visual question answering finetuning
1.0.0
該存儲庫使用生成AI(Genai)來實現機器學習培訓和推理團,以基於提供的圖像來回答問題。存在預訓練的模型以實現此類任務,但是它們是a)無法適應特定領域的方案 - 因此,為什麼我們需要微調和b)不顯示將部署到生產環境中的能力。
為了解決這個問題,這篇文章通過對使用Amazon SageMaker的時尚數據集上的VLM(視覺語言模型)微調VLM(視覺語言模型),展示瞭如何從產品圖像中提取特定域的產品屬性,然後使用Amazon Bedrock使用提取的屬性作為輸入來生成產品描述。
有關此存儲庫的詳細演練,請參閱我們的博客文章。
該存儲庫中使用的數據取自Kaggle時尚圖像數據集,我們嘗試求解的用戶酶正在為電子商務網站生成這些時尚產品的字幕,這一任務在歷史上一直很耗時。高質量的產品描述通過搜索引擎優化(SEO)提高可搜索性,並通過允許他們做出明智的決策來提高客戶滿意度。
該存儲庫中的模型列出是Blip-2模型,更具體地說,是使用Flan-T5-XL的變體。
下圖說明了Blip-2的概述:
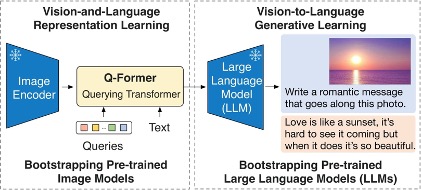
該解決方案可以分為兩個部分,在下面的成就中被標記為綠色和藍色:a)綠色和b)藍色推斷。
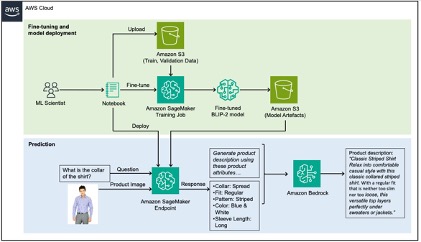
有關更多信息,請參見貢獻。
該圖書館已獲得MIT-0許可證的許可。請參閱許可證文件。


