p search
1.0.0
P-Search-это инструмент EMACS, чтобы найти вещи. Он объединяет концепции из теории поиска информации и байесовской поиска, чтобы помочь пользователю в поиске документов.
Boolean Searchs (то есть документ содержит слово «x»), хотя и простые и полезные, не совпадают с предыдущими убеждениями искателя относительно того, где находятся соответствующие файлы. Часто у поисковика есть конкретные идеи относительно того, где находится документ. Например, какой это тип файла, который является автором документа, когда был создан документ. Поискатель часто не полностью уверен в том, как появляются термины Seach или появляются ли они вообще.
Пока P-поиск не будет доступен в ELPA/MELPA, вам придется установить этот пакет вручную. Единственная зависимость P-поиска-куча.
Используя Quelpa:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))Используя прямые:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))Использование ELPACA:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " )) Поисковый сеанс может быть инициирован с помощью команды p-search . Команда настроит сеанс для поиска файлов либо в каталоге проектов (см. Project.el), если существует проект, либо в текущем каталоге. Выполните p-search с префиксом Cu , чтобы создать пустой сеанс (TODO).
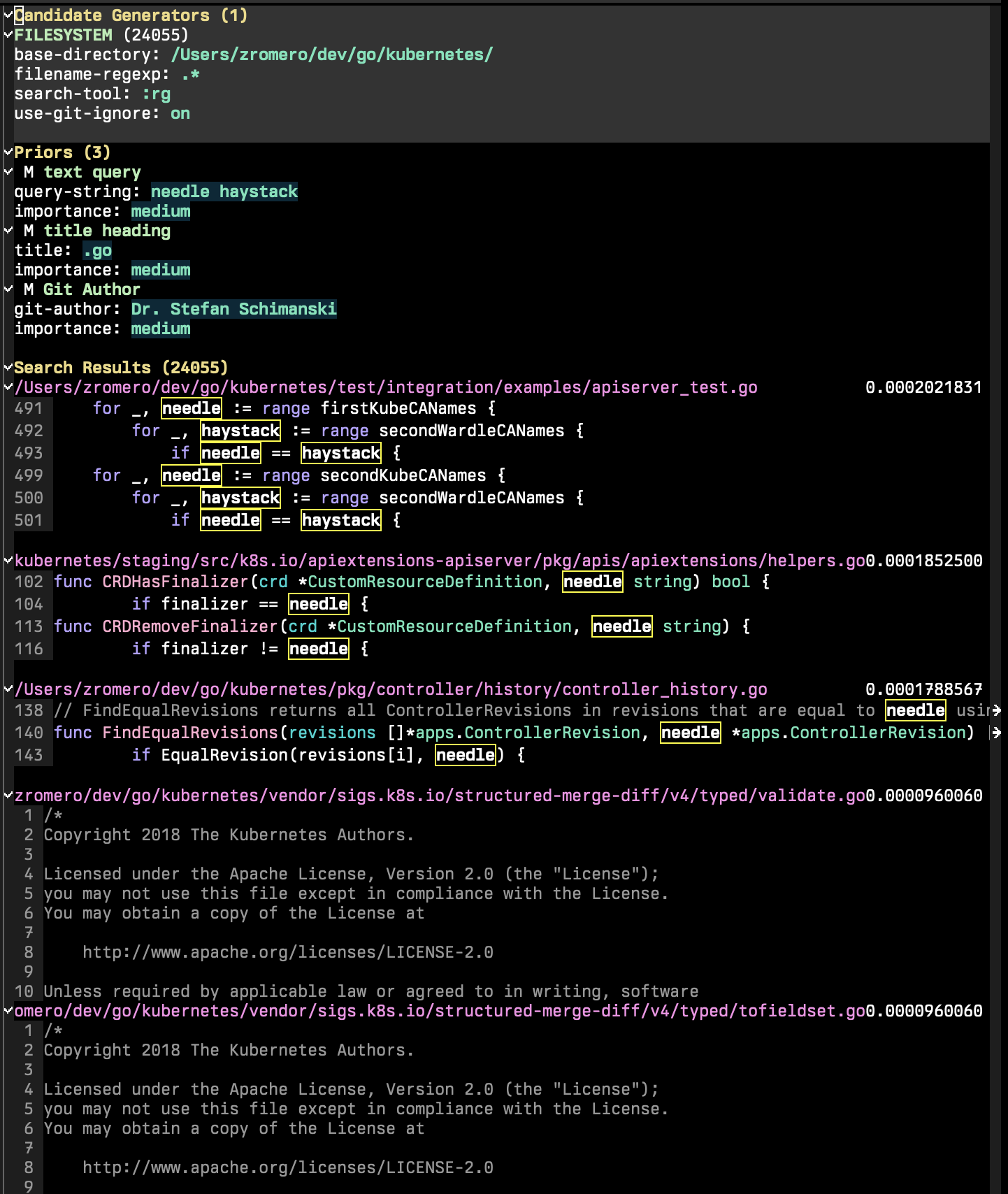
Сессия P-Search состоит из трех основных разделов: генераторы-кандидаты, априоры и результаты поиска.
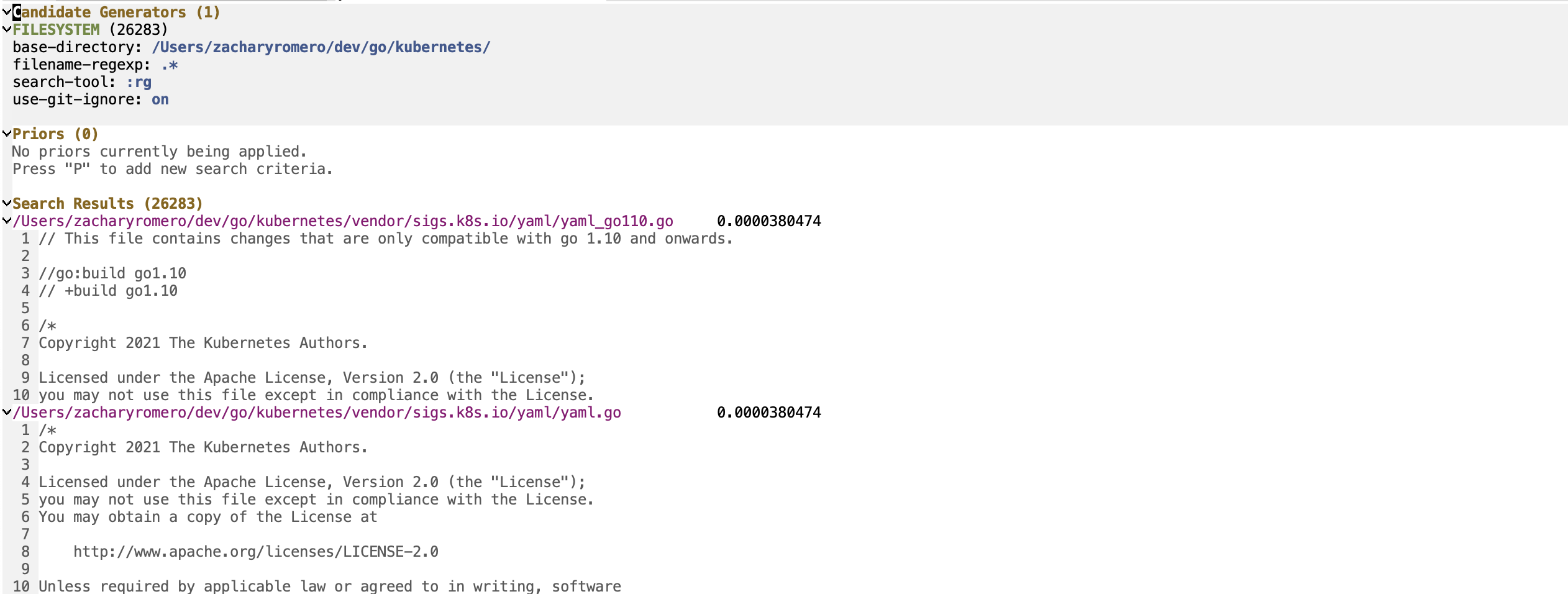
Генераторы кандидатов - это части поисковой сессии, которые перечисляют всех возможных кандидатов на поиск. Кандидат в поисках - это объект с набором свойств ключа/значения, 'content и 'title Мантория». Могут существовать другие свойства, которые позволят вам использовать дополнительные предыдущие функции. В сеансе P-Search запустите p-search-add-candidate-generator ( C ), чтобы добавить новый генератор-кандидат.
Вы можете удалить ранее с командой p-search-kill-entry-at-point .
Раздел Priors - это часть, где вы добавляете критерии поиска в свой сеанс. Запустите p-search-add-prior ( P ), чтобы добавить предыдущую функцию.
Сначала вы должны выбрать тип предыдущего, который вы хотите добавить. Тогда вам придется настроить предварительный. Это сначала подскажет вам любые поля, которые являются Манторией.
После этого появится новое переходное меню, позволяющее вам настроить предварительное. Каждая предыдущая функция будет иметь свой собственный набор входов и параметров, но каждый из них позволит вам установить его важность и следует ли принимать дополнение .
Вы можете удалить ранее с командой p-search-kill-entry-at-point ( k ).
Каждому документу -кандидату дается оценка из каждой предыдущей функции в зависимости от того, насколько хорошо соответствует предварительная функция.
Так, например, предположим, что у вас есть поиск текстового запроса. Запрос будет ранжировать каждый документ по шкале от 0 до 1. Затем этот балл изменяется по важности. Если вы присводите высокое значение, то вероятности будут выдвинуты до крайности. Низкая важность подталкивает вероятности до 0,5, снижая его воздействие.
Так, например, если запрос на текстовый поиск отмечал документ как очень актуальный, 0,7, но получил низкое значение, его вероятность может быть изменена до 0,55, что снижает его воздействие. С другой стороны, если текстовый запрос плохо сочетается с баллом 0,3, но его важность низкая, то его вероятность будет повышена до 0,45.
[Генератор -кандидат] | | [Prior_x] [prior_y] | | -doc_a-> againt_x (score_x_a) ✖ | | -doc_b-> againt_x (score_x_b) ✖ againt_y (score_y_b) ... | --- doc_c-> againt_x (score_x_c) ✖
Текстовый поиск является выдающимся компонентом в p-search. В то время как поиск текста функционирует так же, как и другие предыдущие функции (в результате чего от 0 до 1), мекахнизм, стоящие за ним, являются более сложными.
Вы можете создать текстовый запрос, выбрав «Текстовый запрос» в переходном меню при запуске p-search-add-prior .
Тогда вам будет предложено для вашего запроса. В зависимости от запроса, который вы пишете, будут созданы один или несколько процессов для выполнения поиска.
Как упоминалось ранее, в каждом документе кандидата в поисках есть 'content . Текстовый поиск выполняется в этом поле. Как вы, вероятно, можете иммировать, необходимость поиска каждого документа в одном потоке EMACS LISP является медленной, поэтому каждая функция генератора кандидатов может иметь более быстрый метод для выполнения поиска. Вот почему вы видите инструмент поиска, например :grep или :rg на генераторе кандидатов в файловую систему. При выполнении текстового запроса на документы, поступающие из этого, он будет полагаться на этот инструмент для выполнения поиска.
Для текстового запроса каждый результат поиска разделен пространство. Так что, если вы напечатаете teacher student school она выполнит три отдельных поиска трех терминов. Каждый термин будет генерировать свой собственный счет для каждого документа, и затем они будут объединены, чтобы сформировать окончательный счет. Вы можете использовать цитаты, чтобы группировать слова, чтобы найти что -то в целом, поэтому "teacher student school" выполнит один поиск с словами в последовательности.
Неоцененные термины будут обработаны в несколько вариантов и искать параллельно. Так, например, teacherStudentSchool будет искать как «Teach Instrondentschool» (нечувствительный к делу), но и «wearm_student_school», «учитель-школьник» (с более низким баллом) и секундные термины «учитель», «ученик» и «школа» (приведены даже более низкий счет).
Вы можете увеличить термин с ^ так, чтобы teacher student^ school дала ученый. Вы также можете указать числовое увеличение, как в teacher student^2 school^3 .
Вы можете искать термины, которые встречаются рядом друг с другом с помощью синтаксиса (term1 term2 ...)~ . В зависимости от значения p-search-default-near-line-length , элементы должны будут быть в определенном количестве строк друг от друга.
P-Search покажет вам только первые значения p-search-top-n результатов поиска. Если вы не видите соответствующих результатов, вы можете рассмотреть возможность добавления критериев поиска. Вы также можете запустить команду p-search-observe , чтобы снизить вероятность определенного результата. Это снизит вероятность того, что элемент умножает его на 0,3. С префиксом Cu p-search-observe вы можете указать вероятность. После того, как вы выполните наблюдение, вероятности будут пересматриваться, и результаты будут обновляться.
p-search-peruse-mode -это экспериментальный глобальный незначительный режим, который, когда он активен, будет отслеживать процент просматриваемых вами файлов. Процент представления будет обновлен в разделе «Результаты поиска».
P-Search содержит ряд механизмов для ускорения вашего процесса поиска. С одной стороны, вы можете программатически создавать команду и вызвать различные функции P-поиска, чтобы создать сессию по своему вкусу. С другой стороны, просто в закладке сессия, используя командную bookmark-set (обычно связанную Cx rm ), позволит вам сохранить сеанс, генераторы-кандидаты и анкеры для быстрого доступа в будущем.
Еще один способ настроить поведение p-search-это установить переменную p-search-default-command-behavior . По словам его значения, вы можете настроить, как ведет себя команда p-search . Вы также можете установить переменную через файл.
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " ))))))) Вы можете запустить команду p-search-show-session-preset чтобы увидеть текущий сеанс, представленный как объект LISP. Передав эту структуру данных в функцию p-search-setup-buffer , вы можете программатически создавать желаемый сеанс P-поиска.


