visual question answering finetuning
1.0.0
Ce référentiel implémente une formation d'apprentissage automatique et un régiment d'inférence, en utilisant une IA générative (Genai) pour répondre aux questions basées sur des images fournies. Les modèles pré-formés existent pour atteindre de telles tâches, mais ils sont a) incapables de s'adapter aux scénarios spécifiques au domaine - d'où la raison pour laquelle nous devons affiner et b) ne pas afficher la capacité à déployer dans des environnements de production.
Pour résoudre ce problème, cet article montre comment extraire les attributs de produits spécifiques au domaine à partir d'images de produit en affinant un VLM (modèle de vision-langage) sur un ensemble de données de mode à l'aide d'Amazon SageMaker, puis utilisez le substratum rocheux d'Amazon pour générer des descriptions de produits en utilisant les attributs extraits comme entrée.
Pour une procédure détaillée de ce référentiel, veuillez vous référer à notre blog.
Les données utilisées dans ce référentiel sont tirées de l'ensemble de données Kaggle Fashion Images et de l'USecase que nous essayons de résoudre consiste à générer des légendes pour ces produits de mode pour un site Web de commerce électronique, une tâche qui a historiquement pris beaucoup de temps. Les descriptions de produits de haute qualité améliorent la recherche grâce à l'optimisation des moteurs de recherche (SEO), ainsi qu'à accroître la satisfaction des clients en leur permettant de prendre des décisions éclairées.
Le modèle financé dans ce référentiel est le modèle BLIP-2 et plus spécifiquement, une variante de celui-ci en utilisant Flan-T5-XL.
Le diagramme suivant illustre l'aperçu de Blip-2:
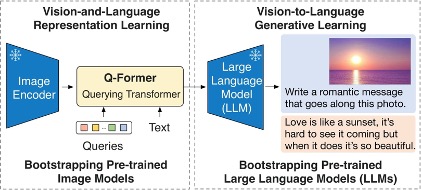
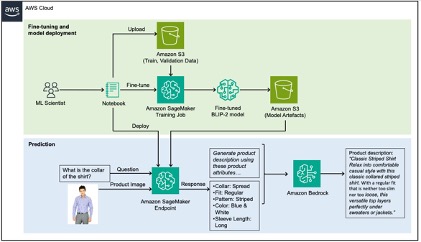
La solution peut être décomposée en deux sections, marquée verte et bleue dans l'achitecture ci-dessous: a) Fonction finale en vert et b) inférence en bleu.
Voir contribuer pour plus d'informations.
Cette bibliothèque est autorisée sous la licence MIT-0. Voir le fichier de licence.


