DensePhrases
1.1.0
Erste Schritte | Lee et al., ACL 2021 | Lee et al., EMNLP 2021 | Demo | Referenzen | Lizenz
Denphrasen ist ein Text -Abrufmodell, mit dem Phrasen, Sätze, Passagen oder Dokumente für Ihre natürlichen Spracheingaben zurückgegeben werden können. Mithilfe von Milliarden dichten Ausdrucksvektoren aus der gesamten Wikipedia sucht Denphrasen in Echtzeit die Antworten auf Ihre Fragen auf Ihre Fragen oder holt Passagen nach nachgelagerten Aufgaben ab.
In unserem ACL-Papier (lerndichte Darstellungen von Phrasen in Maßstab) finden Sie Einzelheiten zum Erlernen dichter Darstellungen von Phrasen und dem EMNLP-Papier (Phrase Abruf lernt auch Passage Abruf), wie man Multi-Granularity-Abruf durchführt.
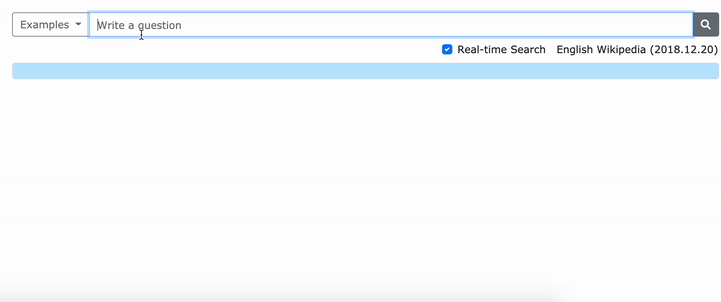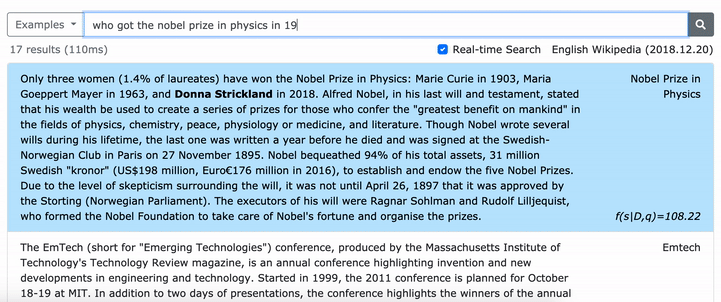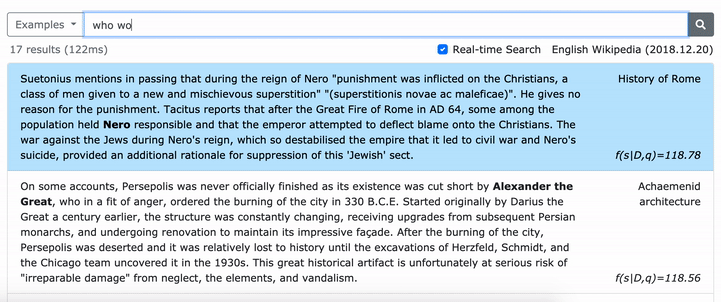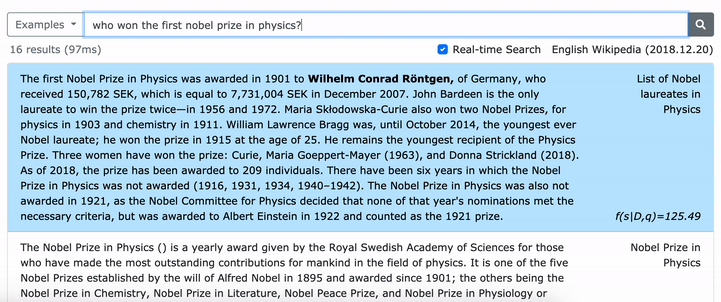
***** Probieren Sie hier unsere Online -Demo von Denphrasen aus! *****
transformers==4.13.0 (siehe Anmerkungen).densephrases-multi-query-* hinzu.Nach der Installation von DiSphrasen und Dowload eines Phrase -Index können Sie problemlos Phrasen, Sätze, Absätze oder Dokumente für Ihre Abfrage abrufen.
Weitere Beispiele wie die Verwendung der CPU-Modus, das Erstellen eines benutzerdefinierten Index und mehr finden Sie unter Verwendung von CPU-Modus.
Sie können auch Denphrasen verwenden, um relevante Dokumente für einen Dialog abzurufen oder eine Entität ausführen, die über bestimmte Texte verlinkt.
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]Wir geben weitere Beispiele an, darunter die Schulung eines hochmodernen Fragen zur Beantwortung von Fragen zur Beantwortung des Fusion-in-Decoders von Izacard und Grave, 2021.
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop main verwendet python==3.7 und transformers==2.9.0 . Weiter unten finden Sie andere Versionen von Denphrasen.
| Freigeben | Notiz | Beschreibung |
|---|---|---|
| v1.0.0 | Link | transformers==2.9.0 , wie main |
| v1.1.0 | Link | transformers==4.13.0 |
Vor dem Herunterladen der erforderlichen Dateien unten legen Sie bitte die Standardverzeichnisse wie folgt fest und stellen Sie sicher, dass Sie über genügend Speicherplatz verfügen, um die Dateien herunterzuladen und zu öffnen:
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh Um die unten beschriebenen Ressourcen herunterzuladen, können Sie download.sh wie folgt verwenden:
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR herunter und entpacken Sie es oder verwenden Sie download.sh .$DATA_DIR herunter und entpacken Sie es oder verwenden Sie download.sh . # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump Sie können vorgebildete Modelle aus dem Hubface-Modell-Hub verwenden. Jeder Modellname, der mit princeton-nlp beginnt (angegeben in load_dir ), wird automatisch als Modell in unserem Hubface-Modell-Hub übersetzt.
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| Modell | Abfrage. | Nq | Webq | TREC | Triviaqa | Kader | Beschreibung |
|---|---|---|---|---|---|---|---|
| Denphrasen-Multi | Keiner | 31.9 | 25,5 | 35.7 | 44.4 | 29.3 | Em vor einem Abfrage-ft. |
| Denphrasen-Multi-Query-Multi | Mehrere | 40.8 | 35.0 | 48,8 | 53.3 | 34.2 | Für Demo verwendet |
| Modell | Abfrage. & Eval | Em | Vorhersage (Test) | Beschreibung |
|---|---|---|---|---|
| Denphrasen-Multi-Query-NQ | Nq | 41.3 | Link | - - |
| Denphrasen-Multi-Query-WQ | Webq | 41,5 | Link | - - |
| Denphrasen-Multi-Query-Trec | TREC | 52.9 | Link | --regex erforderlich |
| Denphrasen-Multi-Query-TQA | Triviaqa | 53,5 | Link | - - |
| Denphrasen-Multi-Query-SQD | Kader | 34.5 | Link | - - |
WICHTIG : Alle Modelle mit Ausnahme von densephrases-multi werden mit dem angegebenen Datensatz (Query-Fft) fein abgestimmt mit dem Phrase-Index-Denphrasen-Multi_Wiki-20181220. Beachten Sie auch, dass unsere vorgebreiteten Modelle Fall-sensitive Modelle sind und die besten Ergebnisse erzielt werden, wenn --truecase für alle niedrigeren Abfragen (z. B. NQ) eingeschaltet ist.
densephrases-multi : Ausgebildet in mutiple Leseverständnisdatensätzen (NQ, Webq, TREC, Triviaqa, Squad).densephrases-multi-query-multi : densephrases-multi -Abfragen, die auf mehreren QA-Datensätzen mit offener Domänen abgestimmt sind (NQ, Webq, Trec, Triviaqa, Squad).densephrases-multi-query-* : densephrases-multi -Abfragen, die auf jedem QA-Datensatz mit offenem Domänen abgestimmt sind. Für vorgebrachte Modelle in anderen Aufgaben (z. B. Slotfüllung) siehe Beispiele. Beachten Sie, dass die meisten vorgebreiteten Modelle die Ergebnisse der feinstunten-dichtphrasen densephrases-multi Fine-Side-Seite sind.
spanbert-base-cased-* ). Laden Sie es unter $SAVE_DIR herunter und entpacken Sie es oder verwenden Sie download.sh . # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )Bitte beachten Sie, dass Sie diesen Phrase -Index nicht herunterladen müssen, es sei denn, Sie möchten an der vollständigen Wikipedia -Skala arbeiten.
$SAVE_DIR herunter und entpacken Sie es oder verwenden Sie download.sh .Wir bieten auch kleinere Phrase -Indizes an, die auf einer aggressiveren Filterung basieren (optional).
Diese kleineren Indizes sollten unter $SAVE_DIR/densephrases-multi_wiki-20181220/dump/start zusammen mit anderen von Ihnen heruntergeladenen Indizes platziert werden. Wenn Sie nur einen kleineren Phrase-Index verwenden und den großen Index (74 GB) nicht herunterladen möchten, müssen Sie Metadaten (20 GB) herunterladen und unter $SAVE_DIR/densephrases-multi_wiki-20181220/dump Ordner wie unten gezeigt platzieren. Die Struktur der Dateien sollte aussehen wie:
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small Alle Phrase-Indizes werden aus demselben Modell ( densephrases-multi ) erstellt, und Sie können alle oben ausgebildeten Modelle mit einem dieser Phrasenindizes verwenden. Um den Index zu ändern, setzen Sie einfach index_name (oder --index_name in densephrases/options.py ) wie folgt fest:
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... ) Die Leistung von densephrases-multi-query-nq zu natürlichen Fragen (Test) mit unterschiedlichen Phrase-Indexen ist unten gezeigt.
| Phrasenindex | Open-Domain-QA (EM) | Satzabruf (ACC@1/5) | Durchgangsabnahme (ACC@1/5) | Größe | Beschreibung |
|---|---|---|---|---|---|
| 1048576_flat_opq96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60 GB | bewertet mit eval-index-psg |
| 1048576_flat_opq96_medium | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39 GB | |
| 1048576_flat_opq96_small | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20 GB |
Beachten Sie, dass die Genauigkeit des Durchgangsabrufs (ACC@1/5) im Allgemeinen höher ist
Sie können die Demo im Wikipedia-Maßstab auf Ihrem eigenen Server ausführen. Für Ihre eigene Demo können Sie den Phrase-Index (erhalten von hier aus) oder den Abfrage-Encoder (z. B. in densephrases-multi-query-nq ) ändern.
Die Ressourcenanforderung für die Ausführung der vollständigen Demo der Wikipedia Scale lautet:
Beachten Sie, dass Sie keine SSD mehr benötigen, um die Demo im Gegensatz zu früheren Phrasen -Abrufmodellen (Denspi, Denspi+SPARC) auszuführen. Die folgenden Befehle dienen genau der gleichen Demo wie hier auf Ihrem http://localhost:51997 .
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997 Bitte ändern Sie --load_dir oder --dump_dir falls erforderlich, und entfernen Sie --cuda für CPU-Version. Sobald Sie die Demo eingerichtet haben, werden die Protokolldateien in $SAVE_DIR/logs/ werden automatisch aktualisiert, wenn eine neue Frage eingeht. Sie können auch Abfragen an Ihren Server mit Mini-Stapeln von Fragen für eine schnellere Inferenz senden.
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred Weitere Informationen (z. B. das Ändern des Testsatzes) finden Sie in den Zielen in Makefile ( q-serve , p-serve , eval-demo usw.).
In diesem Abschnitt führen wir ein schrittweise Verfahren ein, um Denphrasen zu trainieren, Phrase-Vektoren und -Indexe zu erstellen und mit dem geschulten Modell Schlussfolgerungen durchzuführen. Alle unsere Befehle hier werden als Makefile -Ziele vereinfacht, die genaue Datensatzpfade, Hyperparametereinstellungen usw. enthalten.
Wenn der folgende Testlauf nach der Installation und dem Download ohne Fehler abgeschlossen ist, können Sie loslegen!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test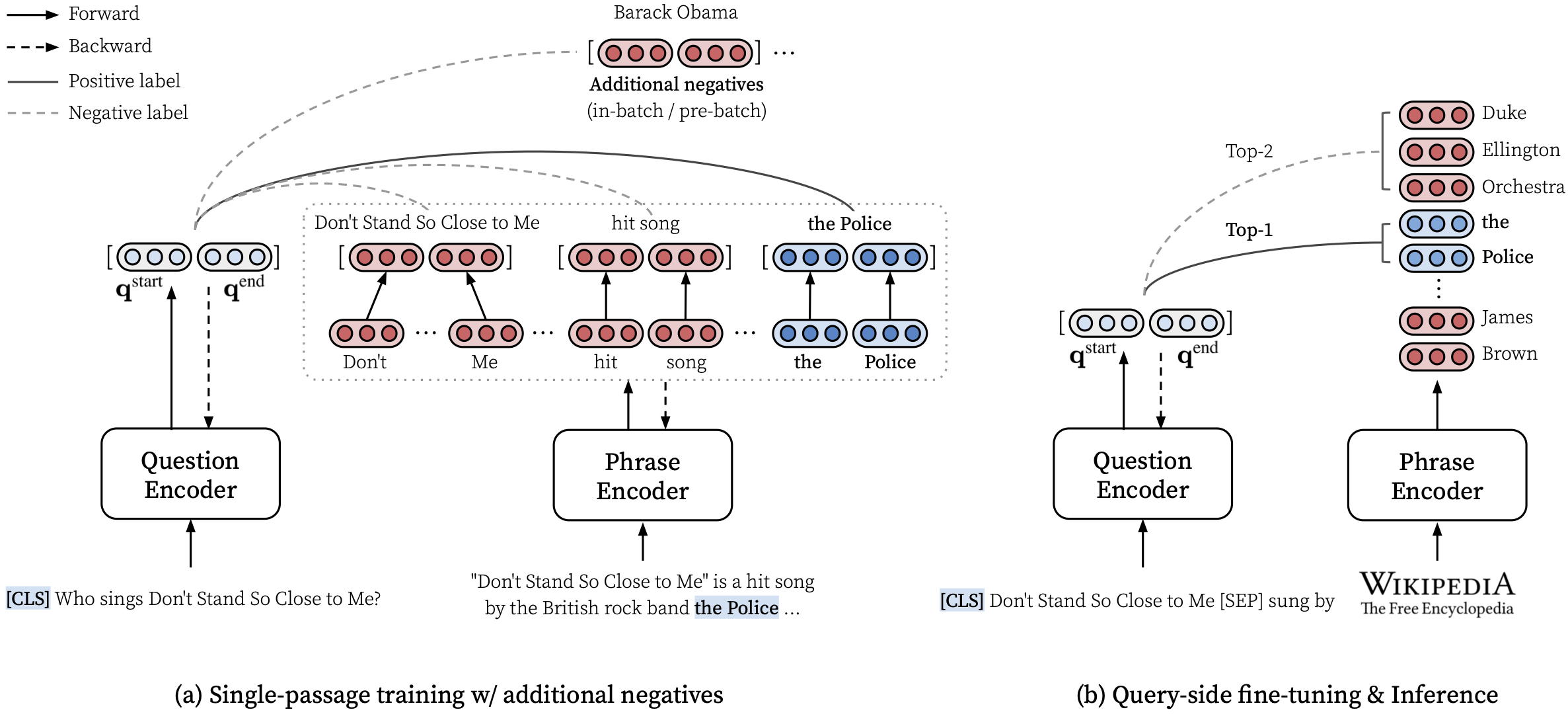
Verwenden Sie run-rc-nq in Makefile , der Denphrasen auf NQ (vorverarbeitet für die Leseverständnisaufgabe), um Denphrasen von Grund auf neu zu trainieren, und bewerten Sie sie auf Leseverständnis sowie auf (semi) Open-Domain-QA. Sie können einfach den Trainingssatz ändern, indem Sie die Abhängigkeiten von run-rc-nq (EG, nq-rc-data => sqd-rc-data und nq-param => sqd-param für das Training am Kader) ändern. Sie benötigen eine einzelne 24 -GB -GPU für Schulungsdichtungspflichten bei Leseverständnisaufgaben. Sie können jedoch kleinere GPUs durch Einstellen verwenden --gradient_accumulation_steps ordnungsgemäß.
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq besteht aus den sechs Befehlen wie folgt (im Falle eines Trainings auf NQ):
make train-rc ... : Zug-Denphrasen auf NQ mit Gl. 9 (l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg) mit generierten Fragen.make train-rc ... : Last trainierte DiSphrasen im vorherigen Schritt und fährt es mit Gl. 9 mit Negativen vor dem Batch.make gen-vecs : Erzeugen Sie Phrase-Vektoren für D_Small (= Satz aller Passagen in NQ Dev).make index-vecs : Erstellen Sie einen Phrase-Index für D_Small.make compress-meta : Kompress-Metadaten für eine schnellere Folgerung.make eval-index ... : Bewerten Sie den Phrase-Index auf den Entwicklungssatzfragen. Am Ende von Schritt 2 sehen Sie die Aufführung der Leseverständnisaufgabe, bei der eine Goldpassage angegeben wird (ca. 72,0 EM auf NQ Dev). Schritt 6 gibt die Leistung in der Semi-Open-Domain-Einstellung (als d_small bezeichnet; siehe Tabelle 6 im Papier), wobei die gesamten Passagen aus dem NQ-Entwicklungssatz für die Indizierung verwendet werden (ca. 62,0 em mit NQ Dev-Fragen). Das geschulte Modell wird unter $SAVE_DIR/$MODEL_NAME gespeichert. Beachten Sie, dass wir während des Einzelpassage-Trainings auf NQ einige Fragen im Entwicklungssatz ausschließen, deren kommentierte Antworten aus einer Liste oder einer Tabelle stammen.
Nehmen wir an, Sie haben überdichtes Denphrasen mit dem Namen densephrases-multi , das auch von hier aus heruntergeladen werden kann. Jetzt können Sie Phrase-Vektoren für einen groß angelegten Korpus wie Wikipedia unter Verwendung von gen-vecs-parallel erzeugen. Beachten Sie, dass Sie einfach den Phrase -Index für die vollständige Wikipedia -Skala herunterladen und diesen Abschnitt überspringen können.
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8 Der Standardtextkorpus zum Erstellen von Phrasenvektoren ist wiki-dev in $DATA_DIR/wikidump . Wir haben drei Optionen für größere Textkorpora:
wiki-dev : 1/100 Wikipedia Scale (abgetastet), 8 Dateienwiki-dev-noise : 1/10 Wikipedia-Skala (abgetastet), 500 Dateienwiki-20181220 : Full Wikipedia (20181220) Skala, 5621 Dateien Die wiki-dev* -Korpora enthalten auch Passagen aus dem NQ-Entwicklungssatz, sodass Sie die Leistung Ihres Modells mit einer zunehmenden Größe des Textkorpus verfolgen können (normalerweise nimmt es ab, wenn es größer wird). Die Phrase-Vektoren werden als HDF5-Dateien in $SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (z. B. $SAVE_DIR/densephrases-multi_wiki-dev/dump ) gespeichert, das unten auf $DUMP_DIR verwiesen wird.
START und END geben den Dateiindex im Korpus an (z. B. START=0 END=8 für wiki-dev und START=0 END=5621 für wiki-20181220 ). Jeder Lauf von gen-vecs-parallel verbraucht nur 2 GB in einer einzelnen GPU, und Sie können die Prozesse mit unterschiedlichem START und END mit Slurm oder Shell-Skript verteilen (z. B. START=0 END=200 , START=200 END=400 , ..., START=5400 END=5621 ). Das Verteilern von 28 Prozessen auf 4 24 GB GPUs (jeweils etwa 200 Dateien) kann in 8 Stunden Ausdrucksvektoren für wiki-20181220 erstellen. Die Verarbeitung der gesamten Wikiepdia erfordert bis zu 500 GB. Wir empfehlen, eine SSD zu verwenden, um sie nach Möglichkeit zu speichern (ein kleinerer Korpus kann in einer Festplatte gespeichert werden).
Nachdem Sie die Phrasenvektoren generiert haben, müssen Sie einen Phrase -Index für die Sublinear -Zeit -Suche nach Phrasen erstellen. Hier verwenden wir IVFOPQ für den Phrase -Index.
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ Für wiki-dev-noise und wiki-20181220 müssen Sie die Anzahl der Cluster auf 101.372 bzw. 1.048.576 ändern (einfach mit medium1-index in ìndex-vecs auf medium2-index oder large-index ) ändern. Für wiki-20181220 (Vollwikipedia) dauert dies je nach Spezifikation Ihrer Maschine ca. ~ 2 Tage und benötigt etwa 100 GB RAM. Für IVFSQ, wie im Papier beschrieben, können Sie index-add und index-merge verwenden, um die Zugabe von Phrasenvektoren an den Index zu verteilen.
Sie müssen auch die Metadaten (in HDF5 -Dateien zusammen mit Phrasenvektoren gespeichert) für eine schnellere Schlussfolgerung dichtem Phrasen komprimieren. Dies ist für den IVFOPQ -Index obligatorisch.
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump Verwenden Sie eval-index zur Bewertung der Leistung von Denphrasen mit Ihren Phrasenindizes.
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/Die Feinabstimmung mit Abfragen macht Denphrasen zu einem vielseitigen Tool zum Abrufen von Multi-Granularity-Text für verschiedene Arten von Eingabebestarten. Während die Feinabstimmung mit Abfragen auch die Leistung in QA-Datensätzen verbessern kann, kann sie verwendet werden, um Denphrasen nicht an Nicht-QA-Style-Eingänge wie "Subjekt [SEP] -Relation" anzupassen, um Objekteinheiten abzurufen oder "Ich liebe Rap-Musik". Relevante Dokumente zum Rappen abrufen.
Erstens benötigen Sie einen Phrase-Index für die vollständige Wikipedia ( wiki-20181220 ), die einfach hier heruntergeladen werden kann, oder einen benutzerdefinierten Phrase-Index, wie hier beschrieben. Angesichts Ihrer Abfrage- oder Abfrage-Dokumentpaare, die als JSON-Dateien in $DATA_DIR/open-qa oder $DATA_DIR/kilt vorverarbeitet sind, können Sie Ihr Modell problemlos fein abfragen. Zum Beispiel sieht der Trainingssatz von T-Rex ( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json ) wie folgt aus:
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
Die folgenden Befehlsabfragen mit Feinstunten- densephrases-multi auf T-Rex.
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Beachten Sie, dass der vorgeborene Abfrage-Encoder in train-query als --load_dir $(SAVE_DIR)/densephrases-multi angegeben ist und ein neues Modell als densephrases-multi-query-trex wie in MODEL_NAME angegeben, gespeichert wird. Sie können auch an verschiedenen Datensätzen trainieren, indem Sie die trex-open-data in *-open-data (z. B. ay2-kilt-data für die Entitätsverbindung) ändern.
Bei allen Denphrasen-Abfragecodierern (z. B. densephrases-multi-query-nq densephrases-multi_wiki-20181220 und einem Phrase --save_pred Index (z.
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997 Ändern Sie für die Bewertung an verschiedenen Datensätzen einfach die Abhängigkeit von eval-index (oder eval-demo ) entsprechend (z. B. nq-open-data zu trec-open-data für die Bewertung auf kuratiertemTrec).
Am Ende von Makefile haben wir Befehle aufgeführt, die wir zur Vorverarbeitung der Datensätze und Wikipedia verwendet haben. Für Trainingsfragegerzeugungsmodelle (T5-Large) haben wir https://github.com/patil-suraj/question_generation verwendet (siehe auch hier für QG). Beachten Sie, dass alle Datensätze bereits vorverarbeitet sind, einschließlich der generierten Fragen, sodass Sie die meisten dieser Skripte nicht ausführen müssen. Informationen zum Erstellen von Testsätzen für benutzerdefinierte (Open-Domain) -fragen finden Sie preprocess-openqa in Makefile .
Senden Sie sich gerne eine E -Mail an Jinhyuk Lee ([email protected]) für Fragen im Zusammenhang mit dem Code oder dem Papier. Sie können auch ein GitHub -Problem öffnen. Bitte versuchen Sie, die Details anzugeben, damit wir das Problem besser verstehen und helfen können.
Bitte zitieren Sie unser Papier, wenn Sie in Ihrer Arbeit DiSphrasen verwenden:
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}Bitte beachten Sie die Lizenz für Details.


