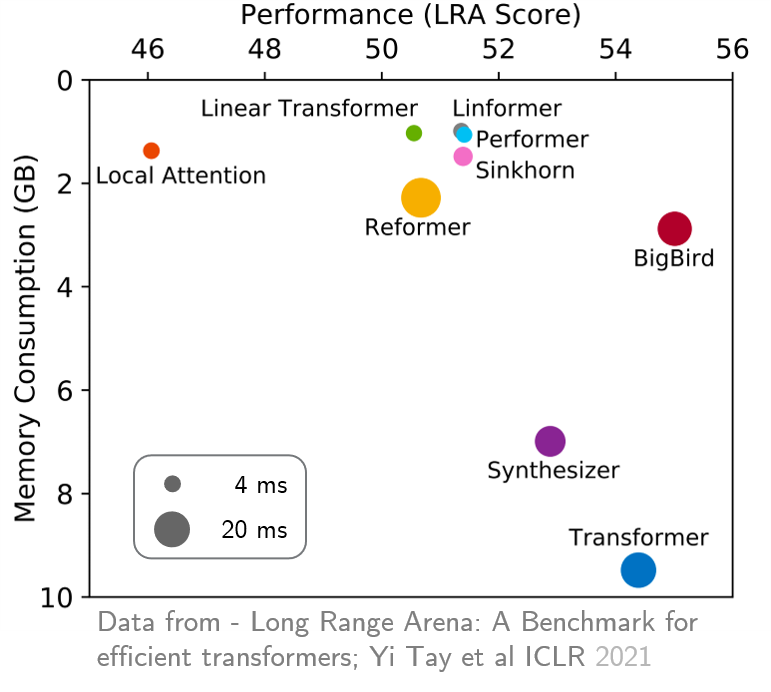
original_full est conseillé car il n'y a aucun avantage à utiliser l'attention de Bigbird clairsemée. Récemment, Arena à longue portée a fourni une référence de six tâches qui nécessitent un contexte plus long et ont effectué des expériences pour comparer tous les transformateurs à longue portée existants. Les résultats sont indiqués ci-dessous. Le modèle Bigbird, contrairement à ses homologues, réduit clairement la consommation de mémoire sans sacrifier les performances.