p search
1.0.0
P-Search es una herramienta de emacs para encontrar cosas. Combina conceptos de la teoría de búsqueda de recuperación de información y bayesiana para ayudar a un usuario a encontrar documentos.
Boolean Búsquedes (es decir, el documento contiene la palabra "x"), aunque simples y útiles, a partir de entonces no coincidan con las creencias previas del buscador sobre dónde están los archivos relevantes. Muchas veces el buscador tiene ideas específicas sobre dónde se encuentra el documento. Al igual que qué tipo de archivo es, quien escribió el documento, cuando se creó el documento. El buscador a menudo no está completamente seguro de cómo aparecen los términos de SEACH o si aparecen en absoluto.
Hasta que P-Search esté disponible en ELPA/MELPA, deberá instalar este paquete manualmente. La única dependencia de P-Search es el montón.
Usando quelpa:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))Usando recto:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))Usando Elpaca:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " )) Se puede iniciar una sesión de búsqueda con el comando p-search . El comando configurará la sesión para buscar archivos, ya sea en el directorio de proyectos (ver Project.el) si existe un proyecto o el directorio actual. Ejecute p-search con el prefijo Cu para instanciar una sesión vacía (TODO).
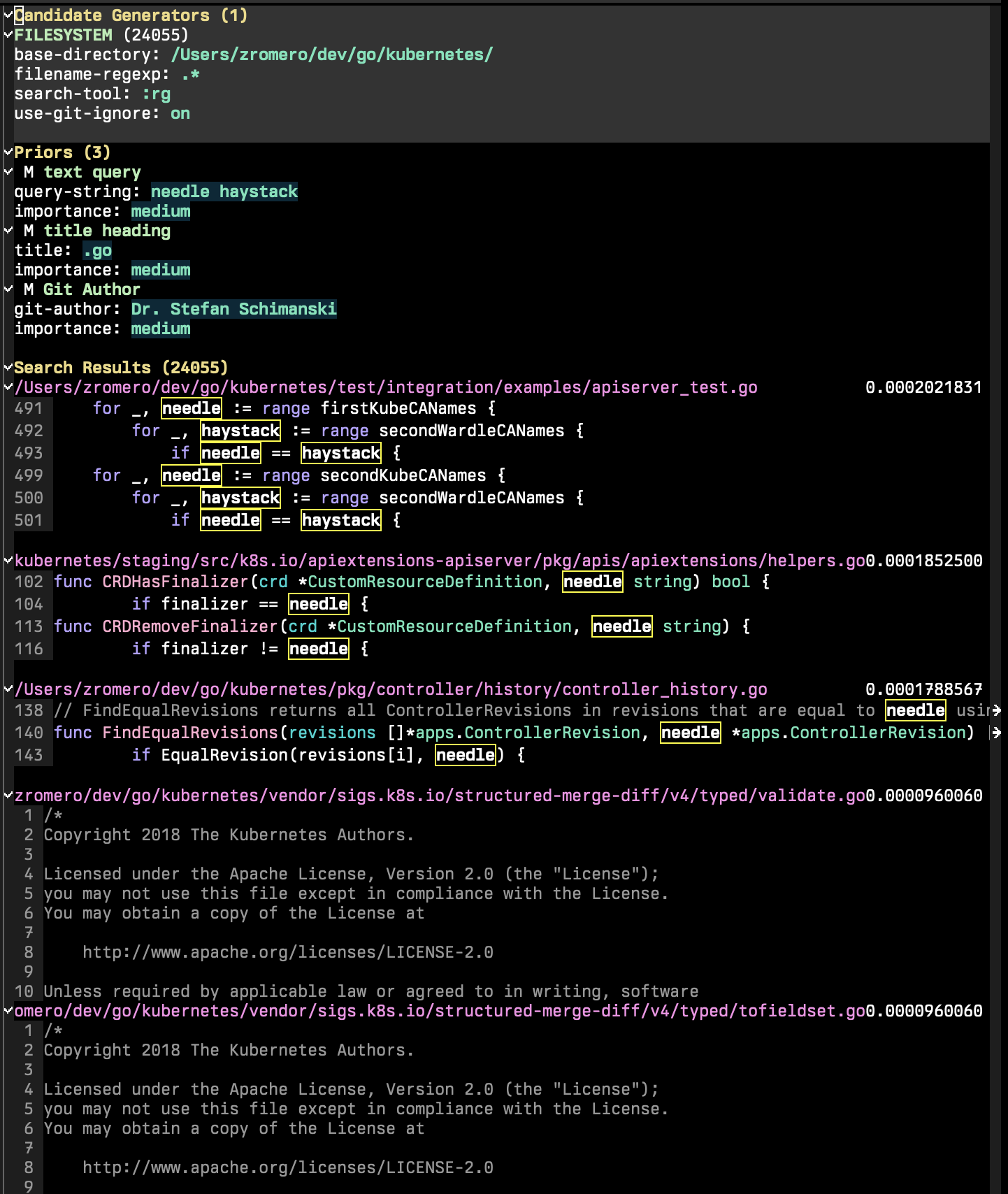
La sesión de búsqueda P se compone de tres secciones principales: generadores candidatos, antecedentes y resultados de búsqueda.
Los generadores candidatos son las partes de la sesión de búsqueda que enumeran todos los candidatos de búsqueda posibles. Un candidato a la búsqueda es una entidad con un conjunto de propiedades clave/valor, 'content y 'title es mandetory. Pueden existir otras propiedades que le permitirán usar funciones anteriores adicionales. En la sesión de P-Search, ejecute p-search-add-candidate-generator ( C ) para agregar un nuevo generador candidato.
Puede eliminar un prior con el comando p-search-kill-entry-at-point .
La sección de Priors es la parte donde agrega criterios de búsqueda a su sesión. Ejecute p-search-add-prior ( P ) para agregar una función anterior.
Primero debe seleccionar el tipo de anterior que desea agregar. Entonces tendrá que configurar el anterior. Primero le solicitará cualquier campo que sean mandetorios.
Después de eso, aparecerá un nuevo menú transitorio, lo que le permite configurar el anterior. Cada función anterior tendrá su propio conjunto de entradas y opciones, pero cada una le permitirá establecer su importancia y si se debe tomar el complemento .
Puede eliminar un prior con el comando p-search-kill-entry-at-point ( k ).
Cada documento candidato recibe una puntuación de cada función anterior dependiendo de qué tan bien coincida la función anterior.
Entonces, por ejemplo, suponga que tiene una búsqueda de consulta de texto. La consulta clasificará cada documento en una escala de 0 a 1. Esta puntuación se modifica por la importancia. Si asigna una gran importancia, las probabilidades se llevarán a los extremos. Una baja importancia lleva las probabilidades a 0.5, reduciendo así su impacto.
Entonces, por ejemplo, si una consulta de búsqueda de texto marcó un documento como altamente relevante, 0.7, pero se le dio una baja importancia, su probabilidad puede modificarse a 0.55, lo que reduce su impacto. Por otro lado, si una consulta de texto coincide mal con una puntuación de 0.3, pero su importancia es baja, entonces su probabilidad se elevará a 0.45.
[Generador candidato] | | [Prior_x] [prior_y] | | -Doc_a-> importancia_x (scATET_X_A) ✖ IMPLICACIÓN_Y (scATIG_Y_A) | | -doc_b-> importancia_x (scATE_X_B) ✖ Imports_y (scATE_Y_B) ... | --- Doc_c-> importancia_x (scATIG_X_C) ✖ Imports_y (score_y_c)
La búsqueda de texto es un componente prominente en P-Search. Si bien la búsqueda de texto funciona de la misma manera que otras funciones anteriores (que resulta en una puntuación de 0 a 1), los mecanismos detrás de ella son más complejos.
Puede crear una consulta de texto seleccionando "Consulta de texto" en el menú transitorio al ejecutar p-search-add-prior .
Luego se le solicitará su consulta. Dependiendo de la consulta que escriba, se crearán uno o más procesos para realizar la búsqueda.
Como se mencionó anteriormente, cada documento candidato de búsqueda tiene un 'content propiedad. La búsqueda de texto se realiza en este campo. Como probablemente pueda inmaginar, tener que buscar cada documento en un solo hilo LISP de emacs es lento, por lo que cada función de generador candidato puede tener un método más rápido para realizar la búsqueda. Es por eso que ve la herramienta de búsqueda como :grep o :rg en el generador de candidatos del sistema de archivos. Al realizar una consulta de texto en los documentos que provienen de esto, dependerá de esta herramienta para realizar la búsqueda.
Para la consulta de texto, cada resultado de la búsqueda está separado en el espacio. Entonces, si escribe teacher student school realizará tres búsquedas separadas para los tres términos. Cada término generará su propio puntaje para cada documento y luego se combinarán para formar un puntaje final. Puede usar citas para agrupar palabras para buscar algo en su conjunto, por lo tanto, "teacher student school" realizará una búsqueda con las palabras en una secuencia.
Los términos no cotizados se procesarán en múltiples variantes y se buscarán en paralelo. Entonces, por ejemplo, teacherStudentSchool buscarán tanto "maestro de educación" (insensible al caso), pero también "maestro_student_school", "maestro-estudiante-escolar" (con una puntuación más baja) y los términos sepolares "maestro", "alumno" y "escuela" (dado incluso un puntaje más bajo).
Puede impulsar un término con ^ para que teacher student^ school dé un impulso al estudiante. También puede especificar un impulso numérico, como en teacher student^2 school^3 .
Puede buscar términos que ocurran uno cerca del otro con la sintaxis (term1 term2 ...)~ . Dependiendo del valor de p-search-default-near-line-length , se requerirá que los elementos estén dentro de un cierto número de líneas entre sí.
P-Search solo le mostrará los primeros valores p-search-top-n de los resultados de búsqueda. Si no está viendo resultados relevantes, puede considerar agregar criterios de búsqueda. También puede ejecutar el comando p-search-observe para reducir la probabilidad de un resultado particular. Hacerlo reducirá la probabilidad del elemento multiplicándolo por 0.3. Con el prefijo Cu p-search-observe , puede especificar la probabilidad. Después de realizar la observación, las probabilidades se recalcularán y los resultados se actualizarán.
p-search-peruse-mode es un modo menor global experimental, que cuando está activo, rastreará el porcentaje de archivos que vio. El porcentaje de vista se actualizará en la sección de resultados de búsqueda.
P-Search contiene una serie de mecanismos para acelerar su proceso de búsqueda. Por un lado, puede crear programáticamente un comando y llamar a varias funciones de búsqueda P para instanciar una sesión a su gusto. Por otro lado, simplemente el marcador de la sesión utilizando el bookmark-set de comandos (generalmente Bound Cx rm ) le permitirá guardar la sesión, los generadores de candidatos y los antecedentes, para acceder rápidamente en el futuro.
Otra forma de configurar el comportamiento de P-Search es establecer la variable p-search-default-command-behavior . Por setitng es el valor a nivel mundial, puede configurar cómo se comporta el comando p-search . También puede establecer la variable a través de un archivo ".dir-leocals.el", como lo siguiente, para tener configuraciones locales de directorio:
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " ))))))) Puede ejecutar el comando p-search-show-session-preset para ver la sesión actual representada como un objeto LISP. Al pasar esta estructura de datos a la función p-search-setup-buffer , puede crear programáticamente la sesión P-Search que desea.


