DensePhrases
1.1.0
開始| Lee et al。、ACL 2021 | Lee et al。、EMNLP 2021 |デモ|参照|ライセンス
DensePhraseは、自然言語の入力のためにフレーズ、文章、文書、またはドキュメントを返すことができるテキスト検索モデルです。ウィキペディア全体から数十億の密集したフレーズベクトルを使用して、濃い障害はリアルタイムで質問に対するフレーズレベルの回答を検索するか、下流タスクのパッセージを取得します。
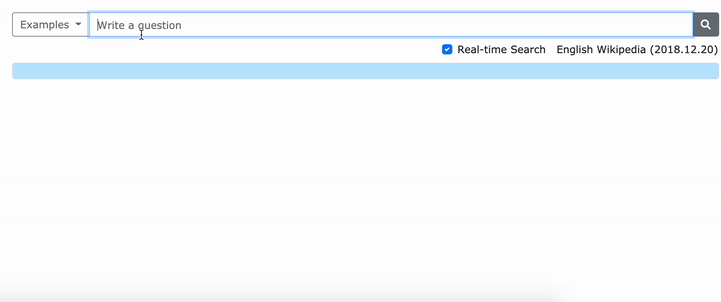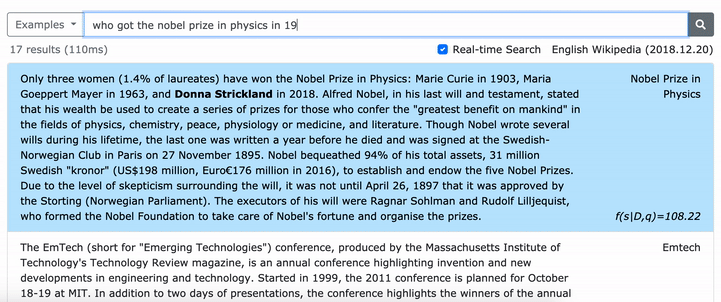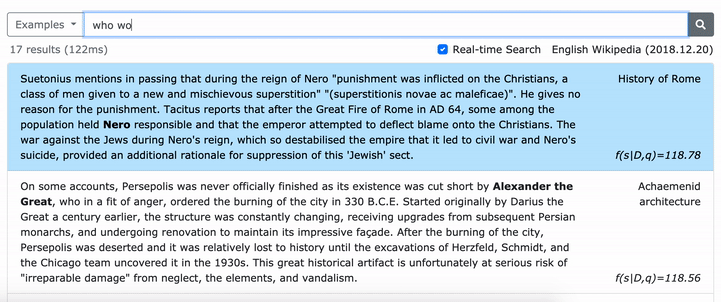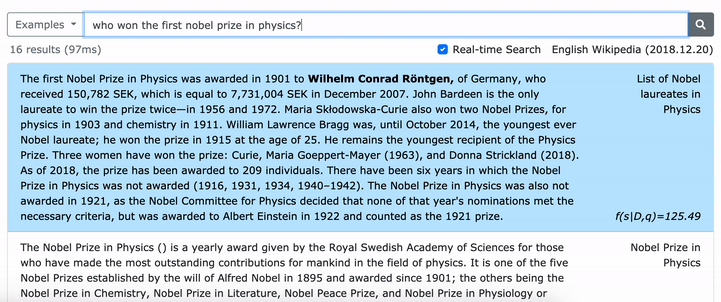
フレーズの密な表現を学習する方法の詳細については、Multi-Granularityの取得を実行する方法についてのemnlpペーパー(フレーズ検索も学習する)については、ACLペーパー(規模のフレーズの密な表現を学習)を参照してください。
*****ここで濃度のオンラインデモを試してみてください! *****
transformers==4.13.0 (メモを参照)。densephrases-multi-query-*のテスト予測ファイル - 追加。DensePhraseをインストールし、フレーズインデックスをダウロードした後、クエリ用のフレーズ、文、段落、またはドキュメントを簡単に取得できます。
CPUのみのモードの使用、カスタムインデックスの作成など、その他の例については、こちらをご覧ください。
また、DensePhraseを使用して、対話に関連するドキュメントを取得したり、特定のテキストにリンクしているエンティティを実行することもできます。
> >> from densephrases import DensePhrases
# Load DensePhrases for dialogue and entity linking
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-kilt-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )
# Retrieve relevant documents for a dialogue
> >> model . search ( 'I love rap music.' , retrieval_unit = 'document' , top_k = 5 )
[ 'Rapping' , 'Rap metal' , 'Hip hop' , 'Hip hop music' , 'Hip hop production' ]
# Run entity linking for the target phrase denoted as [START_ENT] and [END_ENT]
> >> model . search ( '[START_ENT] Security Council [END_ENT] members expressed concern on Thursday' , retrieval_unit = 'document' , top_k = 1 )
[ 'United Nations Security Council' ]2021年、Izacard and GraveによるFusion-in-Decoderと呼ばれる最先端のオープンドメイン質問回答モデルのトレーニングを含む、より多くの例を提供します。
# Install torch with conda (please check your CUDA version)
conda create -n densephrases python=3.7
conda activate densephrases
conda install pytorch=1.9.0 cudatoolkit=11.0 -c pytorch
# Install apex
git clone https://www.github.com/nvidia/apex.git
cd apex
python setup.py install
cd ..
# Install DensePhrases
git clone -b v1.0.0 https://github.com/princeton-nlp/DensePhrases.git
cd DensePhrases
pip install -r requirements.txt
python setup.py develop mainブランチではpython==3.7とtransformers==2.9.0使用します。濃度の他のバージョンについては、以下を参照してください。
| リリース | 注記 | 説明 |
|---|---|---|
| v1.0.0 | リンク | transformers==2.9.0 、 mainと同じ |
| v1.1.0 | リンク | transformers==4.13.0 |
以下の必要なファイルをダウンロードする前に、デフォルトのディレクトリを次のように設定し、ファイルをダウンロードして解凍するのに十分なストレージがあることを確認してください。
# Running config.sh will set the following three environment variables:
# DATA_DIR: for datasets (including 'kilt', 'open-qa', 'single-qa', 'truecase', 'wikidump')
# SAVE_DIR: for pre-trained models or index; new models and index will also be saved here
# CACHE_DIR: for cache files from Huggingface Transformers
source config.sh以下に説明するリソースをダウンロードするには、次のようにdownload.shを使用できます。
# Use bash script to download data (change data to models or index accordingly)
source download.sh
Choose a resource to download [data/wiki/models/index]: data
data will be downloaded at ...
...
Downloading data done !$DATA_DIRでダウンロードして解凍するか、 download.shを使用します。$DATA_DIRでダウンロードして解凍するか、 download.shを使用します。 # Check if the download is complete
ls $DATA_DIR
kilt open-qa single-qa truecase wikidumpHuggingface Model Hubの事前に訓練されたモデルを使用できます。 princeton-nlp ( load_dirで指定)から始まるモデル名は、ハグFaceモデルハブのモデルとして自動的に翻訳されます。
> >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq from the Huggingface model hub
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )| モデル | Query-ft。 | NQ | webq | Trec | Triviaqa | 分隊 | 説明 |
|---|---|---|---|---|---|---|---|
| DensePhrase-Multi | なし | 31.9 | 25.5 | 35.7 | 44.4 | 29.3 | query-ftの前にem。 |
| DensePhrase-Multi-Query-Multi | 複数 | 40.8 | 35.0 | 48.8 | 53.3 | 34.2 | デモに使用されます |
| モデル | Query-ft。 &評価 | em | 予測(テスト) | 説明 |
|---|---|---|---|---|
| DensePhrase-Multi-Query-Nq | NQ | 41.3 | リンク | - |
| DensePhrase-Multi-Query-Wq | webq | 41.5 | リンク | - |
| DensePhrase-Multi-Query-Trec | Trec | 52.9 | リンク | --regexが必要です |
| DensePhrase-Multi-Query-TQA | Triviaqa | 53.5 | リンク | - |
| DensePhrase-Multi-Query-Sqd | 分隊 | 34.5 | リンク | - |
重要: densephrases-multiを除くすべてのモデルは、フレーズインデックスDensePhrase-Multi_Wiki-20181220を使用して、指定されたデータセット(query-ft。)でクエリ側に微調整されています。また、事前に訓練されたモデルはケースに敏感なモデルであり、低いクエリ(例えば、NQ)で--truecaseがオンになっている場合、最良の結果が得られることに注意してください。
densephrases-multi :Mutiple読解データセット(NQ、WebQ、Trec、Triviaqa、Squad)で訓練されています。densephrases-multi-query-multi :複数のオープンドメインQAデータセット(NQ、WebQ、Trec、Triviaqa、Squad)で微調整されたdensephrases-multi -Side。densephrases-multi-query-* :各オープンドメインQAデータセットで微調整されたdensephrases-multi -Side。他のタスクの事前に訓練されたモデル(たとえば、スロットフィリング)については、例を参照してください。ほとんどの事前に訓練されたモデルは、クエリ側の微調整densephrases-multiの結果であることに注意してください。
spanbert-base-cased-*を含む)。 $SAVE_DIRでダウンロードして解凍するか、 download.shを使用します。 # Check if the download is complete
ls $SAVE_DIR
densephrases-multi densephrases-multi-query-nq ... spanbert-base-cased-squad > >> from densephrases import DensePhrases
# Load densephraes-multi-query-nq locally
> >> model = DensePhrases (
... load_dir = '/path/to/densephrases-multi-query-nq' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... )ウィキペディアの完全なスケールで作業したい場合を除き、このフレーズインデックスをダウンロードする必要はないことに注意してください。
$SAVE_DIRでダウンロードして解凍するか、 download.shを使用します。また、より攻撃的なフィルタリング(オプション)に基づいて、より小さなフレーズインデックスを提供します。
これらの小さなインデックスは、ダウンロードした他のインデックスと一緒に$SAVE_DIR/densephrases-multi_wiki-20181220/dump/startに配置する必要があります。小さいフレーズインデックスのみを使用し、大きなインデックス(74GB)をダウンロードしたくない場合は、メタデータ(20GB)をダウンロードし、以下に示すように$SAVE_DIR/densephrases-multi_wiki-20181220/dumpフォルダーの下に配置する必要があります。ファイルの構造は次のように見える必要があります。
$SAVE_DIR /densephrases-multi_wiki-20181220
└── dump
├── meta_compressed.pkl
└── start
├── 1048576_flat_OPQ96
├── 1048576_flat_OPQ96_medium
└── 1048576_flat_OPQ96_smallすべてのフレーズインデックスは、同じモデル( densephrases-multi )から作成されており、これらのフレーズインデックスのいずれかで上記のすべての事前訓練モデルを使用できます。インデックスを変更するには、次のように次のようにdensephrases/options.pyでindex_name (or --index_name )を設定するだけです。
> >> from densephrases import DensePhrases
# Load DensePhrases with a smaller index
> >> model = DensePhrases (
... load_dir = 'princeton-nlp/densephrases-multi-query-multi' ,
... dump_dir = '/path/to/densephrases-multi_wiki-20181220/dump' ,
... index_name = 'start/1048576_flat_OPQ96_small'
... )さまざまなフレーズインデックスを使用した自然な質問(テスト)でのdensephrases-multi-query-nqのパフォーマンスを以下に示します。
| フレーズインデックス | オープンドメインQA(EM) | 文の検索(ACC@1/5) | パッセージ検索(ACC@1/5) | サイズ | 説明 |
|---|---|---|---|---|---|
| 1048576_FLAT_OPQ96 | 41.3 | 48.7 / 66.4 | 52.6 / 71.5 | 60GB | eval-index-psgで評価されます |
| 1048576_FLAT_OPQ96_MEDIUM | 39.9 | 48.3 / 65.8 | 52.2 / 70.9 | 39GB | |
| 1048576_FLAT_OPQ96_SMALL | 38.0 | 47.2 / 64.0 | 50.7 / 69.1 | 20GB |
これらのフレーズインデックスは固定サイズのテキストブロック(つまり、100ワード)ではなく自然段落を返すため、パッセージ検索の精度(ACC@1/5)は一般に、ペーパーで報告された数値よりも高いことに注意してください。
自分のサーバーでウィキペディアスケールのデモを実行できます。独自のデモでは、フレーズインデックス(こちらから取得)またはクエリエンコーダー(例: densephrases-multi-query-nq )を変更できます。
ウィキペディアスケールの完全なデモを実行するためのリソース要件は次のとおりです。
以前のフレーズ検索モデル(denspi、denspi+SPARC)とは異なり、デモを実行するためにSSDは必要ないことに注意してください。次のコマンドはhttp://localhost:51997でこことまったく同じデモを提供します。
# Serve a query encoder on port 1111
nohup python run_demo.py
--run_mode q_serve
--cache_dir $CACHE_DIR
--load_dir princeton-nlp/densephrases-multi-query-multi
--cuda
--max_query_length 32
--query_port 1111 > $SAVE_DIR /logs/q-serve_1111.log &
# Serve a phrase index on port 51997 (takes several minutes)
nohup python run_demo.py
--run_mode p_serve
--index_name start/1048576_flat_OPQ96
--cuda
--truecase
--dump_dir $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
--query_port 1111
--index_port 51997 > $SAVE_DIR /logs/p-serve_51997.log &
# Below are the same but simplified commands using Makefile
make q-serve MODEL_NAME=densephrases-multi-query-multi Q_PORT=1111
make p-serve DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/ Q_PORT=1111 I_PORT=51997必要に応じて--load_dirまたは--dump_dirを変更して、CPUのみのバージョンの--cudaを削除してください。デモを設定すると、 $SAVE_DIR/logs/のログファイルは、新しい質問が来るたびに自動的に更新されます。また、より速い推論のために質問のミニバッチを使用してサーバーにクエリを送信することもできます。
# Test on NQ test set
python run_demo.py
--run_mode eval_request
--index_port 51997
--test_path $DATA_DIR /open-qa/nq-open/test_preprocessed.json
--eval_batch_size 64
--save_pred
--truecase
# Same command with Makefile
make eval-demo I_PORT=51997
# Result
(...)
INFO - eval_phrase_retrieval - { ' exact_match_top1 ' : 40.83102493074792, ' f1_score_top1 ' : 48.26451418695196}
INFO - eval_phrase_retrieval - { ' exact_match_top10 ' : 60.11080332409972, ' f1_score_top10 ' : 68.47386731458751}
INFO - eval_phrase_retrieval - Saving prediction file to $SAVE_DIR /pred/test_preprocessed_3610_top10.pred詳細(テストセットの変更など)については、 Makefileのターゲット( q-serve 、 p-serve 、 eval-demoなど)をご覧ください。
このセクションでは、密度の高い手順を紹介し、密な障害を訓練し、フレーズベクトルとインデックスを作成し、訓練されたモデルで推論を実行します。ここでのコマンドはすべて、 Makefileターゲットとして簡素化されています。これには、正確なデータセットパス、ハイパーパラメーター設定などが含まれます。
インストールとダウンロード後にエラーなしで次のテストの実行が完了した場合は、行ってもいいです!
# Test run for checking installation (takes about 10 mins; ignore the performance)
make draft MODEL_NAME=test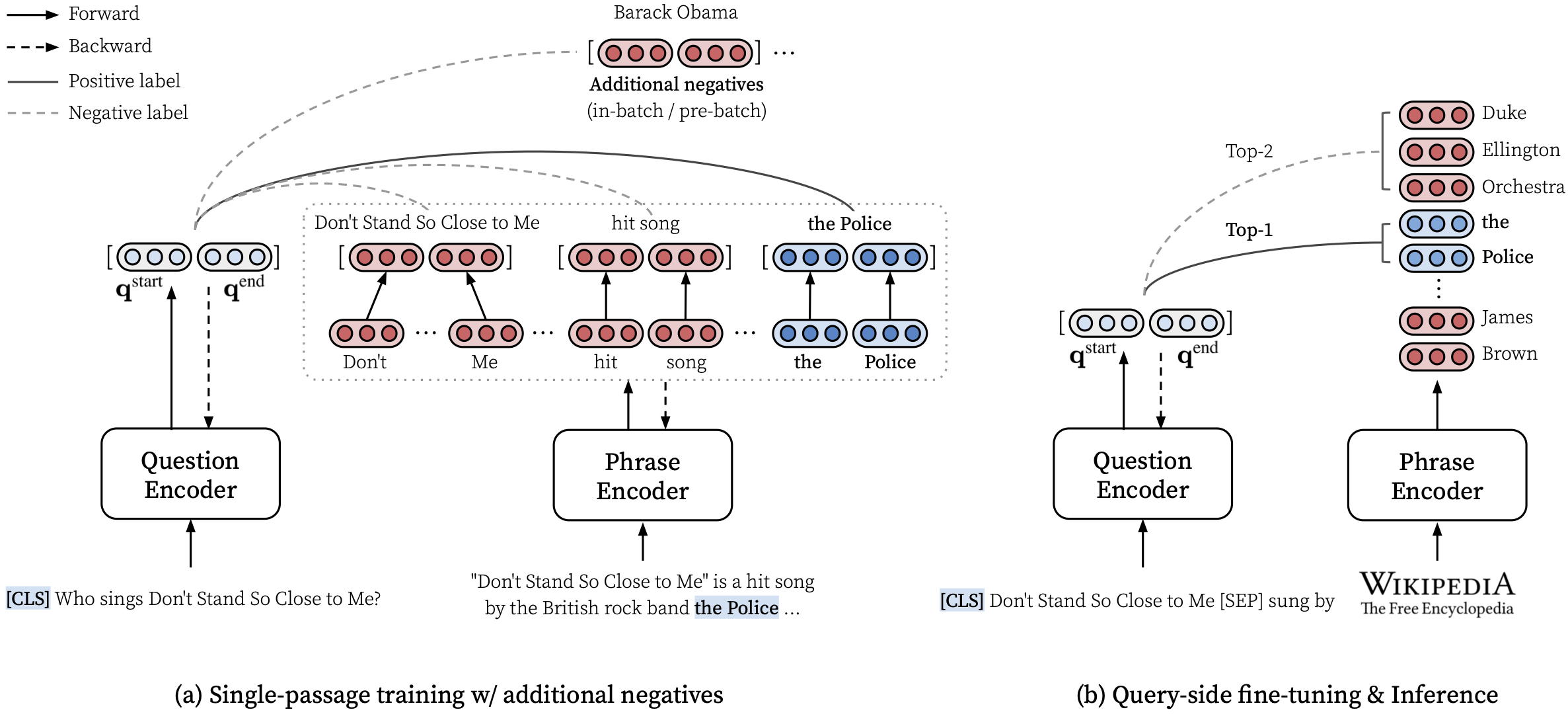
洗練された濃度をゼロから訓練するには、NQで密な濃度を訓練するMakefileでrun-rc-nqを使用し(読解力のために前処理)、読解力と(Semi)Open-Domain QAで評価します。 run-rc-nqの依存関係を変更することにより、トレーニングセットを変更するだけで(例: nq-rc-data => sqd-rc-dataおよびnq-param => sqd-param )、Squadでのトレーニングのために)。読解タスクで密な障害をトレーニングするために1つの24GB GPUが必要ですが、 --gradient_accumulation_steps適切に設定することで、より小さなGPUを使用できます。
# Train DensePhrases on NQ with Eq. 9 in Lee et al., ACL'21
make run-rc-nq MODEL_NAME=densephrases-nq run-rc-nq次のように6つのコマンドで構成されています(NQでのトレーニングの場合):
make train-rc ... :eqを使用してNQで密集した密度疾患を排出します。 9(l = lambda1 l_single + lambda2 l_distill + lambda3 l_neg)生成された質問。make train-rc ... :前のステップで訓練された密な濃度をロードし、Eqでさらに訓練します。 9バッチ前のネガがあります。make gen-vecs :D_SMALLのフレーズベクトルを生成します(= NQ DEVのすべてのパッセージのセット)。make index-vecs :D_SMALLのフレーズインデックスを作成します。make compress-meta :メタデータを圧縮して、より速い推論します。make eval-index ... :開発セットの質問のフレーズインデックスを評価します。ステップ2の終わりには、金の通路が与えられる読解タスクのパフォーマンスが表示されます(NQ開発者の約72.0 EM)。ステップ6では、NQ開発セットからの通路全体がインデックス作成に使用される、セミオペンドメイン設定(D_SMALLとして表され、論文の表6を参照)でパフォーマンスを示します(NQ DEVの質問で約62.0 EM)。訓練されたモデルは$SAVE_DIR/$MODEL_NAMEで保存されます。 NQでのシングルパセージトレーニング中に、リストまたはテーブルから注釈付きの回答が見つかった開発セットにいくつかの質問を除外することに注意してください。
densephrases-multiという名前の事前に訓練された濃縮障害があると仮定しましょう。これもここからダウンロードできます。これで、 gen-vecs-parallelを使用して、ウィキペディアのような大規模なコーパスのフレーズベクトルを生成できます。 Wikipediaスケール全体のフレーズインデックスをダウンロードして、このセクションをスキップできることに注意してください。
# Generate phrase vectors in parallel for a large-scale corpus (default = wiki-dev)
make gen-vecs-parallel MODEL_NAME=densephrases-multi START=0 END=8フレーズベクトルを作成するためのデフォルトのテキストコーパスは$DATA_DIR/wikidumpにあるwiki-devです。より大きなテキストコーパスの3つのオプションがあります:
wiki-dev :1/100ウィキペディアスケール(サンプリング)、8ファイルwiki-dev-noise :1/10 Wikipediaスケール(サンプリング)、500ファイルwiki-20181220 :Full Wikipedia(20181220)スケール、5621ファイルwiki-dev* Corporaには、NQ開発セットからの通路も含まれているため、テキストコーパスのサイズが増加するとモデルのパフォーマンスを追跡できます(通常、大きくなるにつれて減少します)。フレーズベクトルは$SAVE_DIR/$(MODEL_NAME)_(data_name)/dump $SAVE_DIR/densephrases-multi_wiki-dev/dump $DUMP_DIR )/dumpのhdf5ファイルとして保存されます。
STARTとENDコーパスのファイルインデックスを指定します(例: wiki-devの場合はSTART=0 END=8 、 START=0 END=5621でwiki-20181220の場合)。 gen-vecs-parallelの各実行は、単一のGPUで2GBのみを消費し、SlurmまたはShellスクリプトを使用して異なるSTARTとENDでプロセスを配布できます(例: START=0 END=200 、 START=200 END=400 、...、 START=5400 END=5621 )。 44GB GPU(各処理の約200ファイル)に28のプロセスを配布すると、8時間でwiki-20181220のフレーズベクトルを作成できます。 WikiepDia全体を処理するには最大500GBが必要であり、SSDを使用して可能であれば保存することをお勧めします(HDDに小さなコーパスを保存できます)。
フレーズベクトルを生成した後、フレーズのサブリンタイム検索のためのフレーズインデックスを作成する必要があります。ここでは、Frase IndexにIVFOPQを使用します。
# Create IVFOPQ index for a set of phrase vectors
make index-vecs DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/ wiki-dev-noiseおよびwiki-20181220の場合、クラスターの数をそれぞれ101,372および1,048,576に変更する必要があります(単にìndex-vecsのmedium1-index medium2-indexまたはlarge-indexに変更するだけです)。 wiki-20181220 (フルウィキペディア)の場合、マシンの仕様に応じて約1〜2日かかり、約100GBのRAMが必要です。論文で説明されているIVFSQの場合、 index-addとindex-mergeを使用して、フレーズベクトルの追加をインデックスに分配できます。
また、濃度の推論をより速く推論するために、メタデータ(フレーズベクトルと一緒にHDF5ファイルに保存)を圧縮する必要があります。これは、IVFOPQインデックスに必須です。
# Compress metadata of wiki-dev
make compress-meta DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dumpフレーズインデックスを使用した濃度のパフォーマンスを評価するには、 eval-indexを使用してください。
# Evaluate on the NQ test set questions
make eval-index MODEL_NAME=densephrases-multi DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-dev/dump/クエリサイドの微調整により、濃度は、さまざまな種類の入力クエリの多粒度テキストを取得するための汎用性の高いツールになります。クエリサイドの微調整もQAデータセットのパフォーマンスを改善することができますが、オブジェクトエンティティや「私はラップ音楽が大好き」を取得するために「件名[SEP]関係」などの非QAスタイルの入力クエリに濃度を適応させるために使用できます。ラップで関連するドキュメントを取得する。
まず、フルウィキペディア( wiki-20181220 )のフレーズインデックスが必要です。これは、ここから単純にダウンロードできます。また、ここで説明するカスタムフレーズインデックスが必要です。 $DATA_DIR/open-qaまたは$DATA_DIR/kiltでJSONファイルとして前処理されたクエリアンドワーまたはクエリドキュメントのペアを考えると、モデルを簡単に微調整できます。たとえば、T-Rexのトレーニングセット( $DATA_DIR/kilt/trex/trex-train-kilt_open_10000.json )は次のように見えます。
{
"data": [
{
"id": "111ed80f-0a68-4541-8652-cb414af315c5",
"question": "Effie Germon [SEP] occupation",
"answers": [
"actors",
...
]
},
...
]
}
次のコマンドクエリ側のファインチューンは、t-rexのdensephrases-multi 。
# Query-side fine-tune on T-REx (model will be saved as MODEL_NAME)
make train-query MODEL_NAME=densephrases-multi-query-trex DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/事前に訓練されたクエリエンコーダーはdensephrases-multi-query-trex train-queryの--load_dir $(SAVE_DIR)/densephrases-multiで指定されていることに注意してくださいMODEL_NAMEまた、依存関係trex-open-data *-open-data (例えば、エンティティリンク用のay2-kilt-data )に変更することで、異なるデータセットでトレーニングすることもできます。
DensePhrasesクエリエンコーダー(例: densephrases-multi-query-nq )とフレーズインデックス(例: densephrases-multi_wiki-20181220 )を使用すると、次のようにクエリをテストでき、検索結果は--save_predオプションのJSONファイルとして保存されます。
# Evaluate on Natural Questions
make eval-index MODEL_NAME=densephrases-multi-query-nq DUMP_DIR= $SAVE_DIR /densephrases-multi_wiki-20181220/dump/
# If the demo is being served on http://localhost:51997
make eval-demo I_PORT=51997さまざまなデータセットでの評価の場合、それに応じてeval-index (またはeval-demo )の依存性を変更するだけです(例えば、curatedtrecでの評価のためにtrec-open-data nq-open-data )。
Makefileの下部に、データセットとWikipediaの前処理に使用したコマンドをリストします。質問生成モデル(T5-Large)のトレーニングには、https://github.com/patil-suraj/question_generationを使用しました(QGについてはこちらも参照)。生成された質問を含むすべてのデータセットはすでに前処理されているため、これらのスクリプトのほとんどを実行する必要はないことに注意してください。カスタム(オープンドメイン)の質問のテストセットを作成するには、 Makefileのpreprocess-openqa参照してください。
コードまたは論文に関連する質問については、jinhyuk lee ([email protected])にメールしてください。 GitHubの問題を開くこともできます。問題をよりよく理解し、解決できるように、詳細を指定してみてください。
作品に密な散布を使用している場合は、私たちの論文を引用してください。
@inproceedings { lee2021learning ,
title = { Learning Dense Representations of Phrases at Scale } ,
author = { Lee, Jinhyuk and Sung, Mujeen and Kang, Jaewoo and Chen, Danqi } ,
booktitle = { Association for Computational Linguistics (ACL) } ,
year = { 2021 }
} @inproceedings { lee2021phrase ,
title = { Phrase Retrieval Learns Passage Retrieval, Too } ,
author = { Lee, Jinhyuk and Wettig, Alexander and Chen, Danqi } ,
booktitle = { Conference on Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 } ,
}詳細については、ライセンスをご覧ください。


