p search
1.0.0
P-Search是找到事物的效果工具。它结合了信息检索和贝叶斯搜索理论的概念,以帮助用户查找文档。
布尔搜索(即文档包含“ x”一词),虽然简单且有用,但不符合搜索者在相关文件所在的位置的先前信念。通常,搜索者对文档的位置有特定的想法。就像是什么类型的文件一样,在创建文档时撰写了文档。搜索者通常对SEACH术语的出现或是否出现并不完全自信。
在ELPA/MELPA上提供P-Search之前,您必须手动安装此软件包。 p-search的唯一依赖性是堆。
使用Quelpa:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))使用直线:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))使用elpaca:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " ))可以使用p-search命令启动搜索会话。该命令将设置会话以搜索项目目录中的文件(请参见项目)或当前目录。使用前缀Cu执行p-search以实例化空话(todo)。
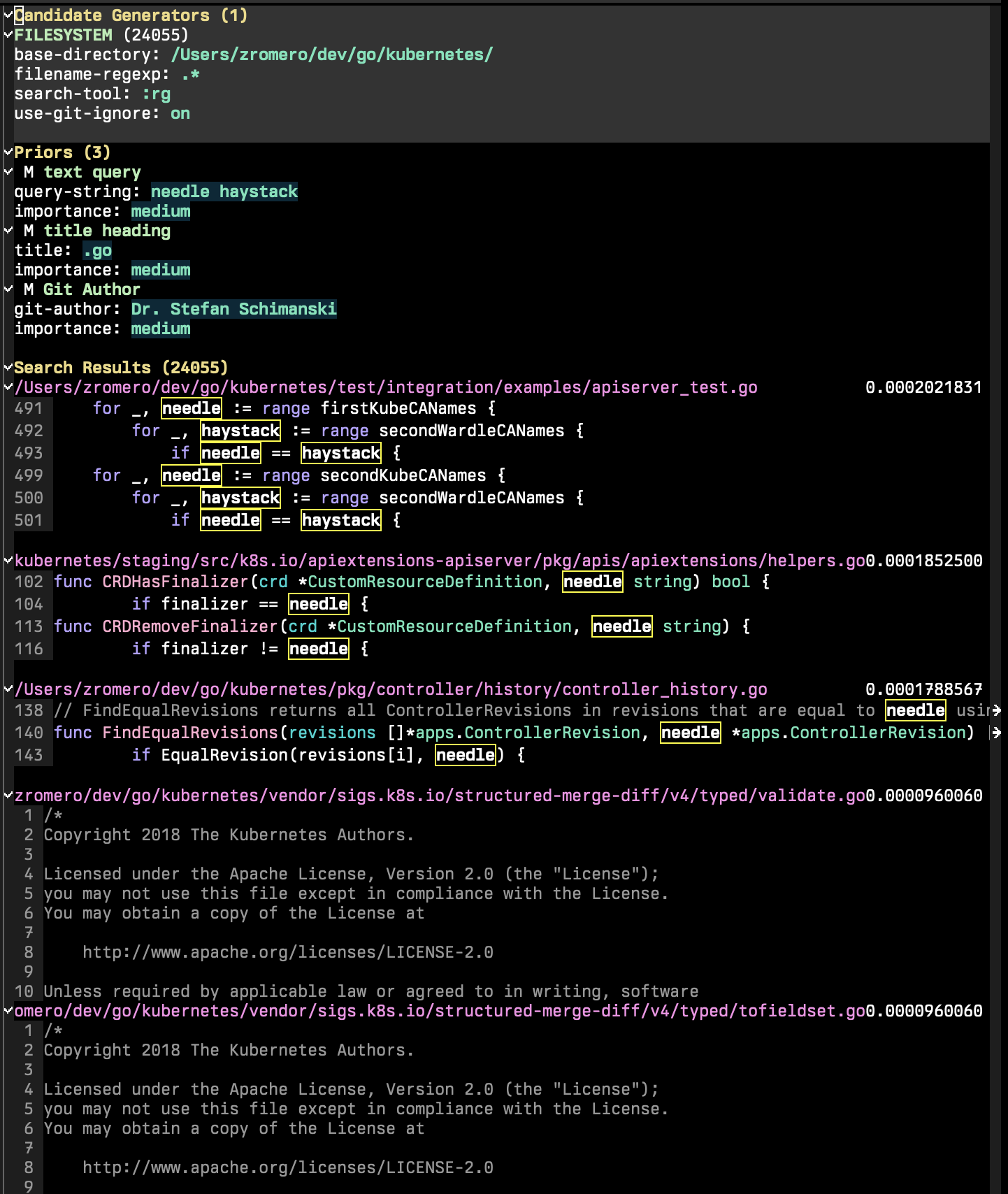
P-Search会议由三个主要部分组成:候选生成器,先验和搜索结果。
候选生成器是搜索会话的一部分,列举了所有可能的搜索候选者。搜索候选者是一个具有一组密钥/值属性的实体, 'content和'title为mandetory。可能存在其他属性,这将使您可以使用其他先验功能。在P-Search会话中,运行p-search-add-candidate-generator ( C )添加新的候选生成器。
您可以使用命令p-search-kill-entry-at-point删除先验。
“先验”部分是您在会话中添加搜索条件的部分。运行p-search-add-prior ( P )以添加先验功能。
首先,您必须选择要添加的先验类型。然后,您将必须配置先验。它会首先提示您获取任何符合要求的字段。
之后,将出现一个新的瞬态菜单,允许您配置先验。每个先前的功能都将具有自己的一组输入和选项,但是每个功能都可以让您设置其重要性以及是否应采取补充。
您可以使用命令p-search-kill-entry-at-point ( k )删除先验。
根据先前功能的匹配程度,每个候选文档都会从每个先前的功能中给出分数。
因此,例如,假设您有文本查询搜索。查询将以0到1的比例对每个文档进行排名。然后,该分数通过重要性修改。如果您分配了高度的重视,那么概率将被推到极端。较低的重要性将概率提高到0.5,从而降低了其影响。
因此,例如,如果文本搜索查询将文档标记为高度相关的0.7,但重点较低,则其概率可能会被修改为0.55,从而降低其影响。另一方面,如果文本查询匹配不佳,得分为0.3,但其重要性很低,则其概率将提高到0.45。
[候选生成器] | | [PIRIC_X] [PIRIC_Y] | | - doc_a--> questional_x(score_x_a)✖ | | - doc_b-> guentionals_x(score_x_b)✖ | --- doc_c-> guentionce_x(score_x_c)✖
文本搜索是p-search中的重要组成部分。虽然文本搜索的功能与其他先前功能相同(得分为0到1),但其背后的麦克海斯主义更为复杂。
您可以在运行p-search-add-prior时在瞬态菜单中选择“文本查询”来创建文本查询。
然后,您将提示您查询。根据您编写的查询,将创建一个或多个进程来执行搜索。
如前所述,每个搜索候选文档都有一个属性'content 。文本搜索在此字段上执行。您可能可能会不会出现,因此必须在单个Emacs Lisp线程上搜索每个文档很慢,因此每个候选生成器函数都可以具有更快的方法来执行搜索。这就是为什么您会在文件系统候选生成器上看到搜索工具:grep或:rg 。在对此文档进行文本查询时,它将依靠此工具来执行搜索。
对于文本查询,每个搜索结果均分开。因此,如果您键入teacher student school则将对三个任期进行三个单独的搜索。每个学期将为每个文档生成自己的分数,然后将它们合并成最终分数。您可以使用引号将单词分组以搜索整体,因此"teacher student school"将通过顺序执行一个搜索。
未引用的术语将被处理为多个变体,并并行搜索。因此,例如, teacherStudentSchool将同时搜索“ Teacterstudents Chool”(案例不敏感),也将搜索“ Teacher_student_school”,“教师学生学校”(分数较低)和分离术语“老师”,“学生”,“学生”和“学校”(甚至得分较低)(得分较低)。
您可以通过^来提高学期,以便teacher student^ school可以促进学生。您也可以指定一个数字提升,例如在teacher student^2 school^3 。
您可以使用(term1 term2 ...)~语法搜索彼此接近的术语。根据p-search-default-near-line-length的值,这些项目将被要求彼此之间的一定数量。
p-search只会向您显示搜索结果的第一个p-search-top-n值。如果您没有看到相关结果,则可能需要考虑添加搜索标准。您还可以运行命令p-search-observe以降低特定结果的概率。这样做将通过将项目乘以0.3来降低项目的概率。使用前缀Cu p-search-observe ,您可以指定概率。执行观察结果后,将重新计算概率,结果将更新。
p-search-peruse-mode是一种实验性的全球次要模式,在活动时,它将跟踪您查看的文件的百分比。视图百分比将在搜索结果部分中更新。
P-Search包含许多机制来加快您的搜索过程。一方面,您可以从编程中创建命令并调用各种p-search函数,以使会话对您的喜好进行实例化。另一方面,只需使用命令bookmark-set (通常是绑定的Cx rm )将会话添加书签,这将使您保存会话,候选人的生成器和先验,以便将来快速访问。
配置P-Search行为的另一种方法是设置变量p-search-default-command-behavior 。通过设置它的值,您可以在全球范围内配置命令p-search的行为。您还可以通过“ .dir-locals.el”文件设置变量,如下所示,具有目录 - 局部设置:
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " )))))))您可以运行命令p-search-show-session-preset以查看当前会话表示为LISP对象。通过将此数据结构传递给函数p-search-setup-buffer ,您可以按程序上创建所需的p-search会话。


