DensePhrases
1.1.0
Commencer | Lee et al., ACL 2021 | Lee et al., EMNLP 2021 | Démo | Références | Licence
DensePhrases est un modèle de récupération de texte qui peut renvoyer des phrases, des phrases, des passages ou des documents pour vos entrées en langage naturel. En utilisant des milliards de vecteurs à phrases denses de l'ensemble de Wikipedia, densePhrases recherche des réponses au niveau de la phrase à vos questions en temps réel ou récupère des passages pour les tâches en aval.
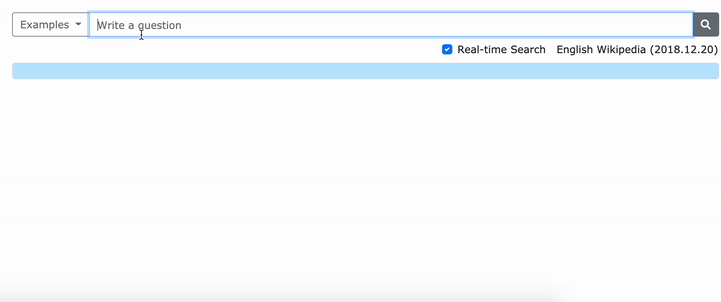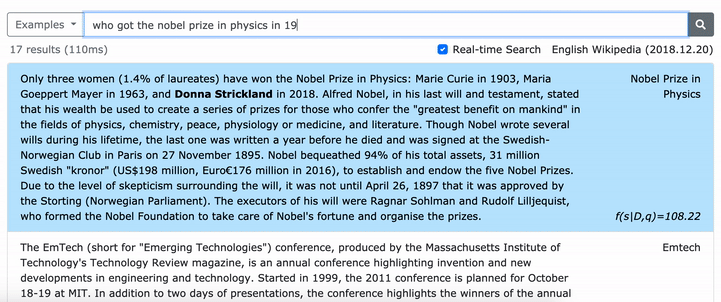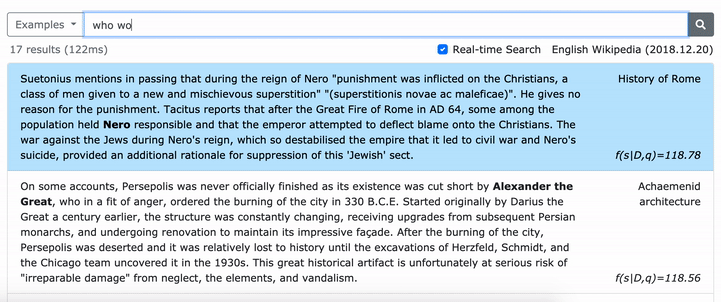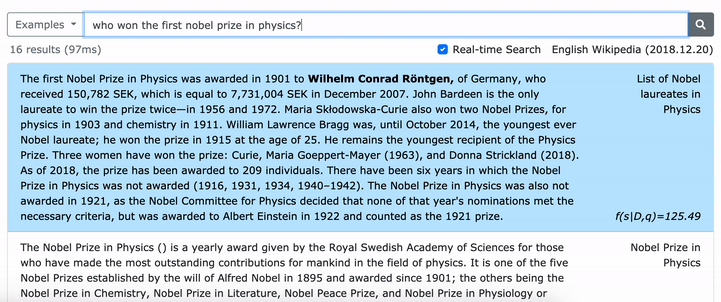
Veuillez consulter notre article ACL (apprentissage des représentations denses des phrases à grande échelle) pour plus de détails sur la façon d'apprendre des représentations denses des phrases et l'article EMNLP (la récupération des phrases apprend également la récupération de passage) sur la façon d'effectuer une récupération multi-granularité.
***** Essayez notre démo en ligne de Densephrases ici! *****
transformers==4.13.0 (voir notes).densephrases-multi-query-* ajouté.Après avoir installé des densesphrases et télécharger un index de phrase, vous pouvez facilement récupérer des phrases, des phrases, des paragraphes ou des documents pour votre requête.
Voir ici pour plus d'exemples tels que l'utilisation du mode CPU uniquement, la création d'un index personnalisé, etc.
Vous pouvez également utiliser les DensePhrases pour récupérer des documents pertinents pour un dialogue ou exécuter une entité liant les textes donnés.
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]Nous fournissons plus d'exemples, qui comprend la formation d'un modèle de réponse à la question de la question de la pointe de la technologie appelée Fusion-in-Decoder par Izacard et Grave, 2021.
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop La branche main utilise python==3.7 et transformers==2.9.0 . Voir ci-dessous pour d'autres versions de DensePhrases.
| Libérer | Note | Description |
|---|---|---|
| v1.0.0 | lien | transformers==2.9.0 , identique main |
| v1.1.0 | lien | transformers==4.13.0 |
Avant de télécharger les fichiers requis ci-dessous, veuillez définir les répertoires par défaut comme suit et assurez-vous d'avoir suffisamment de stockage pour télécharger et décompresser les fichiers:
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh Pour télécharger les ressources décrites ci-dessous, vous pouvez utiliser download.sh comme suit:
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR ou utilisez download.sh .$DATA_DIR ou utilisez download.sh . # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump Vous pouvez utiliser des modèles pré-formés à partir du Huggingface Model Hub. Tout nom de modèle qui commence par princeton-nlp (spécifié dans load_dir ) sera automatiquement traduit par un modèle dans notre hub HuggingFace.
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| Modèle | Requête-ft. | Nq | Webq | Trec | Triviaqa | Équipe | Description |
|---|---|---|---|---|---|---|---|
| densephrases-multi | Aucun | 31.9 | 25.5 | 35.7 | 44.4 | 29.3 | Em avant toute requête-ft. |
| densephrases-multi-query-multi | Multiple | 40.8 | 35.0 | 48.8 | 53.3 | 34.2 | Utilisé pour la démo |
| Modèle | Requête-ft. & Eval | Em | Prédiction (test) | Description |
|---|---|---|---|---|
| densephrases-multi-query-nq | Nq | 41.3 | lien | - |
| densephrases-multi-query-wq | Webq | 41.5 | lien | - |
| densephrases-multi-query-trec | Trec | 52.9 | lien | --regex requis |
| densephrases-multi-query-tqa | Triviaqa | 53.5 | lien | - |
| densephrases-multi-query-sqd | Équipe | 34.5 | lien | - |
IMPORTANT : Tous les modèles à l'exception densephrases-multi sont affinés côté requête sur l'ensemble de données spécifié (Query-FT.) En utilisant l'index de phrase densephrases-multi_wiki-20181220. Notez également que nos modèles pré-formés sont des modèles sensibles à la cas et que les meilleurs résultats sont obtenus lorsque --truecase est activé pour toutes les requêtes basées sur des bases (par exemple, nq).
densephrases-multi : formé sur des ensembles de données de compréhension de la lecture de mutiles (NQ, Webq, TREC, Triviaqa, Squad).densephrases-multi-query-multi : densephrases-multi -side ajusté fin sur plusieurs ensembles de données QA à domaine ouvert (nq, webq, trec, triviaqa, squad).densephrases-multi-query-* : densephrases-multi -side ajusté fin sur chaque ensemble de données QA à domaine ouvert. Pour les modèles pré-formés dans d'autres tâches (par exemple, remplissage de fentes), voir des exemples. Notez que la plupart des modèles pré-formés sont les résultats de la requête de la requête densephrases-multi .
spanbert-base-cased-* ). Téléchargez et décompressez-le sous $SAVE_DIR ou utilisez download.sh . # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )Veuillez noter que vous n'avez pas besoin de télécharger cet index de phrase, sauf si vous souhaitez travailler sur l'échelle complète de Wikipedia.
$SAVE_DIR ou utilisez download.sh .Nous fournissons également des index de phrases plus petits basés sur un filtrage plus agressif (facultatif).
Ces index plus petits doivent être placés en vertu de $SAVE_DIR/densephrases-multi_wiki-20181220/dump/start avec tous les autres index que vous avez téléchargés. Si vous n'utilisez qu'un index de phrases plus petit et que vous ne souhaitez pas télécharger le grand index (74 Go), vous devez télécharger des métadonnées (20 Go) et la placer sous $SAVE_DIR/densephrases-multi_wiki-20181220/dump Folder comme indiqué ci-dessous. La structure des fichiers doit ressembler:
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small Tous les index de phrases sont créés à partir du même modèle ( densephrases-multi ) et vous pouvez utiliser tous les modèles pré-formés ci-dessus avec l'un de ces indices de phrase. Pour modifier l'index, définissez simplement index_name (ou --index_name dans densephrases/options.py ) comme suit:
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... ) Les performances des densephrases-multi-query-nq sur les questions naturelles (test) avec différents indices de phrases sont illustrées ci-dessous.
| Index de phrase | QA à domaine ouvert (EM) | Récupération des phrases (ACC @ 1/5) | Récupération de passage (ACC @ 1/5) | Taille | Description |
|---|---|---|---|---|---|
| 1048576_flat_opq96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60 Go | évalué avec eval-index-psg |
| 1048576_flat_opq96_medium | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39 Go | |
| 1048576_flat_opq96_small | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20 Go |
Notez que la précision de récupération de passage (ACC @ 1/5) est généralement plus élevée que les nombres rapportés dans l'article, car ces index de phrase renvoient les paragraphes naturels au lieu de blocs de texte de taille fixe (c'est-à-dire 100 mots).
Vous pouvez exécuter la démo à l'échelle de Wikipedia sur votre propre serveur. Pour votre propre démo, vous pouvez modifier l'indice de phrase (obtenu à partir d'ici) ou l'encodeur de requête (par exemple, à densephrases-multi-query-nq ).
L'exigence de ressources pour exécuter la démo complète de l'échelle Wikipedia est:
Notez que vous n'avez plus besoin d'un SSD pour exécuter la démo contrairement aux modèles de récupération de phrases précédents (denspi, denspi + sparc). Les commandes suivantes servent exactement la même démo que ici sur votre http://localhost:51997 .
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997 Veuillez modifier --load_dir ou --dump_dir si nécessaire et supprimer --cuda pour la version CPU uniquement. Une fois que vous avez configuré la démo, les fichiers journaux dans $SAVE_DIR/logs/ seront automatiquement mis à jour chaque fois qu'une nouvelle question arrive. Vous pouvez également envoyer des requêtes à votre serveur à l'aide de mini-lots de questions pour une inférence plus rapide.
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred Pour plus de détails (par exemple, modification de l'ensemble de tests), veuillez consulter les cibles dans Makefile ( q-serve , p-serve , eval-demo , etc.).
Dans cette section, nous introduisons une procédure étape par étape pour former desphrases dense, créons des vecteurs et des index de phrase et exécutons les inférences avec le modèle formé. Toutes nos commandes ici sont simplifiées en tant que cibles Makefile , qui incluent des chemins de données exacts, des paramètres d'hyperparamètre, etc.
Si le test suivant se termine sans erreur après l'installation et le téléchargement, vous êtes prêt à partir!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test
Pour entraîner desphrases à partir de zéro, utilisez run-rc-nq dans Makefile , qui forme desphrases dense sur NQ (prétraitée pour la tâche de compréhension de la lecture) et l'évaluez sur la compréhension de la lecture ainsi que sur (semi) Domain Open Domain. Vous pouvez simplement modifier l'ensemble de formation en modifiant les dépendances de run-rc-nq (par exemple, nq-rc-data => sqd-rc-data et nq-param => sqd-param pour une formation sur l'escouade). Vous aurez besoin d'un seul GPU de 24 Go pour la formation de DensePhrases sur les tâches de compréhension en lecture, mais vous pouvez utiliser correctement les GPU en réglage --gradient_accumulation_steps .
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq est composé des six commandes comme suit (en cas de formation sur NQ):
make train-rc ... : Train Densephrases sur nq avec l'équation. 9 (l = lambda1 l_single + lambda2 l_Distill + lambda3 l_neg) avec des questions générées.make train-rc ... : Chargez des denses dense des étapes précédentes et entraînez-la avec Eq. 9 avec des négatifs avant lots.make gen-vecs : générer des vecteurs de phrase pour d_small (= ensemble de tous les passages dans nq dev).make index-vecs : Créez un index de phrase pour D_SMALL.make compress-meta : Compresse les métadonnées pour une inférence plus rapide.make eval-index ... : Évaluez l'index de phrase sur les questions de jeu de développement. À la fin de l'étape 2, vous verrez les performances sur la tâche de compréhension de la lecture où un passage d'or est donné (environ 72,0 EM sur nq dev). L'étape 6 donne les performances sur le réglage du domaine semi-ouvert (désigné d_small; voir le tableau 6 dans le document) où les passages entiers de l'ensemble de développement NQ sont utilisés pour l'indexation (environ 62,0 EM avec des questions de développement NQ). Le modèle qualifié sera économisé sous $SAVE_DIR/$MODEL_NAME . Notez que lors de la formation à un seul passage sur NQ, nous excluons certaines questions dans l'ensemble de développement, dont les réponses annotées se trouvent à partir d'une liste ou d'une table.
Supposons que vous disposez de Densephrases pré-formées nommées densephrases-multi , qui peuvent également être téléchargées à partir d'ici. Maintenant, vous pouvez générer des vecteurs de phrase pour un corpus à grande échelle comme Wikipedia en utilisant gen-vecs-parallel . Notez que vous pouvez simplement télécharger l'index de phrase pour l'échelle complète de Wikipedia et ignorer cette section.
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8 Le corpus de texte par défaut pour créer des vecteurs de phrase est wiki-dev situé dans $DATA_DIR/wikidump . Nous avons trois options pour les plus grands corpus de texte:
wiki-dev : Échelle Wikipedia 1/100 (échantillonnée), 8 fichierswiki-dev-noise : Échelle Wikipedia 1/10 (échantillonnée), 500 fichierswiki-20181220 : échelle complète de Wikipedia (20181220), 5621 fichiers Les corpus wiki-dev* contiennent également des passages de l'ensemble de développement NQ, afin que vous puissiez suivre les performances de votre modèle avec une taille croissante du corpus de texte (diminue généralement à mesure qu'il augmente). Les vecteurs de phrase seront enregistrés sous forme de fichiers HDF5 dans $SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (par exemple, $SAVE_DIR/densephrases-multi_wiki-dev/dump ), qui sera référé à $DUMP_DIR ci-dessous.
START et END Spécifiez l'index de fichier dans le corpus (par exemple, START=0 END=8 pour wiki-dev et START=0 END=5621 pour wiki-20181220 ). Chaque exécution de gen-vecs-parallel ne consomme que 2 Go dans un seul GPU, et vous pouvez distribuer les processus avec START et END différents en utilisant Slurm ou Shell Script (par exemple, START=0 END=200 , START=200 END=400 , ..., START=5400 END=5621 ). La distribution de 28 processus sur 4 GPU de 24 Go (chaque traitement environ 200 fichiers) peut créer des vecteurs de phrase pour wiki-20181220 en 8 heures. Le traitement de l'intégralité de Wikiepdia nécessite jusqu'à 500 Go et nous vous recommandons d'utiliser un SSD pour les stocker si possible (un corpus plus petit peut être stocké dans un disque dur).
Après avoir généré les vecteurs de phrase, vous devez créer un index de phrase pour la recherche de temps sous-linéaire des phrases. Ici, nous utilisons IVFOPQ pour l'index de phrase.
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ Pour wiki-dev-noise et wiki-20181220 , vous devez modifier le nombre de clusters à 101 372 et 1 048 576, respectivement (changez simplement medium1-index dans ìndex-vecs à medium2-index ou large-index ). Pour wiki-20181220 (Wikipedia complet), cela prend environ 1 à 2 jours en fonction de la spécification de votre machine et nécessite environ 100 Go de RAM. Pour l'IVFSQ comme décrit dans l'article, vous pouvez utiliser index-add et index-merge pour distribuer l'ajout de vecteurs de phrase à l'index.
Vous devez également compresser les métadonnées (enregistrées dans les fichiers HDF5 avec des vecteurs de phrase) pour une inférence plus rapide des densephrases. Ceci est obligatoire pour l'indice IVFOPQ.
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump Pour évaluer les performances de DensePhrases avec vos index de phrase, utilisez eval-index .
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/Le réglage fin de la requête fait de DensePhrases un outil polyvalent pour récupérer le texte multi-granularité pour différents types de requêtes d'entrée. Bien que le réglage fin de la requête puisse également améliorer les performances des ensembles de données QA, il peut être utilisé pour adapter les densesphrases à des requêtes d'entrée de style non QA telles que "Subject [SEP] Relation" pour récupérer des entités objets ou "j'aime la musique rap". pour récupérer des documents pertinents sur le rap.
Tout d'abord, vous avez besoin d'un index de phrase pour le Wikipedia complet ( wiki-20181220 ), qui peut être simplement téléchargé ici, ou un index de phrase personnalisé comme décrit ici. Compte tenu de votre requête-répondage ou de vos paires de documents de requête prétraitées sous forme de fichiers JSON dans $DATA_DIR/open-qa ou $DATA_DIR/kilt , vous pouvez facilement remettre en question votre modèle. Par exemple, l'ensemble de formation de T-REX ( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json ) ressemble à:
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
La commande suivante des fins de requête de la commande densephrases-multi sur T-Rex.
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Notez que le codeur de requête pré-formé est spécifié dans train-query en tant que --load_dir $(SAVE_DIR)/densephrases-multi et un nouveau modèle sera enregistré en tant que densephrases-multi-query-trex comme spécifié dans MODEL_NAME . Vous pouvez également vous entraîner sur différents ensembles de données en modifiant la dépendance trex-open-data en *-open-data (par exemple, ay2-kilt-data pour la liaison d'entités).
Avec tous les encodeurs de requête densephrases (par exemple, densephrases-multi-query-nq ) et un index de phrase (par exemple, densephrases-multi_wiki-20181220 ), vous pouvez tester vos questions comme suit et les résultats de récupération seront enregistrés en tant que fichier JSON avec l'option --save_pred :
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997 Pour l'évaluation des différents ensembles de données, modifiez simplement la dépendance de eval-index (ou eval-demo ) en conséquence (par exemple, nq-open-data à trec-open-data pour l'évaluation sur CaratedTrec).
Au bas de Makefile , nous répertorions les commandes que nous avons utilisées pour prétraiter les ensembles de données et Wikipedia. Pour la formation de modèles de génération de questions (T5-Large), nous avons utilisé https://github.com/patil-suraj/question_generation (voir aussi ici pour QG). Notez que tous les ensembles de données sont déjà prétraités, y compris les questions générées, vous n'avez donc pas besoin d'exécuter la plupart de ces scripts. Pour créer des ensembles de tests pour les questions personnalisées (domaine ouvert), voir preprocess-openqa dans Makefile .
N'hésitez pas à envoyer un courriel à Jinhyuk Lee ([email protected]) pour toutes les questions liées au code ou au journal. Vous pouvez également ouvrir un problème GitHub. Veuillez essayer de spécifier les détails afin que nous puissions mieux comprendre et vous aider à résoudre le problème.
Veuillez citer notre papier si vous utilisez desphrases dense dans votre travail:
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}Veuillez consulter la licence pour plus de détails.


