DensePhrases
1.1.0
入門| Lee等人,ACL 2021 | Lee等人,EMNLP 2021 |演示|參考|執照
密碼詞是一種文本檢索模型,可以為您的自然語言輸入返回短語,句子,段落或文檔。使用來自整個Wikipedia的數十億個密集的短語向量,密集詞搜索了您的問題的短語級答案或檢索下游任務的段落。
有關如何學習如何執行多粒性檢索的信息,請參閱我們的ACL論文(大規模學習短語的密集表示)。
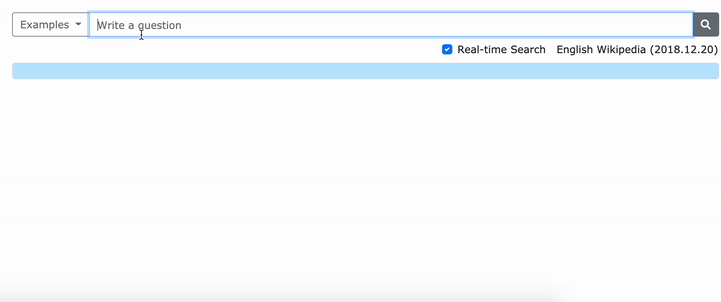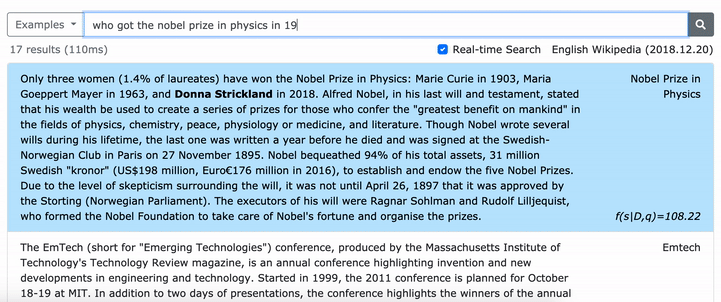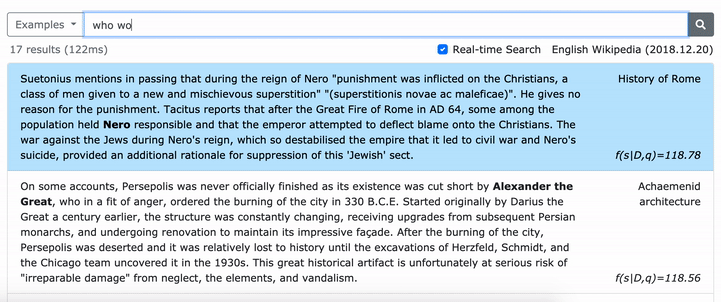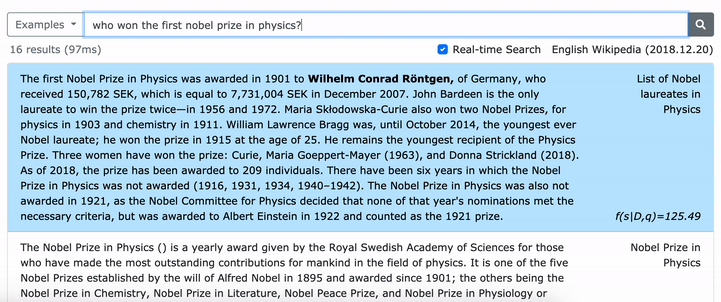
*****在這裡嘗試我們的密集詞的在線演示! *****
transformers==4.13.0釋放的密碼v1.1.0(請參閱註釋)。densephrases-multi-query-*的預測文件。在安裝密碼和下載短語索引後,您可以輕鬆地檢索查詢的短語,句子,段落或文檔。
有關更多示例,例如使用僅CPU模式,創建自定義索引等。
您還可以使用密碼詞來檢索對話的相關文檔或在給定文本上鍊接的實體。
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]我們提供了更多示例,其中包括培訓izacard and Grave的最先進的開放域問題答案模型,稱為Fusion-In-In-In-In-In-In-Decoder,2021年。
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop main分支使用python==3.7 ,而transformers==2.9.0 。參見下面的其他版本的緻密詞。
| 發布 | 筆記 | 描述 |
|---|---|---|
| V1.0.0 | 關聯 | transformers==2.9.0 ,與main相同 |
| v1.1.0 | 關聯 | transformers==4.13.0 |
在下面下載所需的文件之前,請按以下方式設置默認目錄,並確保您有足夠的存儲空間可以下載和解壓縮文件:
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh要下載下面所述的資源,您可以使用download.sh如下:
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR下下載並解壓縮,或使用download.sh 。$DATA_DIR下下載並解壓縮,或使用download.sh 。 # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump您可以使用HuggingFace Model Hub中的預訓練模型。以princeton-nlp ( load_dir中指定)開頭的任何模型名稱將自動翻譯為我們的HuggingFace Model Hub中的模型。
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| 模型 | 查詢ft。 | NQ | WebQ | trec | Triviaqa | 隊 | 描述 |
|---|---|---|---|---|---|---|---|
| 密集詞形成 | 沒有任何 | 31.9 | 25.5 | 35.7 | 44.4 | 29.3 | 在任何查詢之前。 |
| 密集詞形成 - 雜種 - 穆爾蒂 | 多種的 | 40.8 | 35.0 | 48.8 | 53.3 | 34.2 | 用於演示 |
| 模型 | 查詢ft。 &評估 | Em | 預測(測試) | 描述 |
|---|---|---|---|---|
| 密集詞 - 雜種 - Query-nq | NQ | 41.3 | 關聯 | - |
| 密集詞形成 - 雜種-WQ | WebQ | 41.5 | 關聯 | - |
| 密集詞形成 - 怪異 - 特雷克 | trec | 52.9 | 關聯 | --regex需要Regex |
| 密集詞形成 - 怪異 - Query-TQA | Triviaqa | 53.5 | 關聯 | - |
| 密集詞 - 雜種 - Query-sqd | 隊 | 34.5 | 關聯 | - |
重要的是:使用densephrases-multi數據集(Query-ft。),使用短語索引densex-multi_wiki-wiki-20181220在指定的數據集(Query-ft。)上進行了查詢側進行微調。另請注意,我們的預訓練模型是案例敏感的模型,當--truecase均可獲得任何低估的查詢(例如NQ)時,獲得了最佳結果。
densephrases-multi ):經過Mutiple Reading理解數據集(NQ,WebQ,TREC,TRIVIAQA,小隊)的培訓。densephrases-multi-query-multi :在多個開放域QA數據集(NQ,WebQ,TREC,TREC,TRIVIAQA,SEEKAD)上densephrases-multi查詢側進行微調。densephrases-multi-query-* :每個開放域QA數據集上的densephrases-multi查詢側進行了微調。有關其他任務中的預訓練模型(例如,插槽填充),請參見示例。請注意,大多數預訓練的模型是查詢側微調密集densephrases-multi的結果。
spanbert-base-cased-* )。下載並在$SAVE_DIR下下載並解壓縮或使用download.sh 。 # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )請注意,除非您想在Wikipedia量表上工作,否則您無需下載此短語索引。
$SAVE_DIR下下載並解壓縮或使用download.sh 。我們還基於更多的激烈過濾(可選)提供較小的短語索引。
這些較小的索引應放置在$SAVE_DIR/densephrases-multi_wiki-20181220/dump/start與您下載的任何其他索引一起開始。如果您僅使用較小的短語索引,並且不想下載大型索引(74GB),則需要下載元數據(20GB),並將其放在$SAVE_DIR/densephrases-multi_wiki-20181220/dump文件夾下,如下所示。文件的結構應該看起來像:
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small所有短語索引都是由同一模型( densephrases-multi )創建的,您可以將上面的所有預訓練模型與這些短語索引中的任何一個使用。要更改索引,只需在densephrases/options.py中設置index_name (或--index_name )如下:
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... )下面示出了densephrases-multi-query-nq對具有不同短語索引的自然問題(測試)的性能。
| 短語索引 | 開放域QA(EM) | 句子檢索(ACC@1/5) | 通過檢索(ACC@1/5) | 尺寸 | 描述 |
|---|---|---|---|---|---|
| 1048576_FLAT_OPQ96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60GB | 用eval-index-psg進行評估 |
| 1048576_FLAT_OPQ96_MEDIUM | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39GB | |
| 1048576_FLAT_OPQ96_SMALL | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20GB |
請注意,段落檢索準確性(ACC@1/5)通常高於論文中報告的數字,因為這些短語索引返回自然段落,而不是固定尺寸的文本塊(即100個單詞)。
您可以在自己的服務器上運行Wikipedia級演示。對於自己的演示,您可以更改短語索引(從此處獲取)或查詢編碼器(例如,變為densephrases-multi-query-nq )。
運行完整Wikipedia量表演示的資源要求是:
請注意,與以前的短語檢索模型(Denspi,denspi+sparc)不同,您不再需要SSD來運行演示。以下命令與http://localhost:51997上的演示完全相同。
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997請更改--load_dir或--dump_dir如有必要),然後刪除 - 僅CPU版本的--cuda 。設置演示後,每當出現新問題時,將自動更新$SAVE_DIR/logs/中的日誌文件。您還可以使用小批次的問題將查詢發送到服務器,以更快地推斷。
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred有關更多詳細信息(例如,更改測試集),請參閱Makefile ( q-serve , p-serve , eval-demo等)中的目標。
在本節中,我們介紹了一個逐步的過程,以訓練密碼,創建短語向量和索引,並使用訓練有素的模型進行推斷。我們這裡的所有命令都簡化為Makefile目標,其中包括精確的數據集路徑,超參數設置等。
如果以下測試運行在安裝和下載後沒有錯誤完成,那麼您就可以了!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test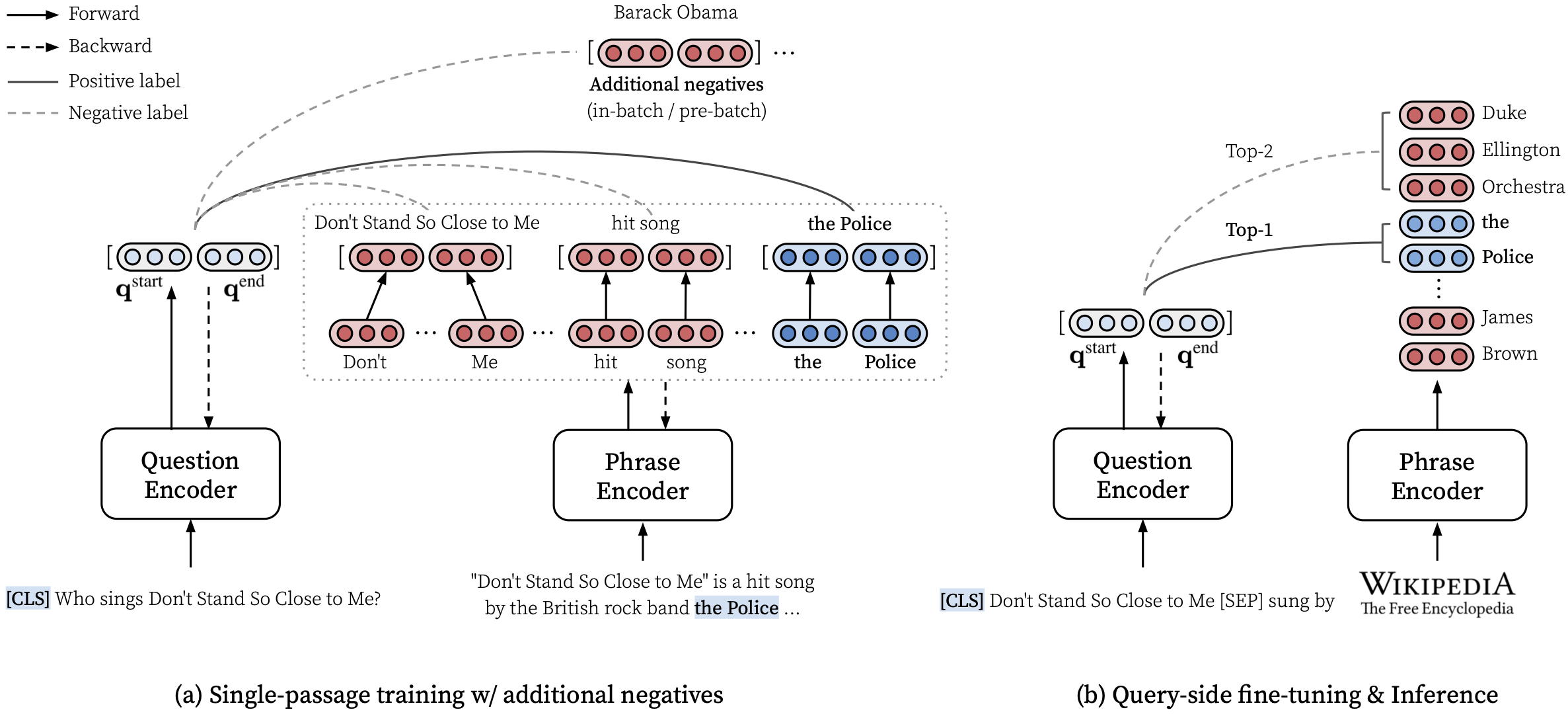
要從從頭開始訓練密集詞,請在Makefile中使用run-rc-nq ,該型號訓練NQ(預處理理解任務預處理),並在閱讀理解和(半)開放式質量固定質量質量質量質量質量質量質量檢查時對其進行評估。您可以通過修改run-rc-nq的依賴項(例如, nq-rc-data => sqd-rc-data和nq-param => sqd-param以在小隊上訓練)來更改訓練集。您需要一個24GB GPU來培訓讀取理解任務的密碼,但是可以通過設置--gradient_accumulation_steps使用較小的GPU。
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq由六個命令組成如下(如果在NQ上進行培訓):
make train-rc ... :火車密碼。 9(l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg)帶有生成的問題。make train-rc ... :負載訓練有素的密碼詞,然後用等式進一步訓練它。 9帶有批處理前的負面因素。make gen-vecs :為d_small生成短語向量(= nq dev中所有段落的集合)。make index-vecs :為d_small構建短語索引。make compress-meta :壓縮元數據以更快地推斷。make eval-index ... :在開發集問題上評估短語索引。在第2步的末尾,您將看到給出黃金通道的閱讀理解任務的性能(在NQ Dev上約為72.0 EM)。步驟6給出了半開放域設置的性能(稱為d_small;請參見表6中的表6),其中NQ開發集中的整個段落用於索引(大約為62.0 EM帶有NQ Dev問題)。訓練有素的模型將在$SAVE_DIR/$MODEL_NAME下保存。請注意,在NQ的單程培訓期間,我們在開發集中排除了一些問題,從列表或表格中找到了帶註釋的答案。
假設您有一個名為densephrases-multi的預訓練的密碼,也可以從此處下載。現在,您可以使用gen-vecs-parallel生成像Wikipedia這樣的大型語料庫的短語向量。請注意,您只需下載完整的Wikipedia量表的短語索引,然後跳過本節即可。
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8用於創建短語向量的默認文本語料庫位於$ wiki-dev $DATA_DIR/wikidump中。我們有三個大型文本語料庫的選擇:
wiki-dev :1/100 Wikipedia量表(採樣),8個文件wiki-dev-noise :1/10 Wikipedia量表(採樣),500個文件wiki-20181220 :Full Wikipedia(20181220)量表,5621文件wiki-dev* Corpora還包含NQ開發集中的段落,因此您可以以文本語料庫的尺寸增加(通常隨著較大而減小)跟踪模型的性能。短語向量將作為hdf5文件保存在$SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (例如, $SAVE_DIR/densephrases-multi_wiki-dev/dump ),將在下面引用$DUMP_DIR 。
START和END在語料庫中指定文件索引(例如, wiki-dev的START=0 END=8 , START=0 END=5621對於wiki-20181220 )。每次運行gen-vecs-parallel僅在單個GPU中消耗2GB,並且您可以使用Slurm或Shell腳本以不同的START和END分配過程(例如, START=0 END=200 , START=200 END=400 ,..., START=5400 END=5621 )。在4個24GB GPU上分發28個進程(每個處理約200個文件)可以在8小時內為wiki-20181220創建短語向量。處理整個Wikiepdia最多需要500GB,我們建議在可能的情況下使用SSD存儲(較小的語料庫可以存儲在HDD中)。
生成短語向量後,您需要為sublinear時間搜索短語創建一個短語索引。在這裡,我們將IVFOPQ用於短語索引。
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/對於wiki-dev-noise和wiki-20181220 ,您需要分別將簇數分別改為101,372和1,048,576(只需更改ìndex-vecs中的medium1-index ,將其更改為medium2-index或large-index )。對於wiki-20181220 (完整的Wikipedia),這大約需要1〜2天,具體取決於您的機器規格,需要約100GB RAM。對於本文中所述的IVFSQ,您可以使用index-add和index-merge將短語向量添加到索引中。
您還需要壓縮元數據(與短語矢量一起保存在HDF5文件中),以更快地推斷緻密源。對於IVFOPQ索引,這是必須的。
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump為了用您的短語索引評估密度詞的性能,請使用eval-index 。
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/查詢側微調使密碼詞成為用於檢索不同類型輸入查詢的多層狀文本的多功能工具。雖然查詢側的微調也可以改善QA數據集的性能,但它可用於將密集詞調整到非QA樣式輸入查詢中,例如“主題[SEP]關係”,以檢索對象實體或“我喜歡說唱音樂”。檢索有關說唱的相關文件。
首先,您需要完整的Wikipedia( wiki-20181220 )的短語索引,該索引可以在此處簡單下載,或者如下所述下載。鑑於您的查詢 - 答案或查詢文件對在$DATA_DIR/open-qa或$DATA_DIR/kilt中預處理為JSON文件,因此您可以輕鬆查詢側面微調模型。例如,T-Rex( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json )的訓練集如下:
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
T-Rex上的以下命令查詢側微型densephrases-multi 。
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/請注意,預先訓練的查詢編碼器在train-query中指定為--load_dir $(SAVE_DIR)/densephrases-multi ,新模型將作為densephrases-multi-query-trex如MODEL_NAME中的指定保存。您還可以通過將依賴項trex-open-data *-open-data (例如,用於實體鏈接的ay2-kilt-data )來訓練不同的數據集。
使用任何密度詞,查詢編碼器(例如, densephrases-multi-query-nq )和短語索引(例如, densephrases-multi_wiki-20181220 ),您可以如下測試查詢,並且檢索結果將作為JSON文件保存為JOSON文件,並具有--save_pred選項:
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997對於在不同數據集上的評估,只需相應地更改eval-index (或eval-demo )的依賴性(例如, nq-open-data to trec-open-data以進行策劃的評估)。
在Makefile的底部,我們列出了用於預處理數據集和Wikipedia的命令。對於培訓問題生成模型(T5-LARGE),我們使用了https://github.com/patil-suraj/question_generation(另請參見此處的QG)。請注意,所有數據集都已預處理,包括生成的問題,因此您無需運行大多數這些腳本。有關為自定義(開放域)問題創建測試集,請參見Makefile中的preprocess-openqa 。
有關與代碼或論文有關的任何問題,請隨時發送電子郵件發送給Jinhyuk Lee ([email protected]) 。您也可以打開GitHub問題。請嘗試指定詳細信息,以便我們更好地理解並幫助您解決問題。
如果您在工作中使用密碼,請引用我們的論文:
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}請參閱許可證以獲取詳細信息。


