p search
1.0.0
P-Search ist ein EMACS-Tool, um Dinge zu finden. Es kombiniert Konzepte aus Informationsabruf und Bayes'sche Suchtheorie, um einem Benutzer bei der Suche nach Dokumenten zu helfen.
Boolesche Suchanfragen (dh das Dokument enthält das Wort „X“), obwohl sie einfach und nützlich sind, dann nicht mit den früheren Überzeugungen des Suchers übereinstimmen, wo sich die relevanten Dateien befinden. Oft hat der Suchende spezifische Ideen, wo sich das Dokument befindet. Zum Beispiel welche Art von Datei, die das Dokument verfasst hat, als das Dokument erstellt wurde. Der Suchende ist oft nicht ganz zuversichtlich, wie die Sach -Begriffe aussehen oder ob sie überhaupt erscheinen.
Bis P-Search bei ELPA/MELPA verfügbar ist, müssen Sie dieses Paket manuell installieren. Die einzige Abhängigkeit von P-Suche ist Heap.
Verwenden von Quelpa:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))Mit geradlinig:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))Verwenden von ELPACA:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " )) Eine Suchsitzung kann mit dem Befehl p-search initiiert werden. In dem Befehl wird die Sitzung so eingerichtet, dass sie entweder im Projektverzeichnis (siehe Projekt.EL) nach Dateien suchen, wenn ein Projekt vorhanden ist oder im aktuellen Verzeichnis. Führen Sie p-search mit dem Präfix Cu aus, um eine leere Sitzung (TODO) zu instanziieren.
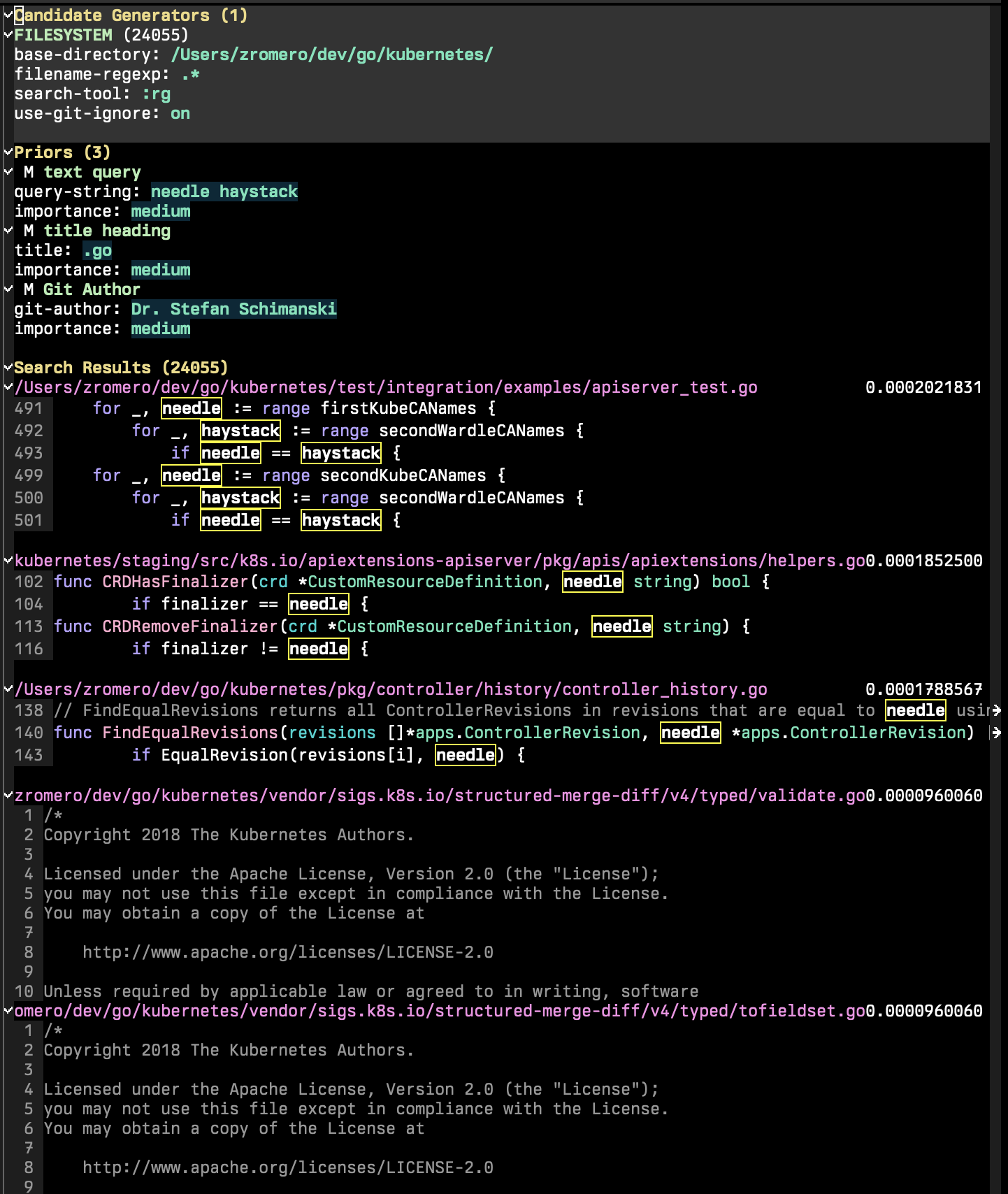
Die P-Search-Sitzung besteht aus drei Hauptabschnitten: Kandidatengeneratoren, Priors und Suchergebnissen.
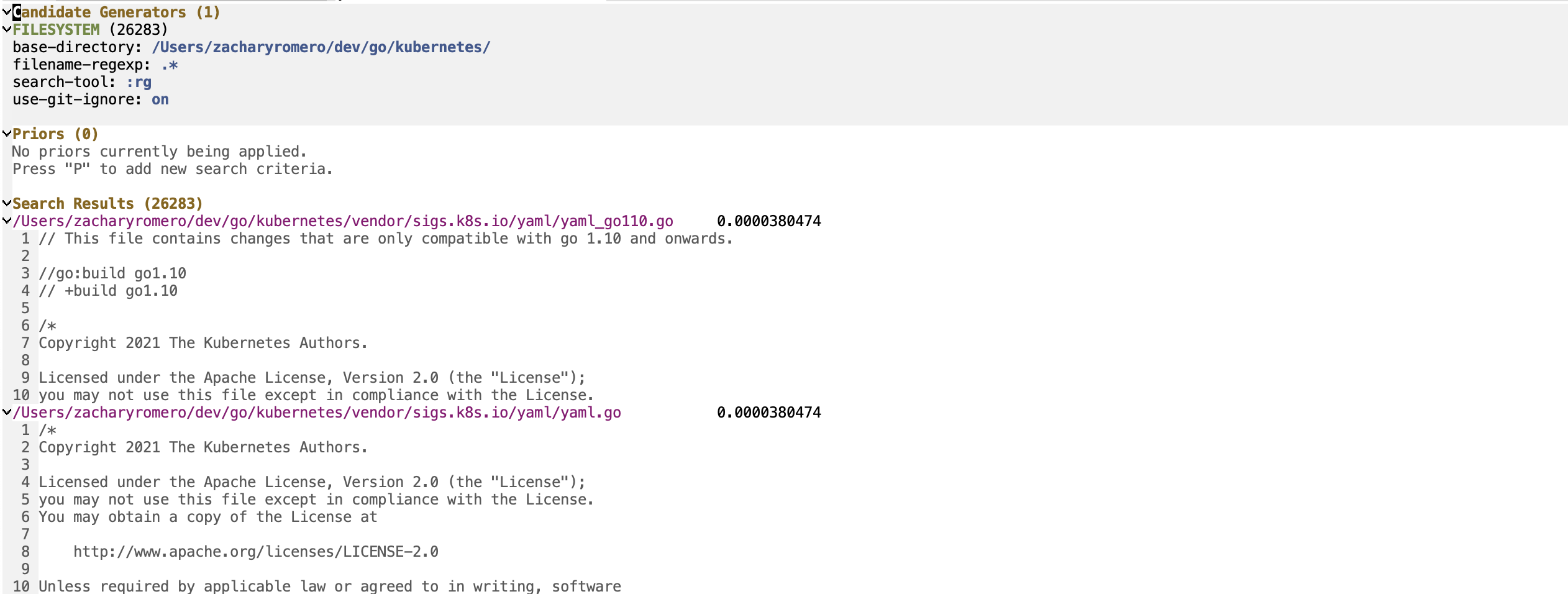
Kandidatengeneratoren sind die Teile der Suchsitzung, die alle möglichen Suchkandidaten aufzählen. Ein Suchkandidat ist ein Entität mit einer Reihe von Schlüssel-/Werteigenschaften, 'content und 'title ist mandetorisch. Möglicherweise gibt es möglicherweise andere Eigenschaften, mit denen Sie zusätzliche frühere Funktionen verwenden können. Führen Sie in der P-Search-Sitzung p-search-add-candidate-generator ( C ) zum Hinzufügen eines neuen Kandidatengenerators.
Sie können einen Prior mit dem Befehl p-search-kill-entry-at-point löschen.
Der Abschnitt Priors ist der Teil, in dem Sie Ihrer Sitzung Suchkriterien hinzufügen. Führen Sie p-search-add-prior ( P ) aus, um eine vorherige Funktion hinzuzufügen.
Zuerst müssen Sie den Prior -Typ auswählen, den Sie hinzufügen möchten. Dann müssen Sie den Prior konfigurieren. Sie werden zuerst alle Felder auffordern, die mandetorisch sind.
Danach wird ein neues transientes Menü angezeigt, mit dem Sie den Prior konfigurieren können. Jede vorherige Funktion verfügt über eigene Eingänge und Optionen, aber bei jeder einzelnen können Sie ihre Bedeutung festlegen und ob das Komplement genommen werden sollte.
Sie können einen Prior mit dem Befehl p-search-kill-entry-at-point ( k ) löschen.
Jedes Kandidatendokument erhält eine Punktzahl aus jeder vorherigen Funktion, je nachdem, wie gut die vorherigen Funktion übereinstimmen.
Nehmen wir zum Beispiel an, Sie haben eine Suchanfrage von Text. Die Abfrage bewertet jedes Dokument auf einer Skala von 0 bis 1. Diese Punktzahl wird dann durch die Bedeutung geändert. Wenn Sie eine hohe Bedeutung zuweisen, werden die Wahrscheinlichkeiten an die Extreme gedrängt. Eine geringe Bedeutung erhöht die Wahrscheinlichkeiten auf 0,5 und senkt so ihre Auswirkungen.
Wenn beispielsweise eine Textsuche ein Dokument als hochrelevante, 0,7 markiert, jedoch eine geringe Bedeutung erhielt, kann ihre Wahrscheinlichkeit auf 0,55 modifiziert werden, wodurch deren Auswirkungen gesenkt werden. Wenn andererseits eine Textabfrage schlecht entspricht, wird eine Punktzahl von 0,3 entspricht, aber seine Bedeutung niedrig ist, dann wird seine Wahrscheinlichkeit auf vielleicht 0,45 erhöht.
[Kandidatengenerator] | | [Prior_x] [prior_y] | | -doc_a-> Bedeutung_x (Score_x_a) ✖ wichtige | | -doc_b-> Bedeutung_x (Score_x_b) ✖ wichtige Punkte (Score_y_b) ... | --- doc_c-> Bedeutung_x (Score_x_c) ✖ wichtige
Die Textsuche ist eine herausragende Komponente in der P-Suche. Während die Textsuche wie andere frühere Funktionen (was zu einer Punktzahl von 0 bis 1) genauso funktioniert, sind die Mecahnismen dahinter komplexer.
Sie können eine Textabfrage erstellen, indem Sie im transienten Menü "Textabfrage" auswählen, wenn Sie p-search-add-prior ausführen.
Sie werden dann für Ihre Anfrage aufgefordert. Abhängig von der Abfrage, die Sie schreiben, werden ein oder mehrere Prozesse erstellt, um die Suche durchzuführen.
Wie bereits erwähnt, verfügt jedes Suchkandidat -Dokument über einen 'content Eigenschaft. Die Textsuche wird in diesem Feld durchgeführt. Da Sie wahrscheinlich immaginen können, ist es langsam, jedes Dokument auf einem einzigen EMACS -LISP -Thread durchsuchen zu müssen, sodass jede Funktion für die Suche nach Kandidatengenerator eine schnellere Methode zur Durchführung der Suche aufweisen kann. Aus diesem Grund sehen Sie das Suchwerkzeug wie :grep oder :rg im Dateisystemkandidatengenerator. Bei der Ausführung einer Textabfrage zu Dokumenten, die davon stammen, wird sie auf dieses Tool beruhen, um die Suche durchzuführen.
Für die Textabfrage ist jedes Suchergebnis Platz getrennt. Wenn Sie also teacher student school eingeben, werden drei separate Suchanfragen nach den drei Begriffen durchgeführt. Jeder Begriff generiert eine eigene Punktzahl für jedes Dokument und wird dann kombiniert, um eine Enderbewertung zu bilden. Sie können Zitate verwenden, um Wörter zu gruppieren, um etwas als Ganzes zu durchsuchen. Daher führt "teacher student school" eine Suche mit den Wörtern in einer Sequenz durch.
Nicht geeignete Begriffe werden in mehrere Varianten verarbeitet und parallel gesucht. So werden beispielsweise teacherStudentSchool sowohl nach „TeacherStudentSchool“ (Fall unempfindlich), aber auch „lehrer_student_school“, „Lehrer-Schüler-School“ (mit einer niedrigeren Punktzahl) und den seelenen Begriffen „Lehrer“, „Schüler“ und „Schule“ durchsuchen (mit einer niedrigeren Punktzahl).
Sie können einen Begriff mit ^ so steigern, dass teacher student^ school an die Schüler steigert wird. Sie können auch einen numerischen Schub angeben, wie in teacher student^2 school^3 .
Sie können nach Begriffen suchen, die mit der (term1 term2 ...)~ Syntax in der Nähe voneinander auftreten. Abhängig vom Wert der p-search-default-near-line-length müssen die Elemente innerhalb einer bestimmten Anzahl von Zeilen voneinander entfernt sein.
P-Search zeigt Ihnen nur die ersten p-search-top-n Werte der Suchergebnisse an. Wenn Sie keine relevanten Ergebnisse sehen, sollten Sie in Betracht ziehen, Suchkriterien hinzuzufügen. Sie können auch den Befehl p-search-observe ausführen, um die Wahrscheinlichkeit eines bestimmten Ergebnisses zu senken. Dies senkt die Wahrscheinlichkeit des Elements durch Multiplizieren mit 0,3. Mit dem Präfix Cu p-search-observe können Sie die Wahrscheinlichkeit angeben. Nachdem Sie die Beobachtung durchgeführt haben, werden die Wahrscheinlichkeiten neu berechnet und die Ergebnisse aktualisieren.
p-search-peruse-mode ist ein experimenteller globaler kleiner Moll-Modus, der den Prozentsatz der von Ihnen angezeigten Dateien verfolgt. Der Ansichtsprozentsatz wird im Abschnitt Suchergebnisse aktualisiert.
P-Search enthält eine Reihe von Mechanims, um Ihren Suchprozess zu beschleunigen. Einerseits können Sie programmatisch einen Befehl erstellen und verschiedene P-Search-Funktionen aufrufen, um eine Sitzung nach Ihren Wünschen zu instanziieren. Auf der anderen Seite können Sie die Sitzung einfach mit dem Befehls bookmark-set (normalerweise gebundener Cx rm ) einbrocken, um die Sitzung, Kandidatengeneratoren und Priors, zu speichern, um in Zukunft schnell zugreifen zu können.
Eine andere Möglichkeit, das Verhalten von P-Such zu konfigurieren, besteht darin, das Variable p-search-default-command-behavior einzustellen. Durch SetItng ist es weltweit Wert. Sie können konfigurieren, wie sich der Befehl p-search verhält. Sie können die Variable auch über eine ".dir-locals.el" -Datei wie folgt festlegen, um Verzeichnis-lokale Einstellungen zu haben:
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " ))))))) Sie können den Befehl p-search-show-session-preset ausführen, um die aktuelle Sitzung als Lisp-Objekt darzustellen. Indem Sie diese Datenstruktur an die Funktion p-search-setup-buffer übergeben, können Sie die gewünschte P-Search-Sitzung programmatisch erstellen.


