DensePhrases
1.1.0
เริ่มต้นใช้งาน | Lee et al., ACL 2021 | Lee et al., Emnlp 2021 | การสาธิต ข้อมูลอ้างอิง | ใบอนุญาต
Densephrases เป็นแบบจำลองการดึงข้อความที่สามารถส่งคืนวลีประโยคข้อความหรือเอกสารสำหรับอินพุตภาษาธรรมชาติของคุณ การใช้เวกเตอร์วลีที่มีความหนาแน่นหลายพันล้านครั้งจาก Wikipedia ทั้งหมดทำให้ Densephrases ค้นหาคำตอบระดับวลีสำหรับคำถามของคุณแบบเรียลไทม์หรือดึงข้อความสำหรับงานดาวน์สตรีม
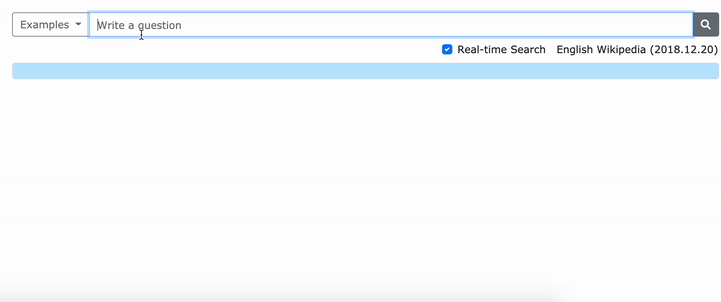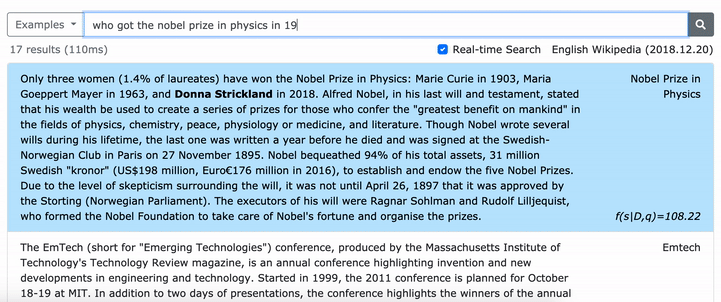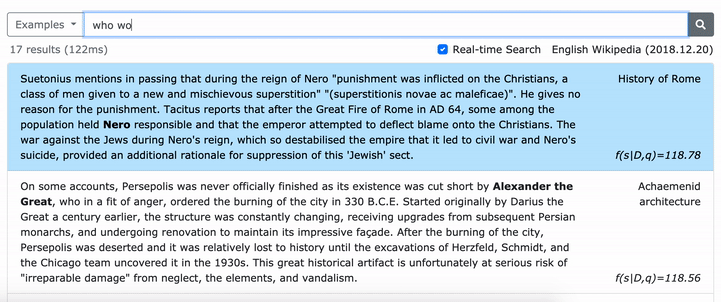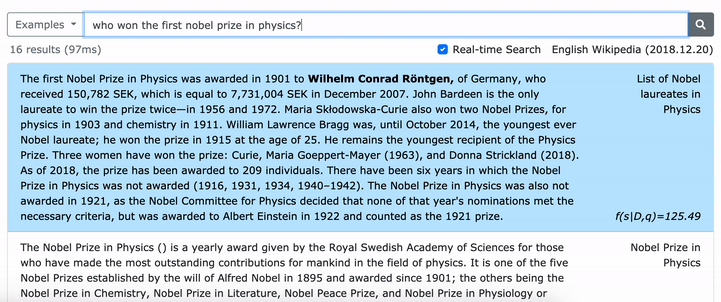
โปรดดูกระดาษ ACL ของเรา (การเรียนรู้การเป็นตัวแทนของวลีที่หนาแน่น) สำหรับรายละเอียดเกี่ยวกับวิธีการเรียนรู้การเป็นตัวแทนที่หนาแน่นของวลีและกระดาษ EMNLP (การดึงวลีเรียนรู้การดึงข้อความด้วยเช่นกัน) เกี่ยวกับวิธีการดึงข้อมูลหลายระดับ
***** ลองสาธิต densephrases ออนไลน์ของเราที่นี่! -
transformers==4.13.0 (ดูหมายเหตุ)densephrases-multi-query-* เพิ่มหลังจากติดตั้ง densephrases และ dowloading ดัชนีวลีคุณสามารถดึงวลีประโยคย่อหน้าหรือเอกสารสำหรับการสืบค้นของคุณได้อย่างง่ายดาย
ดูที่นี่สำหรับตัวอย่างเพิ่มเติมเช่นการใช้โหมด CPU เท่านั้นสร้างดัชนีที่กำหนดเองและอื่น ๆ
นอกจากนี้คุณยังสามารถใช้ densephrases เพื่อดึงเอกสารที่เกี่ยวข้องสำหรับบทสนทนาหรือเรียกใช้เอนทิตีที่เชื่อมโยงกับข้อความที่กำหนด
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]เราให้ตัวอย่างเพิ่มเติมซึ่งรวมถึงการฝึกอบรมรูปแบบการตอบคำถามแบบเปิดโดเมนที่ทันสมัยที่เรียกว่า Fusion-in-Decoder โดย Izacard และ Grave, 2021
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop สาขา main ใช้ python==3.7 และ transformers==2.9.0 ดูด้านล่างสำหรับ densephrases รุ่นอื่น ๆ
| ปล่อย | บันทึก | คำอธิบาย |
|---|---|---|
| v1.0.0 | การเชื่อมโยง | transformers==2.9.0 เช่นเดียวกับ main |
| v1.1.0 | การเชื่อมโยง | transformers==4.13.0 |
ก่อนดาวน์โหลดไฟล์ที่ต้องการด้านล่างโปรดตั้งค่าไดเรกทอรีเริ่มต้นดังนี้และตรวจสอบให้แน่ใจว่าคุณมีที่เก็บข้อมูลเพียงพอที่จะดาวน์โหลดและคลายซิปไฟล์:
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh ในการดาวน์โหลดทรัพยากรที่อธิบายไว้ด้านล่างคุณสามารถใช้ download.sh ดังนี้:
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR หรือใช้ download.sh$DATA_DIR หรือใช้ download.sh # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump คุณสามารถใช้โมเดลที่ผ่านการฝึกอบรมมาก่อนจาก HuggingFace Model Hub ชื่อรุ่นใด ๆ ที่เริ่มต้นด้วย princeton-nlp (ที่ระบุใน load_dir ) จะได้รับการแปลโดยอัตโนมัติเป็นรุ่นใน HuggingFace Model Hub ของเรา
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| แบบอย่าง | Query-ft. | NQ | webq | ผู้ที่ได้รับการแต่งตั้ง | เรื่องไม่สำคัญ | ทีม | คำอธิบาย |
|---|---|---|---|---|---|---|---|
| Densephrases-Multi | ไม่มี | 31.9 | 25.5 | 35.7 | 44.4 | 29.3 | em ก่อนที่จะมีการสอบถามใด ๆ |
| Densephrases-Multi-Multi-Multi | หลายรายการ | 40.8 | 35.0 | 48.8 | 53.3 | 34.2 | ใช้สำหรับการสาธิต |
| แบบอย่าง | Query-ft. และประเมิน | em | การทำนาย (ทดสอบ) | คำอธิบาย |
|---|---|---|---|---|
| Densephrases-Multi-Query-NQ | NQ | 41.3 | การเชื่อมโยง | - |
| Densephrases-Multi-Query-WQ | webq | 41.5 | การเชื่อมโยง | - |
| Densephrases-Multi-Query-Trec | ผู้ที่ได้รับการแต่งตั้ง | 52.9 | การเชื่อมโยง | --regex จำเป็นต้องใช้ |
| densephrases-multi-query-tqa | เรื่องไม่สำคัญ | 53.5 | การเชื่อมโยง | - |
| densephrases-multi-query-sqd | ทีม | 34.5 | การเชื่อมโยง | - |
สำคัญ : ทุกรุ่นยกเว้น densephrases-multi นั้นได้รับการปรับแต่งด้านการสอบถามในชุดข้อมูลที่ระบุ (Query-ft.) โดยใช้ดัชนีวลี Densephrases-Multi_wiki-20181220 นอกจากนี้โปรดทราบว่าแบบจำลองที่ผ่านการฝึกอบรมล่วงหน้าของเราเป็นแบบจำลองที่ไวต่อตัวพิมพ์ใหญ่และผลลัพธ์ที่ดีที่สุดจะได้รับเมื่อ --truecase เปิดใช้งานสำหรับการสืบค้นที่ลดลง (เช่น NQ)
densephrases-multi : ฝึกอบรมเกี่ยวกับชุดข้อมูลความเข้าใจที่ไม่น่าเชื่อ (NQ, WebQ, TREC, Triviaqa, Squad)densephrases-multi-query-multi : densephrases-multi Query-side-tuned ปรับแต่งในชุดข้อมูล QA แบบเปิดหลายรายการ (NQ, WebQ, TREC, Triviaqa, Squad)densephrases-multi-query-* : densephrases-multi Query-side-tuned ปรับแต่งในแต่ละชุดข้อมูล QA แบบเปิดโดเมน สำหรับโมเดลที่ผ่านการฝึกอบรมมาก่อนในงานอื่น ๆ (เช่นการเติมสล็อต) ดูตัวอย่าง โปรดทราบว่าโมเดลที่ผ่านการฝึกอบรมมาก่อนส่วนใหญ่เป็นผลลัพธ์ของการปรับแต่งการปรับแต่ง densephrases-multi
spanbert-base-cased-* ) ดาวน์โหลดและคลายซิปภายใต้ $SAVE_DIR หรือใช้ download.sh # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )โปรดทราบว่าคุณไม่จำเป็นต้องดาวน์โหลดดัชนีวลีนี้เว้นแต่คุณต้องการทำงานในระดับวิกิพีเดียเต็มรูปแบบ
$SAVE_DIR หรือใช้ download.shนอกจากนี้เรายังจัดทำดัชนีวลีที่เล็กลงตามการกรองที่ยิ่งใหญ่กว่า (ไม่บังคับ)
ดัชนีขนาดเล็กเหล่านี้ควรอยู่ภายใต้ $SAVE_DIR/densephrases-multi_wiki-20181220/dump/start พร้อมกับดัชนีอื่น ๆ ที่คุณดาวน์โหลด หากคุณใช้ดัชนีวลีที่เล็กกว่าเท่านั้นและไม่ต้องการดาวน์โหลดดัชนีขนาดใหญ่ (74GB) คุณต้องดาวน์โหลดข้อมูลเมตา (20GB) และวางไว้ภายใต้ $SAVE_DIR/densephrases-multi_wiki-20181220/dump Folder ดังแสดงด้านล่าง โครงสร้างของไฟล์ควรมีลักษณะ:
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small ดัชนีวลีทั้งหมดถูกสร้างขึ้นจากโมเดลเดียวกัน ( densephrases-multi ) และคุณสามารถใช้โมเดลที่ผ่านการฝึกอบรมมาก่อนทั้งหมดด้วยดัชนีวลีเหล่านี้ หากต้องการเปลี่ยนดัชนีให้ตั้งค่า index_name (หรือ --index_name ใน densephrases/options.py ) ดังนี้:
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... ) ประสิทธิภาพของ densephrases-multi-query-nq ในคำถามธรรมชาติ (ทดสอบ) ที่มีดัชนีวลีที่แตกต่างกันแสดงอยู่ด้านล่าง
| ดัชนีวลี | Open-Domain QA (EM) | การดึงประโยค (ACC@1/5) | การดึงข้อความ (ACC@1/5) | ขนาด | คำอธิบาย |
|---|---|---|---|---|---|
| 1048576_FLAT_OPQ96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60GB | ประเมินด้วย eval-index-psg |
| 1048576_flat_opq96_medium | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39GB | |
| 1048576_FLAT_OPQ96_SMALL | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20GB |
โปรดทราบว่าความแม่นยำในการดึงข้อความ (ACC@1/5) โดยทั่วไปสูงกว่าตัวเลขที่รายงานในกระดาษเนื่องจากดัชนีวลีเหล่านี้ส่งคืนย่อหน้าธรรมชาติแทนบล็อกข้อความขนาดคงที่ (เช่น 100 คำ)
คุณสามารถเรียกใช้การสาธิตระดับวิกิพีเดียบนเซิร์ฟเวอร์ของคุณเอง สำหรับการสาธิตของคุณเองคุณสามารถเปลี่ยนดัชนีวลี (ได้รับจากที่นี่) หรือตัวเข้ารหัสแบบสอบถาม (เช่นเป็น densephrases-multi-query-nq )
ข้อกำหนดด้านทรัพยากรสำหรับการสาธิตสเกลวิกิพีเดียเต็มรูปแบบคือ:
โปรดทราบว่าคุณไม่จำเป็นต้องใช้ SSD อีกต่อไปเพื่อเรียกใช้การสาธิตซึ่งแตกต่างจากโมเดลการดึงวลีก่อนหน้า (Denspi, Denspi+SPARC) คำสั่งต่อไปนี้ให้บริการการสาธิตเดียวกันกับที่นี่บน http://localhost:51997
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997 โปรดเปลี่ยน --load_dir หรือ --dump_dir หากจำเป็นและลบ --cuda สำหรับเวอร์ชัน CPU เท่านั้น เมื่อคุณตั้งค่าการสาธิตไฟล์บันทึกใน $SAVE_DIR/logs/ จะได้รับการอัปเดตโดยอัตโนมัติเมื่อใดก็ตามที่มีคำถามใหม่เข้ามาคุณยังสามารถส่งแบบสอบถามไปยังเซิร์ฟเวอร์ของคุณโดยใช้คำถามขนาดเล็กสำหรับการอนุมานเร็วขึ้น
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred สำหรับรายละเอียดเพิ่มเติม (เช่นการเปลี่ยนชุดทดสอบ) โปรดดูเป้าหมายใน Makefile ( q-serve , p-serve , eval-demo ฯลฯ )
ในส่วนนี้เราแนะนำขั้นตอนทีละขั้นตอนเพื่อฝึกอบรม densephrases สร้างวลีเวกเตอร์และดัชนีและเรียกใช้การอนุมานด้วยรูปแบบที่ผ่านการฝึกอบรม คำสั่งทั้งหมดของเราที่นี่เป็นเป้าหมายของ Makefile ซึ่งรวมถึงเส้นทางชุดข้อมูลที่แน่นอนการตั้งค่า HyperParameter ฯลฯ
หากการทดสอบต่อไปนี้เสร็จสิ้นโดยไม่มีข้อผิดพลาดหลังจากการติดตั้งและการดาวน์โหลดคุณก็พร้อมที่จะไป!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test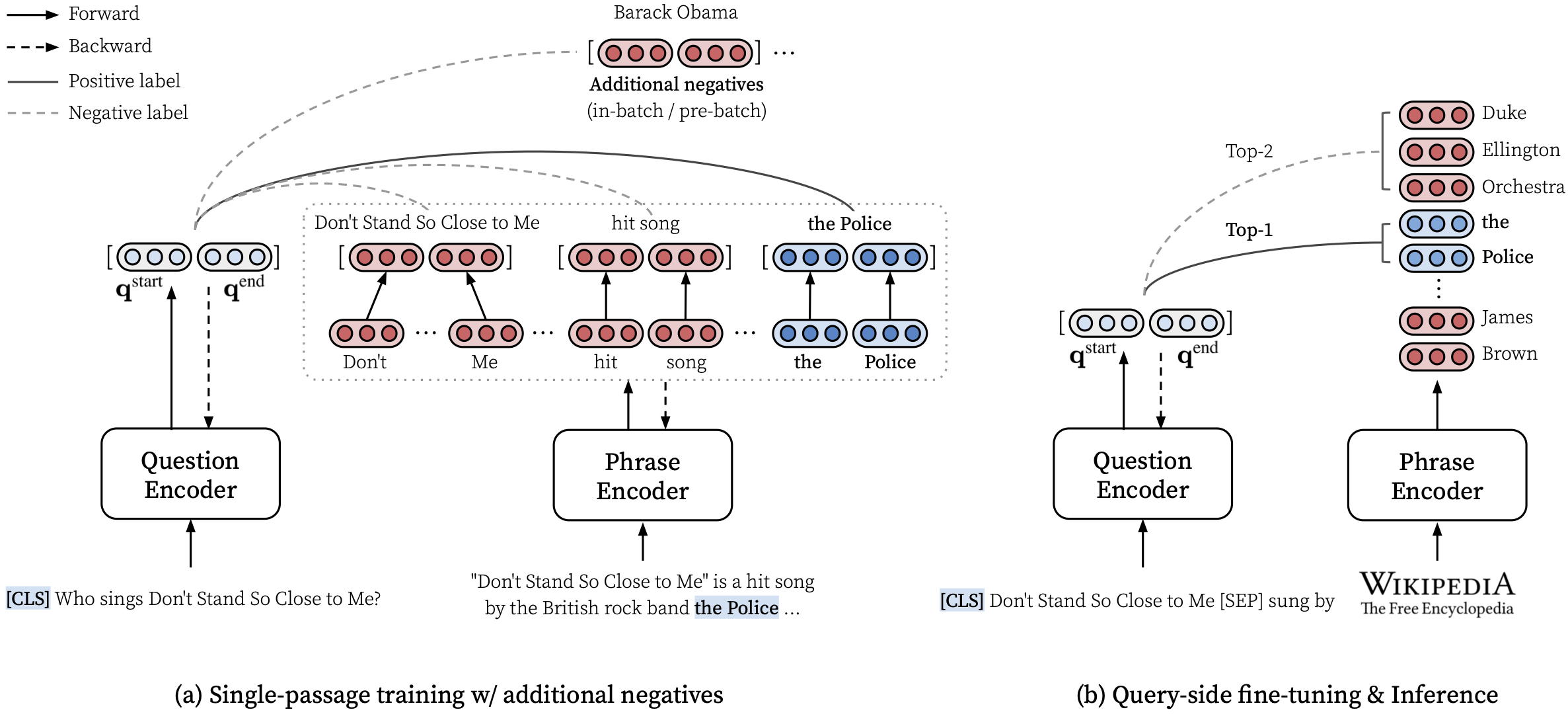
ในการฝึกอบรม densephrases ตั้งแต่เริ่มต้นให้ใช้ run-rc-nq ใน Makefile ซึ่งฝึกอบรม densephrases บน NQ (ประมวลผลล่วงหน้าสำหรับงานการอ่านความเข้าใจ) และประเมินความเข้าใจในการอ่านเช่นเดียวกับ (กึ่ง) เปิดโดเมน QA คุณสามารถเปลี่ยนชุดการฝึกอบรมได้โดยการปรับเปลี่ยนการพึ่งพาของ run-rc-nq (เช่น nq-rc-data => sqd-rc-data และ nq-param => sqd-param สำหรับการฝึกอบรมในทีม) คุณจะต้องใช้ GPU 24GB เดียวสำหรับการฝึกอบรม densephrases ในการอ่านงานความเข้าใจ แต่คุณสามารถใช้ GPU ขนาดเล็กลงได้โดยการตั้งค่า --gradient_accumulation_steps อย่างถูกต้อง
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq ประกอบด้วยหกคำสั่งดังนี้ (ในกรณีของการฝึกอบรมเกี่ยวกับ NQ):
make train-rc ... : รถไฟเดนเซฟราเซสบน NQ กับ Eq 9 (l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg) พร้อมคำถามที่สร้างขึ้นmake train-rc ... : โหลด densephrases ที่ผ่านการฝึกอบรมในขั้นตอนก่อนหน้าและฝึกอบรมเพิ่มเติมด้วย Eq 9 กับเชิงลบแบบพรีแบทช์make gen-vecs : สร้างเวกเตอร์วลีสำหรับ d_small (= ชุดของข้อความทั้งหมดใน nq dev)make index-vecs : สร้างดัชนีวลีสำหรับ D_SMALLmake compress-meta : การบีบอัดข้อมูลเมตาสำหรับการอนุมานที่เร็วขึ้นmake eval-index ... : ประเมินดัชนีวลีเกี่ยวกับคำถามชุดการพัฒนา ในตอนท้ายของขั้นตอนที่ 2 คุณจะเห็นประสิทธิภาพในงานการอ่านความเข้าใจที่ได้รับทางทองคำ (ประมาณ 72.0 EM บน NQ Dev) ขั้นตอนที่ 6 ให้ประสิทธิภาพในการตั้งค่าแบบกึ่งเปิดโดเมน (แสดงเป็น D_SMALL; ดูตารางที่ 6 ในกระดาษ) ซึ่งข้อความทั้งหมดจากชุดพัฒนา NQ ใช้สำหรับการจัดทำดัชนี (ประมาณ 62.0 EM พร้อมคำถาม NQ DEV) รูปแบบที่ผ่านการฝึกอบรมจะถูกบันทึกภายใต้ $SAVE_DIR/$MODEL_NAME โปรดทราบว่าในระหว่างการฝึกอบรมแบบพยากรณ์เดียวบน NQ เราไม่รวมคำถามบางอย่างในชุดการพัฒนาซึ่งพบคำตอบที่มีคำอธิบายประกอบจากรายการหรือตาราง
สมมติว่าคุณมี densephrases ที่ผ่านการฝึกอบรมมาก่อนชื่อ densephrases-multi ซึ่งสามารถดาวน์โหลดได้จากที่นี่ ตอนนี้คุณสามารถสร้างเวกเตอร์วลีสำหรับคลังขนาดใหญ่เช่นวิกิพีเดียโดยใช้ gen-vecs-parallel โปรดทราบว่าคุณสามารถดาวน์โหลดดัชนีวลีสำหรับสเกล Wikipedia เต็มรูปแบบและข้ามส่วนนี้
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8 คลังข้อความเริ่มต้นสำหรับการสร้างวลีเวกเตอร์คือ wiki-dev อยู่ใน $DATA_DIR/wikidump เรามีสามตัวเลือกสำหรับ Corpora ข้อความขนาดใหญ่:
wiki-dev : 1/100 Wikipedia Scale (ตัวอย่าง), 8 ไฟล์wiki-dev-noise : 1/10 Wikipedia Scale (ตัวอย่าง), 500 ไฟล์wiki-20181220 : Scale Wikipedia เต็มรูปแบบ (20181220) ไฟล์ 5621 ไฟล์ wiki-dev* corpora ยังมีข้อความจากชุดการพัฒนา NQ เพื่อให้คุณสามารถติดตามประสิทธิภาพของโมเดลของคุณด้วยขนาดที่เพิ่มขึ้นของคลังข้อความ (โดยปกติจะลดลงเมื่อมันใหญ่ขึ้น) เวกเตอร์วลีจะถูกบันทึกเป็นไฟล์ hdf5 ใน $SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (เช่น $SAVE_DIR/densephrases-multi_wiki-dev/dump ) ซึ่งจะถูกอ้างถึง $DUMP_DIR ด้านล่าง
START และ END ระบุดัชนีไฟล์ในคอร์ปัส (เช่น START=0 END=8 สำหรับ wiki-dev และ START=0 END=5621 สำหรับ wiki-20181220 ) การเรียกใช้ gen-vecs-parallel แต่ละครั้งใช้ 2GB ใน GPU เดียวและคุณสามารถแจกจ่ายกระบวนการด้วย START และ END ที่แตกต่างกันโดยใช้ Slurm หรือ Shell Script (เช่น START=0 END=200 , START=200 END=400 , ... , START=5400 END=5621 ) การแจกจ่าย 28 กระบวนการบน GPU 4GB 4GB (แต่ละการประมวลผลประมาณ 200 ไฟล์) สามารถสร้างวลีเวกเตอร์สำหรับ wiki-20181220 ใน 8 ชั่วโมง การประมวลผล WikiePDIA ทั้งหมดต้องการสูงสุด 500GB และเราขอแนะนำให้ใช้ SSD เพื่อเก็บไว้หากเป็นไปได้ (คลังข้อมูลขนาดเล็กสามารถเก็บไว้ใน HDD)
หลังจากสร้างเวกเตอร์วลีคุณต้องสร้างดัชนีวลีสำหรับการค้นหาวลีเวลา sublinear ที่นี่เราใช้ IVFOPQ สำหรับดัชนีวลี
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ สำหรับ wiki-dev-noise และ wiki-20181220 คุณต้องปรับเปลี่ยนจำนวนกลุ่มเป็น 101,372 และ 1,048,576 ตามลำดับ (เพียงเปลี่ยน medium1-index ใน ìndex-vecs เป็น medium2-index หรือ large-index ) สำหรับ wiki-20181220 (Wikipedia เต็มรูปแบบ) ใช้เวลาประมาณ 1 ~ 2 วันขึ้นอยู่กับข้อกำหนดของเครื่องของคุณและต้องใช้ RAM ประมาณ 100GB สำหรับ IVFSQ ตามที่อธิบายไว้ในกระดาษคุณสามารถใช้ index-add และ index-merge เพื่อแจกจ่ายการเพิ่มวลีเวกเตอร์ไปยังดัชนี
คุณต้องบีบอัดข้อมูลเมตา (บันทึกไว้ในไฟล์ HDF5 พร้อมกับเวกเตอร์วลี) เพื่อการอนุมานที่เร็วขึ้นของ densephrases นี่เป็นข้อบังคับสำหรับดัชนี IVFOPQ
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump สำหรับการประเมินประสิทธิภาพของ densephrases ด้วยดัชนีวลีของคุณให้ใช้ eval-index
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/การปรับจูนแบบสืบค้นทำให้ DENSEPHRASES เป็นเครื่องมืออเนกประสงค์สำหรับการดึงข้อความแบบหลายระดับสำหรับการสืบค้นอินพุตประเภทต่างๆ ในขณะที่การปรับจูนแบบสืบค้นสามารถปรับปรุงประสิทธิภาพในชุดข้อมูล QA ได้ แต่สามารถใช้ในการปรับ densephrases ให้เข้ากับ การสืบค้นอินพุตสไตล์ที่ไม่ใช่ QA เช่น "ความสัมพันธ์ [ก.ย. ]" เพื่อดึงเอนทิตีวัตถุหรือ "ฉันรักเพลงแร็พ" เพื่อดึงเอกสารที่เกี่ยวข้องเกี่ยวกับการแร็พ
ก่อนอื่นคุณต้องใช้ดัชนีวลีสำหรับวิกิพีเดียเต็มรูปแบบ ( wiki-20181220 ) ซึ่งสามารถดาวน์โหลดได้ที่นี่หรือดัชนีวลีที่กำหนดเองตามที่อธิบายไว้ที่นี่ ด้วยการสืบค้นคำตอบหรือคู่สืบค้นของคุณประมวลผลล่วงหน้าเป็นไฟล์ JSON ใน $DATA_DIR/open-qa หรือ $DATA_DIR/kilt คุณสามารถสืบค้นปรับแต่งโมเดลของคุณได้อย่างง่ายดาย ตัวอย่างเช่นชุดการฝึกอบรมของ T-Rex ( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json ) ดูดังนี้:
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
คำสั่งต่อไปนี้คำสั่งแบบสอบถามด้านการปรับแต่ง densephrases-multi บน T-Rex
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ โปรดทราบว่าตัวเข้ารหัสแบบสอบถามที่ผ่านการฝึกอบรมมาก่อนถูกระบุไว้ใน train-query เป็น --load_dir $(SAVE_DIR)/densephrases-multi และรุ่นใหม่จะถูกบันทึกเป็น densephrases-multi-query-trex ตามที่ระบุไว้ใน MODEL_NAME นอกจากนี้คุณยังสามารถฝึกอบรมในชุดข้อมูลที่แตกต่างกันโดยการเปลี่ยน trex-open-data การพึ่งพาเป็น *-open-data (เช่น ay2-kilt-data สำหรับการเชื่อมโยงเอนทิตี)
ด้วยตัวเข้ารหัสแบบสอบถาม Densephrases (เช่น densephrases-multi-query-nq ) และดัชนีวลี (เช่น densephrases-multi_wiki-20181220 ) คุณสามารถทดสอบการสอบถามของคุณได้ดังต่อ --save_pred นี้
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997 สำหรับการประเมินผลในชุดข้อมูลที่แตกต่างกันเพียงแค่เปลี่ยนการพึ่งพา eval-index (หรือ eval-demo ) ตาม (เช่น nq-open-data เป็น trec-open-data สำหรับการประเมินผลของ CuratedTrec)
ที่ด้านล่างของ Makefile เราแสดงรายการคำสั่งที่เราใช้สำหรับการประมวลผลชุดข้อมูลและ Wikipedia ล่วงหน้า สำหรับรูปแบบการสร้างคำถามการฝึกอบรม (T5-LARGE) เราใช้ https://github.com/patil-suraj/question_generation (ดูที่นี่สำหรับ QG) โปรดทราบว่าชุดข้อมูลทั้งหมดได้รับการประมวลผลล่วงหน้าแล้วรวมถึงคำถามที่สร้างขึ้นดังนั้นคุณไม่จำเป็นต้องเรียกใช้สคริปต์เหล่านี้ส่วนใหญ่ สำหรับการสร้างชุดทดสอบสำหรับคำถามที่กำหนดเอง (เปิดโดเมน) ดูที่ preprocess-openqa ใน Makefile
อย่าลังเลที่จะส่งอีเมลถึง Jinhyuk Lee ([email protected]) สำหรับคำถามใด ๆ ที่เกี่ยวข้องกับรหัสหรือกระดาษ คุณยังสามารถเปิดปัญหา GitHub ได้ โปรดพยายามระบุรายละเอียดเพื่อให้เราสามารถเข้าใจและช่วยคุณแก้ปัญหาได้ดีขึ้น
โปรดอ้างถึงกระดาษของเราหากคุณใช้ densephrases ในงานของคุณ:
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}โปรดดูใบอนุญาตสำหรับรายละเอียด


