p search
1.0.0
P-pencarian adalah alat Emacs untuk menemukan sesuatu. Ini menggabungkan konsep dari teori pencarian pengambilan informasi dan Bayesian untuk membantu pengguna dalam menemukan dokumen.
Pencarian boolean (yaitu dokumen berisi kata "x"), walaupun sederhana dan berguna, kadang -kadang tidak cocok dengan keyakinan sebelumnya dari pencari tentang di mana file yang relevan berada. Sering kali pencari memiliki ide -ide spesifik tentang di mana dokumen berada. Seperti jenis file apa itu, yang menulis dokumen, ketika dokumen dibuat. Pencari sering kali tidak sepenuhnya percaya diri tentang bagaimana istilah SECARA muncul atau apakah mereka muncul sama sekali.
Sampai P-Search tersedia di ELPA/MELPA, Anda harus menginstal paket ini secara manual. Satu-satunya ketergantungan P-pencarian adalah tumpukan.
Menggunakan quelpa:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))Menggunakan Straight:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))Menggunakan Elpaca:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " )) Sesi pencarian dapat dimulai dengan perintah p-search . Perintah akan mengatur sesi untuk mencari file baik di direktori proyek (lihat Project.el) Jika ada proyek atau direktori saat ini. Jalankan p-search dengan awalan Cu untuk membuat instantiate sesi kosong (TODO).
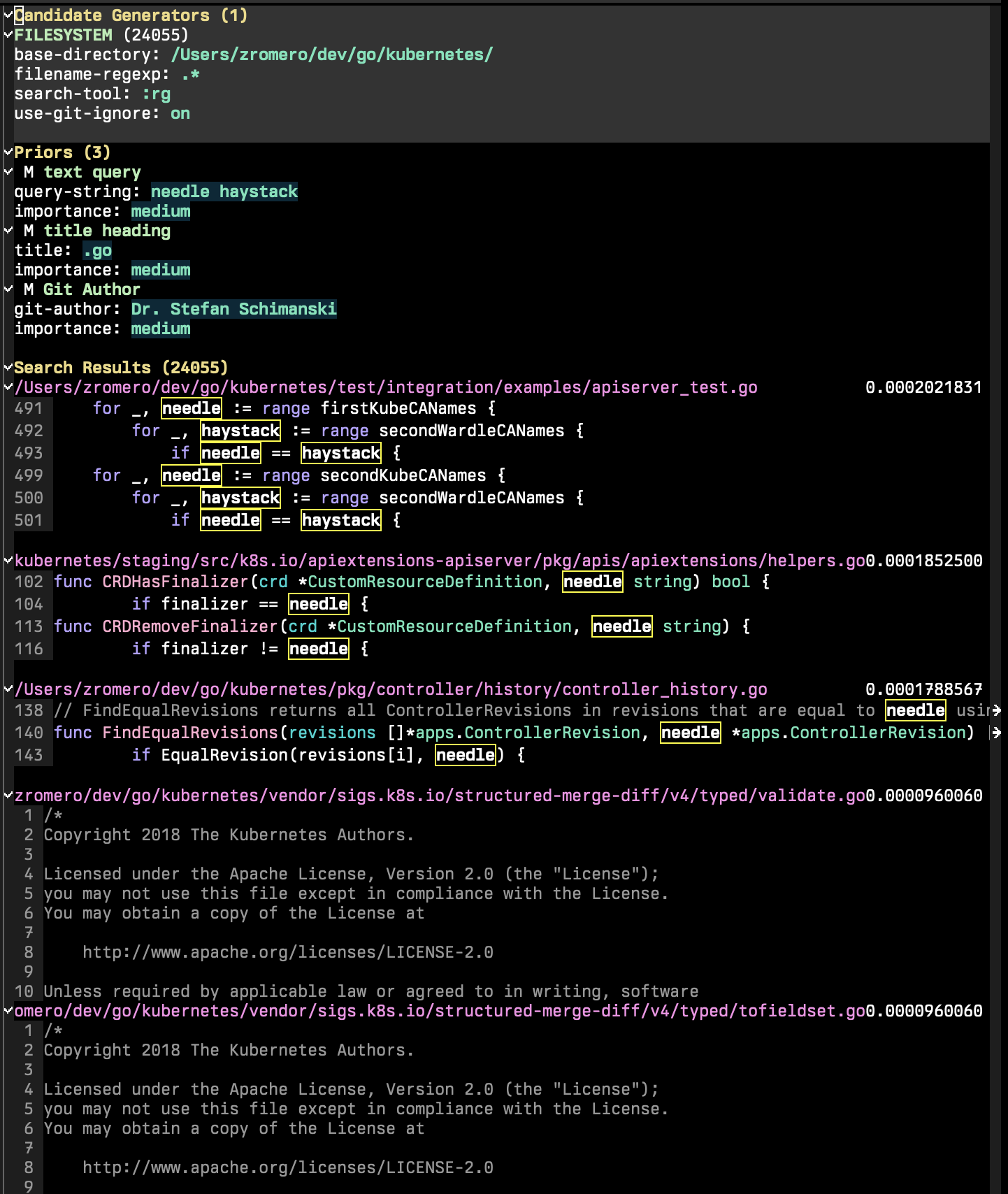
Sesi P-pencarian terdiri dari tiga bagian utama: kandidat generator, prior, dan hasil pencarian.
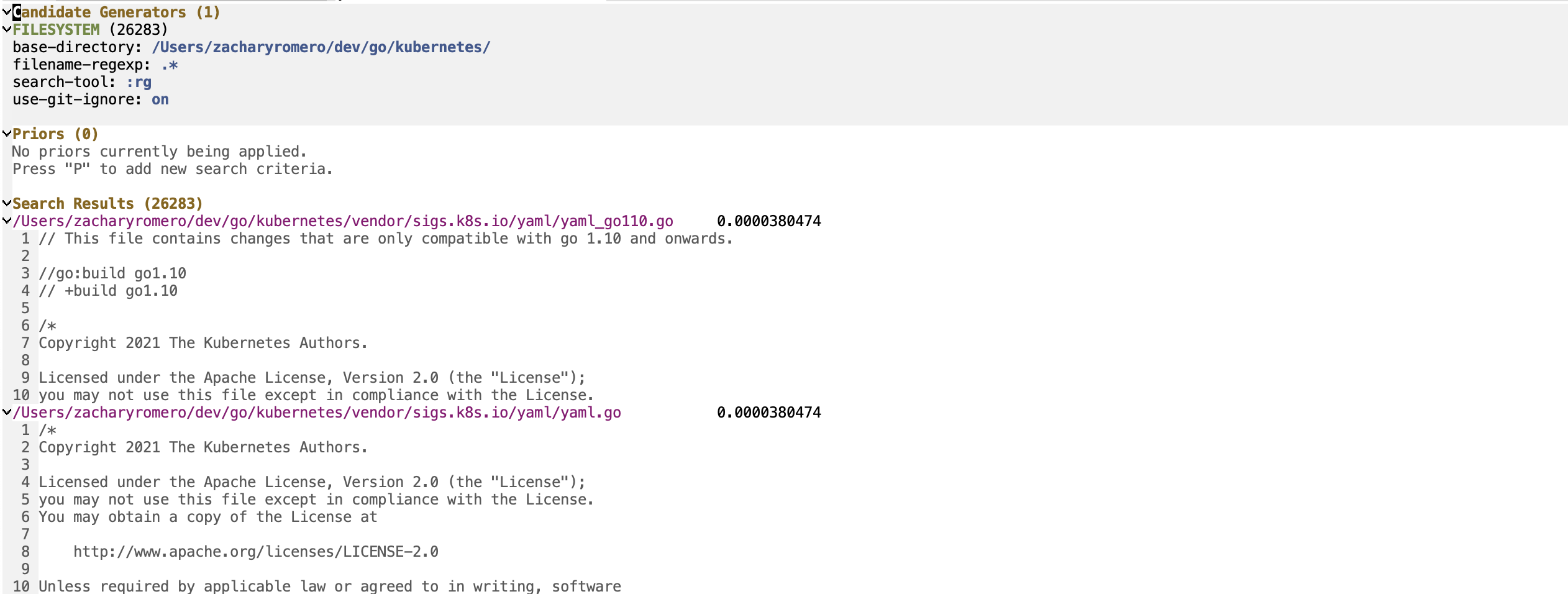
Generator kandidat adalah bagian dari sesi pencarian yang menyebutkan semua kandidat pencarian yang mungkin. Kandidat pencarian adalah entitas dengan satu set properti kunci/nilai, 'content dan 'title wajib. Properti lain mungkin ada yang memungkinkan Anda untuk menggunakan fungsi tambahan sebelumnya. Dalam sesi P-pencarian menjalankan p-search-add-candidate-generator ( C ) untuk menambahkan generator kandidat baru.
Anda dapat menghapus prior dengan perintah p-search-kill-entry-at-point .
Bagian Priors adalah bagian di mana Anda menambahkan kriteria pencarian ke sesi Anda. Jalankan p-search-add-prior ( P ) untuk menambahkan fungsi sebelumnya.
Pertama, Anda harus memilih jenis sebelumnya yang ingin Anda tambahkan. Maka Anda harus mengonfigurasi sebelumnya. Ini pertama -tama akan meminta Anda untuk setiap bidang yang wajib.
Setelah itu, menu transien baru akan muncul, memungkinkan Anda mengonfigurasi sebelumnya. Setiap fungsi sebelumnya akan memiliki set input dan opsi sendiri, tetapi masing -masing akan membiarkan Anda menetapkan kepentingannya dan apakah komplemen harus diambil.
Anda dapat menghapus prior dengan perintah p-search-kill-entry-at-point ( k ).
Setiap dokumen kandidat diberikan skor dari setiap fungsi sebelumnya tergantung pada seberapa baik fungsi sebelumnya cocok.
Jadi misalnya, misalkan Anda memiliki pencarian kueri teks. Kueri akan memberi peringkat setiap dokumen pada skala dari 0 hingga 1. Skor ini kemudian dimodifikasi oleh pentingnya. Jika Anda memberikan kepentingan tinggi, maka probabilitas akan didorong ke ekstrem. Kepentingan rendah mendorong probabilitas menjadi 0,5, sehingga menurunkan dampaknya.
Jadi misalnya, jika kueri pencarian teks menandai dokumen sebagai sangat relevan, 0,7, tetapi diberi kepentingan rendah, probabilitasnya dapat dimodifikasi menjadi 0,55, sehingga menurunkan dampaknya. Di sisi lain, jika kueri teks cocok dengan buruk memberikan skor 0,3 tetapi kepentingannya rendah, maka probabilitasnya akan dinaikkan menjadi 0,45.
[Generator Kandidat] | | [Prior_x] [prior_y] | | -doc_a-> pentingnya_x (skor_x_a) ✖ pentingnya_y (score_y_a) | | -doc_b-> penting. | --- doc_c-> pentingnya_x (skor_x_c) ✖ pentingnya_y (score_y_c)
Pencarian teks adalah komponen yang menonjol dalam P-pencarian. Sementara pencarian teks berfungsi dengan cara yang sama seperti fungsi sebelumnya (menghasilkan skor 0 hingga 1), mecahnisms di belakangnya lebih kompleks.
Anda dapat membuat kueri teks dengan memilih "kueri teks" di menu transien saat menjalankan p-search-add-prior .
Anda kemudian akan diminta untuk pertanyaan Anda. Bergantung pada kueri yang Anda tulis, satu atau lebih proses akan dibuat untuk melakukan pencarian.
Seperti yang disebutkan sebelumnya, setiap dokumen kandidat pencarian memiliki 'content properti. Pencarian teks dilakukan di bidang ini. Seperti yang mungkin Anda dapatkan, harus mencari setiap dokumen pada satu utas LISP Emacs tunggal lambat, sehingga setiap fungsi generator kandidat dapat memiliki metode yang lebih cepat untuk melakukan pencarian. Inilah sebabnya Anda melihat alat pencarian seperti :grep atau :rg pada generator kandidat sistem file. Saat melakukan kueri teks pada dokumen yang berasal dari ini, itu akan bergantung pada alat ini untuk melakukan pencarian.
Untuk kueri teks, setiap hasil pencarian dipisahkan ruang. Jadi, jika Anda mengetik teacher student school itu akan melakukan tiga pencarian terpisah untuk tiga istilah. Setiap istilah akan menghasilkan skornya sendiri untuk setiap dokumen dan kemudian akan digabungkan untuk membentuk skor akhir. Anda dapat menggunakan kutipan untuk mengelompokkan kata -kata untuk mencari sesuatu secara keseluruhan, sehingga "teacher student school" akan melakukan satu pencarian dengan kata -kata dalam urutan.
Istilah yang tidak dikutip akan diproses menjadi beberapa varian dan dicari secara paralel. Jadi misalnya teacherStudentSchool akan mencari kedua “Teacherstudentschool” (kasus tidak sensitif), tetapi juga “Teacher_student_school”, “Guru-Student-School” (dengan skor yang lebih rendah), dan istilah terpisah “guru”, “siswa”, dan “sekolah” (diberikan bahkan skor yang lebih rendah).
Anda dapat meningkatkan istilah dengan ^ sehingga teacher student^ school akan memberikan dorongan kepada siswa. Anda juga dapat menentukan dorongan numerik, seperti pada teacher student^2 school^3 .
Anda dapat mencari istilah yang terjadi di dekat satu sama lain dengan (term1 term2 ...)~ sintaks. Bergantung pada nilai p-search-default-near-line-length , item akan diminta untuk berada dalam jumlah tertentu dari satu sama lain.
P-pencarian hanya akan menunjukkan kepada Anda nilai p-search-top-n pertama dari hasil pencarian. Jika Anda tidak melihat hasil yang relevan, Anda mungkin ingin mempertimbangkan untuk menambahkan kriteria pencarian. Anda juga dapat menjalankan perintah p-search-observe untuk menurunkan probabilitas hasil tertentu. Melakukan hal itu akan menurunkan probabilitas item dengan mengalikannya dengan 0,3. Dengan awalan Cu p-search-observe , Anda dapat menentukan probabilitasnya. Setelah Anda melakukan pengamatan, probabilitas akan dihitung ulang dan hasilnya akan diperbarui.
p-search-peruse-mode adalah mode minor global eksperimental, bahwa ketika aktif, akan melacak persentase file yang Anda lihat. Persentase tampilan akan diperbarui di bagian Hasil Pencarian.
P-pencarian berisi sejumlah mekanim untuk mempercepat proses pencarian Anda. Di satu sisi, Anda dapat secara program membuat perintah dan memanggil berbagai fungsi pencarian-P untuk membuat instantiate sesi sesuai keinginan Anda. Di sisi lain, cukup bookmark sesi menggunakan komando bookmark-set (biasanya terikat Cx rm ) akan memungkinkan Anda menyimpan sesi, kandidat generator dan prior, untuk mengakses dengan cepat di masa depan.
Cara lain untuk mengonfigurasi perilaku P-pencarian adalah dengan mengatur variabel p-search-default-command-behavior . Dengan setitng itu nilainya secara global, Anda dapat mengonfigurasi bagaimana perintah p-search berperilaku. Anda juga dapat mengatur variabel melalui file ".dir-locals.el", seperti sebagai berikut, untuk memiliki pengaturan direktori-lokal:
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " ))))))) Anda dapat menjalankan perintah p-search-show-session-preset untuk melihat sesi saat ini diwakili sebagai objek LISP. Dengan meneruskan struktur data ini ke fungsi p-search-setup-buffer , Anda dapat secara program membuat sesi pencarian-P yang Anda inginkan.


