有效的大語言模型:調查
高效的大語言模型:調查[ARXIV](版本1:12/06/2023;版本2:12/23/2023;版本3:01/31/2024;版本4:05/23/2024,機器學習研究上的攝像機準備版本
Zhongwei Wan 1 ,Xin Wang 1 ,Che Liu 2 ,Samiul Alam 1 ,Yu Zheng 3 ,Jichen Liu 4 ,Zhongnan Qu 5 ,Shen Yan 6 ,Shen Yan 6,Yi Zhu 7 ,Quanlu Zhang 8 ,Mosharaf Chowdhury 4 ,Mi Zhang 1,Mi Zhang 1,Mi Zhang 1
1俄亥俄州立大學,倫敦帝國學院2號,密歇根州立大學3號,密歇根大學4號,亞馬遜AWS AI, 6 Google Research, 7 Boson AI, 8 Microsoft Research Asia
News:我們的調查已被機器學習研究(TMLR)的交易正式接受,2024年5月。相機Ready版本可用:[OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
❤️社區支持
該存儲庫維護Tuidan ([email protected]),維持橋([email protected]), Samiul272 ([email protected])和Mi-Zhang ([email protected])。我們歡迎反饋,建議和貢獻,可以幫助改善這一調查和存儲庫,從而使它們成為有益的資源以使整個社區受益。
我們將通過納入新的研究來積極維護該存儲庫。如果您對我們的分類學有任何建議,請找到任何缺失的論文,或更新已接受給某個場所的任何預印紙紙,請隨時向我們發送電子郵件或使用以下Markdown格式提交拉動請求。
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
?這項調查是什麼?
大型語言模型(LLMS)在許多重要任務中表現出了顯著的能力,並有可能對我們的社會產生重大影響。但是,這種功能具有相當大的資源需求,強烈強烈需要開發有效的技術來解決LLMS帶來的效率挑戰。在這項調查中,我們對有效的LLMS研究進行了系統的全面綜述。我們以三個主要類別組成的分類學組織文獻,分別涵蓋了以模型為中心,以數據為中心和框架的觀點,分別涵蓋了獨特但相互聯繫的有效LLMS主題。我們希望我們的調查和該GITHUB存儲庫可以作為寶貴的資源,以幫助研究人員和從業者對有效LLM的研究發展有系統的了解,並激發他們為這個重要而令人興奮的領域做出貢獻。
?為什麼需要有效的LLM?
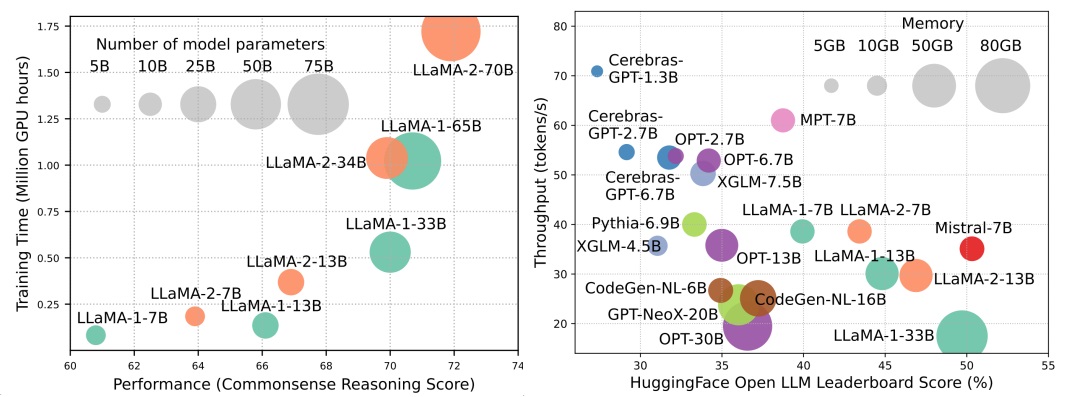
儘管LLM正在領導下一波AI革命,但LLM的顯著能力是以其大量資源需求為代價。圖1(左)說明了模型性能與模型訓練時間之間的關係,即Llama系列的GPU小時,其中每個圓的大小與模型參數的數量成正比。如圖所示,儘管較大的模型能夠實現更好的性能,但是隨著模型尺寸擴大規模,用於訓練它們的GPU小時數量成倍增長。除了培訓外,推論還對LLM的運營成本做出了很大貢獻。圖2(右)描繪了模型性能與推理吞吐量之間的關係。同樣,擴大模型大小可以實現更好的性能,但以較低的推理吞吐量(推理潛伏期)為代價,對這些模型的挑戰提出了將其覆蓋範圍擴展到更廣泛的客戶群和以具有成本效益的方式進行的挑戰。 LLMS的高資源需求強調了開發技術以提高LLM效率的強大需求。如圖2所示,與Llama-1-33b相比,Mismtral-7b(使用分組的疑問和滑動窗口注意來加快推斷,實現可比的性能和更高的吞吐量。這種優勢強調了LLMS設計效率技術的可行性和意義。
內容表
- ?以模型為中心的方法
- 模型壓縮
- 有效的預訓練
- 有效的微調
- 有效的推斷
- 有效的體系結構
- 有效的關注
- 共享的注意力
- 功能信息減少
- 內核或低級別
- 固定模式策略
- 可學習的模式策略
- 專家的混合物
- 長上下文LLM
- 變壓器替代體系結構
- ?以數據為中心的方法
- ?系統級效率優化和LLM框架
- 系統級效率優化
- 系統級訓練效率優化
- 系統級服務效率優化
- 算法 - 硬件共同設計
- LLM框架
?以模型為中心的方法
模型壓縮
量化
訓練後量化
僅重量量化
- i-llm:對完全量化的低位大語言模型的有效整數推斷, Arxiv,2024年[紙]
- IntactKV:通過保持樞軸代幣完整來改善大型語言模型量化, Arxiv,2024年[紙]
- 無所不在:全語:大語模型的全向校準量化, ICLR,2024 [紙] [代碼]
- Onebit:朝著極低的大型語言模型, Arxiv,2024年[紙]
- GPTQ:生成預訓練的變壓器的準確量化, ICLR,2023年[紙] [代碼]
- 諷刺:具有保證的大型語言模型的2位量化, Arxiv,2023年[紙] [代碼]
- AWQ:LLM壓縮和加速度的激活意識重量量化, Arxiv,2023年[紙] [代碼]
- OWQ:從激活異常值中學到的經驗教訓,用於大語言模型中的權重量化, Arxiv,2023年[紙] [代碼]
- SPQR:稀疏定量的表示,用於近乎無效的LLM重量壓縮, Arxiv,2023年[紙] [代碼]
- 細性:通過使用細顆粒的量量化LLMS的效率,解鎖效率, Neurips-enlsp,2023年[紙]
- llm.int8():變形金剛的8位矩陣乘法規模, Neurlps,2022 [紙] [代碼]
- 最佳大腦壓縮:精確訓練後量化和修剪的框架,神經,2022年[紙] [代碼]
- 量化:基於優化的語言模型量化, Arxiv,2023年[紙] [代碼]
權重激活共量化
- 旋轉和排列的高級異常管理和LLM有效量化的旋轉和置換,神經,2024年[紙]
- 無所不在:全語:大語模型的全向校準量化, ICLR,2024 [紙] [代碼]
- 量化量化的有趣特性,神經,2023年[紙]
- 零V2:探索LLM中從綜合研究到低等級補償的LLM中訓練後量化, Arxiv,2023年[紙] [代碼]
- 零fp:使用浮點格式,LLMS訓練後W4A8量化的LLMS的飛躍, Neurips-enlsp,2023年[紙] [代碼]
- Olive:通過硬件友好的離群值對量化加速大型語言模型, ISCA,2023年[紙] [代碼]
- RPTQ:大型語言模型的基於重新排序的培訓量化, Arxiv,2023年[紙] [代碼]
- 異常抑制+:通過等效和最佳縮小和縮放對大語言模型進行準確量化, Arxiv,2023年[紙] [代碼]
- QLLM:大語言模型的準確有效的低含寬量化, Arxiv,2023年[紙]
- 平滑:大語言模型的準確有效的訓練後量化, ICML,2023 [紙] [代碼]
- 零:大規模變壓器的有效且負擔得起的訓練後量化,神經,2022年[紙]
評估訓練後量化
- 評估量化的大語言模型, Arxiv,2024年[紙]
量化感知培訓
- 1位LLMS的時代:所有大型語言模型均以1.58位, Arxiv,2024年[紙]
- FP8-LM:培訓FP8大語言模型, Arxiv,2023年[紙]
- 使用8位浮點培訓和推斷大型語言模型, Arxiv,2023年[紙]
- 比特網:為大語言模型縮放1位變壓器, Arxiv,2023年[紙]
- LLM-QAT:大語言模型的無數據量化培訓, Arxiv,2023年[紙] [代碼]
- 通過量化壓縮生成培訓的語言模型, ACL,2022年[紙]
參數修剪
結構化修剪
- 通過修剪和知識蒸餾,緊湊的語言模型, Arxiv,2024年[紙]
- 更深入地看一下LLM的深度修剪, Arxiv,2024年[紙]
- 困惑的困惑:基於困惑的數據修剪,小參考模型, Arxiv,2024年[紙]
- 插件:一種有效的大語言模型的訓練後修剪方法, ICLR,2024 [紙]
- BESA:用塊參數有效的稀疏分配修剪大型語言模型, Arxiv,2024年[紙]
- 短時:大語言模型中的層數比您預期的要多餘, Arxiv,2024年[紙]
- NutePrune:有效的逐步修剪大型語言模型, Arxiv,2024年[紙]
- slicegpt:通過刪除行和列來壓縮大語言模型, ICLR,2024 [紙] [代碼]
- Lorashear:高效的大語言模型結構修剪和知識恢復, Arxiv,2023年[紙]
- LLM-Pruner:關於大語言模型的結構修剪,神經,2023年[紙] [代碼]
- 剪切的美洲駝:通過結構化修剪預訓練的加速語言模型, Neurips-enlsp,2023年[紙] [代碼]
- Loraprune:修剪符合低級參數效率微調, Arxiv,2023年[紙]
非結構化的修剪
- maskllm:大語言模型的可學習半結構化稀疏性, NIP,2024年[紙]
- 動態稀疏無培訓:稀疏LLM的無培訓微調, ICLR,2024 [紙]
- 稀疏:大規模的語言模型可以單次精確修剪, ICML,2023 [紙] [代碼]
- 大型語言模型的一種簡單有效的修剪方法, Arxiv,2023年[紙] [代碼]
- 對大語言模型的單發靈敏度感知的混合稀疏性修剪, Arxiv,2023年[紙]
低級別近似
- SVD-LLM:大語言模型壓縮的單數值分解, Arxiv,2024年[紙] [代碼]
- ASVD:用於壓縮大語言模型的激活感知值分解, Arxiv,2023年[紙] [代碼]
- 語言模型壓縮和加權低級分解, ICLR,2022 [紙]
- 張量:基於張量 - 訓練分解,在LLMS中嵌入層的有效壓縮, Arxiv,2023年[紙]
- Losparse:基於低級別和稀疏近似的大語言模型的結構化壓縮, ICML,2023 [紙] [代碼]
知識蒸餾
白盒KD
- DDK:蒸餾域知識的高效大語言模型Arxiv,2024年[紙]
- 重新考慮大語模型知識蒸餾中的kullback-leibler差異Arxiv,2024年[紙]
- Distillm:邁向大型語言模型的簡化蒸餾, Arxiv,2024年[紙] [代碼]
- 在蒸餾語言模型中達到能力差距的法則, Arxiv,2023年[紙] [代碼]
- 嬰兒駱駝:從沒有表現懲罰的小型數據集中訓練的老師合奏的知識蒸餾, Arxiv,2023年[紙]
- 大型語言模型的知識蒸餾, Arxiv,2023年[紙] [代碼]
- GKD:自動回歸序列模型的廣義知識蒸餾, Arxiv,2023年[紙]
- 通過蒸餾傳播對LMS的知識更新, Arxiv,2023年[紙] [代碼]
- 少更多:語言模型壓縮的任務感知層蒸餾, ICML,2023 [紙]
- 三元重量生成語言模型的令牌標準logit蒸餾, Arxiv,2023年[紙]
Black-Box KD
- Zephyr:直接蒸餾LM對齊, Arxiv,2023年[紙]
- 使用GPT-4進行指導調整, Arxiv,2023年[紙] [代碼]
- 獅子:封閉源大型語言模型的對抗性蒸餾, Arxiv,2023年[紙] [代碼]
- 專門針對多步推理的較小語言模型, ICML,2023 [紙] [代碼]
- 逐步蒸餾!超過較小的培訓數據和較小的模型大小的較大語言模型, ACL,2023年[紙]
- 大型語言模型是推理教師, ACL,2023年[紙] [代碼]
- Scott:自以赴的鏈條蒸餾, ACL,2023年[紙] [代碼]
- 符號鏈蒸餾:小型模型也可以逐步“思考”, ACL,2023年[紙]
- 將推理功能提煉成較小的語言模型, ACL,2023年[紙] [代碼]
- 在內部的學習蒸餾:轉移預訓練的語言模型的幾次學習能力, Arxiv,2022年[紙]
- 大型語言模型的解釋使小推理器變得更好, Arxiv,2022年[紙]
- 迪斯科:用大語言模型提煉反事實, Arxiv,2022年[紙] [代碼]
參數共享
- Mobillama:朝著準確且輕巧的完全透明的GPT, Arxiv,2024年[紙]
有效的預訓練
混合精度訓練
- Bfloat16神經網絡處理, Arith,2019年[紙]
- Bfloat16的研究用於深度學習培訓, Arxiv,2019年[紙]
- 混合精度訓練, ICLR,2018年[紙]
縮放模型
- 檸檬:無損模型擴展, ICLR,2024 [紙]
- 準備在語言模型上進行漸進培訓的課程, AAAI,2024年[紙]
- 學習成長預貼模型以進行有效的變壓器培訓, ICLR,2023年[紙] [代碼]
- 2倍通過掩蓋結構增長預訓練的語言模型更快, Arxiv,2023年[紙]
- 多線性操作員重複使用預估計的模型進行有效的培訓,神經,2023年[紙]
- FLM-101B:開放LLM以及如何用$ 100 K預算培訓它, Arxiv,2023年[紙] [代碼]
- 對預訓練的語言模型的知識繼承, NAACL,2022年[紙] [代碼]
- 針對變壓器語言模型的培訓, ICML,2022 [紙] [代碼]
初始化技術
- 深網:將變壓器縮放到1,000層, Arxiv,2022年[紙] [代碼]
- 零初始化:只有零和一個初始化神經網絡, TMLR,2022 [紙] [代碼]
- Rezero就是您所需要的:大深度快速收斂, UAI,2021年[紙] [代碼]
- 批處理歸一化偏向於深網中的身份函數的殘留塊,神經,2020年[紙]
- 通過更好的初始化來改善變壓器優化, ICML,2020年[紙] [代碼]
- 修復初始化:剩餘學習沒有歸一化, ICLR,2019年[紙]
- 關於深度神經網絡的重量初始化, Arxiv,2017年[紙]
培訓優化器
- 旨在最佳學習語言模型, Arxiv,2024年[紙] [代碼]
- 優化算法的符號發現, Arxiv,2023年[紙]
- Sophia:用於語言模型預訓練的可擴展隨機二階優化器, Arxiv,2023年[紙] [代碼]
有效的微調
參數有效的微調
基於適配器的調整
- OPENDELTA:用於預訓練模型的參數效率改編的插件庫, ACL演示,2023年[紙] [代碼]
- LLM-適配器:用於大型語言模型參數有效微調的適配器家族, Emnlp,2023年[紙] [代碼]
- 兼容者:有效的低級超複合適配器層,神經,2023年[紙] [代碼]
- 幾乎沒有彈出參數的微調比在文化學習中更好,更便宜,神經,2022年[紙] [代碼]
- 元適配器:參數有效地通過元學習進行了幾次微調, Automl,2022年[紙]
- Adamix:用於參數有效模型調整的適應性混合物, Emnlp,2022年[紙] [代碼]
- Sparseadapter:一種簡單的方法,用於提高適配器的參數效率, Emnlp,2022年[紙] [代碼]
低級適應
- hydralora:一種不對稱的洛拉結構,用於有效微調,神經,2024年[紙]
- LOFIT:LLM表示局部微調, Arxiv,2024年[紙]
- 低級適應中的貝面混合物, Arxiv,2024年[紙] [代碼]
- MEFT:通過稀疏適配器進行記憶有效的微調, ACL,2024年[紙]
- 洛拉在統一框架下遇到輟學Arxiv,2024年[紙]
- 星:洛拉(Lora Arxiv,2024年[紙]
- 洛拉+:大型模型的有效低級適應Arxiv,2024年[紙]
- Lora-fa:大型語言模型微調的記憶效率低級適應, Arxiv,2023年[紙]
- Lorahub:通過動態Lora組成有效的跨任務概括, Arxiv,2023年[紙] [代碼]
- LONGLORA:長篇文化大型語言模型的有效微調, Arxiv,2023年[紙] [代碼]
- 多頭適配器路由以進行交叉任務概括,神經,2023年[紙] [代碼]
- 自適應預算分配用於參數有效微調, ICLR,2023年[紙]
- Dylora:使用動態無搜索低級適應的預處理模型的參數調整, EACL,2023年[紙] [代碼]
- 綁定洛拉:通過重量綁紮提高洛拉的參數效率, Arxiv,2023年[紙]
- 洛拉:大語言模型的低級改編, ICLR,2022 [紙] [代碼]
前綴調整
- 駱駝適配:有效地對語言模型的有效微調,請注意, Arxiv,2023年[紙] [代碼]
- 前綴調整:優化發電的連續提示ACL,2021 [紙] [代碼]
及時調整
- 壓縮,然後提示:通過可轉讓的提示提高LLM推斷的準確性效率折衷, Arxiv,2023年[紙]
- GPT也明白AI開放,2023年[紙] [代碼]
- 模塊化提示的多任務預訓練,以進行幾次學習ACL,2023年[紙] [代碼]
- 多任務提示調整啟用參數有效的傳輸學習, ICLR,2023年[紙]
- PPT:預先訓練的及時調整以進行幾次學習, ACL,2022年[紙] [代碼]
- 參數有效的及時調整使廣義和校準的神經文本奪回器, Emnlp-findings,2022年[紙] [代碼]
- p-Tuning V2:提示調整可以與跨量表和任務普遍普遍的FINETUNS相提並論, ACL-Short,2022 [紙] [代碼]
- 參數有效及時調整的比例功能, Emnlp,2021年[紙]
記憶有效的微調
- 一項針對微調大語言模型的優化研究, Arxiv,2024/ins> [紙]
- 大語言模型微調的稀疏矩陣, Arxiv,2024/ins> [紙]
- 盛大:通過梯度低級投影的記憶效率LLM訓練, Arxiv,2024/ins> [紙]
- REFT:語言模型的表示列表, Arxiv,2024/ins> [紙]
- LISA:對內存有效的大語言模型微調的層次重要性採樣, Arxiv,2024/ins> [紙]
- Bitdelta:您的微調可能只有一點點, Arxiv,2024/ins> [紙]
- 獲獎者 - 全列行採樣用於內存有效適應語言模型的採樣,神經,2023年[紙] [代碼]
- 記憶有效的選擇性微調, ICML研討會,2023年[紙]
- 用於有限資源的大型語言模型的完整參數微調, Arxiv,2023年[紙] [代碼]
- 帶有正向通過的微調語言模型,神經,2023年[紙] [代碼]
- 通過低4位整數量化對壓縮大語模型的記憶有效的微調,神經,2023年[紙]
- Loftq:大語言模型的Lora-Fine-tuning-tauning-Aware-Awaring-Aware-Awaring-Awaring-Awaring-Awaring-Awaring-taining-warme量化Arxiv,2023年[紙] [代碼]
- QA-LORA:大型語言模型的量化低級適應, Arxiv,2023年[紙] [代碼]
- QLORA:量化LLM的有效捕獲,神經,2023年[Paper] [Code1] [Code2]
Moe有效的預定效果
- 讓專家堅持他的最後一個:專家專業的微調,以稀疏建築大型語言模型, Arxiv,2024年[紙]
有效的推斷
平行解碼
- CLLM:一致性大語言模型, Arxiv,2024年[紙]
- 一次編碼並並行解碼:有效的變壓器解碼, Arxiv,2024年[紙]
投機解碼
- MagicDec:通過投機解碼來打破長篇小說生成的延遲交換權權衡, Arxiv,2024年[紙]
- 傑出:用閃光樹專註解碼,以實現有效的樹結構的LLM推理, Arxiv,2024年[紙]
- LayersKip:實現早期出口推理和自我指導, Arxiv,2024年[紙]
- Triforce:通過分層投機解碼的長序列產生的無損加速度, Arxiv,2024年[紙]
- 休息:基於檢索的投機解碼, Arxiv,2024年[紙]
- 推理有效LLM的串聯變壓器, Arxiv,2024年[紙]
- 通過:平行投機抽樣, Neurips研討會,2023年[紙]
- 加速變壓器推斷通過並行解碼,用於翻譯, ACL,2023年[紙] [代碼]
- 美杜莎:簡單的框架,用於加速LLM具有多個解碼頭的生成,博客,2023年[博客] [代碼]
- 通過投機解碼從變形金剛快速推斷, ICML,2023 [紙]
- 加速LLM推斷分階段的投機解碼, ICML研討會,2023年[紙]
- 加速使用投機抽樣的大型語言模型解碼, Arxiv,2023年[紙]
- 用大小解碼器進行投機解碼,神經,2023年[紙] [代碼]
- SpecInfer:加速具有投機推理和令牌樹驗證的生成LLM, Arxiv,2023年[紙] [代碼]
- 參考的推斷:大語言模型的無損加速度, Arxiv,2023年[紙] [代碼]
- 種子:通過計劃的投機解碼加速推理樹的建設, Arxiv,2024年[紙]
KV-CACHE優化
- VL-CACHE:視覺模型推理加速度的稀疏性和模態感知的KV緩存壓縮, Arxiv,2024年[紙]
- 臨界1.0:通過動態稀疏注意力加速長篇文化LLM的預填充, Arxiv,2024年[紙]
- KVSharer:通過層次不同的KV緩存共享有效推斷, Arxiv,2024年[紙]
- 二重奏:有效的長篇小寫LLM與檢索和流式腦的推理, Arxiv,2024年[紙]
- lazyllm:用於有效的長上下文推理的動態令牌修剪, Arxiv,2024年[紙]
- PALU:通過低級投影壓縮KV-CACHE, Arxiv,2024年[紙] [代碼]
- Look-M:在KV緩存中的外觀優化,以進行有效的多模式長篇小說推斷, Arxiv,2024年[紙]
- D2O:動態判別操作,用於有效地推斷大語言模型的生成推斷, Arxiv,2024年[紙]
- 任務:查詢意識到的稀疏性對於有效的長篇小寫LLM推斷, ICML,2024 [紙]
- 減少變壓器鑰匙值高速緩存大小,並以跨層的注意, Arxiv,2024年[紙]
- snapkv:llm知道您在世代之前正在尋找什麼, Arxiv,2024年[紙]
- 基於錨的大語言模型, Arxiv,2024年[紙]
- kvquant:使用KV緩存量化的1000萬個上下文長度LLM推斷, Arxiv,2024年[紙]
- 齒輪:一種有效的KV緩存壓縮配方Arxiv,2024年[紙]
- 動態內存壓縮:加速推理的翻新LLMS, Arxiv,2024年[紙]
- 沒有留下的令牌:可靠的KV緩存通過重要性感知的混合精度量化, Arxiv,2024年[紙]
- 少獲取更多:通過有效LLM推斷的KV CACHE壓縮的合成複發, Arxiv,2024年[紙]
- wkvquant:量化大型語言模型的重量和鍵/值緩存更多, Arxiv,2024年[紙]
- 關於驅逐策略對密鑰價值約束生成語言模型推論的功效, Arxiv,2024年[紙]
- KIVI:KV緩存的無調的不對稱2bit量化, Arxiv,2024年[紙] [代碼]
- 模型告訴您要丟棄什麼:llms的自適應KV緩存壓縮, ICLR,2024 [紙]
- Skipdecode:自動迴旋跳過解碼,用於批處理和緩存,以進行有效的LLM推理, Arxiv,2023年[紙]
- H2O:重擊甲骨文以有效地推斷大語言模型,神經,2023年[紙]
- 剪刀:利用在測試時為LLM KV緩存壓縮的重要性假設的持續性,神經,2023年[紙]
- 動態環境修剪有效且可解釋的自動回歸變壓器, Arxiv,2023年[紙]
有效的體系結構
有效的關注
共享的注意力
- 洛馬:無損壓縮記憶的關注, Arxiv,2024年[紙]
- MOBILELL:優化數十億個參數語言模型用於設備上的用例, Arxiv,2024年[紙]
- GQA:訓練多頭檢查點的廣義多電量變壓器模型, Emnlp,2023年[紙]
- 快速變壓器解碼:一個寫頭是您所需要的, Arxiv,2019年[紙]
功能信息減少
- NYSTRöMformer:一種基於Nyström的算法,用於近似自我注意力, AAAI,2021年[紙] [代碼]
- 漏斗轉換器:濾除有效語言處理的順序冗餘,神經,2020年[紙] [代碼]
- 設置變壓器:基於注意的置換不變性神經網絡的框架, ICML,2019年[紙]
內核或低級別
- Loki:低級鑰匙,有效稀疏注意, ICML研討會,2023年[紙]
- sumformer:有效變壓器的通用近似,, ICML研討會,2023年[紙]
- Flurka:快速融合的低級和內核的注意, Arxiv,2023年[紙]
- 散射腦:統一稀疏和低等級的注意力, Neurlps,2021 [紙] [代碼]
- 重新思考表演者的關注, ICLR,2021 [紙] [代碼]
- 隨機特徵注意, ICLR,2021 [紙]
- Linformer:線性複雜性的自我注意力, Arxiv,2020年[紙] [代碼]
- 使用低級變壓器的輕巧,高效的端到端語音識別, ICASSP,2020年[紙]
- 變形金剛是RNN:具有線性注意的快速自回歸變壓器, ICML,2020年[紙] [代碼]
固定模式策略
- 簡單的線性注意力語言模型平衡了召回折衷方案, Arxiv,2024年[紙]
- Lightning Coative-2:免費午餐,用於處理大語言模型中無限序列長度的免費午餐, Arxiv,2024年[紙] [代碼]
- 通過稀疏的閃光燈注意,在大序列上更快的因果關注, ICML研討會,2023年[紙]
- 集合形式:長文檔建模,集合注意力, ICML,2021 [紙]
- 大鳥:變壓器更長的序列,神經,2020年[紙] [代碼]
- longformer:長期變壓器, Arxiv,2020年[紙] [代碼]
- 長期文檔理解的自我注意力, Emnlp,2020年[紙] [代碼]
- 用稀疏的變壓器生成長序列, Arxiv,2019年[紙]
可學習的模式策略
- MOA:自動大型語言模型壓縮的稀疏注意力的混合物, Arxiv,2024年[紙]
- 超級註意:在接近線性的時間內長期關注, Arxiv,2023年[紙] [代碼]
- 聚類形式:神經聚類的注意力,以提高高效變壓器, ACL,2022年[紙]
- 改革者:有效的變壓器, ICLR,2022 [紙] [代碼]
- 稀疏的sindhorn注意力, ICML,2020年[紙]
- 快速的變壓器引起關注,神經,2020年[紙] [代碼]
- 通過路由變壓器,有效的基於內容的稀疏注意力, TACL,2020年[紙] [代碼]
專家的混合物
基於MOE的LLM
- 自我摩托:邁向具有自專業專家的構圖大語模型, Arxiv,2024年[紙]
- Lory:自回歸語言模型預訓練的充分區分混合物,2024 [Paper]
- JETMOE:以0.10萬美元的價格達到Llama2性能,2024 [紙]
- 專家是值得一個令牌的:通過專家令牌路由協同為多個專家LLM,2024年[Paper]
- 深入的混合物:在基於變壓器的語言模型中動態分配計算,2024 [Paper]
- 分支機構混合:將專家LLM混合到Experts LLM的混合物中,2024 [Paper]
- 專家的混合Arxiv,2024年[紙] [代碼]
- Mistral 7b, Arxiv,2023年[紙] [代碼]
- pangu-σ:使用稀疏異質計算的數万億個參數語言模型, Arxiv,2023年[紙]
- 開關變壓器:具有簡單有效的稀疏性的縮放到萬億個參數模型, JMLR,2022年[紙] [代碼]
- 有效的大規模語言建模與專家的混合物, Emnlp,2022年[紙] [代碼]
- 基層:簡化大型稀疏模型的培訓, ICML,2021 [紙] [代碼]
- GSHARD:使用條件計算和自動碎片的尺度縮放巨型模型, ICLR,2021 [紙]
算法級MUE優化
- Seer-Moe:通過正規化的專家效率稀少Arxiv,2024/ins> [紙]
- 為專家的細粒度混合物的縮放法律, Arxiv,2024/ins> [紙]
- 終身用分銷專家預測的語言, ICML,2023 [紙]
- Experts的混合物符合教學調整:大型語言模型的獲勝組合, Arxiv,2023年[紙]
- 與專家選擇路由相混合的混合物,神經,2022年[紙]
- Stablemoe:專家混合的穩定路由策略, ACL,2022年[紙] [代碼]
- 關於專家稀疏混合物的代表崩潰,神經,2022年[紙]
長上下文LLM
外推和插值
- 兩塊石頭擊中一隻鳥:雙杆位置編碼,以提高長度的外推, ICML,2024 [紙]
- ∞基礎:將長上下文評估延長超過100k令牌, Arxiv,2024年[紙]
- 共振繩:改善上下文長度概括大型語言模型, Arxiv,2024年[紙] [代碼]
- longrope:將LLM上下文窗口延長超過200萬個令牌, Arxiv,2024年[紙]
- e^2-llm:大語模型的高效和極端長度擴展, Arxiv,2024年[紙]
- 基於繩索外推的縮放定律, Arxiv,2023年[紙]
- 一個長度驅動變壓器, ACL,2023年[紙] [代碼]
- 通過位置插值擴展大型語言模型的上下文窗口, Arxiv,2023年[紙]
- NTK插值,博客,2023年[Reddit帖子]
- 紗線:大語模型的有效上下文窗口擴展, Arxiv,2023年[紙] [代碼]
- clex:大語言模型的連續長度外推, Arxiv,2023年[紙] [代碼]
- 姿勢:通過位置跳過訓練的LLM的有效上下文窗口擴展, Arxiv,2023年[紙] [代碼]
- 相對位置的功能插值可改善長上下文變壓器, Arxiv,2023年[紙]
- 訓練短,測試長:帶有線性偏見的注意力可以使輸入長度外推, ICLR,2022 [紙] [代碼]
- 探索大語模型中的長度概括,神經,2022年[紙]
復發結構
- 保留網絡:大型語言模型變壓器的繼任者, Arxiv,2023年[紙] [代碼]
- 經常性內存變壓器,神經,2022年[紙] [代碼]
- 塊狀變壓器,神經,2022年[紙] [代碼]
- ∞組:無限內存變壓器, ACL,2022年[紙] [代碼]
- memformer:用於序列建模的內存增強變壓器, aacl-findings,2020年[紙] [代碼]
- Transformer-XL:超出固定長度上下文的細心語言模型, ACL,2019年[紙] [代碼]
細分和滑動窗口
- XL3M:基於細分推斷的LLM長度擴展的無訓練框架, Arxiv,2024年[紙]
- Transformerfam:反饋注意是工作記憶, Arxiv,2024年[紙]
- 基於天真的貝葉斯的上下文擴展大語模型, NAACL,2024年[紙]
- 沒有留下背景Arxiv,2024年[紙]
- 對神經壓縮文本的培訓LLM, Arxiv,2024年[紙]
- LM侵犯:大語言模型的零射擊極端概括, Arxiv,2024年[紙]
- 大型語言模型的無培訓長篇小說縮放, Arxiv,2024年[紙] [代碼]
- 使用並行上下文編碼的長篇小寫語言建模, Arxiv,2024年[紙] [代碼]
- 從4K飆升至400k:通過激活信標擴展LLM的上下文, Arxiv,2024年[紙] [代碼]
- llm也許是longlm:自我擴展llm上下文窗口而無需調整, Arxiv,2024年[紙] [代碼]
- 通過語義壓縮擴展大型語言模型的上下文窗口, Arxiv,2023年[紙]
- 有效的流式語言模型,帶有註意力下沉, Arxiv,2023年[紙] [代碼]
- 大型語言模型的並行上下文窗口, ACL,2023年[紙] [代碼]
- Longnet:將變形金剛縮放到1,000,000,000個令牌, Arxiv,2023年[紙] [代碼]
- 有效的長文本模型的有效理解, TACL,2023年[紙] [代碼]
內存回程增強
- INFLLM:揭示LLM的內在能力,以理解無訓練記憶的極長序列, Arxiv,2024年[紙]
- 具有里程碑意義的關注:變壓器的隨機訪問無限上下文長度, Arxiv,2023年[紙] [代碼]
- 具有長期記憶的增強語言模型,神經,2023年[紙]
- 無形者:無限長度輸入的遠程變壓器,神經,2023年[紙] [代碼]
- 專注的變壓器:上下文縮放的對比培訓,神經,2023年[紙] [代碼]
- 檢索符合長上下文大語言模型, Arxiv,2023年[紙]
- 記憶變壓器, ICLR,2022 [紙] [代碼]
變壓器替代體系結構
狀態空間模型
- 變形金剛是SSM:通過結構化狀態空間二重性的廣義模型和有效算法, Arxiv,2024年[紙]
- Moe-Mamba:有效的選擇性狀態空間模型與專家混合在一起, Arxiv,2024年[紙]
- Densemamba:具有密集隱藏連接的狀態空間模型,可高效的大語言模型, Arxiv,2024年[紙] [代碼]
- Mambabyte:無令牌的選擇性狀態空間模型, Arxiv,2024年[紙]
- 稀疏的模塊化激活,用於有效序列建模,神經,2023年[紙] [代碼]
- MAMBA:具有選擇性狀態空間的線性時間序列建模, Arxiv,2023年[紙] [代碼]
- 飢餓的飢餓河馬:邁向使用狀態空間模型的語言建模, ICLR 2023 [紙] [代碼]
- 通過封閉狀態空間進行遠程語言建模, ICLR,2023年[紙]
- 塊狀變壓器,神經,2023年[紙]
- 有效地用結構化狀態空間對長序列進行建模, ICLR,2022 [紙] [代碼]
- 對角狀態空間與結構化狀態空間一樣有效,神經,2022年[紙] [代碼]
其他順序模型
- 差分變壓器, Arxiv,2024年[紙]
- 可擴展的無原始語言建模, Arxiv,2024年[紙]
- 您僅緩存一次:語言模型的解碼器架構, Arxiv,2024年[紙]
- Megalodon:有效的LLM預訓練和無限上下文長度的推斷, Arxiv,2024年[紙]
- Dijiang:通過緊湊的內核化有效的大型語言模型, Arxiv,2024年[紙]
- 格里芬:將封閉式線性複發與當地的關注進行混合,以提高有效語言模型, Arxiv,2024年[紙]
- pangu-π:通過非線性補償增強語言模型體系結構, Arxiv,2023年[紙]
- RWKV:重塑變壓器時代的RNN, Emnlp-findings,2023年[紙]
- 鬣狗的層次結構:邁向更大的捲積語言模型, Arxiv,2023年[紙]
- Megabyte:使用多尺度變壓器預測百萬個字節序列, Arxiv,2023年[紙]
?以數據為中心的方法
數據選擇
有效培訓的數據選擇
- 伴侶:用於使用數據影響模型進行有效預處理的模型感知數據選擇, Arxiv,2024年[紙]
- DOREMI:優化數據混合物加快了語言模型的預處理,神經,2023年[紙]
- 通過重要性重採樣的語言模型的數據選擇,神經,2023年[紙] [代碼]
- NLP從頭開始,沒有大規模預處理:一個簡單有效的框架, ICML,2022 [紙] [代碼]
- 跨越預培訓以回答問題, ACL,2020年[紙] [代碼]
有效微調的數據選擇
- 顯示,不要說:將語言模型與已顯示的反饋對齊, Arxiv,2024年[紙]
- 從頭開始的合成數據(幾乎):語言模型的廣義指令調整, Arxiv,2024年[紙]
- AutomAthText:使用數學文本的語言模型的自主數據選擇, Arxiv,2024年[紙] [代碼]
- 是什麼使良好的數據保持對齊?對教學調整中的自動數據選擇的全面研究, ICLR,2024 [紙] [代碼]
- 如何培訓數據效率LLM, Arxiv,2024年[紙]
- 少:選擇有影響力的數據以調整有影響力的數據, Arxiv,2024年[紙] [代碼]
- 超濾波器:快速指令調整的弱到較強的數據過濾, Arxiv,2024年[紙] [代碼]
- 一個鏡頭學習作為大語模型的指導數據勘探者, Arxiv,2023年[紙]
- mods:指導調整的面向模型的數據選擇, Arxiv,2023年[紙] [代碼]
- 從數量到質量:通過自導的數據選擇來提高LLM性能以進行指導調整, Arxiv,2023年[紙] [代碼]
- 指令挖掘:當數據挖掘符合大型語言模型列出時, Arxiv,2023年[紙]
- 使用交叉任務最近的鄰居的數據有效的填充, ACL,2023年[紙] [代碼]
- 使用傳輸的沙普利值的微調大語言模型的數據選擇, ACL SRW,2023年[紙] [代碼]
- 也許只需要0.5%的數據:對低訓練數據指導調整的初步探索, Arxiv,2023年[紙]
- Alpagasus:訓練一個更好的羊駝的數據,較少的數據, Arxiv,2023年[紙] [代碼]
- 利馬:更少的是對齊, Arxiv,2023年[紙]
及時的工程
很少射擊
示範組織
演示選擇
- 統一的演示檢索器,用於內在的學習, ACL,2023年[紙] [代碼]
- 大型語言模型是潛在變量模型:解釋和尋找良好的示威活動,神經,2023年[紙] [代碼]
- 在迭代演示選擇中學習中的內在學習, Arxiv,2022年[紙]
- ICL博士:示範 - 重新介紹的學習, Arxiv,2022年[紙]
- 學會檢索大語模型的文章示例, Arxiv,2022年[紙]
- 尋找支持示例的文章學習, Arxiv,2022年[紙]
- 自適應性內在學習:信息壓縮透視示例選擇和訂購的觀點, ACL,2023年[紙] [代碼]
- 選擇性註釋使語言模型更好,幾乎沒有學習者, ICLR,2023年[紙] [代碼]
- 是什麼使GPT-3的良好的文本示例呢? Deelio,2022年[紙]
- 學會檢索提示中的內在學習, Naacl-HLT,2022年[紙] [代碼]
- 積極的示例選擇中下文學習, Emnlp,2022年[紙] [代碼]
- 重新思考示範的作用:是什麼使內在的學習工作? Emnlp,2022年[紙] [代碼]
演示順序
- 奇妙的有序提示和在哪裡可以找到它們:克服幾乎沒有彈藥的命令敏感性, ACL,2022年[紙]
模板格式
指導生成
- 大型語言模型作為優化者, Arxiv,2023年[紙]
- 指導誘導:從幾個示例到自然語言任務描述, ACL,2023年[紙] [代碼]
- 大型語言模型是人級及時的工程師, ICLR,2023年[紙] [代碼]
- TEGIT:使用文本接地的任務設計生成高質量的指令調整數據, Arxiv,2023年[紙]
- 自我建造:將語言模型與自我生成的指示結合, ACL,2023年[紙] [代碼]
多步推理
- 縮放LLM測試時間計算最佳比例比縮放模型參數更有效, Arxiv,2024年[紙]
- 學習與LLM一起推理,網站,2024年[html]
- 安靜的明星:語言模型可以在說話之前自我思考, Arxiv,2024年[紙]
- 從顯式cot到隱式cot:學習逐步內部化cot, ICLR,2024 [紙]
- 自動思想鏈引發大型語言模型, ICLR,2023年[紙] [代碼]
- 測量和縮小語言模型中的組成差距, Emnlp,2023年[紙] [代碼]
- 反應:在語言模型中協同推理和作用, ICLR,2023年[紙] [代碼]
- 最小一是提示可以在大語言模型中實現複雜的推理, ICLR,2023年[紙]
- 思想圖:解決大型語言模型的詳盡問題, Arxiv,2023年[紙] [代碼]
- 思想樹:大型語言模型的故意解決問題,神經,2023年[紙] [代碼]
- 自我矛盾改善了語言模型中的思想推理鏈, ICLR,2023年[紙]
- 思想圖:解決大型語言模型的詳盡問題, Arxiv,2023年[紙] [代碼]
- 對比鏈的促進,促使Arxiv,2023年[紙] [代碼]
- 一切思想:違抗彭羅斯三角定律,以創造思想的產生, Arxiv,2023年[紙]
- 經過思考的鏈條促使在大語言模型中引起推理,神經,2022年[紙]
平行生成
- 通過多言論預測更好,更快的大語模型, Arxiv,2023年[紙]
- 思想骨架:大型語言模型可以進行平行解碼, Arxiv,2023年[紙] [代碼]
及時壓縮
- llmlingua-2:數據蒸餾,以實現高效和忠實的任務不合時宜的及時壓縮, Arxiv,2024年[紙]
- PCToolKit:大型語言模型的統一插件提示工具包, Arxiv,2024年[紙]
- 在線語言模型互動的壓縮上下文內存, ICLR,2024 [紙]
- 學會用要點令牌壓縮提示, Arxiv,2023年[紙]
- 適應語言模型以壓縮上下文, Emnlp,2023年[紙] [代碼]
- 在大型語言模型中進行上下文壓縮的內在自動編碼器, Arxiv,2023年[紙] [代碼]
- longllmlingua:通過迅速壓縮,在長上下文場景中加速和增強LLM, Arxiv,2023年[紙] [代碼]
- 通過增強學習的離散及時壓縮, Arxiv,2023年[紙]
- 掘金2D:用於縮放解碼器語言模型的動態上下文壓縮, Arxiv,2023年[紙]
迅速產生
- Templm:將語言模型蒸餾到基於模板的發生器中, Arxiv,2022年[紙] [代碼]
- 提示:使用生成模型自動生成提示, NAACL發現,2022年[紙]
- 自動啟動:從具有自動生成的提示的語言模型中獲取知識, Emnlp,2020年[紙] [代碼]
?系統級效率優化和LLM框架
系統級效率優化
系統級訓練效率優化
- Megascale:將大型語言模型培訓擴展到10,000多個GPU, Arxiv,2024年[紙]
- 牧羊犬:有效地對大語言模型進行協作培訓, Emnlp,2023年[紙] [代碼]
- 一種高效訓練超大深度學習模型的2D方法, IPDP,2023 [紙] [代碼]
- Pytorch FSDP:平行縮放完全碎片數據的體驗, VLDB,2023年[紙]
- 竹子:使可負擔培訓有彈性的搶占實例, NSDI,2023年[紙] [代碼]
- Oobleck:使用管道模闆對大型模型的彈性分佈訓練, SOSP,2023年[紙] [代碼]
- Varuna:大規模深度學習模型的可擴展,低成本培訓,歐元,2022年[紙] [代碼]
- 統一:通過代數轉換和並行化的聯合優化加速DNN訓練,奧斯迪,2022年[紙] [代碼]
- Tesseract:有效地使張量並行性平行, ICPP,2022年, [紙]
- ALPA:自動化分佈式深度學習的間和內部的並行性,奧斯迪,2022年,[紙] [代碼]
- 在巨大神經網絡的分佈式培訓中最大化並行性, Arxiv,2021年[紙]
- Megatron-LM:使用模型並行培訓數十億個參數語言模型, Arxiv,2020年[紙]
- 使用Megatron-LM對GPU群集進行有效的大規模語言模型培訓, SC,2021 [紙] [代碼]
- 零內在:打破GPU記憶牆以進行極端的深度學習, SC,2021 [紙]
- 零下載:民主化十億個規模的模型培訓, USENIX ATC,2021年[紙] [代碼]
- 零:用於訓練萬億參數模型的內存優化, SC,2020 [紙] [代碼]
系統級服務效率優化
服務系統設計
- LUT Tensor Core:查找表啟用有效的低位LLM推理加速度, Arxiv,2024年[紙]
- Turbotransformer:用於變壓器模型的有效GPU服務系統, PPOPP,2021年[紙]
- ORCA:用於基於變壓器的生成模型的分佈式服務系統,奧斯迪,2022年[紙]
- FlexGEN:具有單個GPU的大語言模型的高通量生成推斷, ICML,2023 [紙] [代碼]
- 有效地縮放變壓器推斷, MLSYS,2023年[紙]
- 深速推導:以前所未有的規模啟用變壓器模型的有效推斷, SC,2022 [紙]
- 大型語言模型的有效記憶管理,以用page術服務, SOSP,2023年[紙] [代碼]
- S-Lora:為成千上萬的並發洛拉適配器提供服務, Arxiv,2023年[紙] [代碼]
- 花瓣:大型模型的協作推理和微調, Arxiv,2023年[紙]
- Spotserve:在可享有的實例上提供生成的大語言模型, Arxiv,2023年[紙]
服務性能優化
- KV-Runahead:可擴展的因果LLM通過並行鍵值緩存生成, Arxiv,ICML [紙]
- Cachegen:快速語言模型服務的KV緩存壓縮和流媒體, Arxiv,2024年[紙]
- 預測性管道解碼:精確LLM解碼的計算延遲權衡, TMLR,2024 [紙]
- Flash-llm:實現具有成本效益且高效的大生成模型的推斷,並具有非結構化的稀疏性, Arxiv,2023年[紙]
- S3:在生成推斷期間增加GPU利用率以提高吞吐量, Arxiv,2023年[紙]
- 快速分佈式推理用於大型語言模型, Arxiv,2023年[紙]
- 響應長度感知和序列調度:LLM授權的LLM推理管道, Arxiv,2023年[紙]
- Sarathi:有效的LLM通過塊狀預填補的解碼來推論, Arxiv,2023年[紙]
- frugalgpt:如何使用大語言模型,同時降低成本和提高性能, Arxiv,2023年[紙]
- 提示緩存:低延遲推斷的模塊化注意力使用, Arxiv,2023年[紙]
- 服務大型語言模型的公平性, Arxiv,2023年[紙]
算法 - 硬件共同設計
- flashattention-3:異步和低精度,快速準確地關注, Arxiv,2024年[紙]
- 閃存:具有IO意識的快速和記憶效率精確的關注,神經,2022年[紙] [代碼]
- flashattention-2:更快地關注和平行性和工作劃分, Arxiv,2023年[紙] [代碼]
- 閃存編碼用於長篇小說推斷,博客,2023年[部落格]
- flashdecoding ++:gpus上更快的大語言模型推斷, Arxiv,2023年[紙]
- PowerInfer:用消費級GPU服務的快速大語模型, Arxiv,2023年[紙] [代碼]
- 閃光燈中的LLM:有限的內存,有效的大型語言模型推斷, Arxiv,2023年[紙]
- chiplet雲:構建用於服務大型生成語言模型的AI超級計算機, Arxiv,2023年[紙]
- Edgemoe:基於MOE的大型語言模型的快速推理, Arxiv,2022年[紙]
LLM框架
| 有效的培訓 | 有效的推斷 | 有效的微調 |
|---|
| 深速[代碼] | ✅ | ✅ | ✅ |
| 威震天[代碼] | ✅ | ✅ | ✅ |
| Colossalai [代碼] | ✅ | ✅ | ✅ |
| 納米人[代碼] | ✅ | ✅ | ✅ |
| 巨型[代碼] | ✅ | ✅ | ✅ |
| FairScale [代碼] | ✅ | ✅ | ✅ |
| PAX [代碼] | ✅ | ✅ | ✅ |
| 作曲家[代碼] | ✅ | ✅ | ✅ |
| optlllm [代碼] | | ✅ | ✅ |
| llm-foundry [代碼] | | ✅ | ✅ |
| VLLM [代碼] | | ✅ | |
| tensorrt-llm [代碼] | | ✅ | |
| TGI [代碼] | | ✅ | |
| rayllm [代碼] | | ✅ | |
| MLC LLM [代碼] | | ✅ | |
| 薩克斯[代碼] | | ✅ | |
| MOSEC [代碼] | | ✅ | |


