p search
1.0.0
P-Searchは、物を見つけるためのEMACSツールです。情報検索とベイズの検索理論からの概念を組み合わせて、ユーザーがドキュメントを見つけるのを支援します。
ブール検索(つまり、ドキュメントには「x」という単語が含まれています)が、シンプルで便利ですが、関連するファイルがどこにあるかに関する検索者の以前の信念と一致しません。多くの場合、検索者はドキュメントのどこにあるかについて特定のアイデアを持っています。ドキュメントが作成されたときに、ドキュメントを作成したファイルの種類と同様に。検索者は、多くの場合、Seachの用語がどのように表示されるか、またはそれらがまったく表示されるかどうかについて完全に自信がありません。
P-SearchがELPA/MELPAで利用可能になるまで、このパッケージを手動でインストールする必要があります。 p-searchの唯一の依存関係はヒープです。
Quelpaの使用:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))ストレートの使用:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))ELPACAの使用:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " ))p-searchコマンドで検索セッションを開始できます。コマンドは、プロジェクトが存在する場合はプロジェクトディレクトリ(Project.elを参照)または現在のディレクトリのいずれかでファイルを検索するようにセッションを設定します。 Prefix Cuでp-searchを実行して、空のセッション(TODO)をインスタンス化します。
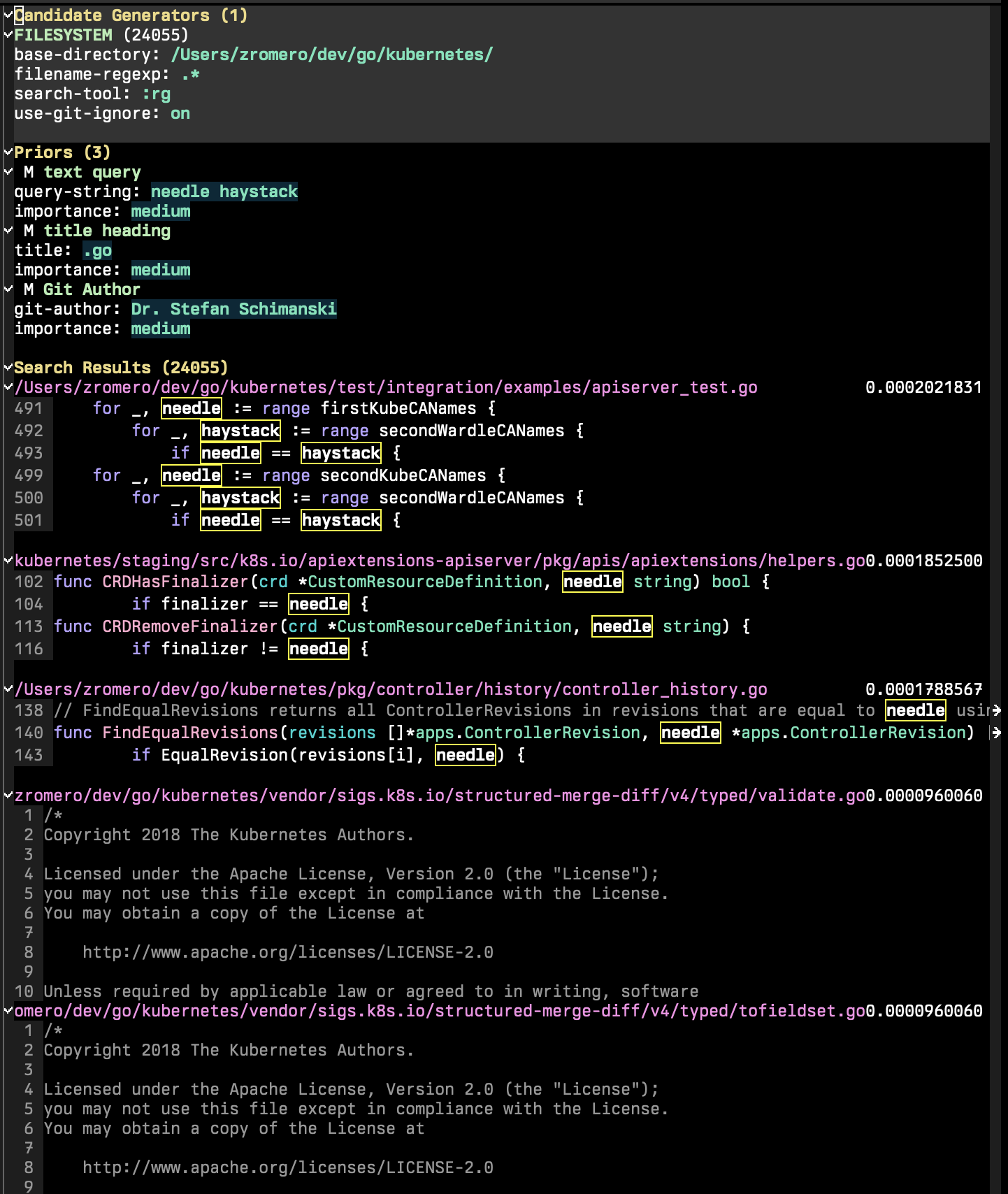
P-Searchセッションは、候補ジェネレーター、プライアー、および検索結果の3つの主要なセクションで構成されています。
候補ジェネレーターは、可能なすべての検索候補を列挙する検索セッションの部分です。検索候補は、キー/バリュープロパティのセット、 'content 、および'titleがマンデトリーであるエンティティ」です。追加の事前関数を使用できる他のプロパティが存在する場合があります。 p-searchセッションではp-search-add-candidate-generator ( C )を実行して、新しい候補ジェネレーターを追加します。
コマンドp-search-kill-entry-at-pointで以前を削除できます。
Priorsセクションは、セッションに検索基準を追加する部分です。 p-search-add-prior ( P )を実行して、以前の関数を追加します。
最初に、追加する前のタイプのタイプを選択する必要があります。その後、事前に構成する必要があります。まず、マンデトリーのフィールドを求めます。
その後、新しい一時的なメニューが表示され、前のメニューを構成できます。それぞれの以前の関数には、独自の入力とオプションのセットがありますが、それぞれがその重要性と補体を取るべきかどうかを設定することができます。
コマンドp-search-kill-entry-at-point ( k )で以前を削除できます。
各候補のドキュメントには、以前の関数がどれだけうまく一致するかに応じて、各以前の関数からスコアが与えられます。
たとえば、テキストクエリ検索があるとします。クエリは、各ドキュメントを0から1までのスケールでランク付けします。このスコアは重要性によって変更されます。重要性が高い場合、確率は極端にプッシュされます。重要性が低いと確率が0.5に押し付けられ、その衝撃が低下します。
したがって、たとえば、テキスト検索クエリがドキュメントを非常に関連性のある0.7とマークしたが、重要性が低い場合、その確率は0.55に変更される可能性があるため、その衝撃が低下します。一方、テキストクエリの一致が0.3のスコアの不十分な場合、その重要性が低い場合、その確率はおそらく0.45に引き上げられます。
[候補ジェネレーター] | | [prior_x] [prior_y] | | -doc_a-> cuttom_x(score_x_a)✖faltion_y(score_y_a) | | -doc_b-> cuttom_x(score_x_b)✖faltion_y(score_y_b)... | --- doc_c-> cuptition_x(score_x_c)✖fatement_y(score_y_c)
テキスト検索は、P-Searchの顕著なコンポーネントです。テキスト検索は、他の以前の関数と同じように機能しますが(0から1のスコアになります)、その背後にあるメカニズムはより複雑です。
p-search-add-priorを実行するときに、Transientメニューで「テキストクエリ」を選択することにより、テキストクエリを作成できます。
その後、クエリを求められます。書いたクエリに応じて、検索を実行するために1つ以上のプロセスが作成されます。
前述のように、各検索候補のドキュメントにはプロパティ'contentがあります。このフィールドでテキスト検索が実行されます。おそらくイマジンをすることができるように、単一のemacs lispスレッドで各ドキュメントを検索しなければならないのは遅いため、各候補のジェネレーター関数は検索を実行するためのより迅速な方法を持つことができます。これが、ファイルシステム候補ジェネレーターの:grepまたは:rgのような検索ツールを見る理由です。これからのドキュメントでテキストクエリを実行すると、このツールに依存して検索を実行します。
テキストクエリの場合、各検索結果はスペース分離です。したがって、 teacher student schoolと入力すると、3つの用語に対して3つの個別の検索が行われます。各用語は、各ドキュメントに対して独自のスコアを生成し、その後、それらを組み合わせて最終スコアを形成します。引用符を使用して単語をグループ化して何かを全体として検索することができます。したがって、 "teacher student school"単語をシーケンスで1回検索します。
引用されていない用語は、複数のバリアントに処理され、並行して検索されます。したがって、たとえば、 teacherStudentSchoolは、「Teacherstudentsschool」(ケースの鈍感)だけでなく、「Teacher_student_school」、「教師と学生の学校」(スコアが低い)、および「教師」、「生徒」、「学校」(低いスコアも与えられます)の両方を検索します。
teacher student^ school生徒を後押しするように、 ^で用語をブーストできます。 teacher student^2 school^3のように、数値ブーストを指定することもできます。
(term1 term2 ...)~ 〜Syntaxで互いに近くで発生する用語を検索できます。 p-search-default-near-line-lengthの値に応じて、アイテムは互いに特定の数の行内である必要があります。
p-searchは、検索結果の最初のp-search-top-n値のみを表示します。関連する結果が表示されていない場合は、検索条件の追加を検討することをお勧めします。また、コマンドp-search-observeを実行して、特定の結果の確率を下げることもできます。そうすることで、アイテムに0.3を掛けることで、アイテムの確率が低下します。接頭辞Cu p-search-observeを使用すると、確率を指定できます。観察を実行すると、確率が再計算され、結果が更新されます。
p-search-peruse-modeは、実験的なグローバルマイナーモードであり、アクティブな場合、表示したファイルの割合を追跡します。ビューの割合は、検索結果セクションで更新されます。
P-Searchには、検索プロセスをスピードアップするための多数のメカニムが含まれています。一方では、コマンドをプログラム的に作成し、さまざまなP-Search関数を呼び出して、お好みに合わせてセッションをインスタンス化できます。もう1つは、コマンドbookmark-set (通常はバインドされたCx rm )を使用してセッションをブックマークするだけで、セッション、候補ジェネレーター、および事前に保存して、将来すばやくアクセスできます。
p-searchの動作を構成する別の方法は、可変p-search-default-command-behaviorを設定することです。 Setitngとは、グローバルに値であり、コマンドp-search動作方法を構成できます。 「.dir-locals.el」ファイルを介して変数を設定して、次のように、Directory-Local Settingsを持つこともできます。
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " )))))))コマンドp-search-show-session-presetを実行して、現在のセッションがLISPオブジェクトとして表されることを確認できます。このデータ構造を関数p-search-setup-bufferに渡すことにより、必要なp-searchセッションをプログラムで作成できます。


