DensePhrases
1.1.0
Introdução | Lee et al., ACL 2021 | Lee et al., EMNLP 2021 | Demo | REFERÊNCIAS | Licença
Densefrases é um modelo de recuperação de texto que pode retornar frases, frases, passagens ou documentos para suas entradas de linguagem natural. Usando bilhões de vetores densos de frase de toda a Wikipedia, as densas pesquisas pesquisas em nível de frase respostas às suas perguntas em tempo real ou recuperam passagens para tarefas a jusante.
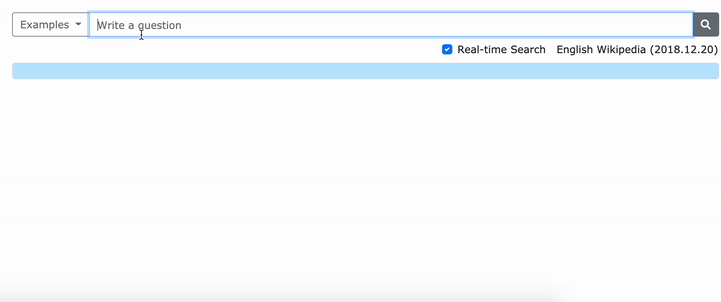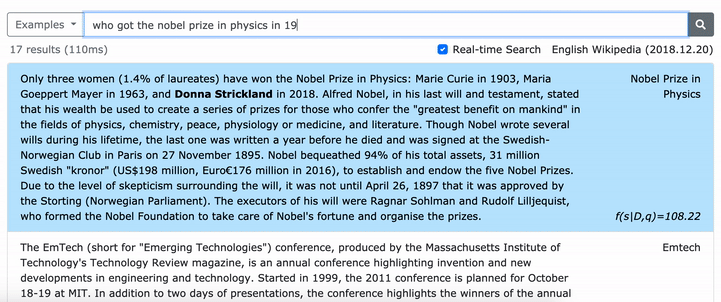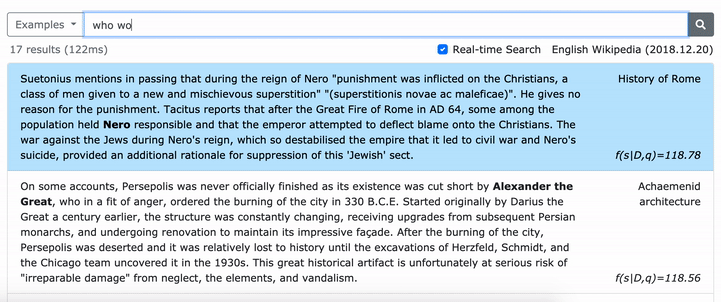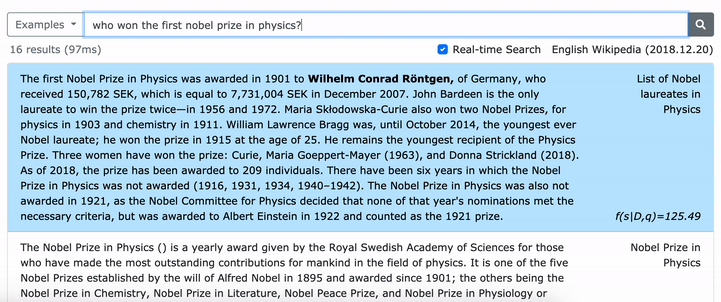
Consulte nosso artigo da ACL (aprendendo representações densas de frases em escala) para obter detalhes sobre como aprender representações densas de frases e o artigo EMNLP (a recuperação da frase também aprende a recuperação de passagem) sobre como realizar a recuperação de multi-granularidade.
***** Experimente nossa demonstração on -line de densas aqui! *****
transformers==4.13.0 (ver notas).densephrases-multi-query-* adicionado.Depois de instalar densas e dowload, você pode recuperar facilmente frases, frases, parágrafos ou documentos para sua consulta.
Veja aqui para mais exemplos, como o uso do modo somente CPU, criando um índice personalizado e muito mais.
Você também pode usar densefrases para recuperar documentos relevantes para um diálogo ou a entidade executada vinculando textos.
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]Fornecemos mais exemplos, que incluem o treinamento de um modelo de resposta de perguntas sobre o domínio aberto chamado Fusion-in-Decoder por Izacard e Grave, 2021.
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop O ramo main usa python==3.7 e transformers==2.9.0 . Veja abaixo para outras versões de densasfrases.
| Liberar | Observação | Descrição |
|---|---|---|
| v1.0.0 | link | transformers==2.9.0 , o mesmo que main |
| v1.1.0 | link | transformers==4.13.0 |
Antes de baixar os arquivos necessários abaixo, defina os diretórios padrão da seguinte forma e verifique se você tem armazenamento suficiente para baixar e descompactar os arquivos:
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh Para baixar os recursos descritos abaixo, você pode usar download.sh da seguinte forma:
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR ou use download.sh .$DATA_DIR ou use download.sh . # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump Você pode usar modelos pré-treinados no hub do modelo Huggingface. Qualquer nome do modelo que começa com princeton-nlp (especificado em load_dir ) será convertido automaticamente como um modelo em nosso hub de modelo Huggingface.
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| Modelo | Query-ft. | Nq | Webq | Trec | Triviaqa | Esquadrão | Descrição |
|---|---|---|---|---|---|---|---|
| Densefrases-Multi | Nenhum | 31.9 | 25.5 | 35.7 | 44.4 | 29.3 | EM antes de qualquer consulta-ft. |
| Densefrases-Multi-Query-Multi | Múltiplo | 40.8 | 35.0 | 48.8 | 53.3 | 34.2 | Usado para demonstração |
| Modelo | Query-ft. & Aval | Em | Previsão (teste) | Descrição |
|---|---|---|---|---|
| Densefrases-multi-Query-nq | Nq | 41.3 | link | - |
| Densefrases-Multi-Query-wq | Webq | 41.5 | link | - |
| Densefrases-Multi-Query-Trec | Trec | 52.9 | link | --regex necessário |
| Densefrases-multi-Query-TQA | Triviaqa | 53.5 | link | - |
| Densefrases-multi-Query-sqd | Esquadrão | 34.5 | link | - |
IMPORTANTE : Todos os modelos, exceto densephrases-multi são ajustados no lado da consulta no conjunto de dados especificado (Query-ft.) Usando o índice de frase densefrases-multi_wiki-20181220. Observe também que nossos modelos pré-treinados são modelos sensíveis à caixa e os melhores resultados são obtidos quando --truecase está ativado para qualquer consulta inferior (por exemplo, NQ).
densephrases-multi : treinado em conjuntos de dados de compreensão de leitura de amotas (NQ, Webq, Trec, Triviaqa, Esquadrão).densephrases-multi-query-multi : densephrases-multi , afinou-se do lado da consulta em vários conjuntos de dados de QA de domínio aberto (NQ, Webq, Trec, Triviaqa, Esquadrão).densephrases-multi-query-* : densephrases-multi , afinou-se do lado da consulta em cada conjunto de dados de QA de domínio aberto. Para modelos pré-treinados em outras tarefas (por exemplo, preenchimento de slots), consulte Exemplos. Observe que a maioria dos modelos pré-treinados são os resultados de densephrases-multi de ajuste fino do lado da consulta.
spanbert-base-cased-* ). Download e descompacte -o em $SAVE_DIR ou use download.sh . # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )Observe que você não precisa baixar esse índice de frase, a menos que queira trabalhar na escala completa da Wikipedia.
$SAVE_DIR ou use download.sh .Também fornecemos índices de frase menores com base em filtragem mais agressiva (opcional).
Esses índices menores devem ser colocados em $SAVE_DIR/densephrases-multi_wiki-20181220/dump/start junto com outros índices que você baixou. Se você usa apenas um índice de frase menor e não quiser baixar o grande índice (74 GB), precisará baixar metadados (20 GB) e colocá-lo na pasta $SAVE_DIR/densephrases-multi_wiki-20181220/dump como mostrado abaixo. A estrutura dos arquivos deve parecer:
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small Todos os índices de frase são criados a partir do mesmo modelo ( densephrases-multi ) e você pode usar todos os modelos pré-treinados acima com qualquer um desses índices de frase. Para alterar o índice, basta definir index_name (ou --index_name em densephrases/options.py ) da seguinte forma:
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... ) O desempenho de densephrases-multi-query-nq em questões naturais (teste) com diferentes índices de frase é mostrado abaixo.
| Índice de frase | QA de domínio aberto (EM) | Recuperação de frases (ACC@1/5) | Recuperação de passagem (ACC@1/5) | Tamanho | Descrição |
|---|---|---|---|---|---|
| 1048576_FLAT_OPQ96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60 GB | Avaliado com eval-index-psg |
| 1048576_flat_opq96_medium | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39 GB | |
| 1048576_FLAT_OPQ96_SMALL | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20 GB |
Observe que a precisão da recuperação da passagem (ACC@1/5) é geralmente maior que os números relatados no artigo, pois esses índices de frase retornam parágrafos naturais em vez de blocos de texto de tamanho fixo (ou seja, 100 palavras).
Você pode executar a demonstração em escala da Wikipedia em seu próprio servidor. Para sua própria demonstração, você pode alterar o índice de frase (obtido daqui) ou o codificador de consulta (por exemplo, para densephrases-multi-query-nq ).
O requisito de recurso para executar a demonstração completa da escala da Wikipedia é:
Observe que você não precisa mais de um SSD para executar a demonstração, diferentemente dos modelos anteriores de recuperação de frases (denspi, denspi+SPARC). Os seguintes comandos servem exatamente a mesma demonstração que aqui no seu http://localhost:51997 .
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997 Altere --load_dir ou --dump_dir se necessário, e remova --cuda para versão somente CPU. Depois de configurar a demonstração, os arquivos de log em $SAVE_DIR/logs/ serão atualizados automaticamente sempre que uma nova pergunta entrar. Você também pode enviar consultas ao seu servidor usando mini-lotes de perguntas para inferência mais rápida.
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred Para obter mais detalhes (por exemplo, alterando o conjunto de testes), consulte as metas no Makefile ( q-serve , p-serve , eval-demo , ETC).
Nesta seção, introduzimos um procedimento passo a passo para treinar densasfrases, criar vetores e índices de frase e executar inferências com o modelo treinado. Todos os nossos comandos aqui são simplificados como alvos Makefile , que incluem caminhos exatos do conjunto de dados, configurações de hiperparâmetro etc.
Se o teste seguinte será concluído sem erro após a instalação e o download, você estará pronto!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test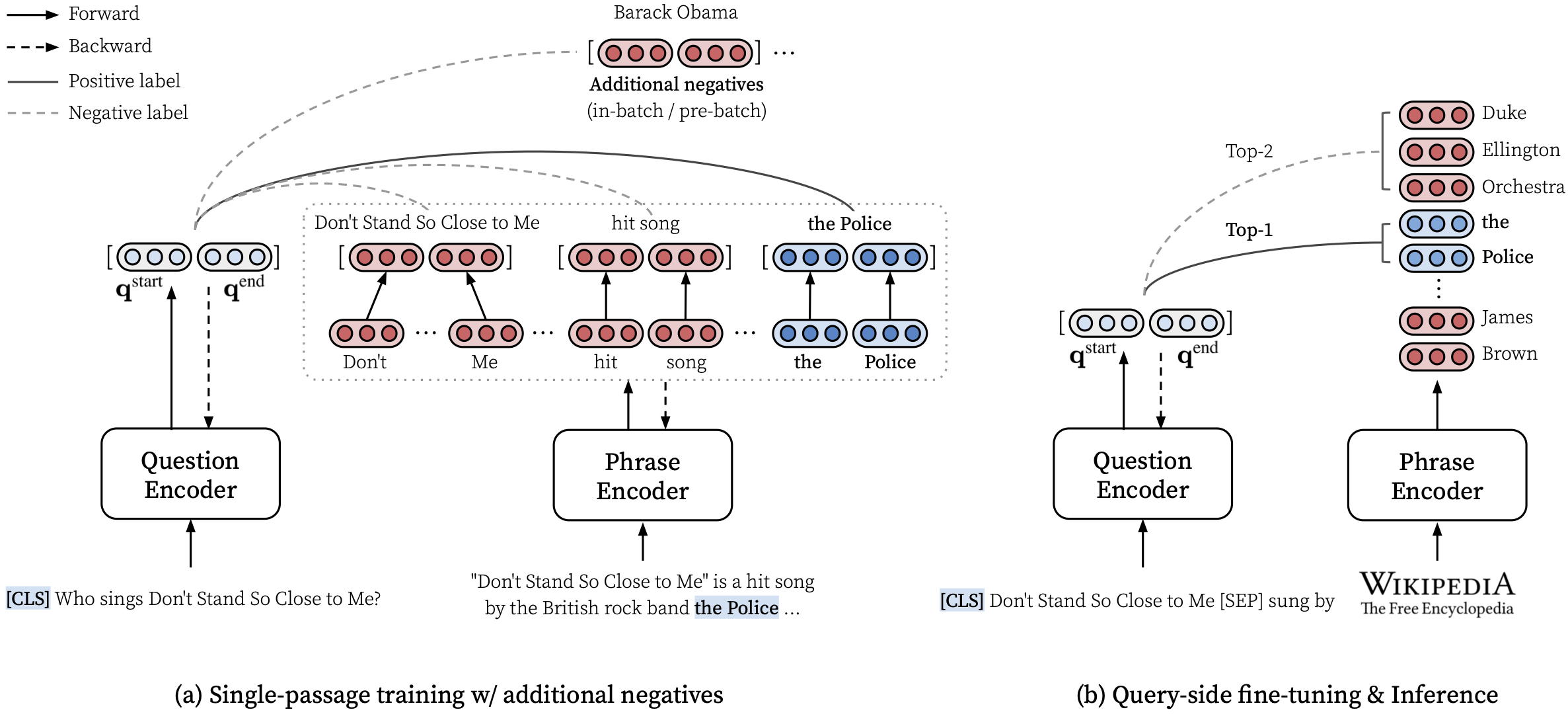
Para treinar densasfrases do zero, use run-rc-nq no Makefile , que treina densefrases no NQ (pré-processado para a tarefa de compreensão de leitura) e avalie-o na compreensão de leitura e também no qa (semi) de domínio aberto. Você pode simplesmente alterar o conjunto de treinamento modificando as dependências de run-rc-nq (por exemplo, nq-rc-data => sqd-rc-data e nq-param => sqd-param para treinamento em esquadrão). Você precisará de uma única GPU de 24 GB para treinamento de densas em tarefas de compreensão de leitura, mas pode usar GPUs menores configurando --gradient_accumulation_steps corretamente.
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq é composto pelos seis comandos da seguinte maneira (no caso de treinamento no NQ):
make train-rc ... : Treine densefrases no NQ com a Eq. 9 (l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg) com perguntas geradas.make train-rc ... : Carregue densefrases treinadas na etapa anterior e treine-o com a Eq. 9 com negativos pré-lotes.make gen-vecs : Gere vetores de frase para d_small (= conjunto de todas as passagens no NQ dev).make index-vecs : Crie um índice de frase para D_Small.make compress-meta : compacta os metadados para uma inferência mais rápida.make eval-index ... : Avalie o índice de frase nas perguntas do Desenvolvimento. No final da etapa 2, você verá o desempenho na tarefa de compreensão de leitura, onde é dada uma passagem de ouro (cerca de 72,0 EM no NQ Dev). A etapa 6 fornece o desempenho na configuração de domínio semi-aberto (indicado como d_small; consulte a Tabela 6 no papel), onde todas as passagens do conjunto de desenvolvimento NQ são usadas para a indexação (cerca de 62,0 EM com perguntas de dev nq). O modelo treinado será salvo sob $SAVE_DIR/$MODEL_NAME . Observe que, durante o treinamento de passagem única no NQ, excluímos algumas perguntas no conjunto de desenvolvimento, cujas respostas anotadas são encontradas em uma lista ou uma tabela.
Vamos supor que você tenha uma densefrases pré-treinadas chamada densephrases-multi , que também pode ser baixada a partir daqui. Agora, você pode gerar vetores de frase para um corpus em larga escala como a Wikipedia usando gen-vecs-parallel . Observe que você pode simplesmente baixar o índice de frase para a escala completa da Wikipedia e pular esta seção.
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8 O corpus de texto padrão para a criação de vetores de frase está wiki-dev localizado em $DATA_DIR/wikidump . Temos três opções para corpora de texto maiores:
wiki-dev : 1/100 Wikipedia Scale (amostrado), 8 arquivoswiki-dev-noise : 1/10 Escala da Wikipedia (amostrada), 500 arquivoswiki-20181220 : Escala completa da Wikipedia (20181220), 5621 arquivos O wiki-dev* Corpora também contém passagens do conjunto de desenvolvimento NQ, para que você possa rastrear o desempenho do seu modelo com um tamanho crescente do corpus de texto (geralmente diminui à medida que aumenta). Os vetores da frase serão salvos como arquivos HDF5 em $SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (por exemplo, $SAVE_DIR/densephrases-multi_wiki-dev/dump ), que será referido a $DUMP_DIR abaixo.
START e END especifique o índice de arquivo no corpus (por exemplo, START=0 END=8 para wiki-dev e START=0 END=5621 para wiki-20181220 ). Cada execução do gen-vecs-parallel consome apenas 2 GB em uma única GPU e você pode distribuir os processos com diferentes START e END usando slurm ou script de shell (por exemplo, START=0 END=200 , START=200 END=400 , ..., START=5400 END=5621 ). A distribuição de 28 processos em 4 GPUs de 24 GB (cada processamento de cerca de 200 arquivos) pode criar vetores de frase para wiki-20181220 em 8 horas. O processamento de todo o Wikiepdia requer até 500 GB e recomendamos o uso de um SSD para armazená -los se possível (um corpus menor pode ser armazenado em um HDD).
Depois de gerar os vetores de frase, você precisa criar um índice de frase para a pesquisa de tempo sublinear de tempo. Aqui, usamos o IVFOPQ para o índice de frase.
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ Para wiki-dev-noise e wiki-20181220 , você precisa modificar o número de clusters para 101.372 e 1.048.576, respectivamente (basta alterar medium1-index em ìndex-vecs para medium2-index ou large-index ). Para wiki-20181220 (Wikipedia completa), isso leva cerca de 1 ~ 2 dias, dependendo da especificação da sua máquina e requer cerca de 100 GB de RAM. Para o IVFSQ, conforme descrito no artigo, você pode usar index-add e index-merge para distribuir a adição de vetores de frase ao índice.
Você também precisa comprimir os metadados (salvos em arquivos HDF5, juntamente com vetores de frase) para uma inferência mais rápida de densasfrases. Isso é obrigatório para o Índice IVFOPQ.
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump Para avaliar o desempenho de densasfrases com seus índices de frase, use eval-index .
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/O ajuste fino do lado da consulta faz de densasfrases uma ferramenta versátil para recuperar o texto de várias granulares para diferentes tipos de consultas de entrada. Embora o ajuste fino do lado da consulta também possa melhorar o desempenho nos conjuntos de dados de controle de qualidade, ele pode ser usado para adaptar densasfrases às consultas de entrada no estilo não QA, como "Relacionamento de Assunto [SEP]" para recuperar entidades de objetos ou "eu amo música rap". para recuperar documentos relevantes sobre rap.
Primeiro, você precisa de um índice de frase para a Wikipedia completa ( wiki-20181220 ), que pode ser simplesmente baixada aqui, ou um índice de frase personalizado, conforme descrito aqui. Dados seus pares de respostas ou documentos de consulta pré-processados como arquivos json em $DATA_DIR/open-qa ou $DATA_DIR/kilt , você pode facilmente consultar o seu modelo. Por exemplo, o conjunto de treinamento de T-Rex ( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json ) parece o seguinte:
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
O seguinte comando, com o lado da consulta, densephrases-multi no T-Rex.
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Observe que o codificador de consulta pré-treinado é especificado no train-query como --load_dir $(SAVE_DIR)/densephrases-multi e um novo modelo será salvo como densephrases-multi-query-trex conforme especificado em MODEL_NAME . Você também pode treinar em diferentes conjuntos de dados, alterando os trex-open-data para *-open-data (por exemplo, ay2-kilt-data para vincular a entidade).
Com quaisquer codificadores de consultas densefrases (por exemplo, densephrases-multi-query-nq ) e um índice de frase (por exemplo, densephrases-multi_wiki-20181220 ), você pode testar suas consultas da --save_pred
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997 Para a avaliação de diferentes conjuntos de dados, basta alterar a dependência do eval-index (ou eval-demo ) de acordo (por exemplo, nq-open-data para trec-open-data para a avaliação no CuratedTrec).
Na parte inferior do Makefile , listamos comandos que usamos para pré-processamento dos conjuntos de dados e Wikipedia. Para modelos de geração de perguntas de treinamento (T5-Large), usamos https://github.com/patil-suraj/question_generation (consulte também aqui para QG). Observe que todos os conjuntos de dados já são pré-processados, incluindo as perguntas geradas, para que você não precise executar a maioria desses scripts. Para criar conjuntos de testes para perguntas personalizadas (de domínio aberto), consulte preprocess-openqa no Makefile .
Sinta -se à vontade para enviar um e -mail para Jinhyuk Lee ([email protected]) para qualquer dúvida relacionada ao código ou ao artigo. Você também pode abrir um problema do GitHub. Tente especificar os detalhes para que possamos entender melhor e ajudá -lo a resolver o problema.
Cite nosso artigo se você usar densasfrases em seu trabalho:
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}Por favor, consulte a licença para obter detalhes.


