DensePhrases
1.1.0
시작하기 | Lee et al., ACL 2021 | Lee et al., Emnlp 2021 | 데모 | 참조 | 특허
DensePhrases 는 자연어 입력에 대한 문구, 문장, 구절 또는 문서를 반환 할 수있는 텍스트 검색 모델입니다. Wikipedia 전체의 수십억 개의 조밀 한 문구 벡터를 사용하여 DensePhrases는 실시간으로 질문에 대한 문구 수준의 답변을 검색하거나 다운 스트림 작업을위한 구절을 검색합니다.
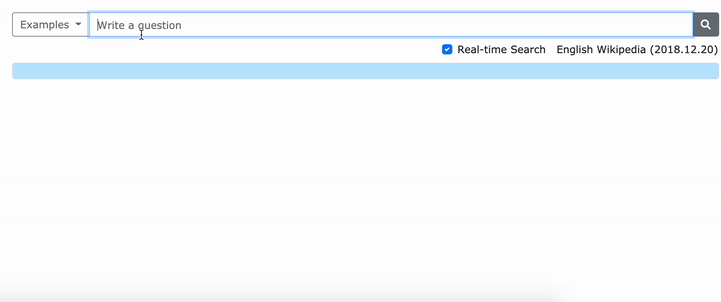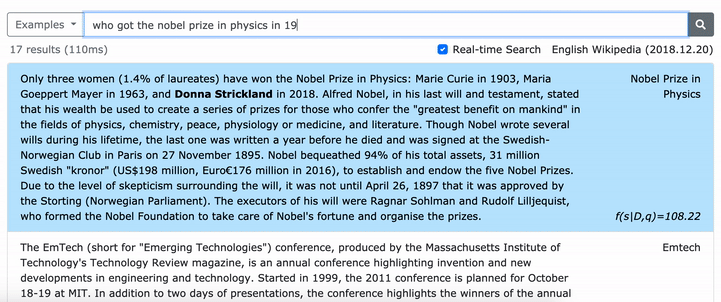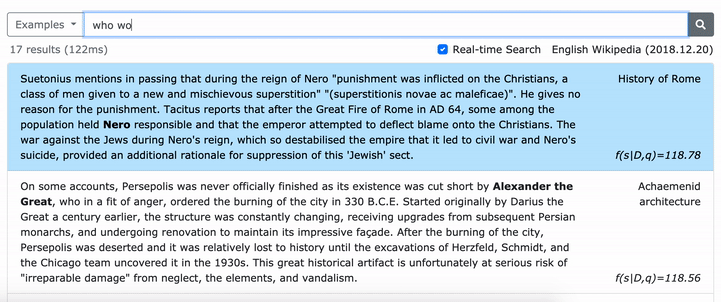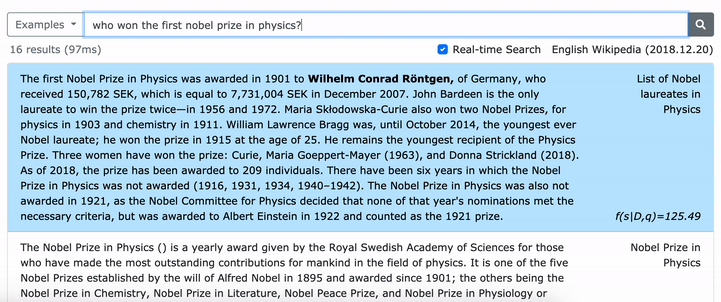
문구의 조밀 한 표현을 배우는 방법에 대한 자세한 내용은 ACL 논문 (규모의 문구를 짙은 표현)을 참조하십시오.
***** 여기에서 DensePhrases의 온라인 데모를 사용해보십시오! ***********
transformers==4.13.0 에 대해 DensePhrases v1.1.0이 출시되었습니다 (참고 참조).densephrases-multi-query-* 의 검정 예측 파일.DensePhrases를 설치하고 구절 인덱스를 Dowload 후에는 쿼리의 문구, 문장, 단락 또는 문서를 쉽게 검색 할 수 있습니다.
CPU 전용 모드 사용, 사용자 정의 색인 생성 등과 같은 더 많은 예는 여기를 참조하십시오.
또한 DensePhrases를 사용하여 주어진 텍스트에 대한 대화 또는 실행 엔터티를 실행하는 관련 문서를 검색 할 수 있습니다.
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]우리는 2021 년 Izacard and Grave의 Fusion-in-Decoder라는 최첨단 오픈 도메인 질문 응답 모델을 훈련시키는 것을 포함하여 더 많은 사례를 제공합니다.
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop main 브랜치는 python==3.7 및 transformers==2.9.0 사용합니다. 다른 버전의 DensePhrases는 아래를 참조하십시오.
| 풀어 주다 | 메모 | 설명 |
|---|---|---|
| v1.0.0 | 링크 | transformers==2.9.0 , main 과 동일합니다 |
| v1.1.0 | 링크 | transformers==4.13.0 |
아래에 필수 파일을 다운로드하기 전에 기본 디렉토리를 다음과 같이 설정하고 파일을 다운로드하여 압축 할 수있는 충분한 스토리지가 있는지 확인하십시오.
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh 아래에 설명 된 리소스를 다운로드하려면 다음과 같이 download.sh 사용할 수 있습니다.
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR 에서 다운로드하고 압축을 풀거나 download.sh 사용하십시오 .SH.$DATA_DIR 에서 다운로드하고 압축을 풀거나 download.sh 사용하십시오 .SH. # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump Huggingface Model Hub에서 미리 훈련 된 모델을 사용할 수 있습니다. princeton-nlp ( load_dir 로 지정 됨)로 시작하는 모든 모델 이름은 Huggingface 모델 허브의 모델로 자동으로 변환됩니다.
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| 모델 | 쿼리 -FT. | NQ | webq | 트렉 | Triviaqa | 분대 | 설명 |
|---|---|---|---|---|---|---|---|
| Densephrases-multi | 없음 | 31.9 | 25.5 | 35.7 | 44.4 | 29.3 | query-ft 전에 em. |
| Densephrases-multi-query-multi | 다수의 | 40.8 | 35.0 | 48.8 | 53.3 | 34.2 | 데모에 사용됩니다 |
| 모델 | 쿼리 -FT. & 평가 | 여자 이름 | 예측 (테스트) | 설명 |
|---|---|---|---|---|
| DENSECHRASES-MULTI-QUERY-NQ | NQ | 41.3 | 링크 | - |
| Densephrases-multi-Query-Wq | webq | 41.5 | 링크 | - |
| Densephrases-multi-query-trec | 트렉 | 52.9 | 링크 | --regex 필수 |
| Densephrases-multi-Query-tqa | Triviaqa | 53.5 | 링크 | - |
| Densephrases-multi-Query-sqd | 분대 | 34.5 | 링크 | - |
중요 : densephrases-multi 제외한 모든 모델은 지수 인덱스 DensePhrases-Multi_wiki-20181220을 사용하여 지정된 데이터 세트 (query-ft.)에서 쿼리 측 미세 조정됩니다. 또한 미리 훈련 된 모델은 사례에 민감한 모델이며, 최상의 결과는 --truecase 낮은 쿼리 (예 : NQ)에 켜져있을 때 얻습니다.
densephrases-multi : Mutiple Reading Pholipension 데이터 세트 (NQ, WebQ, Trec, Triviaqa, Squad)에 대한 교육.densephrases-multi-query-multi : 다중 Open-Domain QA 데이터 세트 (NQ, WebQ, TREC, Triviaqa, Squad)에서 미세 조정 된 densephrases-multi 측면 미세 조정.densephrases-multi-query-* : 각 Open-Domain QA 데이터 세트에서 densephrases-multi -Side 미세 조정. 다른 작업 (예 : 슬롯 필링)에서 미리 훈련 된 모델은 예제를 참조하십시오. 미리 훈련 된 대부분의 모델은 쿼리 사이드 미세 조정 densephrases-multi 의 결과입니다.
spanbert-base-cased-* 포함). $SAVE_DIR 에서 다운로드하고 압축을 풀거나 download.sh 사용하십시오 .SH. # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )전체 Wikipedia 척도에서 작업하지 않으면이 문구 색인을 다운로드 할 필요가 없습니다.
$SAVE_DIR 에서 다운로드하고 압축을 풀거나 download.sh 사용하십시오 .SH.또한보다 적응적인 필터링 (선택 사항)을 기반으로 작은 문구 색인을 제공합니다.
이 작은 인덱스는 $SAVE_DIR/densephrases-multi_wiki-20181220/dump/start 와 함께 다운로드 한 다른 인덱스 아래에 배치해야합니다. 작은 문구 색인 만 사용하고 큰 인덱스 (74GB)를 다운로드하지 않으려면 메타 데이터 (20GB)를 다운로드하여 아래 그림과 같이 $SAVE_DIR/densephrases-multi_wiki-20181220/dump 폴더 아래에 배치해야합니다. 파일의 구조는 다음과 같아야합니다.
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small 모든 문구 인덱스는 동일한 모델 ( densephrases-multi )에서 생성되며 위의 모든 사전 훈련 된 모델을 이러한 문구 인덱스와 함께 사용할 수 있습니다. 인덱스를 변경하려면 다음과 같이 index_name (또는 densephrases/options.py 에서 --index_name )을 설정하십시오.
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... ) 다른 문구 인덱스가있는 자연스러운 질문 (테스트)에 대한 densephrases-multi-query-nq 의 성능은 다음과 같습니다.
| 문구 색인 | 오픈 도메인 QA (EM) | 문장 검색 (ACC@1/5) | 통과 검색 (ACC@1/5) | 크기 | 설명 |
|---|---|---|---|---|---|
| 1048576_FLAT_OPQ96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60GB | eval-index-psg 로 평가 |
| 1048576_flat_opq96_medium | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39GB | |
| 1048576_FLAT_OPQ96_SMALL | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20GB |
구절 검색 정확도 (ACC@1/5)는이 문구 색인이 고정 된 크기의 텍스트 블록 (즉, 100 단어) 대신 자연 단락을 반환하기 때문에 논문의보고 된 숫자보다 일반적으로 높습니다.
자신의 서버에서 Wikipedia-Scale 데모를 실행할 수 있습니다. 자신의 데모의 경우 문구 인덱스 (여기에서 얻은) 또는 쿼리 인코더 (예 : densephrases-multi-query-nq )로 변경할 수 있습니다.
전체 Wikipedia Scale 데모를 실행하기위한 자원 요구 사항은 다음과 같습니다.
이전 문구 검색 모델 (denspi, denspi+sparc)과 달리 데모를 실행하기 위해 더 이상 SSD가 필요하지 않습니다. 다음 명령은 http://localhost:51997 에서와 정확히 동일한 데모를 제공합니다.
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997 필요한 경우 --load_dir 또는 --dump_dir 를 변경하고 CPU 전용 버전의 경우 --cuda 제거하십시오. 데모를 설정하면 새로운 질문이 들어올 때마다 $SAVE_DIR/logs/ 의 로그 파일이 자동으로 업데이트됩니다. 더 빠른 추론을 위해 미니 배치의 질문을 사용하여 서버에 쿼리를 보낼 수도 있습니다.
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred 자세한 내용은 (예 : 테스트 세트 변경) Makefile ( q-serve , p-serve , eval-demo 등)의 대상을 참조하십시오.
이 섹션에서는 헤이스 프레이즈를 훈련시키고, 문구 벡터 및 인덱스를 만들고, 훈련 된 모델로 추론을 실행하는 단계별 절차를 도입합니다. 여기의 모든 명령은 정확한 데이터 세트 경로, 하이퍼 파라미터 설정 등을 포함하는 Makefile 대상으로 단순화됩니다.
설치 및 다운로드 후 오류없이 다음 테스트 실행이 완료되면 가면 좋습니다.
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test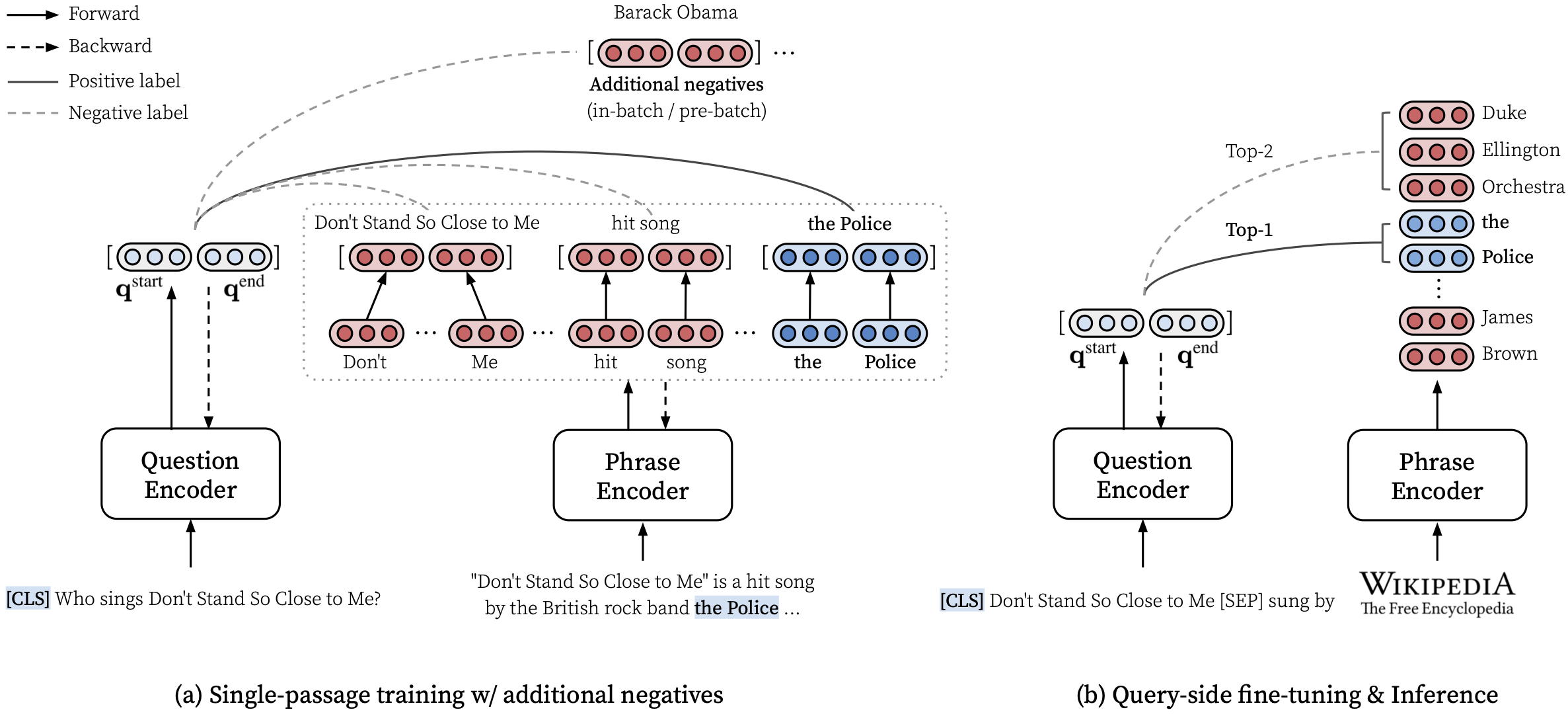
처음부터 밀도를 훈련 시키려면 Makefile 에서 run-rc-nq 사용하여 NQ (읽기 이해 작업을 위해 사전 처리)를 훈련시키고 (Semi) Open-Domain QA뿐만 아니라 독해에 대한 평가를 평가하십시오. run-rc-nq 의 종속성 (예 : nq-rc-data => sqd-rc-data 및 nq-param => sqd-param 분대 훈련)으로 수정하여 설정을 변경할 수 있습니다). 독해력을 읽는 데있어 헤이스 프레이즈를 훈련시키기 위해서는 단일 24GB GPU가 필요하지만 --gradient_accumulation_steps 올바르게 설정하여 더 작은 GPU를 사용할 수 있습니다.
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq 다음과 같이 6 개의 명령으로 구성됩니다 (NQ에 대한 교육의 경우) :
make train-rc ... : NQ에서 Eq. 생성 된 질문과 함께 9 (l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg).make train-rc ... : 이전 단계에서 훈련 된 고밀도를로드하고 Eq. 사전 배치 네거티브가있는 9.make gen-vecs : d_small에 대한 문구 벡터를 생성하십시오 (= NQ Dev의 모든 구절 세트).make index-vecs : D_SMALL에 대한 문구 인덱스를 구축하십시오.make compress-meta : 더 빠른 추론을 위해 메타 데이터를 압축합니다.make eval-index ... : 개발 세트 질문에 대한 문구 색인을 평가하십시오. 2 단계가 끝나면 금 통로가 제공되는 독해 작업의 성능 (NQ Dev에서 약 72.0 EM)을 볼 수 있습니다. 6 단계는 NQ 개발 세트의 전체 구절이 인덱싱에 사용되는 (NQ DEV 질문의 약 62.0 EM)에 사용되는 반 오펜 도메인 설정 (D_SMALL로 표시; 논문의 표 6 참조)에서 성능을 제공합니다. 훈련 된 모델은 $SAVE_DIR/$MODEL_NAME 아래에 저장됩니다. NQ에 대한 단일 패스 훈련 중에는 개발 세트에서 몇 가지 질문을 제외하고 목록이나 테이블에서 주석이 달린 답변이 발견됩니다.
densephrases-multi 라는 미리 훈련 된 큐브라스가 있다고 가정 해 봅시다. 여기에서 다운로드 할 수도 있습니다. 이제 gen-vecs-parallel 사용하여 Wikipedia와 같은 대규모 코퍼스에 대한 문구 벡터를 생성 할 수 있습니다. 전체 Wikipedia 척도에 대한 문구 인덱스를 다운로드 하고이 섹션을 건너 뛸 수 있습니다.
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8 문구 벡터 생성을위한 기본 텍스트 코퍼스는 $DATA_DIR/wikidump 에 위치한 wiki-dev 입니다. 더 큰 텍스트 Corpora에 대한 세 가지 옵션이 있습니다.
wiki-dev : 1/100 Wikipedia Scale (샘플링), 8 파일wiki-dev-noise : 1/10 Wikipedia Scale (샘플링), 500 파일wiki-20181220 : Full Wikipedia (20181220) 스케일, 5621 파일 wiki-dev* Corpora에는 NQ 개발 세트의 통로도 포함되어있어 텍스트 코퍼스의 크기가 증가함에 따라 모델의 성능을 추적 할 수 있습니다 (일반적으로 더 커짐에 따라 감소). 문구 벡터는 $SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (예 : $SAVE_DIR/densephrases-multi_wiki-dev/dump )의 HDF5 파일로 저장되며 아래 $DUMP_DIR 참조합니다.
START 및 END 코퍼스에서 파일 인덱스를 지정합니다 (예 : wiki-dev 의 경우 START=0 END=8 , wiki-20181220 의 경우 START=0 END=5621 ). gen-vecs-parallel 의 각 실행은 단일 GPU에서 2GB 만 소비하며 Slurm 또는 쉘 스크립트를 사용하여 START 및 END 로 프로세스를 분배 할 수 있습니다 (예 : START=0 END=200 , START=200 END=400 , ..., START=5400 END=5621 ). 44GB GPU에 28 개의 프로세스를 배포하면 (약 200 개의 파일 약 200 파일) wiki-20181220 에 대한 문구 벡터를 8 시간 안에 생성 할 수 있습니다. WikiePdia 전체를 처리하려면 최대 500GB가 필요하며 SSD를 사용하여 가능한 경우 저장하는 것이 좋습니다 (작은 코퍼스는 HDD에 저장할 수 있음).
문구 벡터를 생성 한 후에는 문구의 하위 시간 검색을위한 문구 색인을 만들어야합니다. 여기서는 문구 인덱스에 IVFOPQ를 사용합니다.
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ wiki-dev-noise 및 wiki-20181220 의 경우 클러스터 수를 각각 101,372 및 1,048,576으로 수정해야합니다 (간단히 medium1-index ìndex-vecs medium2-index 또는 large-index 로 변경하십시오). wiki-20181220 (Full Wikipedia)의 경우 기계의 사양에 따라 약 1 ~ 2 일이 걸리며 약 100GB RAM이 필요합니다. 논문에 설명 된대로 IVFSQ의 경우 index-add 및 index-merge 사용하여 인덱스 벡터의 추가를 인덱스에 배포 할 수 있습니다.
또한 밀도가 높을 수있는 더 빠른 추론을 위해 메타 데이터 (HDF5 파일에 구절 벡터와 함께 저장)를 압축해야합니다. 이것은 IVFOPQ 지수의 필수입니다.
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump 문구 인덱스로 빽빽한 표준의 성능을 평가하려면 eval-index 사용하십시오.
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/쿼리 측 미세 조정은 DensePhrases가 다양한 유형의 입력 쿼리에 대한 다중 부문 텍스트를 검색하기위한 다양한 도구입니다. 쿼리 측 미세 조정은 QA 데이터 세트의 성능을 향상시킬 수 있지만 객체 엔티티를 검색하거나 "I Love Rap Music"을 검색하기 위해 "대상 [SEP] 관계"와 같은 비 QA 스타일의 입력 쿼리 에 옥수수를 조정하는 데 사용할 수 있습니다. 랩핑시 관련 문서를 검색합니다.
먼저, 여기에서 간단히 다운로드 할 수있는 전체 위키 백과 ( wiki-20181220 )에 대한 문구 색인이 필요하거나 여기에 설명 된대로 사용자 정의 문구 색인이 필요합니다. query-answer 또는 query-document 쌍이 $DATA_DIR/open-qa 또는 $DATA_DIR/kilt 의 JSON 파일로 사전 처리 된 쿼리-문서 쌍을 감안할 때 모델을 쉽게 쿼리 할 수 있습니다. 예를 들어, t-rex ( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json )의 교육 세트는 다음과 같이 보입니다.
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
다음 명령은 t-rex에서 Query-side fine densephrases-multi .
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ 사전 훈련 된 쿼리 인코더는 train-query 에 --load_dir $(SAVE_DIR)/densephrases-multi 로 지정되며 새로운 모델은 MODEL_NAME 에 지정된대로 densephrases-multi-query-trex 로 저장됩니다. 또한 종속성 trex-open-data *-open-data (예 : 엔터티 링크의 ay2-kilt-data )로 변경하여 다른 데이터 세트를 교육 할 수도 있습니다.
DensePhrases Query 인코더 (예 : densephrases-multi-query-nq ) 및 문구 인덱스 (예 : densephrases-multi_wiki-20181220 )를 사용하면 다음과 같이 쿼리를 테스트 할 수 있으며 검색 결과는 --save_pred 옵션으로 JSON 파일로 저장됩니다.
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997 다른 데이터 세트에 대한 평가의 경우, 그에 따라 eval-index (또는 eval-demo )의 종속성을 변경하십시오 (예 : CuratedTrec에 대한 평가를 위해 nq-open-data 에서 trec-open-data ).
Makefile 의 하단에는 데이터 세트 및 Wikipedia를 사전 처리하는 데 사용한 명령을 나열합니다. 교육 질문 생성 모델 (T5-Large)의 경우 https://github.com/patil-suraj/question_generation을 사용했습니다 (QG 참조). 모든 데이터 세트는 생성 된 질문을 포함하여 이미 사전 처리되었으므로 이러한 스크립트의 대부분을 실행할 필요가 없습니다. Custom (Open-Domain) 질문에 대한 테스트 세트를 작성하려면 Makefile 의 preprocess-openqa 참조하십시오.
코드 나 논문과 관련된 질문은 Jinhyuk Lee ([email protected]) 에게 이메일을 보내주십시오. GitHub 문제를 열 수도 있습니다. 문제를 더 잘 이해하고 해결할 수 있도록 세부 사항을 지정하십시오.
작업에서 빽빽한 표현을 사용하는 경우 신문을 인용하십시오.
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}자세한 내용은 라이센스를 참조하십시오.


