p search
1.0.0
P-Search는 사물을 찾는 EMACS 도구입니다. 정보 검색 및 베이지안 검색 이론의 개념을 결합하여 사용자가 문서를 찾는 데 도움을줍니다.
부울 검색 (즉, 문서에는“x”라는 단어가 포함되어 있음)은 간단하고 유용하지만 관련 파일이 어디에 있는지에 관한 검색 자의 이전 신념과 일치하지 않습니다. 종종 검색자는 문서의 위치에 대한 특정 아이디어를 가지고 있습니다. 문서를 작성했을 때 어떤 유형의 파일이 문서를 작성했는지와 마찬가지로. 검색자는 종종 Seach 용어가 어떻게 나타나는지 또는 전혀 나타나는지에 대해 완전히 확신하지 못합니다.
ELPA/MELPA에서 P 검색을 사용할 수있을 때 까지이 패키지를 수동으로 설치해야합니다. P 검색의 유일한 의존성은 힙입니다.
Quelpa 사용 :
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))스트레이트 사용 :
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))Elpaca 사용 :
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " )) p-search 명령으로 검색 세션을 시작할 수 있습니다. 명령은 프로젝트 디렉토리 (Project.EL 참조)에서 파일을 검색하기 위해 세션을 설정합니다 (프로젝트가 존재하는 경우). 접두사 Cu 사용하여 p-search 실행하여 빈 세션 (TODO)을 인스턴스화하십시오.
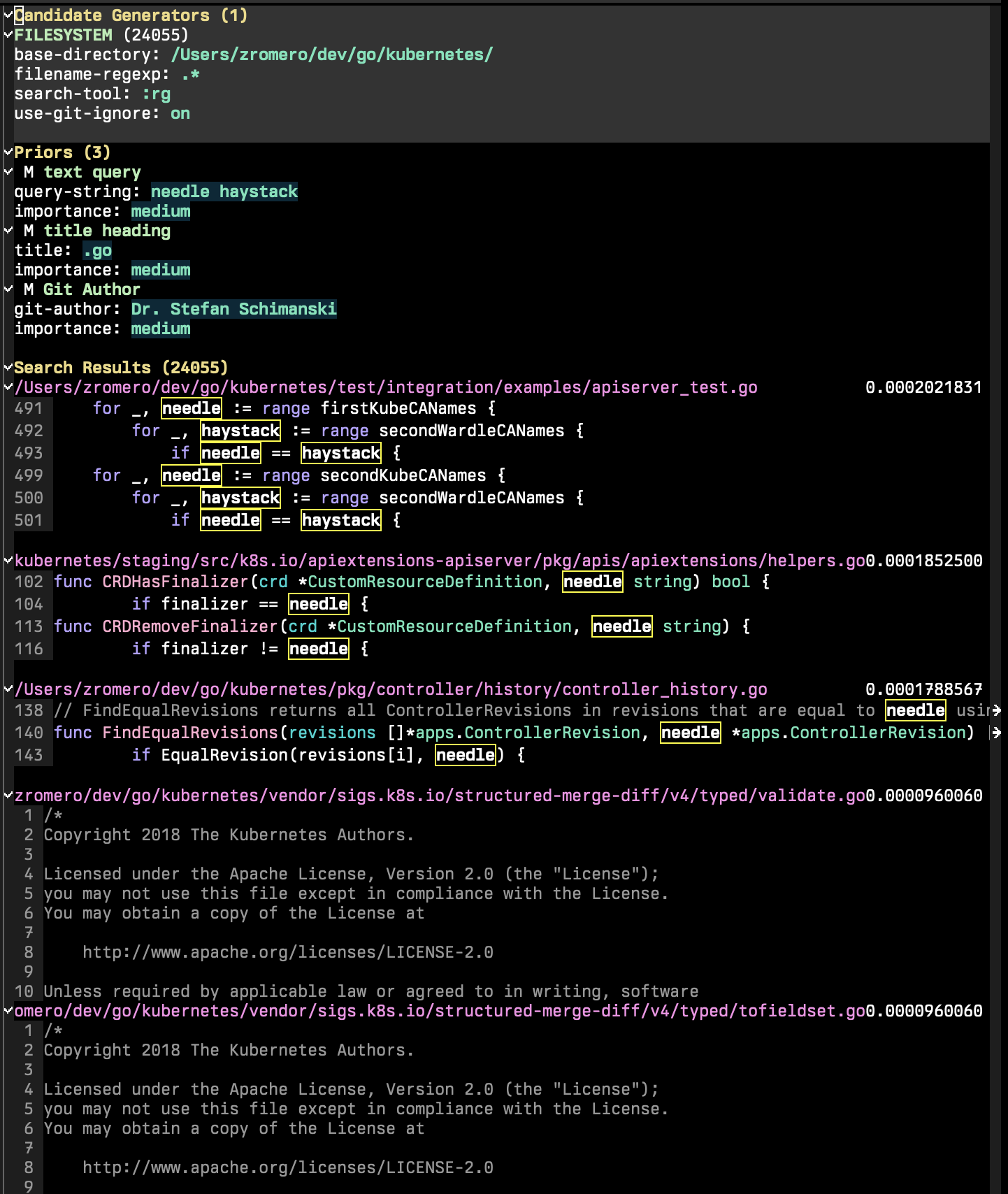
P 검색 세션은 후보 생성기, 사전 및 검색 결과의 세 가지 주요 섹션으로 구성됩니다.
후보 생성기는 가능한 모든 검색 후보를 열거하는 검색 세션의 일부입니다. 검색 후보자는 키/값 속성 세트, 'content 및 'title 맨터리를 갖춘 엔티티입니다. 다른 속성이 존재할 수있는 추가 사전 함수를 사용할 수 있습니다. P 검색 세션에서 p-search-add-candidate-generator ( C )를 실행하여 새로운 후보 생성기를 추가합니다.
p-search-kill-entry-at-point 명령으로 사전 삭제를 삭제할 수 있습니다.
사전 섹션은 세션에 검색 기준을 추가하는 부분입니다. p-search-add-prior ( P )를 실행하여 사전 기능을 추가하십시오.
먼저 추가하려는 사전 유형을 선택해야합니다. 그러면 이전을 구성해야합니다. 먼저 맨터리 필드를 자극합니다.
그런 다음 새 과도 메뉴가 나타나서 이전을 구성 할 수 있습니다. 각각의 이전 기능에는 고유 한 입력 및 옵션 세트가 있지만 각 기능은 중요성 과 보완을 취해야하는지 여부를 설정할 수 있습니다.
p-search-kill-entry-at-point ( k ) 명령으로 사전 삭제할 수 있습니다.
각 후보 문서에는 이전 기능이 얼마나 잘 일치하는지에 따라 각각의 이전 기능의 점수가 부여됩니다.
예를 들어, 텍스트 쿼리 검색이 있다고 가정합니다. 쿼리는 각 문서를 0에서 1까지 척도로 순위를 매 깁니다.이 점수는 중요성에 의해 수정됩니다. 당신이 큰 중요성을 부여하면 확률은 극단으로 밀려납니다. 중요성이 낮 으면 확률이 0.5로 향상되어 그 영향이 줄어 듭니다.
예를 들어, 텍스트 검색 쿼리가 문서를 0.7로 매우 관련성이 높은 것으로 표시했지만 중요성이 낮은 경우, 그 확률은 0.55로 수정되어 그 영향을 낮출 수 있습니다. 반면에 텍스트 쿼리가 일치하면 0.3 점수가 좋지 않지만 중요성이 낮 으면 확률이 0.45로 올라갑니다.
[후보 생성기] | | [Privation_X] [Prior_y] | | -doc_a-> 중요도 _x (score_x_a) ✖ 중요도 _y (score_y_a) | | -doc_b-> 중요도 _x (score_x_b) ✖ 중요도 _y (score_y_b) ... | 방법
텍스트 검색은 P 검색에서 두드러진 구성 요소입니다. 텍스트 검색은 다른 이전 기능 (0 ~ 1의 점수)과 동일한 방식으로 기능하지만 그 뒤에있는 메카 니즘이 더 복잡합니다.
p-search-add-prior 실행할 때 과도 메뉴에서 "텍스트 쿼리"를 선택하여 텍스트 쿼리를 만들 수 있습니다.
그러면 쿼리를 요구합니다. 쓰는 쿼리에 따라 검색을 수행하기 위해 하나 이상의 프로세스가 작성됩니다.
앞에서 언급했듯이 각 검색 후보 문서에는 속성 'content 가 있습니다. 텍스트 검색은이 필드에서 수행됩니다. 면역화 될 수 있듯이 단일 EMACS LISP 스레드에서 각 문서를 검색해야하므로 각 후보 생성기 기능은 검색을 더 빠르게 수행 할 수 있습니다. 그렇기 때문에 파일 시스템 후보 생성기의 :grep 또는 :rg 와 같은 검색 도구가 표시됩니다. 이것에서 나오는 문서에서 텍스트 쿼리를 수행 할 때이 도구에 의존하여 검색을 수행합니다.
텍스트 쿼리의 경우 각 검색 결과가 공간을 구분합니다. 따라서 teacher student school 입력하면 세 가지 용어에 대한 세 가지 별도의 검색을 수행합니다. 각 용어는 각 문서에 대해 자체 점수를 생성 한 다음 결합하여 최종 점수를 형성합니다. 인용문을 사용하여 단어를 그룹화하여 전체적으로 무언가를 검색 할 수 있으므로 "teacher student school" 단어로 한 가지 검색을 수행합니다.
인용되지 않은 용어는 여러 변형으로 처리되고 병렬로 검색됩니다. 예를 들어 teacherStudentSchool “Teacherstudentschool”(사례 insensitive)뿐만 아니라“교사 _student_school”,“교사-학생 학교”(점수가 낮음), 그리고“교사”,“학생”및“학교”(점수가 낮음)를 검색합니다.
teacher student^ school 학생에게 향상시킬 수 있도록 ^ 와 함께 용어를 높일 수 있습니다. teacher student^2 school^3 에서와 같이 숫자 부스트를 지정할 수도 있습니다.
(term1 term2 ...)~ syntax를 사용하여 서로 가까이 발생하는 용어를 검색 할 수 있습니다. p-search-default-near-line-length 의 값에 따라 항목은 서로 특정 수의 라인 내에 있어야합니다.
P-Search는 검색 결과의 첫 번째 p-search-top-n 값 만 표시합니다. 관련 결과가 보이지 않으면 검색 기준 추가를 고려할 수 있습니다. p-search-observe 명령을 실행하여 특정 결과의 확률을 낮추는 것도 가능합니다. 그렇게하면 항목을 0.3으로 곱하여 항목의 확률이 낮아집니다. Prefix Cu p-search-observe 사용하면 확률을 지정할 수 있습니다. 관찰을 수행하면 확률이 다시 계산되고 결과가 업데이트됩니다.
p-search-peruse-mode 활성화 될 때 본 파일의 백분율을 추적하는 실험적인 글로벌 마이너 모드입니다. 보기 백분율은 검색 결과 섹션에서 업데이트됩니다.
P-Search에는 검색 프로세스 속도를 높이기위한 많은 기계가 포함되어 있습니다. 한편으로는 프로그램적으로 명령을 만들고 다양한 P 검색 기능을 호출하여 원하는대로 세션을 인스턴스화 할 수 있습니다. 다른 한편으로, 사령부 bookmark-set (일반적으로 바인딩 Cx rm )를 사용하여 세션을 북마크하면 세션, 후보 생성기 및 사전을 저장하여 향후 신속하게 액세스 할 수 있습니다.
P 검색의 동작을 구성하는 또 다른 방법은 변수 p-search-default-command-behavior 설정하는 것입니다. setitng는 전 세계적으로 값입니다. p-search 명령의 동작 방식을 구성 할 수 있습니다. 다음과 같이 ".dir-locals.el"파일을 통해 변수를 설정하여 디렉토리-로컬 설정을 가질 수도 있습니다.
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " ))))))) p-search-show-session-preset 명령을 실행하여 현재 세션을 LISP 객체로 표시 할 수 있습니다. 이 데이터 구조를 함수 p-search-setup-buffer 에 전달하면 원하는 P 검색 세션을 프로그래밍 방식으로 생성 할 수 있습니다.


