DensePhrases
1.1.0
البدء | Lee et al. ، ACL 2021 | Lee et al. ، emnlp 2021 | العرض التوضيحي | المراجع | رخصة
الكثافة هي نموذج استرجاع النص يمكنه إرجاع العبارات أو الجمل أو المقاطع أو المستندات لمدخلات اللغة الطبيعية الخاصة بك. باستخدام مليارات من ناقلات العبارات الكثيفة من Wikipedia بأكملها ، تقوم عمليات البحث الكثيفة بإجابات على مستوى العبارة على أسئلتك في الوقت الفعلي أو استرداد مقاطع للمهام المصب.
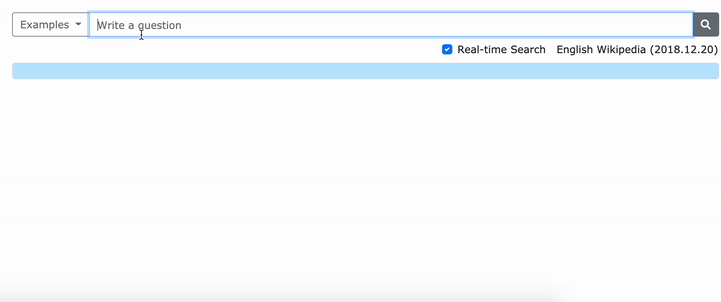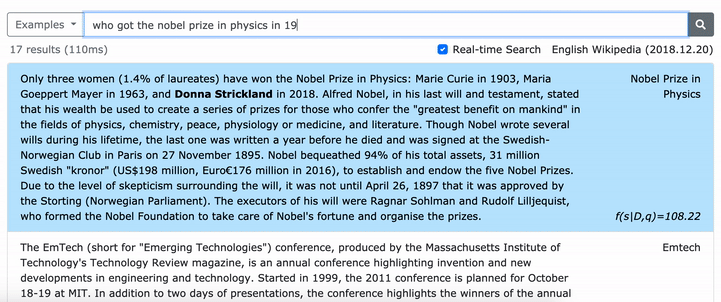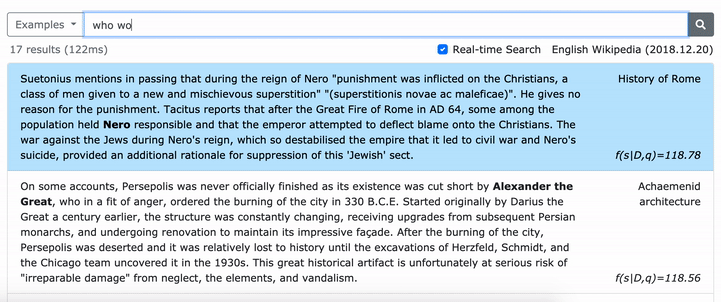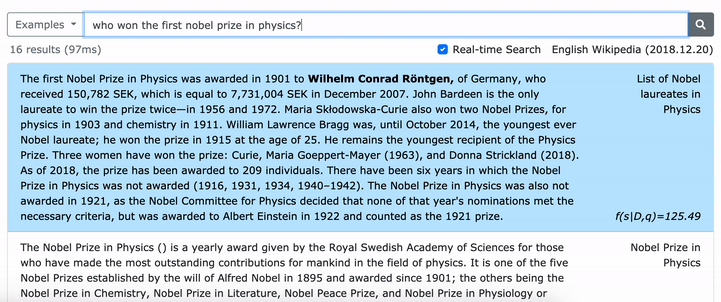
يرجى الاطلاع على ورقة ACL الخاصة بنا (تعلم تمثيلات كثيفة للعبارات على نطاق) للحصول على تفاصيل حول كيفية تعلم تمثيلات كثيفة للعبارات وورقة EMNLP (استرجاع العبارة يتعلم استرجاع الممر ، أيضًا) حول كيفية أداء إعادة التثبيت متعددة الحدود.
***** جرب عرضنا التجريبي عبر الإنترنت للكثافة هنا! *****
transformers==4.13.0 (انظر الملاحظات).densephrases-multi-query-* .بعد تثبيت عبارات كثيفة وتحميل فهرس عبارة ، يمكنك بسهولة استرداد العبارات أو الجمل أو الفقرات أو المستندات الخاصة بك.
انظر هنا للحصول على المزيد من الأمثلة مثل استخدام وضع CPU فقط ، وإنشاء فهرس مخصص ، وأكثر من ذلك.
يمكنك أيضًا استخدام عبارات كثيفة لاسترداد المستندات ذات الصلة للحوار أو تشغيل كيان يربط بين النصوص المعطاة.
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]نحن نقدم المزيد من الأمثلة ، والتي تتضمن تدريب نموذج الإجابة على أسئلة على أحدث طراز للأسئلة المفتوحة يسمى Fusion in-Decovery بواسطة Izacard and Grave ، 2021.
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop يستخدم الفرع main python==3.7 و transformers==2.9.0 . انظر أدناه للحصول على إصدارات أخرى من عبارات كثيفة.
| يطلق | ملحوظة | وصف |
|---|---|---|
| v1.0.0 | وصلة | transformers==2.9.0 ، مثل main |
| v1.1.0 | وصلة | transformers==4.13.0 |
قبل تنزيل الملفات المطلوبة أدناه ، يرجى تعيين الدلائل الافتراضية على النحو التالي والتأكد من أن لديك سعة تخزين كافية لتنزيل الملفات وفك ضغطها:
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh لتنزيل الموارد الموضحة أدناه ، يمكنك استخدام download.sh على النحو التالي:
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR أو استخدم download.sh .$DATA_DIR أو استخدم download.sh . # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump يمكنك استخدام النماذج التي تم تدريبها مسبقًا من مركز Huggingface Model. سيتم ترجمة أي اسم طراز يبدأ بـ princeton-nlp (المحدد في load_dir ) تلقائيًا كنموذج في محور طراز Huggingface الخاص بنا.
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| نموذج | استعلام. | NQ | WebQ | TREC | Triviaqa | فريق | وصف |
|---|---|---|---|---|---|---|---|
| الكثافة-بروتين | لا أحد | 31.9 | 25.5 | 35.7 | 44.4 | 29.3 | م. |
| الكثافة -جولت-Query-multi | عديد | 40.8 | 35.0 | 48.8 | 53.3 | 34.2 | تستخدم للتوضيح |
| نموذج | استعلام. & eval | م | التنبؤ (اختبار) | وصف |
|---|---|---|---|---|
| الكثافة -جول-Query-NQ | NQ | 41.3 | وصلة | - |
| الكثافة-multi-query-wq | WebQ | 41.5 | وصلة | - |
| الكثافة-Multi-Query-TREC | TREC | 52.9 | وصلة | --regex مطلوب |
| الكثافة -جولت-QUERY-TQA | Triviaqa | 53.5 | وصلة | - |
| الكثافة -جولت-QUERY-SQD | فريق | 34.5 | وصلة | - |
هام : جميع النماذج باستثناء densephrases-multi يتم ضبطها على جانب الاستعلام على مجموعة البيانات المحددة (Query-Ft.) باستخدام فهرس العبارات الكثيفة -الفولت -الويك -20181220. لاحظ أيضًا أن نماذجنا التي تم تدريبنا مسبقًا هي نماذج حساسة للحالة ، ويتم الحصول على أفضل النتائج عند- --truecase في أي استعلامات منخفضة (على سبيل المثال ، NQ).
densephrases-multi : تدرب على مجموعات بيانات فهم Mifiple Reading (NQ ، WebQ ، TREC ، TriviaQa ، Squad).densephrases-multi-query-multi : densephrases-multi Query Side تم ضبطها على مجموعات بيانات QA متعددة المجال المفتوح (NQ ، WebQ ، TREC ، Triviaqa ، Squad).densephrases-multi-query-* : تم ضبط Query densephrases-multi على كل مجموعة بيانات QA مفتوحة المجال. للاطلاع على النماذج التي تم تدريبها مسبقًا في مهام أخرى (على سبيل المثال ، ملء الفتحات) ، انظر الأمثلة. لاحظ أن معظم النماذج التي تم تدريبها مسبقًا هي نتائج densephrases-multi الدائرية من جانب الاستعلام.
spanbert-base-cased-* ). قم بتنزيله وفك ضغطه تحت $SAVE_DIR أو استخدم download.sh . # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )يرجى ملاحظة أنك لا تحتاج إلى تنزيل فهرس العبارة هذا ما لم تكن تريد العمل على مقياس ويكيبيديا الكامل.
$SAVE_DIR أو استخدم download.sh .نحن نقدم أيضًا فهارس العبارات الأصغر بناءً على تصفية أكثر إثارة (اختياري).
يجب وضع هذه الفهارس الأصغر ضمن $SAVE_DIR/densephrases-multi_wiki-20181220/dump/start مع أي فهارس أخرى قمت بتنزيلها. إذا كنت تستخدم فهرس عبارة أصغر فقط ولا ترغب في تنزيل الفهرس الكبير (74 جيجابايت) ، فأنت بحاجة إلى تنزيل البيانات الوصفية (20 جيجابايت) ووضعه تحت $SAVE_DIR/densephrases-multi_wiki-20181220/dump Comber كما هو موضح أدناه. يجب أن يبدو هيكل الملفات:
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small يتم إنشاء جميع فهارس العبارات من نفس النموذج ( densephrases-multi ) ويمكنك استخدام جميع النماذج المدربة مسبقًا أعلاه مع أي من فهارس العبارات هذه. لتغيير الفهرس ، ما عليك سوى تعيين index_name (أو --index_name في densephrases/options.py ) على النحو التالي:
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... ) ويرد أدناه أداء densephrases-multi-query-nq على الأسئلة الطبيعية (الاختبار) مع فهارس العبارات المختلفة.
| فهرس عبارة | المجال المفتوح QA (EM) | استرجاع الجملة (ACC@1/5) | استرجاع المرور (ACC@1/5) | مقاس | وصف |
|---|---|---|---|---|---|
| 1048576_flat_opq96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60 جيجابايت | تقييم مع eval-index-psg |
| 1048576_flat_opq96_medium | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39 جيجابايت | |
| 1048576_flat_opq96_small | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20 جيجابايت |
لاحظ أن دقة استرجاع المقطع (ACC@1/5) أعلى بشكل عام من الأرقام المبلغ عنها في الورقة نظرًا لأن فهارس العبارة هذه تُرجع الفقرات الطبيعية بدلاً من كتل النص ذات الحجم الثابت (أي 100 كلمة).
يمكنك تشغيل العرض التوضيحي على نطاق ويكيبيديا على الخادم الخاص بك. بالنسبة إلى العرض التوضيحي الخاص بك ، يمكنك تغيير فهرس العبارات (التي تم الحصول عليها من هنا) أو تشفير الاستعلام (على سبيل المثال ، إلى densephrases-multi-query-nq ).
متطلبات الموارد لتشغيل العرض التجريبي الكامل ويكيبيديا هو:
لاحظ أنك لم تعد بحاجة إلى SSD لتشغيل العرض التوضيحي على عكس نماذج استرجاع العبارات السابقة (Denspi ، Denspi+SPARC). تخدم الأوامر التالية نفس العرض التوضيحي تمامًا هنا على http://localhost:51997 .
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997 يرجى تغيير- --load_dir أو- --dump_dir إذا لزم الأمر وإزالة- --cuda لإصدار وحدة المعالجة المركزية فقط. بمجرد إعداد العرض التوضيحي ، سيتم تحديث ملفات السجل في $SAVE_DIR/logs/ تلقائيًا كلما جاء سؤال جديد. يمكنك أيضًا إرسال استعلامات إلى الخادم الخاص بك باستخدام مجموعات صغيرة من الأسئلة لاستدلال أسرع.
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred لمزيد من التفاصيل (على سبيل المثال ، تغيير مجموعة الاختبار) ، يرجى الاطلاع على الأهداف في Makefile ( q-serve ، p-serve ، eval-demo ، إلخ).
في هذا القسم ، نقدم إجراء خطوة بخطوة لتدريب العبارات الكثيفة ، وإنشاء متجهات وفهارس العبارة ، وتشغيل الاستدلالات مع النموذج المدرب. يتم تبسيط جميع أوامرنا هنا كأهداف Makefile ، والتي تشمل مسارات مجموعة البيانات الدقيقة ، وإعدادات مقياس البارامير ، إلخ.
إذا اكتمل تشغيل الاختبار التالي دون خطأ بعد التثبيت والتنزيل ، فأنت على ما يرام!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test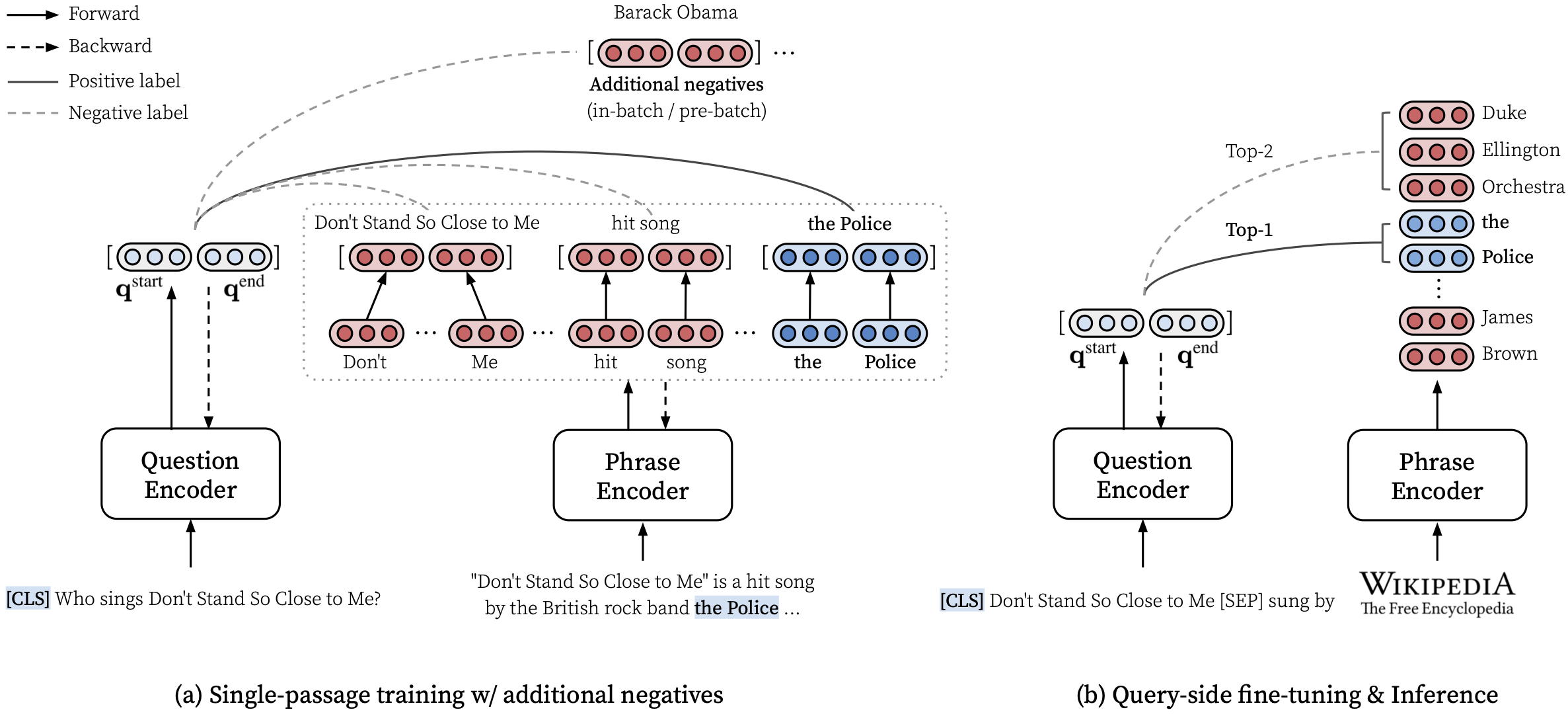
لتدريب عبارات كثيفة من نقطة الصفر ، استخدم run-rc-nq في Makefile ، الذي يدرب الكثافة على NQ (معالجة مسبقًا لمهمة فهم القراءة) وتقييمها على فهم القراءة وكذلك على (شبه) QA المجال المفتوح. يمكنك ببساطة تغيير التدريب الذي تم تعيينه عن طريق تعديل تبعيات run-rc-nq (على سبيل المثال ، nq-rc-data => sqd-rc-data و nq-param => sqd-param للتدريب على الفريق). ستحتاج إلى وحدة معالجة رسومات واحدة 24 جيجا بايت لتدريب عبارات كثيفة على مهام فهم القراءة ، ولكن يمكنك استخدام وحدات معالجة الرسومات الأصغر عن طريق الإعداد --gradient_accumulation_steps بشكل صحيح.
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq يتكون run-rc-nq من الأوامر الستة على النحو التالي (في حالة التدريب على NQ):
make train-rc ... : Train Densephrases على NQ مع Eq. 9 (l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg) مع أسئلة تم إنشاؤها.make train-rc ... : تحميل الكثافة المدربة في الخطوة السابقة وقم بتدريبه بشكل أكبر مع Eq. 9 مع السلبيات قبل الدفعة.make gen-vecs : إنشاء متجهات العبارة لـ D_SMALL (= مجموعة من جميع المقاطع في NQ DEV).make index-vecs : قم بإنشاء فهرس عبارة لـ D_SMALL.make compress-meta : Metadata ضغطات لاستنتاج أسرع.make eval-index ... : تقييم مؤشر العبارات على أسئلة مجموعة التطوير. في نهاية الخطوة 2 ، سترى الأداء في مهمة فهم القراءة حيث يتم إعطاء مقطع ذهبي (حوالي 72.0 م على NQ Dev). تعطي الخطوة 6 الأداء على إعداد المجال شبه المفتوح (يُشار إليه باسم D_SMALL ؛ انظر الجدول 6 في الورقة) حيث يتم استخدام الممرات بأكملها من مجموعة تطوير NQ للفهرسة (حوالي 62.0 م مع أسئلة DEV NQ). سيتم حفظ النموذج المدرب بموجب $SAVE_DIR/$MODEL_NAME . لاحظ أنه خلال التدريب الواحد على NQ ، نستبعد بعض الأسئلة في مجموعة التطوير ، والتي توجد إجابات مشروحة من قائمة أو جدول.
دعنا نفترض أن لديك عبارات كثيفة مدربة مسبقًا تسمى densephrases-multi ، والتي يمكن أيضًا تنزيلها من هنا. الآن ، يمكنك إنشاء متجهات عبارة عن مجموعة واسعة النطاق مثل Wikipedia باستخدام gen-vecs-parallel . لاحظ أنه يمكنك فقط تنزيل فهرس العبارات لمقياس ويكيبيديا الكامل وتخطي هذا القسم.
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8 مجموعة النص الافتراضي لإنشاء متجهات العبارات هي wiki-dev الموجودة في $DATA_DIR/wikidump . لدينا ثلاثة خيارات لشركة نصية أكبر:
wiki-dev : 1/100 مقياس ويكيبيديا (عينة) ، 8 ملفاتwiki-dev-noise : 1/10 Wikipedia مقياس (أخذ عينات) ، 500 ملفwiki-20181220 : مقياس ويكيبيديا الكامل (20181220) ، 5621 ملف تحتوي شركة wiki-dev* أيضًا على مقاطع من مجموعة تطوير NQ ، بحيث يمكنك تتبع أداء النموذج الخاص بك بحجم متزايد من مجموعة النص (عادة ما يتناقص كلما زاد حجمه). سيتم حفظ متجهات العبارة كملفات HDF5 في $SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (على سبيل المثال ، $SAVE_DIR/densephrases-multi_wiki-dev/dump ) ، والتي ستتم إحالتها إلى $DUMP_DIR أدناه.
START END حدد فهرس الملفات في المجموعة (على سبيل المثال ، START=0 END=8 لـ wiki-dev و START=0 END=5621 لـ wiki-20181220 ). يستهلك كل مجموعة من gen-vecs-parallel فقط 2 جيجا بايت في وحدة معالجة الرسومات الواحدة ، ويمكنك توزيع العمليات START END مختلفة باستخدام البرنامج النصي slurm أو shell (على سبيل المثال ، START=0 END=200 ، START=200 END=400 ، ... ، START=5400 END=5621 ). يمكن لتوزيع 28 عملية على 4 24 جيجابايت وحدات معالجة الرسومات (كل معالجة حوالي 200 ملف) إنشاء متجهات عبارة لـ wiki-20181220 في 8 ساعات. تتطلب معالجة WikiePdia بأكملها ما يصل إلى 500 جيجابايت ونوصي باستخدام SSD لتخزينها إن أمكن (يمكن تخزين مجموعة أصغر في HDD).
بعد إنشاء متجهات العبارة ، تحتاج إلى إنشاء فهرس عبارة للبحث عن الوقت تحت الحرة للعبارات. هنا ، نستخدم IVFOPQ لمؤشر العبارات.
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ بالنسبة لـ wiki-dev-noise و wiki-20181220 ، تحتاج إلى تعديل عدد المجموعات إلى 101،372 و 1048،576 ، على التوالي (ببساطة تغيير medium1-index في ìndex-vecs إلى medium2-index أو large-index ). بالنسبة لـ wiki-20181220 (ويكيبيديا الكاملة) ، يستغرق هذا حوالي 1 إلى يومين اعتمادًا على مواصفات جهازك ويتطلب حوالي 100 جيجابايت ذاكرة الوصول العشوائي. بالنسبة إلى IVFSQ كما هو موضح في الورقة ، يمكنك استخدام index-add و index-merge لتوزيع إضافة ناقلات العبارات إلى الفهرس.
تحتاج أيضًا إلى ضغط البيانات الوصفية (المحفوظة في ملفات HDF5 مع ناقلات العبارات) لاستنتاج أسرع من العبارات الكثيفة. هذا إلزامي لمؤشر IVFOPQ.
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump لتقييم أداء عبارات كثيفة مع فهارس العبارة الخاصة بك ، استخدم eval-index .
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/يجعل الاستفسار الدقيق من جانب الاستعلام أداة متعددة الاستخدامات لاسترداد نص متعدد الحصبة لأنواع مختلفة من استعلامات الإدخال. على الرغم من أن عملية التكييف من جانب الاستعلام يمكنها أيضًا تحسين الأداء على مجموعات بيانات ضمان الجودة ، إلا أنه يمكن استخدامها لتكييف عبارات كثيفة مع استعلامات إدخال النمط غير QA مثل "SESP [SEP]" لاسترداد كيانات الكائنات أو "أنا أحب موسيقى الراب". لاسترداد المستندات ذات الصلة على موسيقى الراب.
أولاً ، تحتاج إلى فهرس عبارة لـ Wikipedia الكامل ( wiki-20181220 ) ، والذي يمكن تنزيله ببساطة هنا ، أو فهرس عبارة مخصصة كما هو موضح هنا. بالنظر إلى أزواج الاستعلام أو الاستعلام ، تم تجهيزها مسبقًا كملفات JSON في $DATA_DIR/open-qa أو $DATA_DIR/kilt ، يمكنك بسهولة استعلامك في صياغة الطراز الخاص بك. على سبيل المثال ، تبدو مجموعة التدريب من T-Rex ( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json ) على النحو التالي:
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
إن الاستعلام التالي من جانب الاستعلام الدقيق densephrases-multi على T-Rex.
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ لاحظ أن تشفير الاستعلام الذي تم تدريبه مسبقًا يتم تحديده في train-query كـ- --load_dir $(SAVE_DIR)/densephrases-multi وسيتم حفظ نموذج جديد على شكل densephrases-multi-query-trex كما هو محدد في MODEL_NAME . يمكنك أيضًا التدريب على مجموعات بيانات مختلفة عن طريق تغيير trex-open-data إلى *-open-data (على سبيل المثال ، ay2-kilt-data لربط الكيان).
مع أي تشفير استعلام كثيف (على سبيل المثال densephrases-multi-query-nq ) ومؤشر العبارات (على سبيل المثال ، densephrases-multi_wiki-20181220 ) ، يمكنك اختبار استفساراتك على النحو التالي وسيتم حفظ نتائج الاسترجاع كملف JSON مع- --save_pred .
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997 للتقييم على مجموعات البيانات المختلفة ، ما عليك سوى تغيير تبعية eval-index (أو eval-demo ) وفقًا لذلك (على سبيل المثال ، nq-open-data to trec-open-data للتقييم على regatedTrec).
في الجزء السفلي من Makefile ، ندرج الأوامر التي استخدمناها للمعالجة المسبقة لمجموعات البيانات و Wikipedia. لتدريب نماذج توليد الأسئلة (T5-LARGE) ، استخدمنا https://github.com/patil-suraj/question_generation (انظر أيضًا هنا لـ QG). لاحظ أن جميع مجموعات البيانات يتم معالجتها مسبقًا بما في ذلك الأسئلة التي تم إنشاؤها ، لذلك لا تحتاج إلى تشغيل معظم هذه البرامج النصية. لإنشاء مجموعات الاختبار لأسئلة مخصصة (المجال المفتوح) ، راجع preprocess-openqa في Makefile .
لا تتردد في إرسال بريد إلكتروني إلى Jinhyuk Lee ([email protected]) لأي أسئلة تتعلق بالرمز أو الورقة. يمكنك أيضًا فتح مشكلة github. يرجى محاولة تحديد التفاصيل حتى نتمكن من فهم المشكلة بشكل أفضل ومساعدتك على حل المشكلة.
يرجى الاستشهاد بالورقة إذا كنت تستخدم عبارات كثيفة في عملك:
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}يرجى الاطلاع على الترخيص للحصول على التفاصيل.


