DensePhrases
1.1.0
Memulai | Lee et al., ACL 2021 | Lee et al., EMNLP 2021 | Demo | Referensi | Lisensi
Densefrases adalah model pengambilan teks yang dapat mengembalikan frasa, kalimat, bagian, atau dokumen untuk input bahasa alami Anda. Menggunakan miliaran vektor frasa padat dari seluruh wikipedia, densephrases mencari jawaban tingkat frase untuk pertanyaan Anda secara real-time atau mengambil bagian untuk tugas hilir.
Silakan lihat makalah ACL kami (mempelajari representasi frasa yang padat pada skala) untuk perincian tentang cara mempelajari representasi frasa yang padat dan kertas EMNLP (pengambilan frase belajar pengambilan bagian, juga) tentang cara melakukan pengambilan multi-granularitas.
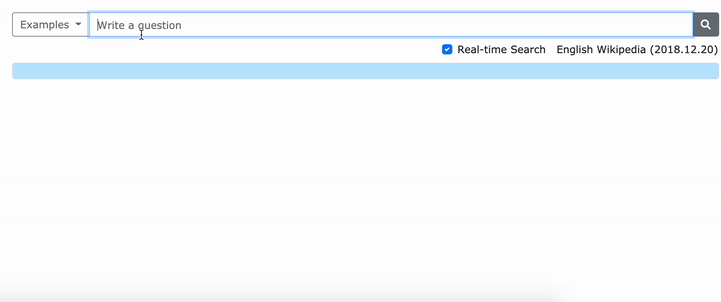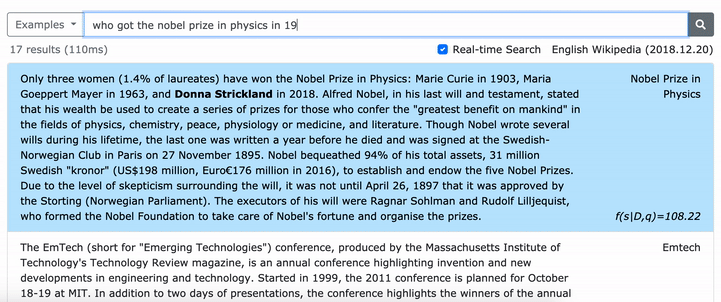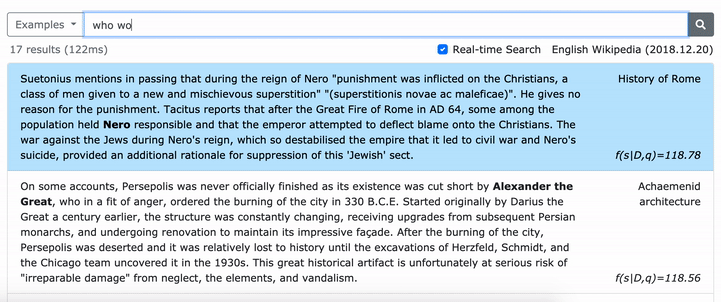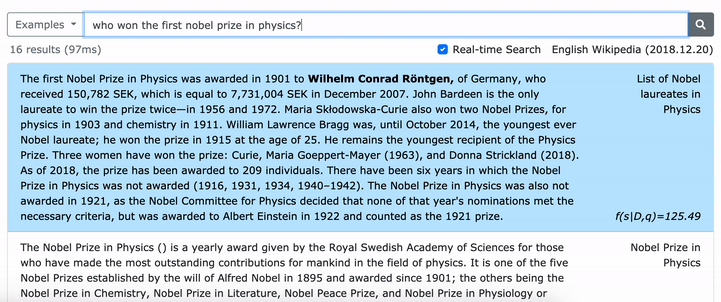
***** Cobalah demo densephrases online kami di sini! *****
transformers==4.13.0 (lihat catatan).densephrases-multi-query-* ditambahkan.Setelah memasang densephrases dan memuat indeks frasa, Anda dapat dengan mudah mengambil frasa, kalimat, paragraf, atau dokumen untuk pertanyaan Anda.
Lihat di sini untuk lebih banyak contoh seperti menggunakan mode CPU-only, membuat indeks khusus, dan banyak lagi.
Anda juga dapat menggunakan densephrases untuk mengambil dokumen yang relevan untuk dialog atau menjalankan entitas yang menghubungkan teks yang diberikan.
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]Kami memberikan lebih banyak contoh, yang mencakup melatih model menjawab pertanyaan domain terbuka yang disebut fusion-in-decoder oleh Izacard dan Grave, 2021.
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop Cabang main menggunakan python==3.7 dan transformers==2.9.0 . Lihat di bawah untuk versi Densefrases lainnya.
| Melepaskan | Catatan | Keterangan |
|---|---|---|
| v1.0.0 | link | transformers==2.9.0 , sama seperti main |
| v1.1.0 | link | transformers==4.13.0 |
Sebelum mengunduh file yang diperlukan di bawah ini, silakan atur direktori default sebagai berikut dan pastikan Anda memiliki cukup penyimpanan untuk mengunduh dan membuka ritsleting file:
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh Untuk mengunduh sumber daya yang dijelaskan di bawah ini, Anda dapat menggunakan download.sh sebagai berikut:
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR atau gunakan download.sh .$DATA_DIR atau gunakan download.sh . # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump Anda dapat menggunakan model pra-terlatih dari Huggingface Model Hub. Nama model apa pun yang dimulai dengan princeton-nlp (ditentukan dalam load_dir ) akan secara otomatis diterjemahkan sebagai model di hub model HuggingFace kami.
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| Model | Query-ft. | Nq | Webq | Trec | Triviaqa | Pasukan | Keterangan |
|---|---|---|---|---|---|---|---|
| densephrases-multi | Tidak ada | 31.9 | 25.5 | 35.7 | 44.4 | 29.3 | Mereka sebelum kueri-ft. |
| Densefrases-Multi-Query-Multi | Banyak | 40.8 | 35.0 | 48.8 | 53.3 | 34.2 | Digunakan untuk demo |
| Model | Query-ft. & Evaluasi | Em | Prediksi (tes) | Keterangan |
|---|---|---|---|---|
| densephrases-multi-query-nq | Nq | 41.3 | link | - |
| Densefrases-Multi-Query-WQ | Webq | 41.5 | link | - |
| Densefrases-Multi-Query-Trec | Trec | 52.9 | link | --regex diperlukan |
| Densefrases-Multi-Query-tqa | Triviaqa | 53.5 | link | - |
| Densefrases-Multi-Query-Sqd | Pasukan | 34.5 | link | - |
Penting : Semua model kecuali densephrases-multi disesuaikan dengan sisi kueri yang disesuaikan pada dataset yang ditentukan (Query-Ft.) Menggunakan frase indeks densephrases-multi_wiki-20181220. Perhatikan juga bahwa model pra-terlatih kami adalah model case-sensitive dan hasil terbaik diperoleh ketika --truecase aktif untuk pertanyaan yang lebih rendah (misalnya, NQ).
densephrases-multi : Didatih Dataset Pemahaman Bacaan Mutiple (NQ, WebQ, TREC, Triviaqa, Skuad).densephrases-multi-query-multi : densephrases-multi Query-Side Fine-Tuned pada beberapa dataset QA domain terbuka (NQ, WebQ, TREC, Triviaqa, Squad).densephrases-multi-query-* : densephrases-multi Query-side-side disesuaikan pada setiap dataset QA domain terbuka. Untuk model pra-terlatih dalam tugas lain (misalnya, pengisian slot), lihat contoh. Perhatikan bahwa sebagian besar model pra-terlatih adalah hasil dari densephrases-multi -tuning-side-side-tuning-tuning.
spanbert-base-cased-* ). Unduh dan unzip di bawah $SAVE_DIR atau gunakan download.sh . # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )Harap dicatat bahwa Anda tidak perlu mengunduh indeks frasa ini kecuali Anda ingin bekerja pada skala Wikipedia lengkap.
$SAVE_DIR atau gunakan download.sh .Kami juga menyediakan indeks frasa yang lebih kecil berdasarkan penyaringan yang lebih agresif (opsional).
Indeks yang lebih kecil ini harus ditempatkan di bawah $SAVE_DIR/densephrases-multi_wiki-20181220/dump/start bersama dengan indeks lain yang Anda unduh. Jika Anda hanya menggunakan indeks frasa yang lebih kecil dan tidak ingin mengunduh indeks besar (74GB), Anda perlu mengunduh metadata (20GB) dan menempatkannya di bawah $SAVE_DIR/densephrases-multi_wiki-20181220/dump folder seperti yang ditunjukkan di bawah ini. Struktur file seharusnya terlihat seperti:
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small Semua indeks frasa dibuat dari model yang sama ( densephrases-multi ) dan Anda dapat menggunakan semua model pra-terlatih di atas dengan salah satu dari indeks frasa ini. Untuk mengubah indeks, cukup atur index_name (atau --index_name di densephrases/options.py ) sebagai berikut:
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... ) Kinerja densephrases-multi-query-nq pada pertanyaan alami (uji) dengan indeks frasa yang berbeda ditunjukkan di bawah ini.
| Indeks frasa | Qa domain terbuka (em) | Pengambilan Kalimat (ACC@1/5) | Pengambilan bagian (ACC@1/5) | Ukuran | Keterangan |
|---|---|---|---|---|---|
| 1048576_flat_opq96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60GB | dievaluasi dengan eval-index-psg |
| 1048576_flat_opq96_medium | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39GB | |
| 1048576_flat_opq96_small | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20GB |
Perhatikan bahwa akurasi pengambilan bagian (ACC@1/5) umumnya lebih tinggi dari angka yang dilaporkan dalam makalah karena frase ini mengandalkan paragraf alami alih-alih blok teks berukuran tetap (yaitu, 100 kata).
Anda dapat menjalankan demo skala Wikipedia di server Anda sendiri. Untuk demo Anda sendiri, Anda dapat mengubah indeks frasa (diperoleh dari sini) atau encoder kueri (misalnya, menjadi densephrases-multi-query-nq ).
Persyaratan sumber daya untuk menjalankan demo skala Wikipedia penuh adalah:
Perhatikan bahwa Anda tidak lagi membutuhkan SSD untuk menjalankan demo tidak seperti model pengambilan frasa sebelumnya (Denspi, Denspi+SPARC). Perintah berikut melayani demo yang persis sama seperti di sini di http://localhost:51997 .
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997 Harap ubah --load_dir atau --dump_dir jika perlu dan hapus --cuda untuk versi CPU saja. Setelah Anda mengatur demo, file log di $SAVE_DIR/logs/ akan diperbarui secara otomatis setiap kali pertanyaan baru masuk. Anda juga dapat mengirim kueri ke server Anda menggunakan mini-batch pertanyaan untuk inferensi yang lebih cepat.
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred Untuk detail lebih lanjut (misalnya, mengubah set tes), silakan lihat target di Makefile ( q-serve , p-serve , eval-demo , dll).
Di bagian ini, kami memperkenalkan prosedur langkah demi langkah untuk melatih densephrases, membuat vektor dan indeks frasa, dan menjalankan kesimpulan dengan model terlatih. Semua perintah kami di sini disederhanakan sebagai target Makefile , yang mencakup jalur dataset yang tepat, pengaturan hiperparameter, dll.
Jika tes berikut selesai selesai tanpa kesalahan setelah instalasi dan unduhan, Anda baik untuk pergi!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test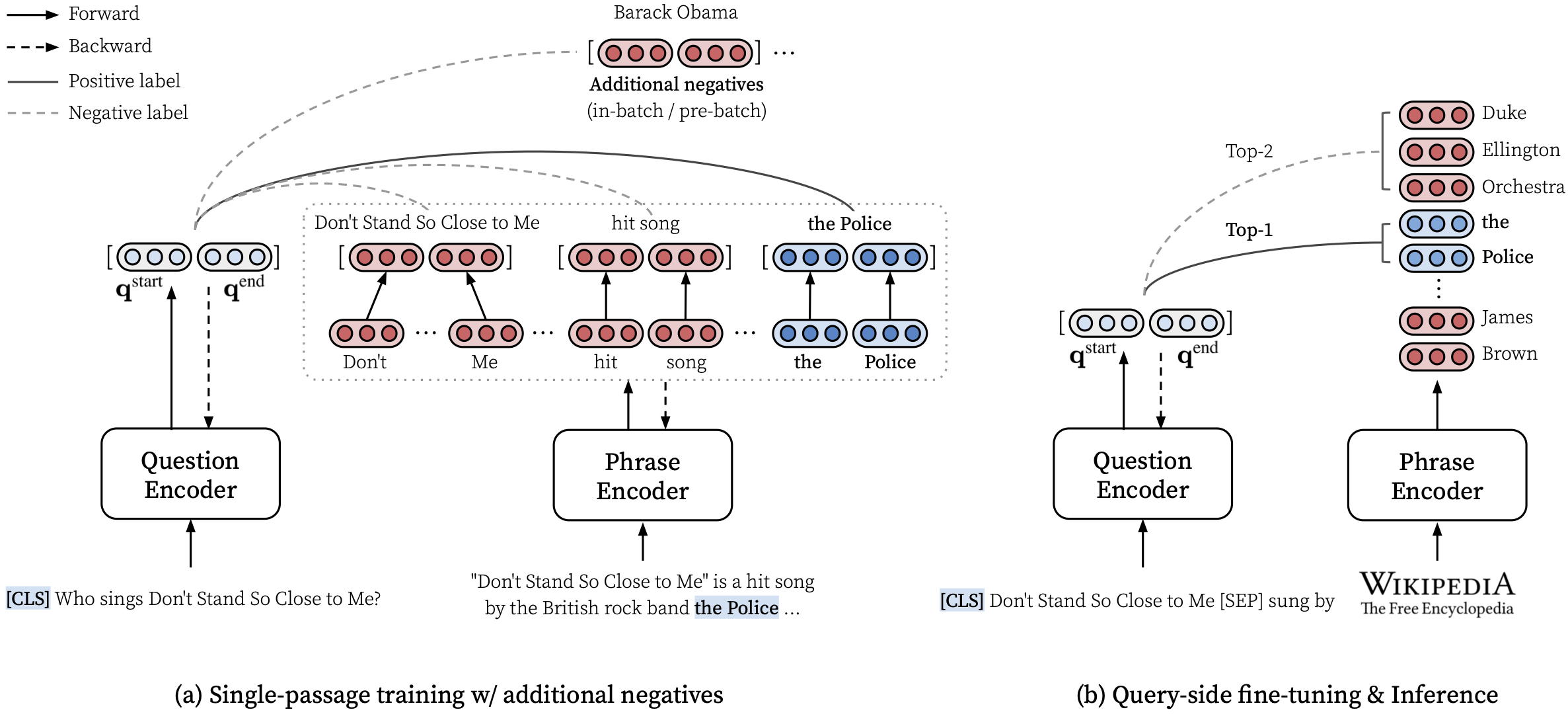
Untuk melatih densephrases dari awal, gunakan run-rc-nq di Makefile , yang melatih densefrass pada NQ (pra-diproses untuk tugas pemahaman membaca) dan mengevaluasinya pada pemahaman membaca serta pada (semi) QA domain terbuka (semi). Anda dapat dengan mudah mengubah set pelatihan dengan memodifikasi dependensi run-rc-nq (misalnya, nq-rc-data => sqd-rc-data dan nq-param => sqd-param untuk pelatihan pada skuad). Anda akan memerlukan GPU 24GB tunggal untuk pelatihan densephrases pada tugas pemahaman membaca, tetapi Anda dapat menggunakan GPU yang lebih kecil dengan mengatur --gradient_accumulation_steps dengan benar.
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq terdiri dari enam perintah sebagai berikut (dalam kasus pelatihan tentang NQ):
make train-rc ... : Densephrases kereta pada NQ dengan Persamaan. 9 (l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg) dengan pertanyaan yang dihasilkan.make train-rc ... : Muat densephrases terlatih di langkah sebelumnya dan lebih lanjut latih dengan Persamaan. 9 dengan negatif pra-batch.make gen-vecs : Hasilkan vektor frasa untuk d_small (= set semua bagian dalam NQ Dev).make index-vecs : Bangun indeks frasa untuk d_small.make compress-meta : Compress metadata untuk inferensi yang lebih cepat.make eval-index ... : Evaluasi indeks frasa pada pertanyaan yang ditetapkan pengembangan. Pada akhir langkah 2, Anda akan melihat kinerja pada tugas pemahaman membaca di mana bagian emas diberikan (sekitar 72,0 em pada nq dev). Langkah 6 memberikan kinerja pada pengaturan semi-terbuka (dilambangkan sebagai d_small; lihat Tabel 6 di koran) di mana seluruh bagian dari set pengembangan NQ digunakan untuk pengindeksan (sekitar 62,0 EM dengan pertanyaan NQ Dev). Model terlatih akan disimpan di bawah $SAVE_DIR/$MODEL_NAME . Perhatikan bahwa selama pelatihan satu passage di NQ, kami mengecualikan beberapa pertanyaan dalam set pengembangan, yang jawaban beranotasi ditemukan dari daftar atau tabel.
Mari kita asumsikan bahwa Anda memiliki densefrases terlatih bernama densephrases-multi , yang juga dapat diunduh dari sini. Sekarang, Anda dapat menghasilkan vektor frase untuk corpus skala besar seperti Wikipedia menggunakan gen-vecs-parallel . Perhatikan bahwa Anda dapat mengunduh indeks frasa untuk skala Wikipedia lengkap dan melewatkan bagian ini.
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8 Korpus teks default untuk membuat vektor frasa adalah wiki-dev yang terletak di $DATA_DIR/wikidump . Kami memiliki tiga opsi untuk korpora teks yang lebih besar:
wiki-dev : 1/100 Wikipedia Scale (Sampled), 8 filewiki-dev-noise : 1/10 Wikipedia Scale (Sampled), 500 filewiki-20181220 : Skala Wikipedia penuh (20181220), 5621 file wiki-dev* corpora juga berisi bagian-bagian dari set pengembangan NQ, sehingga Anda dapat melacak kinerja model Anda dengan peningkatan ukuran corpus teks (biasanya berkurang karena semakin besar). Vektor frasa akan disimpan sebagai file HDF5 di $SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (mis., $SAVE_DIR/densephrases-multi_wiki-dev/dump ), yang akan disebut $DUMP_DIR di bawah.
START dan END Tentukan indeks file dalam corpus (misalnya, START=0 END=8 untuk wiki-dev dan START=0 END=5621 untuk wiki-20181220 ). Setiap menjalankan gen-vecs-parallel hanya mengkonsumsi 2GB dalam satu GPU tunggal, dan Anda dapat mendistribusikan proses dengan START dan END yang berbeda menggunakan skrip slurm atau shell (misalnya, START=0 END=200 , START=200 END=400 , ..., START=5400 END=5621 ). Mendistribusikan 28 proses pada 4 24GB GPU (masing-masing memproses sekitar 200 file) dapat membuat vektor frasa untuk wiki-20181220 dalam 8 jam. Memproses seluruh wikiepdia membutuhkan hingga 500GB dan kami sarankan menggunakan SSD untuk menyimpannya jika memungkinkan (korpus yang lebih kecil dapat disimpan dalam HDD).
Setelah menghasilkan vektor frasa, Anda perlu membuat indeks frasa untuk pencarian frasa waktu sublinear. Di sini, kami menggunakan IVFOPQ untuk indeks frasa.
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ Untuk wiki-dev-noise dan wiki-20181220 , Anda perlu memodifikasi jumlah cluster menjadi 101.372 dan 1.048.576, masing-masing (cukup mengubah medium1-index di ìndex-vecs ke medium2-index atau large-index ). Untuk wiki-20181220 (Wikipedia penuh), ini membutuhkan waktu sekitar 1 ~ 2 hari tergantung pada spesifikasi mesin Anda dan membutuhkan sekitar 100GB RAM. Untuk IVFSQ seperti yang dijelaskan dalam makalah, Anda dapat menggunakan index-add dan index-merge untuk mendistribusikan penambahan vektor frase ke indeks.
Anda juga perlu mengompres metadata (disimpan dalam file HDF5 bersama dengan vektor frasa) untuk inferensi densephrases yang lebih cepat. Ini wajib untuk indeks IVFOPQ.
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump Untuk mengevaluasi kinerja densephrases dengan indeks frasa Anda, gunakan eval-index .
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/Fine-tuning sisi kueri menjadikan densephrases alat serba guna untuk mengambil teks multi-granularitas untuk berbagai jenis kueri input. Sementara fine-tuning sisi kueri juga dapat meningkatkan kinerja pada kumpulan data QA, ini dapat digunakan untuk mengadaptasi densefrass dengan kueri input gaya non-QA seperti "Subjek [Sep] relasi" untuk mengambil entitas objek atau "Saya suka musik rap." Untuk mengambil dokumen yang relevan tentang rap.
Pertama, Anda memerlukan indeks frasa untuk wikipedia lengkap ( wiki-20181220 ), yang dapat dengan mudah diunduh di sini, atau indeks frasa khusus seperti yang dijelaskan di sini. Mengingat pasangan kueri atau dokumen kueri Anda yang telah diproses sebelumnya sebagai file JSON di $DATA_DIR/open-qa atau $DATA_DIR/kilt , Anda dapat dengan mudah meminta fine-tune model Anda. Misalnya, set pelatihan T-Rex ( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json ) terlihat sebagai berikut:
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
Command fine-side-fine-tunes densephrases-multi pada T-rex.
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Perhatikan bahwa encoder kueri pra-terlatih ditentukan dalam train-query sebagai --load_dir $(SAVE_DIR)/densephrases-multi dan model baru akan disimpan sebagai densephrases-multi-query-trex seperti yang ditentukan dalam MODEL_NAME . Anda juga dapat melatih pada dataset yang berbeda dengan mengubah ketergantungan trex-open-data menjadi *-open-data (misalnya, ay2-kilt-data untuk tautan entitas).
Dengan densephrases kueri encoder (misalnya, densephrases-multi-query-nq ) dan indeks frasa (misalnya, densephrases-multi_wiki-20181220 ), Anda dapat menguji pertanyaan Anda sebagai berikut dan hasil pengambilan akan disimpan sebagai file JSON dengan opsi --save_pred : SAVE_PRED:
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997 Untuk evaluasi pada dataset yang berbeda, cukup ubah ketergantungan eval-index (atau eval-demo ) yang sesuai (misalnya, nq-open-data menjadi trec-open-data untuk evaluasi pada CuratedTrec).
Di bagian bawah Makefile , kami mencantumkan perintah yang kami gunakan untuk pra-pemrosesan dataset dan wikipedia. Untuk model pembuatan pertanyaan pelatihan (T5-Large), kami menggunakan https://github.com/patil-suraj/question_generation (lihat juga di sini untuk QG). Perhatikan bahwa semua dataset sudah diproses sebelumnya termasuk pertanyaan yang dihasilkan, sehingga Anda tidak perlu menjalankan sebagian besar skrip ini. Untuk membuat set tes untuk pertanyaan khusus (domain terbuka), lihat preprocess-openqa di Makefile .
Jangan ragu untuk mengirim email ke Jinhyuk Lee ([email protected]) untuk setiap pertanyaan yang terkait dengan kode atau kertas. Anda juga dapat membuka masalah GitHub. Silakan coba tentukan detailnya sehingga kami dapat lebih memahami dan membantu Anda menyelesaikan masalah.
Harap kutip makalah kami jika Anda menggunakan densephrases dalam pekerjaan Anda:
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}Silakan lihat lisensi untuk detailnya.


