DensePhrases
1.1.0
Начало работы | Lee et al., ACL 2021 | Lee et al., Emnlp 2021 | Демо | Ссылки | Лицензия
DensePhrase - это модель поиска текста, которая может возвращать фразы, предложения, отрывки или документы для вашего естественного языка. Используя миллиарды плотных фразовых векторов из всей Википедии, DensePhrase ищут ответы на уровне фразы на ваши вопросы в режиме реального времени или извлекает отрывки для задач по нижней части.
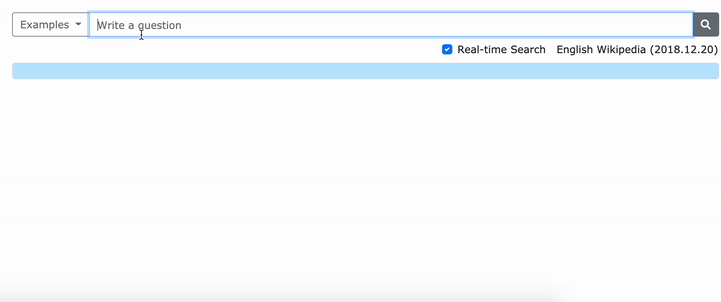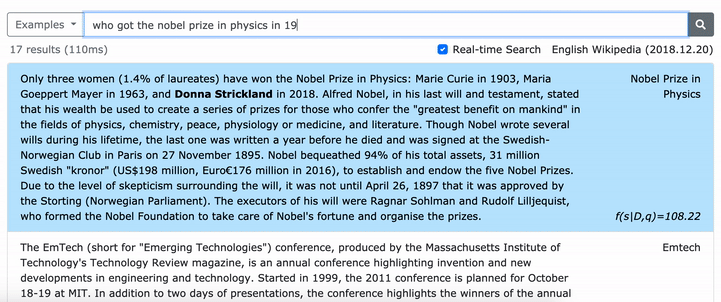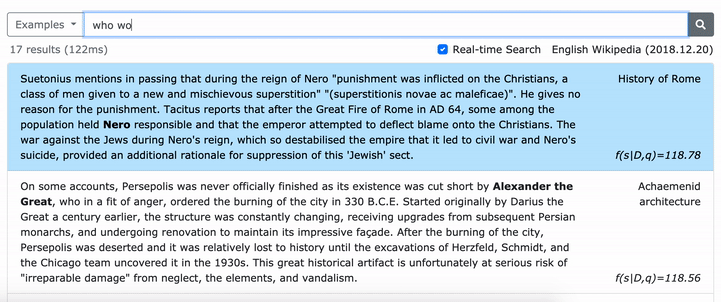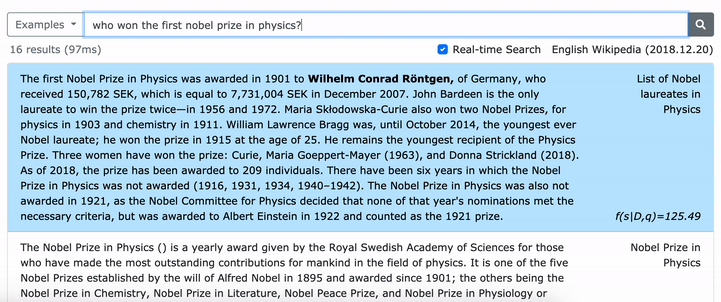
Пожалуйста, смотрите нашу статью ACL (изучение плотных представлений о фразах в масштабе) для получения подробной информации о том, как изучить плотные представления о фразах и статьи EMNLP (поиск фразы также изучает отрывок) о том, как выполнить многочисленную поиск.
***** Попробуйте нашу онлайн -демонстрацию DensePhrase здесь! *****
transformers==4.13.0 (см. Примечания).densephrases-multi-query-* добавлены.После установки DensePhrase и при загрузке индекса фразы вы можете легко получить фразы, предложения, абзацы или документы для вашего запроса.
См. Здесь для получения дополнительных примеров, таких как использование режима только для процессора, создание пользовательского индекса и многое другое.
Вы также можете использовать DensePhrase для получения соответствующих документов для диалога или запуска организации, связывающегося с данными текстами.
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]Мы приводим больше примеров, которые включают обучение современной модели ответа на вопросы с открытым доменом, называемой Fusion-In-Decoder от Izacard и Grave, 2021.
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop main ветвь использует python==3.7 и transformers==2.9.0 . См. Ниже для других версий DensePhrase.
| Выпускать | Примечание | Описание |
|---|---|---|
| v1.0.0 | связь | transformers==2.9.0 , то же самое, что и main |
| v1.1.0 | связь | transformers==4.13.0 |
Перед загрузкой необходимых файлов ниже, пожалуйста, установите каталоги по умолчанию следующим образом и убедитесь, что у вас достаточно хранилища для загрузки и распаковки файлов:
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh Чтобы загрузить ресурсы, описанные ниже, вы можете использовать download.sh следующим образом:
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIR или используйте download.sh .$DATA_DIR или используйте download.sh . # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidump Вы можете использовать предварительно обученные модели из концентратора модели HuggingFace. Любое имя модели, которое начинается с princeton-nlp (указано в load_dir ), будет автоматически переведено как модель в нашем концентраторе модели HuggingFaceface.
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| Модель | Query-ft. | Н.К. | WebQ | Трек | Витривиака | Отряд | Описание |
|---|---|---|---|---|---|---|---|
| DensePhrase-Multi | Никто | 31.9 | 25,5 | 35,7 | 44,4 | 29.3 | Эм перед каким-либо запросом-футом. |
| DensePhrase-Multi-Query-Multi | Несколько | 40,8 | 35,0 | 48.8 | 53,3 | 34.2 | Используется для демонстрации |
| Модель | Query-ft. & Eval | ЭМ | Прогноз (тест) | Описание |
|---|---|---|---|---|
| DensePhrase-Multi-Query-NQ | Н.К. | 41.3 | связь | - |
| DensePhrase-Multi-Query-wq | WebQ | 41,5 | связь | - |
| DensePhrase-Multi-Query-Trec | Трек | 52,9 | связь | --regex требуется |
| DensePhrase-Multi-Query-TQA | Витривиака | 53,5 | связь | - |
| DensePhrase-Multi-Query-Sqd | Отряд | 34,5 | связь | - |
ВАЖНО : Все модели, кроме densephrases-multi находятся на стороне запроса на указанный набор данных (Query-ft.) Используя фразовый индекс DensePhrase-Multi_wiki-20181220. Также обратите внимание, что наши предварительно обученные модели являются чувствительными к случаям моделей, а наилучшие результаты получаются, когда- --truecase для любых более низких запросов (например, NQ).
densephrases-multi : обучен наборам данных по пониманию прочитанного мельницы (NQ, WebQ, TREC, Triviaqa, Squad).densephrases-multi-query-multi : densephrases-multi -запрос, настраиваемый на несколько наборов данных QA с открытым доменом (NQ, WebQ, TREC, Triviaqa, Squad).densephrases-multi-query-* : densephrases-multi -запрос, настраиваемый в каждом наборе данных QA с открытым доменом. Для предварительно обученных моделей в других задачах (например, наполнение слотов) см. Примеры. Обратите внимание, что большинство предварительно обученных моделей являются результатами точно настраиваемой настройки densephrases-multi .
spanbert-base-cased-* ). Загрузите и разканитесь по $SAVE_DIR или используйте download.sh . # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )Обратите внимание, что вам не нужно скачать этот индекс фразы, если вы не хотите работать над полной шкалой Википедии.
$SAVE_DIR или используйте download.sh .Мы также предоставляем более мелкие фразовые индексы, основанные на более агрессивной фильтрации (необязательно).
Эти меньшие индексы должны быть размещены под $SAVE_DIR/densephrases-multi_wiki-20181220/dump/start вместе с любыми другими загруженными вами индексами. Если вы используете только меньший индекс фразы и не хотите загружать большой индекс (74 ГБ), вам необходимо загрузить метаданные (20 ГБ) и поместить его под папку $SAVE_DIR/densephrases-multi_wiki-20181220/dump как показано ниже. Структура файлов должна выглядеть как:
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_small Все индексы фразы создаются из одной и той же модели ( densephrases-multi ), и вы можете использовать все предварительно обученные модели с любым из этих фразовых индексов. Чтобы изменить индекс, просто установите index_name (или --index_name в densephrases/options.py ) следующим образом:
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... ) Производительность densephrases-multi-query-nq на естественных вопросах (тест) с различными фразовыми индексами показана ниже.
| Фразовый индекс | QA (EM) с открытым доменом (EM) | Поиск предложения (ACC@1/5) | Поиск перехода (ACC@1/5) | Размер | Описание |
|---|---|---|---|---|---|
| 1048576_flat_opq96 | 41.3 | 48,7 / 66,4 | 52,6 / 71,5 | 60 ГБ | Оценивается с помощью eval-index-psg |
| 1048576_flat_opq96_medium | 39,9 | 48,3 / 65,8 | 52,2 / 70,9 | 39 ГБ | |
| 1048576_FLAT_OPQ96_SMALL | 38.0 | 47,2 / 64,0 | 50,7 / 69,1 | 20 ГБ |
Обратите внимание, что точность поиска отрывка (ACC@1/5), как правило, выше, чем сообщаемые числа в статье, поскольку эти индексы фразы возвращают естественные абзацы вместо текстовых блоков фиксированного размера (то есть 100 слов).
Вы можете запустить демонстрацию масштаба Википедии на своем собственном сервере. Для вашей собственной демонстрации вы можете изменить индекс фразы (полученный отсюда) или кодер запроса (например, на densephrases-multi-query-nq ).
Требование к ресурсу для запуска полной демонстрации шкалы Википедии:
Обратите внимание, что вам больше не нужен SSD для запуска демонстрации, в отличие от предыдущих моделей поиска фразу (Denspi, Denspi+Sparc). Следующие команды служат точно так же демо, что и здесь на вашем http://localhost:51997 .
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997 Пожалуйста, измените --load_dir или --dump_dir если это необходимо, и удалить --cuda для версии только для процессора. После настройки демонстрации файлы журнала в $SAVE_DIR/logs/ будут автоматически обновляться при появлении нового вопроса. Вы также можете отправлять запросы на ваш сервер, используя мини-партии вопросов для более быстрого вывода.
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred Для получения более подробной информации (например, изменение набора тестов), см. Цели в Makefile ( q-serve , p-serve , eval-demo и т. Д.).
В этом разделе мы вводим пошаговую процедуру для обучения денсифразы, создания фразных векторов и индексов, а также выпускаем выводы с обученной моделью. Все наши команды здесь упрощены в качестве целей Makefile , которые включают точные пути набора данных, настройки гиперпараметра и т. Д.
Если следующий тестовый запуск завершается без ошибки после установки и загрузки, вы готовы идти!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test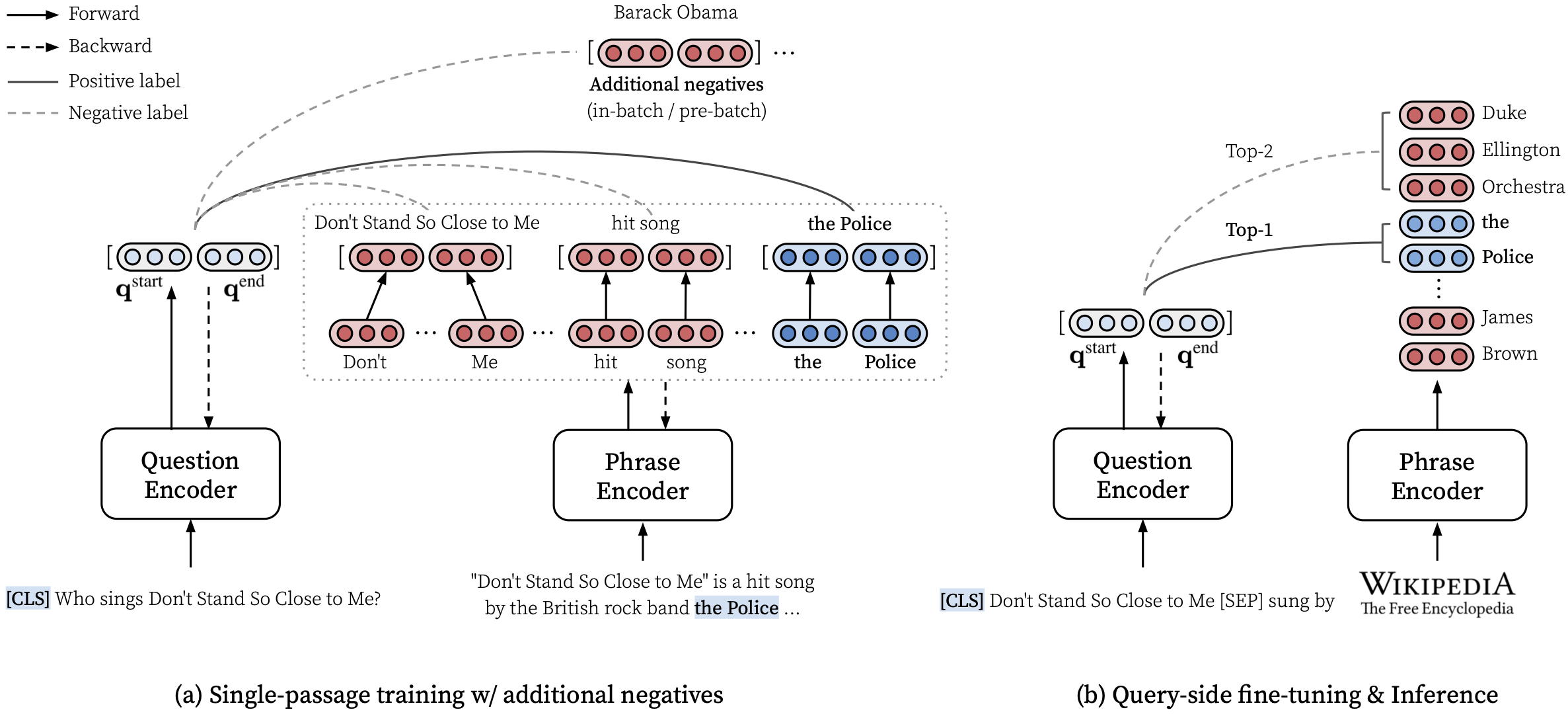
Чтобы обучить денсифразы с нуля, используйте run-rc-nq в Makefile , который обучает денсифразы на NQ (предварительно обработанный для задачи понимания прочитанного) и оценивает его в понимании прочитанного, а также на (полу) QA с открытым доменом. Вы можете просто изменить набор обучения, изменяя зависимости от run-rc-nq (например, nq-rc-data => sqd-rc-data и nq-param => sqd-param для обучения в команде). Вам понадобится единственный графический процессор 24 ГБ для обучения денсифразам по задачам понимания прочитанного, но вы можете использовать меньшие графические процессоры, установив правильно --gradient_accumulation_steps .
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq состоит из шести команд следующим образом (в случае обучения по NQ):
make train-rc ... : поезда DensePhrase на NQ с уравнением. 9 (l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg) с сгенерированными вопросами.make train-rc ... : нагрузка обученных денсифразой на предыдущем этапе и дальнейшее обучение его с уравнением. 9 с предварительным негативам.make gen-vecs : генерировать фразы векторов для d_small (= набор всех отрывков в NQ Dev).make index-vecs : создайте фразовый индекс для d_small.make compress-meta : сжатия метаданные для более быстрого вывода.make eval-index ... : оцените индекс фразы на заданных вопросах. В конце шага 2 вы увидите производительность в задаче понимания прочитанного, где дается золотой отрывок (около 72,0 ем на NQ Dev). Шаг 6 дает производительность в сфере полуоткрыта (обозначается как D_SMALL; см. Таблицу 6 в статье), где для индексации используются все отрывки из набора разработки NQ (около 62,0 EM с вопросами NQ DEV). Обученная модель будет сохранена под $SAVE_DIR/$MODEL_NAME . Обратите внимание, что во время однократного обучения по NQ мы исключаем некоторые вопросы в наборе разработки, чьи аннотированные ответы находятся из списка или таблицы.
Давайте предположим, что у вас есть предварительно обученные денсифразы с именем densephrases-multi , которые также можно загрузить отсюда. Теперь вы можете генерировать фразы векторов для крупномасштабного корпуса, такого как Википедия, используя gen-vecs-parallel . Обратите внимание, что вы можете просто загрузить индекс фразы для полной шкалы Википедии и пропустить этот раздел.
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8 Текстовым корпусом по умолчанию для создания фразовых векторов является wiki-dev расположенный в $DATA_DIR/wikidump . У нас есть три варианта для более крупных текстовых корпораций:
wiki-dev : 1/100 Шкала Википедии (выборка), 8 файловwiki-dev-noise : 1/10 Шкала Википедии (выборка), 500 файловwiki-20181220 : Full Wikipedia (20181220), 5621 файлы Корпуса wiki-dev* также содержат отрывки из набора разработки NQ, так что вы можете отслеживать производительность своей модели с увеличением размера текстового корпуса (обычно уменьшается по мере того, как она становится все больше). Фразные векторы будут сохранены в виде файлов HDF5 в $SAVE_DIR/$(MODEL_NAME)_(data_name)/dump (например, $SAVE_DIR/densephrases-multi_wiki-dev/dump ), который будет направлен в $DUMP_DIR ниже.
START and END Укажите индекс файла в корпусе (например, START=0 END=8 для wiki-dev и START=0 END=5621 для wiki-20181220 ). Каждый запуск gen-vecs-parallel потребляет 2 ГБ в одном графическом процессоре, и вы можете распределять процессы с различным START и END , используя сценарий Slurm или Shell (например, START=0 END=200 , START=200 END=400 , ..., START=5400 END=5621 ). Распределение 28 процессов на 4 24 ГБ графических процессоров (каждая обработка около 200 файлов) может создавать фразовые векторы для wiki-20181220 за 8 часов. Обработка всей Wikiepdia требует до 500 ГБ, и мы рекомендуем использовать SSD для их хранения, если это возможно, (меньший корпус может храниться в жестком жестком состоянии).
После создания фразных векторов вам необходимо создать индекс фразы для подсознательного поиска фраз. Здесь мы используем IVFOPQ для индекса фразы.
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ Для wiki-dev-noise и wiki-20181220 вам необходимо изменить количество кластеров до 101,372 и 1 048 576 соответственно (просто измените medium1-index в ìndex-vecs на medium2-index или large-index ). Для wiki-20181220 (полная Википедия) это занимает около 1 ~ 2 дня в зависимости от спецификации вашей машины и требует около 100 ГБ оперативной памяти. Для IVFSQ, как описано в статье, вы можете использовать index-add и index-merge для распространения добавления фразных векторов в индекс.
Вам также необходимо сжимать метаданные (сохраненные в файлах HDF5 вместе с фразовыми векторами) для более быстрого вывода из денсифразы. Это обязательно для индекса IVFOPQ.
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump Для оценки производительности DensePhrase с помощью ваших фразных индексов используйте eval-index .
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/Точная настройка на стороне запроса делает DensePhrase универсальным инструментом для извлечения текста с несколькими гранулярностью для различных типов входных запросов. Хотя точная настройка на стороне запроса может также улучшить производительность на наборах данных QA, его можно использовать для адаптации денсифраз к входным запросам в стиле QA, таких как «отношение субъекта [SEP] для получения объектов или« я люблю рэп-музыку ». Чтобы получить соответствующие документы по рэп.
Во-первых, вам нужен индекс фразы для полной Википедии ( wiki-20181220 ), который можно просто загрузить здесь, или индекс индивидуального фразы, как описано здесь. Учитывая ваши пары запросов или запросов-документов, предварительно обработанные как файлы json в $DATA_DIR/open-qa или $DATA_DIR/kilt , вы можете легко запросить на стороне настройки своей модели. Например, учебный набор T-REX ( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json ) выглядит следующим образом:
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
Следующие командные запросы на стороне тонких настройки densephrases-multi на T-Rex.
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Обратите внимание, что предварительно обученный энкодер запроса указан в train-query As --load_dir $(SAVE_DIR)/densephrases-multi , а новая модель будет сохранена как densephrases-multi-query-trex как указано в MODEL_NAME . Вы также можете тренироваться на разных наборах данных, изменяя зависимость trex-open-data на *-open-data (например, ay2-kilt-data для связывания сущности).
С любыми кодерами запросов DensePhrase (например, densephrases-multi-query-nq ) и индексом фразы (например, densephrases-multi_wiki-20181220 ), вы можете проверить свои запросы следующим образом, и результаты поиска будут сохранены в качестве файла JSON с опцией --save_pred :
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997 Для оценки на различных наборах данных просто измените зависимость от eval-index (или eval-demo ) соответственно (например, nq-open-data от trec-open-data для оценки на CuratedTrec).
В нижней части Makefile мы перечисляем команды, которые мы использовали для предварительной обработки наборов данных и Википедии. Для обучающих моделей генерации вопросов (T5-large) мы использовали https://github.com/patil-suraj/question_generation (см. Также здесь для QG). Обратите внимание, что все наборы данных уже предварительно обработаны, включая сгенерированные вопросы, поэтому вам не нужно запускать большинство этих сценариев. Для создания тестовых наборов для пользовательских (открытых домен) см. preprocess-openqa в Makefile .
Не стесняйтесь по электронной почте Jinhyuk Lee ([email protected]) на любые вопросы, связанные с кодом или газетой. Вы также можете открыть проблему GitHub. Пожалуйста, попробуйте указать детали, чтобы мы могли лучше понять и помочь вам решить проблему.
Пожалуйста, процитируйте нашу бумагу, если вы используете DensePhrase в своей работе:
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}Пожалуйста, смотрите лицензию для деталей.


