p search
1.0.0
P-Search est un outil EMACS pour trouver des choses. Il combine des concepts de la recherche de recherche d'informations et de la théorie de la recherche bayésienne pour aider un utilisateur à trouver des documents.
Les recherches booléennes (c'est-à-dire que le document contient le mot «x»), bien que simple et utile, de ne pas correspondre aux croyances antérieures du chercheur concernant les fichiers pertinents. Souvent, le chercheur a des idées spécifiques sur la localisation du document. Comme quel type de fichier il s'agit, qui est l'auteur du document, lorsque le document a été créé. Le chercheur n'est souvent pas entièrement confiant quant à la façon dont les termes de lecture apparaissent ou s'ils apparaissent du tout.
Jusqu'à ce que P-Search soit disponible sur ELPA / MELPA, vous devrez installer ce package manuellement. La seule dépendance de la recherche P est le tas.
Utilisation de Quelpa:
(quelpa ' (p-search :repo " zkry/p-search " :fetcher github))Utilisation directe:
( use-package p-search :straight ( :host github :repo " https://github.com/zkry/p-search.git " ))Utilisation d'Elpaca:
( use-package p-search :elpaca ( :host github :repo " https://github.com/zkry/p-search.git " )) Une session de recherche peut être initiée avec la commande p-search . La commande configurera la session pour rechercher des fichiers dans le répertoire des projets (voir Project.el) si un projet existe ou dans le répertoire actuel. Exécutez p-search avec le préfixe Cu pour instancier une session vide (TODO).
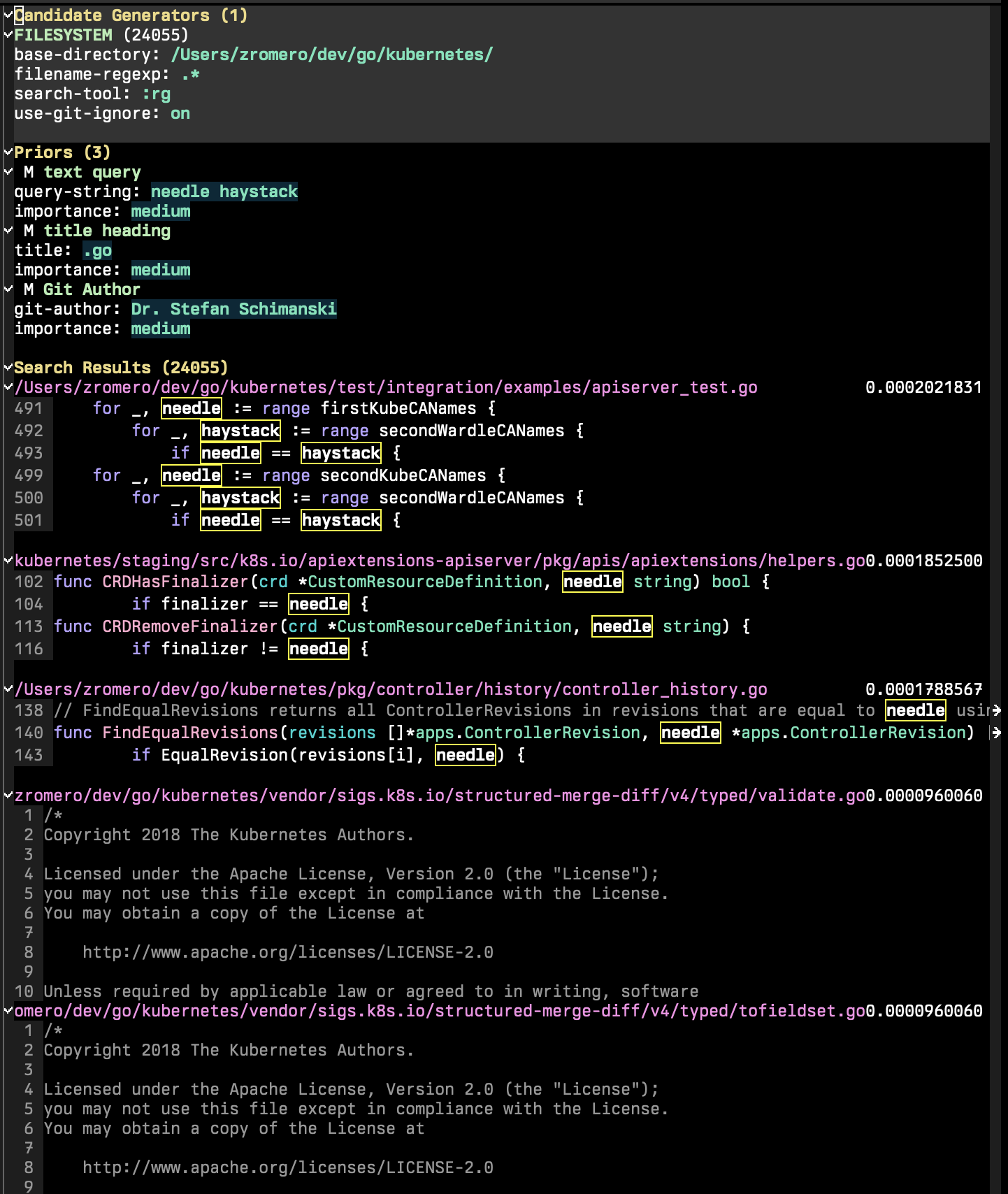
La session P-Search est composée de trois sections principales: générateurs de candidats, prieurs et résultats de recherche.
Les générateurs de candidats sont les parties de la session de recherche qui énumèrent tous les candidats de recherche possibles. Un candidat de recherche est une entité avec un ensemble de propriétés de clé / valeur, 'content et 'title étant manetory. D'autres propriétés peuvent exister, ce qui vous permettra d'utiliser des fonctions antérieures supplémentaires. Dans la session P-Search, exécutez p-search-add-candidate-generator ( C ) pour ajouter un nouveau générateur de candidats.
Vous pouvez supprimer un précédent avec la commande p-search-kill-entry-at-point .
La section Priors est la partie où vous ajoutez des critères de recherche à votre session. Exécutez p-search-add-prior ( P ) pour ajouter une fonction antérieure.
Vous devez d'abord sélectionner le type de précédent que vous souhaitez ajouter. Ensuite, vous devrez configurer le précédent. Cela vous invitera d'abord à tous les champs manetory.
Après cela, un nouveau menu transitoire apparaîtra, vous permettant de configurer le précédent. Chaque fonction antérieure aura son propre ensemble d'entrées et d'options, mais chacun vous permettra de définir son importance et si le complément doit être pris.
Vous pouvez supprimer un précédent avec la commande p-search-kill-entry-at-point ( k ).
Chaque document candidat reçoit un score de chaque fonction antérieure en fonction de la façon dont la fonction antérieure correspond.
Ainsi, par exemple, supposons que vous ayez une recherche de requête texte. La requête classera chaque document sur une échelle de 0 à 1. Ce score est ensuite modifié par l'importance. Si vous attribuez une grande importance, les probabilités seront poussées aux extrêmes. Une faible importance pousse les probabilités à 0,5, réduisant ainsi son impact.
Ainsi, par exemple, si une requête de recherche de texte a marqué un document comme très pertinent, 0,7, mais a reçu une faible importance, sa probabilité peut être modifiée à 0,55, réduisant ainsi son impact. D'un autre côté, si une question de texte correspond mal, ce qui donne un score de 0,3 mais que son importance est faible, sa probabilité sera augmentée à peut-être 0,45.
[Générateur de candidats] | | [Prior_x] [Prior_y] | | - doc_a -> importance_x (score_x_a) ✖ importance_y (score_y_a) | | - doc_b -> importance_x (score_x_b) ✖ importance_y (score_y_b) ... | --- doc_c -> importance_x (score_x_c) ✖ importance_y (score_y_c)
La recherche de texte est un composant proéminent de la recherche P. Alors que la recherche de texte fonctionne de la même manière que les autres fonctions antérieures (résultant en un score de 0 à 1), les mécahnismes derrière lui sont plus complexes.
Vous pouvez créer une requête de texte en sélectionnant «Requête de texte» dans le menu transitoire lors de l'exécution p-search-add-prior .
Vous serez ensuite invité à votre requête. Selon la requête que vous écrivez, un ou plusieurs processus seront créés pour effectuer la recherche.
Comme mentionné précédemment, chaque document candidat de recherche a un 'content propriété. La recherche de texte est effectuée sur ce champ. Comme vous pouvez probablement l'imagine, devoir rechercher chaque document sur un seul thread EMACS LISP est lent, donc chaque fonction de générateur candidat peut avoir une méthode plus rapide pour effectuer la recherche. C'est pourquoi vous voyez l'outil de recherche comme :grep ou :rg sur le générateur de candidats Système de fichiers. Lorsque vous effectuez une requête texte sur des documents en provenance, il s'appuiera sur cet outil pour effectuer la recherche.
Pour la requête du texte, chaque résultat de recherche est séparé de l'espace. Donc, si vous tapez teacher student school il effectuera trois recherches distinctes pour les trois termes. Chaque terme générera son propre score pour chaque document et ils seront ensuite combinés pour former un score final. Vous pouvez utiliser des citations pour regrouper les mots pour rechercher quelque chose dans son ensemble, donc "teacher student school" effectuera une recherche avec les mots dans une séquence.
Les termes non cités seront traités en plusieurs variantes et recherchés en parallèle. Ainsi, par exemple, teacherStudentSchool recherchera à la fois «Teacherstudentschool» (cas insensible), mais aussi «enseignante_student_school», «enseignant-école-école» (avec un score inférieur) et les termes séparés «enseignant», «élève» et «école» (donné même un score inférieur).
Vous pouvez augmenter un terme avec ^ afin que teacher student^ school donne un coup de pouce à l'élève. Vous pouvez également spécifier un coup de pouce numérique, comme dans teacher student^2 school^3 .
Vous pouvez rechercher des termes qui se produisent près les uns des autres avec la syntaxe (term1 term2 ...)~ . Selon la valeur de p-search-default-near-line-length , les éléments devront se situer dans un certain nombre de lignes les uns des autres.
P-Search ne vous montrera que les premières valeurs p-search-top-n des résultats de recherche. Si vous ne voyez pas de résultats pertinents, vous voudrez peut-être envisager d'ajouter des critères de recherche. Vous pouvez également exécuter la commande p-search-observe pour abaisser la probabilité d'un résultat particulier. Cela réduira la probabilité de l'élément en le multipliant par 0,3. Avec le préfixe Cu p-search-observe , vous pouvez spécifier la probabilité. Après avoir effectué l'observation, les probabilités seront recalculées et les résultats seront mis à jour.
p-search-peruse-mode est un mode mineur mondial expérimental qui, lorsqu'il est actif, suivra le pourcentage de fichiers que vous avez consultés. Le pourcentage de vue sera mis à jour dans la section Résultats de la recherche.
P-Search contient un certain nombre de mécanismes pour accélérer votre processus de recherche. D'une part, vous pouvez créer une commande programmatique et appeler diverses fonctions de recherche P pour instancier une session à votre goût. De l'autre, le simple signet de la session à l'aide de la bookmark-set de commande (généralement lié Cx rm ) vous permettra de sauvegarder la session, les générateurs de candidats et les prieurs, pour accéder rapidement à l'avenir.
Une autre façon de configurer le comportement de la recherche P est de définir la variable p-search-default-command-behavior . En définissant sa valeur globale, vous pouvez configurer comment la commande p-search se comporte. Vous pouvez également définir la variable via un fichier «.dir-locals.el», comme comme suit, pour avoir des paramètres de répertoire:
((p-search-mode . ((p-search-default-command-behavior . ( :candidate-generator p-search-candidate-generator-filesystem :args ((base-directory . " ~/dev/ go/delve/cmd " ))))))) Vous pouvez exécuter la commande p-search-show-session-preset pour voir la session actuelle représentée comme un objet LISP. En passant cette structure de données à la fonction p-search-setup-buffer , vous pouvez créer programatiquement la session P-Search que vous souhaitez.


