p search
1.0.0
P-Search é uma ferramenta EMACS para encontrar as coisas. Ele combina conceitos da teoria da recuperação de informações e da pesquisa bayesiana para ajudar um usuário a encontrar documentos.
Pesquisas booleanas (ou seja, o documento contém a palavra "x"), embora simples e útil, de então não correspondem às crenças anteriores do pesquisador sobre onde estão os arquivos relevantes. Muitas vezes, o pesquisador tem idéias específicas sobre onde o documento está localizado. Como o tipo de arquivo, quem é o autor do documento, quando o documento foi criado. Muitas vezes, o pesquisador não está totalmente confiante sobre como os termos de seach aparecem ou se aparecem.
Até a P-Search estar disponível no ELPA/MELPA, você precisará instalar este pacote manualmente. A única dependência da pesquisa p é a pilha.
Usando Quelpa:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))Usando reto:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))Usando Elpaca:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " )) Uma sessão de pesquisa pode ser iniciada com o comando p-search . O comando configurará a sessão para pesquisar arquivos no diretório de projetos (consulte Project.el) se existir um projeto ou o diretório atual. Execute p-search com o prefixo Cu para instanciar uma sessão vazia (TODO).
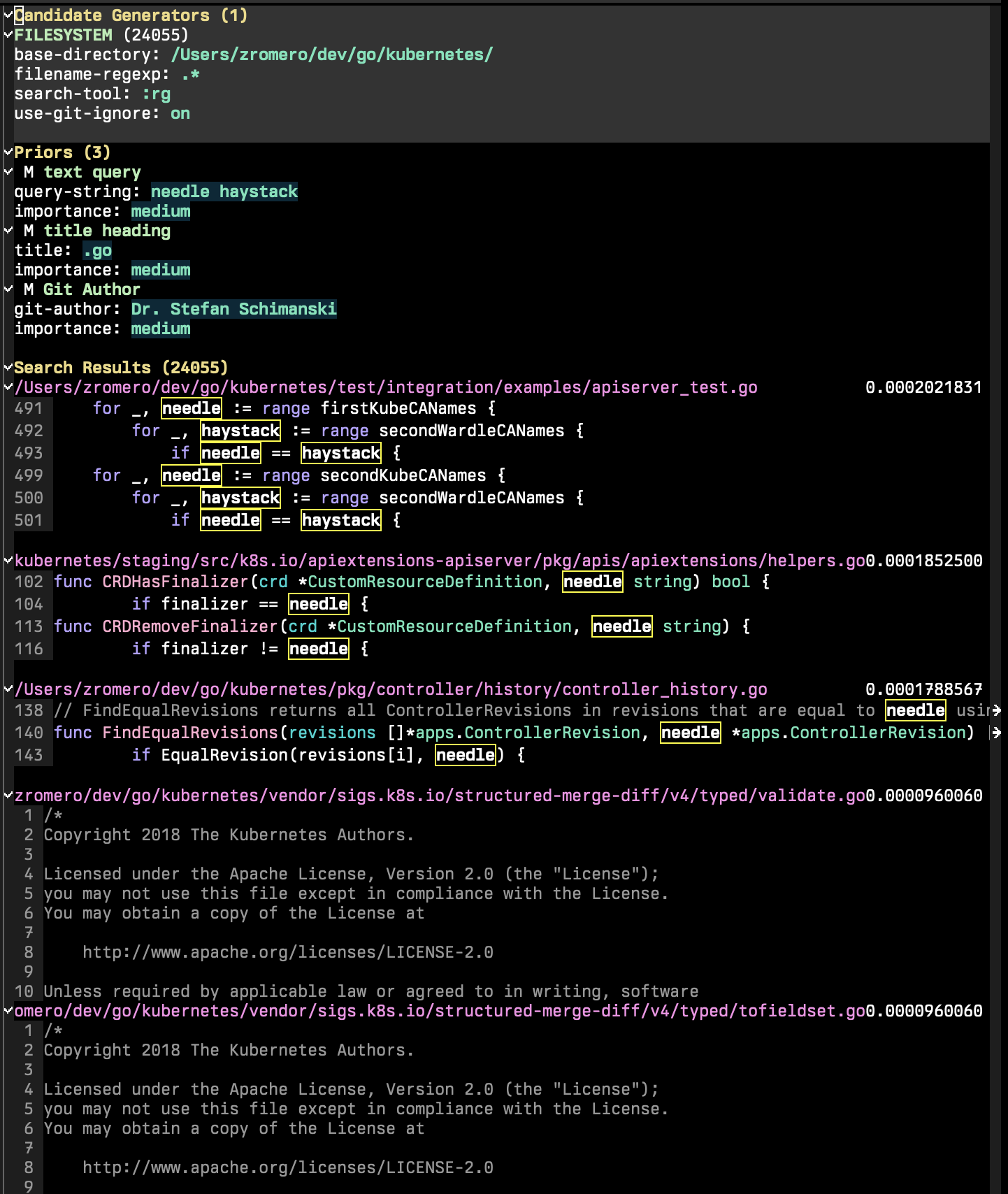
A sessão de busca P é composta por três seções principais: geradores de candidatos, anteriores e resultados de pesquisa.
Geradores de candidatos são as partes da sessão de pesquisa que enumeram todos os candidatos possíveis de pesquisa. Um candidato a pesquisa é uma entidade com um conjunto de propriedades de chave/valor, 'content e 'title sendo mandetório. Outras propriedades podem existir, o que permitirá que você use funções anteriores adicionais. Na sessão P-Search, execute p-search-add-candidate-generator ( C ) para adicionar um novo gerador de candidatos.
Você pode p-search-kill-entry-at-point um anterior com o comando
A seção Priors é a parte em que você adiciona critérios de pesquisa à sua sessão. Execute p-search-add-prior ( P ) para adicionar uma função anterior.
Primeiro, você deve selecionar o tipo de anterior que deseja adicionar. Então você terá que configurar o anterior. Primeiro, ele solicitará a você quaisquer campos que sejam mandetom.
Depois disso, um novo menu transitório aparecerá, permitindo que você configure o anterior. Cada função anterior terá seu próprio conjunto de entradas e opções, mas cada uma permitirá que você defina sua importância e se o complemento deve ser levado.
p-search-kill-entry-at-point pode k um anterior com o comando
Cada documento candidato recebe uma pontuação de cada função anterior, dependendo de quão bem a função anterior corresponde.
Por exemplo, suponha que você tenha uma pesquisa de consulta de texto. A consulta classificará cada documento em uma escala de 0 a 1. Essa pontuação é modificada pela importância. Se você atribuir uma grande importância, as probabilidades serão empurradas para os extremos. Uma baixa importância eleva as probabilidades para 0,5, diminuindo assim seu impacto.
Por exemplo, se uma consulta de pesquisa de texto marcou um documento como altamente relevante, 0,7, mas recebeu uma baixa importância, sua probabilidade pode ser modificada para 0,55, diminuindo assim seu impacto. Por outro lado, se uma consulta de texto corresponder mal a dar uma pontuação de 0,3, mas sua importância for baixa, sua probabilidade será aumentada para talvez 0,45.
[Gerador candidato] | | [Prior_X] [Prior_Y] | | -doc_a-> importância_x (score_x_a) ✖ importância_y (score_y_a) | | -doc_b-> importância_x (score_x_b) ✖ importância_y (score_y_b) ... | --- doc_c-> importância_x (score_x_c) ✖ importância_y (score_y_c)
A pesquisa de texto é um componente proeminente no P-Search. Embora as funções de pesquisa de texto da mesma maneira que outras funções anteriores (resultando em uma pontuação de 0 a 1), os mecahnismos por trás dela são mais complexos.
Você pode criar uma consulta de texto selecionando "Consulta de texto" no menu transitório ao executar p-search-add-prior .
Você será solicitado para sua consulta. Dependendo da consulta que você escrever, um ou mais processos serão criados para executar a pesquisa.
Como mencionado anteriormente, cada documento do candidato de pesquisa possui um 'content propriedade. A pesquisa de texto é realizada neste campo. Como você provavelmente pode imaginar, precisar pesquisar cada documento em um único encadeamento LISP EMACS é lento, para que cada função do gerador candidato possa ter um método mais rápido para executar a pesquisa. É por isso que você vê a ferramenta de pesquisa como :grep ou :rg no gerador candidato do sistema de arquivos. Ao executar uma consulta de texto em documentos provenientes disso, ele contará com essa ferramenta para executar a pesquisa.
Para a consulta de texto, cada resultado de pesquisa é separado pelo espaço. Portanto, se você digitar teacher student school ele realizará três pesquisas separadas pelos três termos. Cada termo gerará sua própria pontuação para cada documento e eles serão combinados para formar uma pontuação final. Você pode usar citações para agrupar palavras para pesquisar algo como um todo, portanto, "teacher student school" realizará uma pesquisa com as palavras em uma sequência.
Termos não cotados serão processados em várias variantes e pesquisados em paralelo. Por exemplo, teacherStudentSchool pesquisarão o "TeacherstudentsChool" (insensível ao caso), mas também "professor_student_school", "professor-aluno-estudante" (com uma pontuação mais baixa) e os termos separados "professor", "aluno" e "escola" (dada até uma pontuação mais baixa).
Você pode aumentar um termo com ^ para que teacher student^ school dê um impulso ao aluno. Você também pode especificar um impulso numérico, como no teacher student^2 school^3 .
Você pode procurar termos que ocorram próximos um do outro com a sintaxe (term1 term2 ...)~ . Dependendo do valor do p-search-default-near-line-length , os itens deverão estar dentro de um certo número de linhas um do outro.
P-Search mostrará apenas os primeiros valores p-search-top-n dos resultados da pesquisa. Se você não estiver vendo resultados relevantes, considere adicionar critérios de pesquisa. Você também pode executar o comando p-search-observe para diminuir a probabilidade de um resultado específico. Isso diminuirá a probabilidade do item multiplicando -o por 0,3. Com o prefixo Cu p-search-observe , você pode especificar a probabilidade. Depois de executar a observação, as probabilidades serão recalculadas e os resultados serão atualizados.
p-search-peruse-mode é um modo global menor experimental, que, quando ativo, rastreará a porcentagem de arquivos que você visualizou. A porcentagem de visualização será atualizada na seção Resultados da pesquisa.
P-Search contém vários mecanismos para acelerar seu processo de pesquisa. Por um lado, você pode criar um comando programaticamente e chamar várias funções de pesquisa P para instanciar uma sessão ao seu gosto. Por outro lado, basta marcar a sessão usando o comando bookmark-set (geralmente Cx rm ) permitirá que você salve a sessão, geradores e anteriores candidatos, para acessar rapidamente no futuro.
Outra maneira de configurar o comportamento da pesquisa P é definir a variável p-search-default-command-behavior . Por seleção de seu valor globalmente, você pode configurar como o comando p-search se comporta. Você também pode definir a variável por meio de um arquivo ".dir-cocals.el", como a seguinte, para ter configurações de diretório local:
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " ))))))) Você pode executar o comando p-search-show-session-preset para ver a sessão atual representada como um objeto LISP. Ao passar essa estrutura de dados para a função p-search-setup-buffer , você pode criar programaticamente a sessão de pesquisa P que deseja.


