p search
1.0.0
P-Search是找到事物的效果工具。它結合了信息檢索和貝葉斯搜索理論的概念,以幫助用戶查找文檔。
布爾搜索(即文檔包含“ x”一詞),雖然簡單且有用,但不符合搜索者在相關文件所在的位置的先前信念。通常,搜索者對文檔的位置有特定的想法。就像是什麼類型的文件一樣,在創建文檔時撰寫了文檔。搜索者通常對SEACH術語的出現或是否出現並不完全自信。
在ELPA/MELPA上提供P-Search之前,您必須手動安裝此軟件包。 p-search的唯一依賴性是堆。
使用Quelpa:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))使用直線:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))使用elpaca:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " ))可以使用p-search命令啟動搜索會話。該命令將設置會話以搜索項目目錄中的文件(請參見項目)或當前目錄。使用前綴Cu執行p-search以實例化空話(todo)。
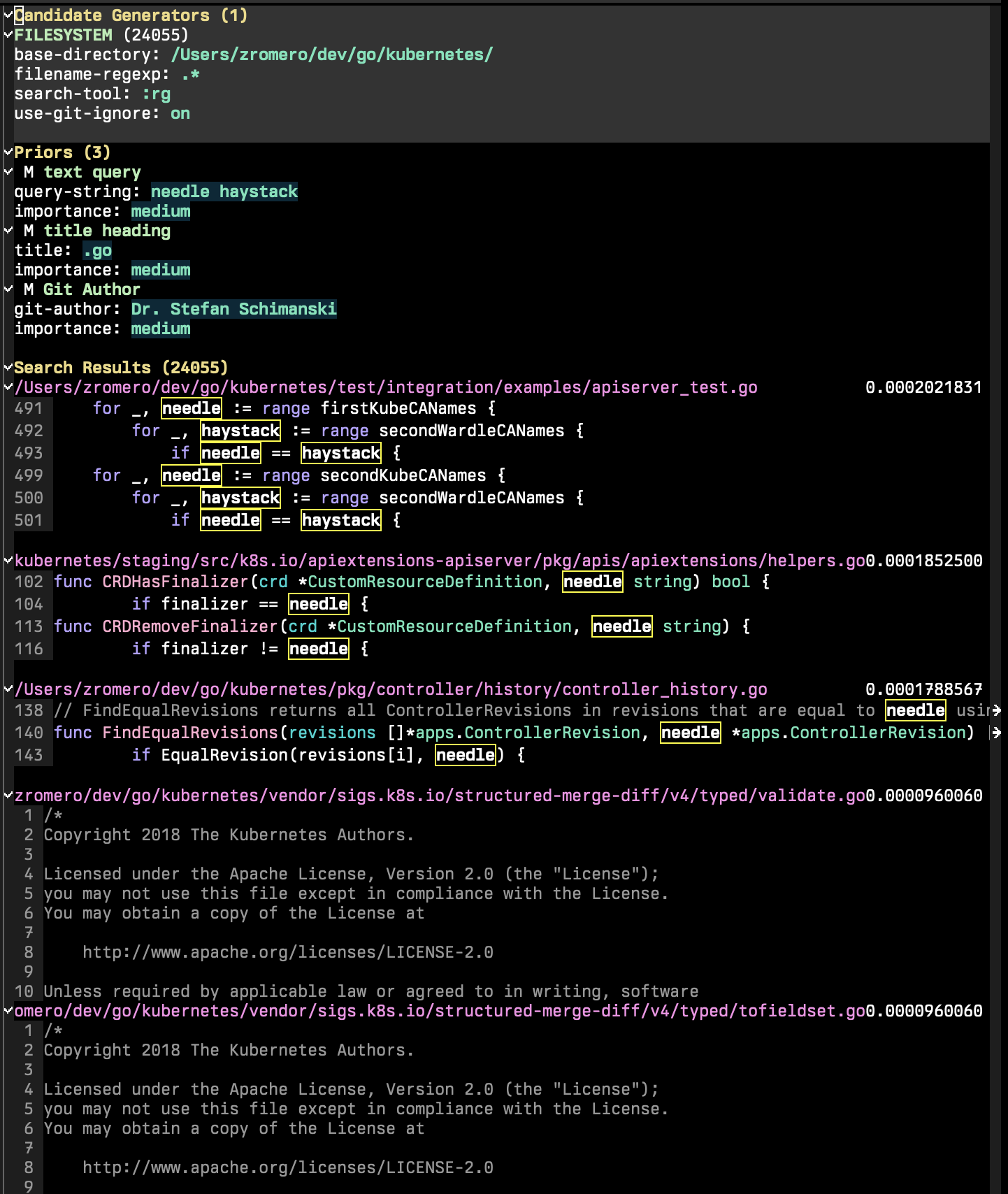
P-Search會議由三個主要部分組成:候選生成器,先驗和搜索結果。
候選生成器是搜索會話的一部分,列舉了所有可能的搜索候選者。搜索候選者是一個具有一組密鑰/值屬性的實體, 'content和'title為mandetory。可能存在其他屬性,這將使您可以使用其他先驗功能。在P-Search會話中,運行p-search-add-candidate-generator generator ( C )添加新的候選生成器。
您可以使用命令p-search-kill-entry-at-point刪除先驗。
“先驗”部分是您在會話中添加搜索條件的部分。運行p-search-add-prior ( P )以添加先驗功能。
首先,您必須選擇要添加的先驗類型。然後,您將必須配置先驗。它會首先提示您獲取任何符合要求的字段。
之後,將出現一個新的瞬態菜單,允許您配置先驗。每個先前的功能都將具有自己的一組輸入和選項,但是每個功能都可以讓您設置其重要性以及是否應採取補充。
您可以使用命令p-search-kill-entry-at-point ( k )刪除先驗。
根據先前功能的匹配程度,每個候選文檔都會從每個先前的功能中給出分數。
因此,例如,假設您有文本查詢搜索。查詢將以0到1的比例對每個文檔進行排名。然後,該分數通過重要性修改。如果您分配了高度的重視,那麼概率將被推到極端。較低的重要性將概率提高到0.5,從而降低了其影響。
因此,例如,如果文本搜索查詢將文檔標記為高度相關的0.7,但重點較低,則其概率可能會被修改為0.55,從而降低其影響。另一方面,如果文本查詢匹配不佳,得分為0.3,但其重要性很低,則其概率將提高到0.45。
[候選生成器] | | [PIRIC_X] [PIRIC_Y] | | - doc_a--> questional_x(score_x_a)✖ | | - doc_b-> guentionals_x(score_x_b)✖ | --- doc_c-> guentionce_x(score_x_c)✖
文本搜索是p-search中的重要組成部分。雖然文本搜索的功能與其他先前功能相同(得分為0到1),但其背後的麥克海斯主義更為複雜。
您可以在運行p-search-add-prior時在瞬態菜單中選擇“文本查詢”來創建文本查詢。
然後,您將提示您查詢。根據您編寫的查詢,將創建一個或多個進程來執行搜索。
如前所述,每個搜索候選文檔都有一個屬性'content 。文本搜索在此字段上執行。您可能可能會不會出現,因此必須在單個Emacs Lisp線程上搜索每個文檔很慢,因此每個候選生成器函數都可以具有更快的方法來執行搜索。這就是為什麼您會在文件系統候選生成器上看到搜索工具:grep或:rg 。在對此文檔進行文本查詢時,它將依靠此工具來執行搜索。
對於文本查詢,每個搜索結果均分開。因此,如果您鍵入teacher student school則將對三個任期進行三個單獨的搜索。每個學期將為每個文檔生成自己的分數,然後將它們合併成最終分數。您可以使用引號將單詞分組以搜索整體,因此"teacher student school"將通過順序執行一個搜索。
未引用的術語將被處理為多個變體,並並行搜索。因此,例如, teacherStudentSchool將同時搜索“ Teacterstudents Chool”(案例不敏感),也將搜索“ Teacher_student_school”,“教師學生學校”(分數較低)和分離術語“老師”,“學生”,“學生”和“學校”(甚至得分較低)(得分較低)。
您可以通過^來提高學期,以便teacher student^ school可以促進學生。您也可以指定一個數字提升,例如在teacher student^2 school^3 。
您可以使用(term1 term2 ...)~語法搜索彼此接近的術語。根據p-search-default-near-line-length的值,這些項目將被要求彼此之間的一定數量。
p-search只會向您顯示搜索結果的第一個p-search-top-n值。如果您沒有看到相關結果,則可能需要考慮添加搜索標準。您還可以運行命令p-search-observe以降低特定結果的概率。這樣做將通過將項目乘以0.3來降低項目的概率。使用前綴Cu p-search-observe ,您可以指定概率。執行觀察結果後,將重新計算概率,結果將更新。
p-search-peruse-mode是一種實驗性的全球次要模式,在活動時,它將跟踪您查看的文件的百分比。視圖百分比將在搜索結果部分中更新。
P-Search包含許多機制來加快您的搜索過程。一方面,您可以從編程中創建命令並調用各種p-search函數,以使會話對您的喜好進行實例化。另一方面,只需使用命令bookmark-set (通常是綁定的Cx rm )將會話添加書籤,這將使您保存會話,候選人的生成器和先驗,以便將來快速訪問。
配置P-Search行為的另一種方法是設置變量p-search-default-command-behavior 。通過設置它的值,您可以在全球範圍內配置命令p-search的行為。您還可以通過“ .dir-locals.el”文件設置變量,如下所示,具有目錄 - 局部設置:
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " )))))))您可以運行命令p-search-show-session-preset以查看當前會話表示為LISP對象。通過將此數據結構傳遞給函數p-search-setup-buffer ,您可以按程序上創建所需的p-search會話。


