نماذج لغة كبيرة فعالة: مسح
نماذج لغة كبيرة فعالة: مسح [ARXIV] (الإصدار 1: 12/06/2023 ؛ الإصدار 2: 12/23/2023 ؛ الإصدار 3: 01/31/2024 ؛ الإصدار 4: 05/23/2024 ، نسخة جاهزة للمعاملات في أبحاث التعلم الآلي)
Zhongwei Wan 1 ، Xin Wang 1 ، Che Liu 2 ، Samiul Alam 1 ، Yu Zheng 3 ، Jiachen Liu 4 ، Zhongnan qu
1 جامعة ولاية أوهايو ، 2 الكلية الإمبراطورية لندن ، 3 جامعة ولاية ميشيغان ، 4 جامعة ميشيغان ، 5 أمازون AWS AI ، 6 Google Research ، 7 Boson AI ، 8 Microsoft Research Asia
⚡ News: تم قبول استطلاعنا رسميًا من خلال المعاملات في أبحاث التعلم الآلي (TMLR) ، مايو 2024. الإصدار الجاهز للكاميرا متاح على: [OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
❤ دعم المجتمع
يتم الحفاظ على هذا المستودع بواسطة تودان ([email protected]) ، Sustechbruce ([email protected]) ، Samiul272 ([email protected]) ، و Mi-Zhang ([email protected]). نرحب بالتعليقات والاقتراحات والمساهمات التي يمكن أن تساعد في تحسين هذا الاستطلاع والمستودع لجعلها موارد قيمة لصالح المجتمع بأكمله.
سنحافظ بنشاط على هذا المستودع من خلال دمج بحث جديد أثناء ظهوره. إذا كان لديك أي اقتراحات بخصوص تصنيفنا ، فابحث عن أي أوراق فائتة ، أو تحديث أي ورقة Preprint Arxiv التي تم قبولها في بعض الأماكن ، أو لا تتردد في إرسال بريد إلكتروني إلينا أو إرسال طلب سحب باستخدام تنسيق تخفيض الطلب التالي.
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
؟ ما هذا الاستطلاع؟
أظهرت نماذج اللغة الكبيرة (LLMS) قدرات ملحوظة في العديد من المهام المهمة ولديها القدرة على إحداث تأثير كبير على مجتمعنا. ومع ذلك ، فإن مثل هذه القدرات تأتي مع متطلبات كبيرة للموارد ، مما يبرز الحاجة القوية لتطوير تقنيات فعالة لمعالجة تحديات الكفاءة التي تطرحها LLMs. في هذا الاستطلاع ، نقدم مراجعة منهجية وشاملة لأبحاث LLMS الفعالة. نقوم بتنظيم الأدبيات في تصنيف يتكون من ثلاث فئات رئيسية ، تغطي مواضيع LLMs المتميزة المميزة ولكن المترابطة من المنظور المتمحور حول النموذج ، المتمحورة حول البيانات ، وتركز على الإطار ، على التوالي. نأمل أن يكون استطلاعنا ومستودع GitHub هذا بمثابة موارد قيمة لمساعدة الباحثين والممارسين على اكتساب فهم منهجي للتطورات البحثية في LLMs الفعالة وإلهامهم للمساهمة في هذا المجال المهم والمثير.
؟ لماذا هناك حاجة إلى LLMs الفعالة؟
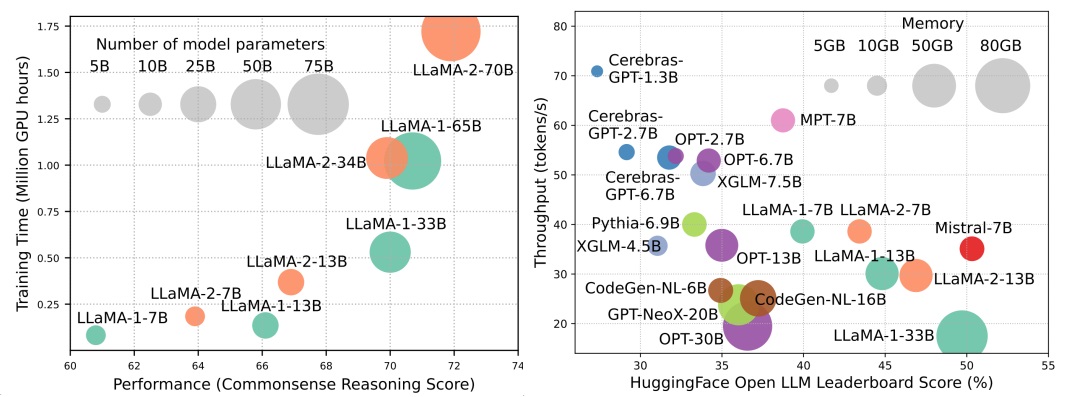
على الرغم من أن LLMS تقود الموجة التالية من ثورة الذكاء الاصطناعي ، فإن القدرات الرائعة لـ LLMs تأتي على حساب متطلبات الموارد الكبيرة. يوضح الشكل 1 (يسار) العلاقة بين أداء النموذج ووقت التدريب النموذجي من حيث ساعات GPU لسلسلة Llama ، حيث يتناسب حجم كل دائرة مع عدد معلمات النموذج. كما هو موضح ، على الرغم من أن النماذج الأكبر قادرة على تحقيق أداء أفضل ، فإن كميات ساعات معالجة الرسومات المستخدمة لتدريبها تنمو بشكل كبير مع ارتفاع أحجام النماذج. بالإضافة إلى التدريب ، يساهم الاستدلال أيضًا بشكل كبير في التكلفة التشغيلية لـ LLMS. الشكل 2 (يمين) يصور العلاقة بين أداء النموذج وإنتاجية الاستدلال. وبالمثل ، فإن زيادة حجم النموذج يتيح أداء أفضل ولكنه يأتي على حساب انخفاض إنتاجية الاستدلال (زمن استنتاج أعلى) ، مما يدل على تحديات لهذه النماذج في توسيع نطاق وصولها إلى قاعدة عملاء أوسع وتطبيقات متنوعة بطريقة فعالة من حيث التكلفة. تبرز متطلبات الموارد العالية من LLMs الحاجة القوية لتطوير تقنيات لتعزيز كفاءة LLMs. كما هو مبين في الشكل 2 ، بالمقارنة مع Llama-1-33b ، فإن Mistral-7B ، والذي يستخدم اهتمامًا جماعيًا واهتمامًا بالنافذة المنزلق لتسريع الاستدلال ، ويحقق أداءً قابلاً للمقارنة وإنتاجية أعلى بكثير. يسلط هذا التفوق الضوء على جدوى وأهمية تصميم تقنيات الكفاءة لـ LLMS.
جدول المحتوى
- ؟ الطرق المتمحورة حول النموذج
- ضغط النموذج
- الكمية
- كمية بعد التدريب
- تقدير الوزن فقط
- التفعيل التفعيل للوزن
- تقييم كمية ما بعد التدريب
- تدريب على دراية كمية
- المعلمة التقليم
- تشذيب منظم
- تقليم غير منظم
- تقريب منخفضة الرتبة
- تقطير المعرفة
- بيضاء الصندوق KD
- صندوق أسود كويدي
- مشاركة المعلمة
- فعالة قبل التدريب
- التدريب الدقيق المختلط
- نماذج التحجيم
- تقنيات التهيئة
- محسن التدريب
- صقل فعال
- المعلمة فعالة صقل دقيق
- ضبط القائم على المحول
- التكيف منخفض الرتبة
- بادئة ضبط
- ضبط موجه
- الذاكرة فعالة النثى
- مواد مفعمة بالإشراف على الضبط
- الاستدلال الفعال
- فك تشفير الموازي
- فك تشفير المضاربة
- KV-Cache Optimization
- الهندسة المعمارية الفعالة
- اهتمام فعال
- الانتباه القائم على المشاركة
- ميزة تخفيض المعلومات
- kernelization أو منخفضة الرتبة
- استراتيجيات نمط ثابت
- استراتيجيات نمط قابلة للتعلم
- مزيج من الخبراء
- LLMS المستندة إلى MOE
- تحسين مستوى الخوارزمية
- سياق طويل LLMS
- الاستقراء والاستيفاء
- بنية متكررة
- تجزئة ونافذة منزلق
- تكبير الذاكرة البارز
- العمارة البديلة المحول
- نماذج فضاء الدولة
- نماذج متتابعة أخرى
- ؟ طرق تركز على البيانات
- اختيار البيانات
- اختيار البيانات للتدريب المسبق الفعال
- اختيار البيانات للضغط الدقيق الفعال
- الهندسة الفورية
- القليل من اللقطة
- منظمة العرض التوضيحي
- اختيار العرض التوضيحي
- ترتيب العرض التوضيحي
- تنسيق قالب
- توليد التعليمات
- التفكير متعدد الخطوات
- جيل موازي
- ضغط فوري
- جيل موجه
- تحسين كفاءة مستوى النظام وأطر LLM
- تحسين الكفاءة على مستوى النظام
- تحسين كفاءة ما قبل التدريب على مستوى النظام
- تحسين كفاءة الخدمة على مستوى النظام
- خدمة تصميم نظام
- خدمة تحسين الأداء
- تصميم الخوارزمية المشاركة في التصميم
- أطر LLM
؟ الطرق المتمحورة حول النموذج
ضغط النموذج
الكمية
كمية بعد التدريب
تقدير الوزن فقط
- I-LLM: الاستدلال الصحيح فقط للنماذج اللغوية المنخفضة بت الكاملة ، Arxiv ، 2024 [ورق]
- INTACTKV: تحسين تقدير نموذج اللغة الكبيرة عن طريق الحفاظ على الرموز المحورية سليمة ، Arxiv ، 2024 [ورق]
- كلوانيك: كلوانيت: الكميات المعايرة في كل مكان للنماذج اللغوية الكبيرة ، ICLR ، 2024 [ورقة] [رمز]
- Onebit: نحو نماذج لغة كبيرة منخفضة البت للغاية ، Arxiv ، 2024 [ورق]
- GPTQ: القياس الدقيق للمحولات التي تم تدريبها مسبقًا ، ICLR ، 2023 [ورقة] [رمز]
- Quip: كمية 2 بت من نماذج اللغة الكبيرة مع ضمانات ، Arxiv ، 2023 [ورقة] [رمز]
- AWQ: كميات الوزن التي تدرك التنشيط لضغط LLM والتسارع ، Arxiv ، 2023 [ورقة] [رمز]
- OWQ: الدروس المستفادة من القيم المتطرفة للتنشيط لتحديد الوزن في نماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- SPQR: تمثيل متناثر مسبق لضغط وزن LLM شبه الخسارة ، Arxiv ، 2023 [ورقة] [رمز]
- غرامة: فتح الكفاءة مع كميات الوزن ذات الوزن الدقيق فقط لـ LLMS ، Neups-enlsp ، 2023 [ورق]
- LLM.Int8 (): مضاعفة مصفوفة 8 بت للمحولات على نطاق واسع ، Neurolps ، 2022 [ورقة] [رمز]
- ضغط الدماغ الأمثل: إطار عمل دقيق لما بعد التدريب والتقليم ، Neupips ، 2022 [ورقة] [رمز]
- الكمية: القياس الكمي القائم على التحسين لنماذج اللغة ، Arxiv ، 2023 [ورقة] [رمز]
التفعيل التفعيل للوزن
- الدوران والتقليب للإدارة الخارجية المتقدمة والكمية الفعالة لـ LLMS ، Neupips ، 2024 [ورق]
- كلوانيك: كلوانيت: الكميات المعايرة في كل مكان للنماذج اللغوية الكبيرة ، ICLR ، 2024 [ورقة] [رمز]
- خصائص مثيرة للاهتمام من القياس الكمي على نطاق واسع ، Neupips ، 2023 [ورق]
- Zeroquant-V2: استكشاف تقدير ما بعد التدريب في LLMs من دراسة شاملة إلى تعويض منخفض الرتبة ، Arxiv ، 2023 [ورقة] [رمز]
- Zeroquant-FP: قفزة إلى الأمام في LLMS بعد التدريب الكمي W4A8 باستخدام تنسيقات الفاصلة العائمة ، Neups-enlsp ، 2023 [ورقة] [رمز]
- الزيتون: تسريع نماذج لغة كبيرة عبر كمية الزوج الصديقة للأجهزة ، ISCA ، 2023 [ورقة] [رمز]
- RPTQ: كميات ما بعد التدريب القائمة على الترتيب لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- القمع الخارجي+: الكمية الدقيقة لنماذج اللغة الكبيرة عن طريق التحول والتوسيع الأمثل والمكافئ ، Arxiv ، 2023 [ورقة] [رمز]
- QLLM: كمية دقيقة وفعالة منخفضة النطاق لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورق]
- SmoothQuant: كمية دقيقة وفعالة بعد التدريب لنماذج اللغة الكبيرة ، ICML ، 2023 [ورقة] [رمز]
- Zeroquant: كفاءة فعالة وبأسعار معقولة بعد التدريب للمحولات على نطاق واسع ، Neupips ، 2022 [ورق]
تقييم كمية ما بعد التدريب
- تقييم نماذج اللغة الكبيرة الكمية ، Arxiv ، 2024 [ورق]
تدريب على دراية كمية
- عصر LLMS 1 بت: جميع نماذج اللغة الكبيرة في 1.58 بت ، Arxiv ، 2024 [ورق]
- FP8-LM: تدريب نماذج اللغة الكبيرة FP8 ، Arxiv ، 2023 [ورق]
- تدريب واستنتاج نماذج اللغة الكبيرة باستخدام نقطة عائمة 8 بت ، Arxiv ، 2023 [ورق]
- Bitnet: تحجيم محولات 1 بت لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورق]
- LLM-QAT: تدريب إدراك كميات خالية من البيانات لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- ضغط نماذج اللغة المسبقة قبل التدريب من خلال القياس الكمي ، ACL ، 2022 [ورق]
المعلمة التقليم
تشذيب منظم
- نماذج اللغة المدمجة عبر تقليم وتقطير المعرفة ، Arxiv ، 2024 [ورق]
- نظرة أعمق على تقليم العمق من LLMS ، Arxiv ، 2024 [ورق]
- في حيرة من الحيرة: البيانات القائمة على الحيرة التي تشبه النماذج المرجعية الصغيرة ، Arxiv ، 2024 [ورق]
- التوصيل والتشغيل: طريقة فعالة بعد التدريب لنماذج اللغة الكبيرة ، ICLR ، 2024 [ورق]
- BESA: تقليم نماذج لغة كبيرة مع تخصيص تفريخ فعال معلمة ، Arxiv ، 2024 [ورق]
- Shortgpt: الطبقات في نماذج اللغة الكبيرة أكثر زائدة مما تتوقع ، Arxiv ، 2024 [ورق]
- Nuteprune: تقليم تدريجي فعال مع العديد من المعلمين لنماذج اللغة الكبيرة ، Arxiv ، 2024 [ورق]
- Slicegpt: ضغط نماذج اللغة الكبيرة عن طريق حذف الصفوف والأعمدة ، ICLR ، 2024 [ورقة] [رمز]
- Lorashear: نموذج لغة كبير فعال منظم تقليم واستعادة المعرفة ، Arxiv ، 2023 [ورق]
- LLM-Pruner: على التقليم الهيكلي لنماذج اللغة الكبيرة ، Neupips ، 2023 [ورقة] [رمز]
- Llama القص: تسريع نموذج اللغة قبل التدريب من خلال التقليم المنظم ، Neups-enlsp ، 2023 [ورقة] [رمز]
- لورابريون: التقليم يلتقي بصقل منخفض معلمة فعال ، Arxiv ، 2023 [ورق]
تقليم غير منظم
- Maskllm: تباين شبه منظم في نماذج اللغة الكبيرة ، نيبس ، 2024 [ورق]
- Dynamic Sparse No Training: صقل خالي من التدريب ل LLMs متناثرة ، ICLR ، 2024 [ورق]
- sparsegpt: يمكن تقليم نماذج اللغة الضخمة بدقة في طلقة واحدة ، ICML ، 2023 [ورقة] [رمز]
- نهج تقليم بسيط وفعال لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- حساسية واحدة-تدرك الحساسية المتنوعة مختلطة التقليم لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورق]
تقريب منخفضة الرتبة
- SVD-LLM: تحلل القيمة الفردية لضغط نموذج اللغة الكبيرة ، Arxiv ، 2024 [ورقة] [رمز]
- ASVD: تحلل القيمة المفرد الوعرة لضغط نماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- ضغط نموذج اللغة مع العوامل المنخفضة المرجح ، ICLR ، 2022 [ورق]
- Tensorgpt: ضغط فعال لطبقة التضمين في LLMs بناءً على تحلل تدريب الموتر ، Arxiv ، 2023 [ورق]
- الغضب: ضغط منظم لنماذج اللغة الكبيرة القائمة على التقريب المنخفض والتفريخ ، ICML ، 2023 [ورقة] [رمز]
تقطير المعرفة
بيضاء الصندوق KD
- DDK: تقطير معرفة المجال لنماذج اللغة الكبيرة الفعالة Arxiv ، 2024 [ورق]
- إعادة التفكير في التباعد Kullback-Lyibler في تقطير المعرفة لنماذج اللغة الكبيرة Arxiv ، 2024 [ورق]
- Distillm: نحو التقطير المبسط لنماذج اللغة الكبيرة ، Arxiv ، 2024 [ورقة] [رمز]
- نحو قانون الفجوة في السعة في نماذج اللغة ، Arxiv ، 2023 [ورقة] [رمز]
- بيبي لاما: تقطير المعرفة من مجموعة من المعلمين المدربين على مجموعة بيانات صغيرة بدون عقوبة أداء ، Arxiv ، 2023 [ورق]
- تقطير المعرفة لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- GKD: تقطير المعرفة المعممة لنماذج التسلسل التلقائي التلقائي ، Arxiv ، 2023 [ورق]
- نشر تحديثات المعرفة إلى LMS من خلال التقطير ، Arxiv ، 2023 [ورقة] [رمز]
- أقل من ذلك: التقطير المرفق للطبقة لضغط نموذج اللغة ، ICML ، 2023 [ورق]
- التقطير المنطقي المميز لنماذج اللغة التوليدية للوزن الثلاثي ، Arxiv ، 2023 [ورق]
صندوق أسود كويدي
- Zephyr: التقطير المباشر لمحاذاة LM ، Arxiv ، 2023 [ورق]
- تعليمات ضبط مع GPT-4 ، Arxiv ، 2023 [ورقة] [رمز]
- الأسد: التقطير العدائي لنموذج اللغة الكبيرة المغلقة ، Arxiv ، 2023 [ورقة] [رمز]
- متخصصة في نماذج اللغة الأصغر نحو التفكير متعدد الخطوات ، ICML ، 2023 [ورقة] [رمز]
- تقطير خطوة بخطوة! يتفوق على نماذج لغة أكبر مع بيانات تدريب أقل وأحجام نموذجية أصغر ، ACL ، 2023 [ورق]
- نماذج اللغة الكبيرة تعتبر المعلمين ، ACL ، 2023 [ورقة] [رمز]
- سكوت: التقطير المتسق ذاتيًا ، ACL ، 2023 [ورقة] [رمز]
- التقطير الرمزي لسلسلة الفكر: يمكن أيضًا "التفكير" في النماذج الصغيرة ، خطوة بخطوة ، ACL ، 2023 [ورق]
- تقطير إمكانيات التفكير في نماذج لغة أصغر ، ACL ، 2023 [ورقة] [رمز]
- التقطير التعليمي في السياق: نقل قدرة التعلم القليلة على نماذج اللغة التي تم تدريبها مسبقًا ، Arxiv ، 2022 [ورق]
- تفسيرات من نماذج اللغات الكبيرة تجعل المناطق الصغيرة أفضل ، Arxiv ، 2022 [ورق]
- ديسكو: تقطير عوامل مضادة مع نماذج لغة كبيرة ، Arxiv ، 2022 [ورقة] [رمز]
مشاركة المعلمات
- موبيلاما: نحو GPT دقيق وخفيف الوزن تمامًا ، Arxiv ، 2024 [ورق]
فعالة قبل التدريب
التدريب الدقيق المختلط
- معالجة BFLOAT16 للشبكات العصبية ، ARITH ، 2019 [ورق]
- دراسة لـ Bfloat16 للتدريب على التعلم العميق ، Arxiv ، 2019 [ورق]
- التدريب الدقيق المختلط ، ICLR ، 2018 [ورق]
نماذج التحجيم
- الليمون: توسيع نموذج خسارة ، ICLR ، 2024 [ورق]
- إعداد دروس للتدريب التدريجي على نماذج اللغة ، AAAI ، 2024 [ورق]
- تعلم نمو نماذج مسبقة لتدريب المحولات الفعالة ، ICLR ، 2023 [ورقة] [رمز]
- 2x نموذج اللغة الأسرع قبل التدريب عن طريق النمو الهيكلي المقنع ، Arxiv ، 2023 [ورق]
- إعادة استخدام النماذج المسبقة من قبل المشغلين متعدد الخطوط للتدريب الفعال ، Neupips ، 2023 [ورق]
- FLM-101B: LLM مفتوح وكيفية تدريبه بميزانية 100 دولار كلفن ، Arxiv ، 2023 [ورقة] [رمز]
- وراثة المعرفة لنماذج اللغة التي تم تدريبها مسبقًا ، NAACL ، 2022 [ورقة] [رمز]
- تدريب على مرور لنماذج لغة المحولات ، ICML ، 2022 [ورقة] [رمز]
تقنيات التهيئة
- DeepNet: تحجيم المحولات إلى 1000 طبقة ، Arxiv ، 2022 [ورقة] [رمز]
- التهيئة صفر: تهيئة الشبكات العصبية مع الأصفار فقط والأفراد ، TMLR ، 2022 [ورقة] [رمز]
- Rezero هو كل ما تحتاجه: التقارب السريع بعمق كبير ، Uai ، 2021 [ورقة] [رمز]
- تحيزات تطبيع الدُفعات الكتل المتبقية نحو وظيفة الهوية في الشبكات العميقة ، Neupips ، 2020 [ورق]
- تحسين تحسين المحولات من خلال تهيئة أفضل ، ICML ، 2020 [ورقة] [رمز]
- تهيئة الإصلاح: التعلم المتبقي بدون تطبيع ، ICLR ، 2019 [ورق]
- على تهيئة الوزن في الشبكات العصبية العميقة ، Arxiv ، 2017 [ورق]
محسن التدريب
- نحو التعلم الأمثل لنماذج اللغة ، Arxiv ، 2024 [ورقة] [رمز]
- اكتشاف رمزي لخوارزميات التحسين ، Arxiv ، 2023 [ورق]
- صوفيا: مُحسّن من الدرجة الثانية القابلة للتطوير لنموذج اللغة المسبق ، Arxiv ، 2023 [ورقة] [رمز]
صقل فعال
صقل دقيق معلمة
ضبط القائم على المحول
- Opendelta: مكتبة التوصيل والتشغيل للتكيف مع المعلمة الموفرة للنماذج التي تم تدريبها مسبقًا ، ACL Demo ، 2023 [ورقة] [رمز]
- LLM-ADAPTERS: عائلة محول لضرب النماذج اللغوية الكبيرة الموفرة للمعلمة ، EMNLP ، 2023 [ورقة] [رمز]
- Compacter: طبقات محول Hypercomplex الفعالة منخفضة الرتبة ، Neupips ، 2023 [ورقة] [رمز]
- إن الضبط الدقيق للمعلمة بضع طلقة أفضل وأرخص من التعلم داخل السياق ، Neupips ، 2022 [ورقة] [رمز]
- المعادن الفوقية: المعلمة فعالة قليلة من الضبط من خلال التعلم التلوي ، السيارات ، 2022 [ورق]
- Adamix: مزيج من المعدلات لضبط النماذج الموفرة للمعلمة ، EMNLP ، 2022 [ورقة] [رمز]
- SparseadApter: نهج سهل لتحسين كفاءة المعلمة للمحولات ، EMNLP ، 2022 [ورقة] [رمز]
التكيف منخفض الرتبة
- Hydralora: بنية Lora غير المتماثلة من أجل الضبط الفعال ، Neupips ، 2024 [ورق]
- Lofit: صقل دقيق على تمثيل LLM ، Arxiv ، 2024 [ورق]
- مزيج من المساحات في التكيف منخفضة الرتبة ، Arxiv ، 2024 [ورقة] [رمز]
- MEFT: صقل دقيق للذاكرة من خلال محول متفرغ ، ACL ، 2024 [ورق]
- تلتقي لورا بالتسرب تحت إطار موحد ، Arxiv ، 2024 [ورق]
- النجمة: القيد Lora مع التعلم النشط الديناميكي لضرب نماذج اللغة الكبيرة الموفرة للبيانات ، Arxiv ، 2024 [ورق]
- Lora+: تكييف رتبة منخفضة للنماذج الكبيرة ، Arxiv ، 2024 [ورق]
- Lora-FA: التكيف المنخفض الرتبة في الذاكرة لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورق]
- Lorahub: تعميم فعال في المهام عبر تكوين Lora الديناميكي ، Arxiv ، 2023 [ورقة] [رمز]
- Longlora: صقل فعال من النماذج اللغوية الكبيرة ذات السياق الطويلة ، Arxiv ، 2023 [ورقة] [رمز]
- توجيه محول متعدد الرأس لتعميم المهام المتقاطعة ، Neupips ، 2023 [ورقة] [رمز]
- تخصيص الميزانية التكيفية للضغط الدقيق للمعلمة ، ICLR ، 2023 [ورق]
- ديلورا: ضبط معلمة فعال للنماذج المسبقة باستخدام التكيف الديناميكي الخالي من البحث المنخفض ، EACL ، 2023 [ورقة] [رمز]
- Lora-Lora: تعزيز كفاءة المعلمة من Lora مع ربط الوزن ، Arxiv ، 2023 [ورق]
- لورا: التكيف منخفض الرتبة لنماذج اللغة الكبيرة ، ICLR ، 2022 [ورقة] [رمز]
بادئة ضبط
- Llama-Adapter: صقل فعال لنماذج اللغة مع اهتمام صفر ، Arxiv ، 2023 [ورقة] [رمز]
- صرف البادئة: تحسين المطالبات المستمرة للجيل ACL ، 2021 [ورقة] [رمز]
ضبط موجه
- ضغط ، ثم المطالبة: تحسين مقايضة دقة كفاءة لاستدلال LLM مع موجه قابل للتحويل ، Arxiv ، 2023 [ورق]
- GPT يفهم ، أيضا ، AI Open ، 2023 [ورقة] [رمز]
- متعددة المهام قبل التدريب لمطالبة معيارية لتعلم القليل ACL ، 2023 [ورقة] [رمز]
- يتيح ضبط المطالبة متعددة المهام التعلم بنقل المعلمة ، ICLR ، 2023 [ورق]
- PPT: ضبط موجه مسبقًا للتعلم قليلاً ، ACL ، 2022 [ورقة] [رمز]
- يجعل الضبط السريع الموفرة للمعلمة مسترجعًا من النصوص العصبية المعممة والمعايرة ، emnlp-findings ، 2022 [ورقة] [رمز]
- p-tuning v2: يمكن أن يكون ضبط موجه مماثل للتكوين على مستوى عالمي عبر المقاييس والمهام , ACL-Short ، 2022 [ورقة] [رمز]
- قوة المقياس لضبط موجه فعال المعلمة ، EMNLP ، 2021 [ورق]
ضبط ذاكرة فعال
- دراسة عن التحسينات لنماذج اللغة الكبيرة الدقيقة ، Arxiv ، 2024/INS> [ورقة]
- مصفوفة متناثرة في نموذج اللغة الكبيرة ، Arxiv ، 2024/INS> [ورقة]
- Galore: تدريب LLM الموفرة للذاكرة عن طريق الإسقاط المتدرج منخفض الرتبة ، Arxiv ، 2024/INS> [ورقة]
- REFT: تمثيل Finetuning لنماذج اللغة ، Arxiv ، 2024/INS> [ورقة]
- ليزا: أخذ العينات ذات أهمية طبقة لنموذج اللغة الكبيرة الموفرة للذاكرة ، Arxiv ، 2024/INS> [ورقة]
- Bitdelta: قد لا يستحق صقلك جيدًا سوى واحد ، Arxiv ، 2024/INS> [ورقة]
- أخذ عينات من صف الأعمدة الفائز بالتكيف مع النموذج اللغوي الفعال للذاكرة ، Neupips ، 2023 [ورقة] [رمز]
- صقل انتقائي فعال الذاكرة ، ورشة ICML ، 2023 [ورق]
- صقل المعلمات الكاملة لنماذج اللغة الكبيرة ذات الموارد المحدودة ، Arxiv ، 2023 [ورقة] [رمز]
- نماذج لغة صقل مع تمريرات إلى الأمام فقط ، Neupips ، 2023 [ورقة] [رمز]
- صقل دقيق للذاكرة لنماذج لغة كبيرة مضغوطة عبر كمية عدد صحيح من 4 بت ، Neupips ، 2023 [ورق]
- Loftq: كميات لوراء-فاين على دراية بنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- QA-Lora: التكيف المنخفض للتكيف مع نماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- qlora: فنية فعالة من LLMs الكمية ، Neupips ، 2023 [ورقة] [CODE1] [CODE2]
وصقل موفرة للوزارة
- دع الخبير يلتزم بآخره: صقل خبير خاص لنماذج اللغة المعمارية الكبيرة المتفجرة ، Arxiv ، 2024 [ورق]
الاستدلال الفعال
فك تشفير الموازي
- CLLMS: نماذج لغة كبيرة ، تناسق ، Arxiv ، 2024 [ورق]
- قم بالتشفير مرة واحدة وفك تشفيرها بالتوازي: فك تشفير المحولات الفعالة ، Arxiv ، 2024 [ورق]
فك تشفير المضاربة
- MagicDec: كسر مفاضلة الكمون الإنتاجية لتوليد السياق الطويل مع فك تشفير المضاربة ، Arxiv ، 2024 [ورق]
- ماهر: فك تشفير مع رفقات الأشجار الفلاش لاستنتاج LLM منظمة للشجرة ، Arxiv ، 2024 [ورق]
- layerskip: تمكين الاستدلال المبكر للخروج وفك التشفير الذاتي ، Arxiv ، 2024 [ورق]
- Triforce: تسريع خسارة لتوليد التسلسل الطويل مع فك تشفير المضاربة الهرمية ، Arxiv ، 2024 [ورق]
- REST: فك تشفير المضاربة القائم على الاسترجاع ، Arxiv ، 2024 [ورق]
- محولات ترادفية لاستنتاج LLMs الفعالة ، Arxiv ، 2024 [ورق]
- تمرير: أخذ عينات مضاربة متوازية ، ورشة عمل Neups ، 2023 [ورق]
- تسريع استدلال المحول للترجمة عبر فك التشفير المتوازي ، ACL ، 2023 [ورقة] [رمز]
- ميدوسا: إطار عمل بسيط لتسريع توليد LLM برؤوس فك التشفير المتعددة ، مدونة ، 2023 [المدونة] [رمز]
- الاستدلال السريع من المحولات عبر فك تشفير المضاربة ، ICML ، 2023 [ورق]
- تسريع استنتاج LLM مع فك تشفير المضاربة ، ورشة ICML ، 2023 [ورق]
- تسريع فك تشفير نموذج اللغة الكبيرة مع أخذ العينات المضاربة ، Arxiv ، 2023 [ورق]
- فك تشفير المضاربة مع فك التشفير الصغير الكبير ، Neupips ، 2023 [ورقة] [رمز]
- SPECINFER: تسريع LLM التوليدي مع الاستدلال المضاربة والتحقق من شجرة الرمز المميز ، Arxiv ، 2023 [ورقة] [رمز]
- الاستدلال مع المرجع: التسارع بدون فقدان نماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- البذور: تسريع بناء شجرة التفكير من خلال فك تشفير المضاربة المجدولة ، Arxiv ، 2024 [ورق]
KV-Cache Optimization
- VL-Cache: sparsity و kv cache ضغط ذاكرة التخزين المؤقت لتسريع استدلال النموذج اللغوي ، Arxiv ، 2024 [ورق]
- Minference 1.0: تسريع ملء مسبقًا لـ LLMs Lontext LLMS عبر الاهتمام الديناميكي المتناثر ، Arxiv ، 2024 [ورق]
- kvsharer: الاستدلال الفعال عبر مشاركة ذاكرة التخزين المؤقت KV متباينة في الطبقة ، Arxiv ، 2024 [ورق]
- الثنائيات: استنتاج فعال LLM في السياق الطويل مع رؤوس الاسترجاع والبث ، Arxiv ، 2024 [ورق]
- Lazyllm: تقليم رمزي ديناميكي لاستنتاج LLM طويل الكفاءة ، Arxiv ، 2024 [ورق]
- Palu: ضغط كيلو فايم مع الإسقاط منخفض الرتبة ، Arxiv ، 2024 [ورقة] [رمز]
- Look-M: التحسين المظهر في ذاكرة التخزين المؤقت KV لاستنتاج سياق طويل الوسائط فعال ، Arxiv ، 2024 [ورق]
- D2O: العمليات التمييزية الديناميكية للاستدلال التوليدي الفعال لنماذج اللغة الكبيرة ، Arxiv ، 2024 [ورق]
- البحث: SPARSITY مدرك للاستعلام لاستدلال LLM الفعال LLM ، ICML ، 2024 [ورق]
- تقليل حجم ذاكرة التخزين المؤقت ذات قيمة المفتاح المحول مع انتباه الطبقة المتقاطعة ، Arxiv ، 2024 [ورق]
- Snapkv: LLM تعرف ما تبحث عنه قبل الجيل ، Arxiv ، 2024 [ورق]
- نماذج اللغة الكبيرة القائمة على المرساة ، Arxiv ، 2024 [ورق]
- Kvquant: نحو 10 ملايين سياق طول السياق LLM مع كمية ذاكرة التخزين المؤقت KV ، Arxiv ، 2024 [ورق]
- الترس: وصفة فعالة لضغط ذاكرة التخزين المؤقت KV للاستدلال التوليدي القريب من LLM ، Arxiv ، 2024 [ورق]
- ضغط الذاكرة الديناميكي: التعديل التحديثي LLMs للاستدلال المتسارع ، Arxiv ، 2024 [ورق]
- لا يوجد رمز مميز خلفه: ضغط ذاكرة التخزين المؤقت KV موثوق به من خلال تقدير الدقة المختلطة ذات الأهمية ، Arxiv ، 2024 [ورق]
- احصل على المزيد مع أقل: توليف تكرار مع ضغط ذاكرة التخزين المؤقت KV من أجل استنتاج LLM الفعال ، Arxiv ، 2024 [ورق]
- WKVQUANT: كمية الوزن وذاكرة التخزين المؤقت للمفتاح/القيمة لنماذج اللغة الكبيرة تكتسب أكثر ، Arxiv ، 2024 [ورق]
- حول فعالية سياسة الإخلاء لاستدلال نموذج اللغة التوليدي المقيد ، Arxiv ، 2024 [ورق]
- Kivi: كمية 2bit غير متماثلة خالية من التوليف لـ KV ذاكرة التخزين المؤقت ، Arxiv ، 2024 [ورقة] [رمز]
- يخبرك النموذج بما يجب تجاهله: ضغط ذاكرة التخزين المؤقت KV التكيفي لـ LLMS ، ICLR ، 2024 [ورق]
- SkipDecode: فك تشفير التخطي التلقائي مع التثبيت والتخزين المؤقت لاستنتاج LLM الفعال ، Arxiv ، 2023 [ورق]
- H2O: Oracle الثقيلة للاستنتاج التوليدي الفعال لنماذج اللغة الكبيرة ، Neupips ، 2023 [ورق]
- مقصات: استغلال استمرار فرضية الأهمية لضغط ذاكرة التخزين المؤقت LLM KV في وقت الاختبار ، Neupips ، 2023 [ورق]
- السياق الديناميكي التقليم لمحولات الانحدار التلقائي الفعال والقابل للتفسير ، Arxiv ، 2023 [ورق]
الهندسة المعمارية الفعالة
اهتمام فعال
الانتباه القائم على المشاركة
- لوما: انتباه الذاكرة المضغوط بدون فقدان ، Arxiv ، 2024 [ورق]
- Mobilellm: تحسين نماذج لغة المعلمة الفرعية للمليون لحالات استخدام الجهاز ، Arxiv ، 2024 [ورق]
- GQA: تدريب نماذج محولات متعددة المسارات معممة من نقاط التفتيش متعددة الرأس ، EMNLP ، 2023 [ورق]
- فك تشفير المحولات السريعة: رأس كتابة واحد هو كل ما تحتاجه ، Arxiv ، 2019 [ورق]
ميزة تخفيض المعلومات
- Nyströmformer: خوارزمية تستند إلى Nyström لتقريب الاهتمام الذاتي ، AAAI ، 2021 [ورقة] [رمز]
- تحويل التحويل: تصفية التكرار المتسلسل لمعالجة اللغة الفعالة ، Neupips ، 2020 [ورقة] [رمز]
- Set Transformer: إطار للشبكات العصبية المستندة إلى الاهتمام ، ICML ، 2019 [ورق]
kernelization أو منخفضة الرتبة
- Loki: مفاتيح منخفضة الرتبة للاهتمام المتفرق الفعال ، ورشة ICML ، 2023 [ورق]
- Sumformer: التقريب العالمي للمحولات الفعالة ، ورشة ICML ، 2023 [ورق]
- Flurka: انتباه سريع تنصهر منخفضة الرتبة والنواة ، Arxiv ، 2023 [ورق]
- Scatterbrain: توحيد الاهتمام المتناثر والمنخفض ، Neurolps ، 2021 [ورقة] [رمز]
- إعادة التفكير في الاهتمام مع الفنانين ، ICLR ، 2021 [ورقة] [رمز]
- اهتمام عشوائي ميزة ، ICLR ، 2021 [ورق]
- Linformer: الاهتمام الذاتي مع التعقيد الخطي ، Arxiv ، 2020 [ورقة] [رمز]
- التعرف على الكلام خفيفة الوزن وفعالة من طرف إلى طرف باستخدام محول منخفض الرتب ، ICASSP ، 2020 [ورق]
- المحولات هي RNNs: محولات سريعة الانحدار مع الاهتمام الخطي ، ICML ، 2020 [ورقة] [رمز]
استراتيجيات نمط ثابت
- توازن نماذج لغة الاهتمام الخطي البسيط مع مفاضلة الاستدعاء ، Arxiv ، 2024 [ورق]
- Lightning Lunting-2: غداء مجاني للتعامل مع أطوال تسلسل غير محدودة في نماذج اللغة الكبيرة ، Arxiv ، 2024 [ورقة] [رمز]
- انتباه سببي أسرع على تسلسل كبير من خلال انتباه فلاش متناثر ، ورشة ICML ، 2023 [ورق]
- Prowingformer: نمذجة مستند طويلة مع تجميع الانتباه ، ICML ، 2021 [ورق]
- Big Bird: Transformers لتسلسلات أطول ، Neupips ، 2020 [ورقة] [رمز]
- Longformer: محول الحوليات الطويلة ، Arxiv ، 2020 [ورقة] [رمز]
- الحظر الذاتي لفهم الوثائق الطويل ، EMNLP ، 2020 [ورقة] [رمز]
- توليد تسلسلات طويلة مع المحولات المتفرقة ، Arxiv ، 2019 [ورق]
استراتيجيات نمط قابلة للتعلم
- وزارة الزراعة: مزيج من الاهتمام المتفريقة لضغط نموذج اللغة الكبير التلقائي ، Arxiv ، 2024 [ورق]
- Hyperattention: اهتمام طويل السياق في الوقت القريب الخطية ، Arxiv ، 2023 [ورقة] [رمز]
- clusterformer: انتباه التجميع العصبي لمحول فعال وفعال ، ACL ، 2022 [ورق]
- المصلح: المحول الفعال ، ICLR ، 2022 [ورقة] [رمز]
- انتباه Sinkhorn المتناثر ، ICML ، 2020 [ورق]
- محولات سريعة مع الاهتمام المجمع ، Neupips ، 2020 [ورقة] [رمز]
- الاهتمام المتناثر الفعال القائم على المحتوى مع محولات التوجيه ، TACL ، 2020 [ورقة] [رمز]
مزيج من الخبراء
LLMS المستندة إلى MOE
- الذاتي: نحو نماذج لغة كبيرة مع خبراء تخصصوا ذاتيا ، Arxiv ، 2024 [ورق]
- Lory: مزيج من الخبراء القابل للتمييز تمامًا لنموذج اللغة التلقائية قبل التدريب ، 2024 [ورقة]
- Jetmoe: الوصول إلى أداء Llama2 مع 0.1 مليون دولار ، 2024 [ورقة]
- الخبير يستحق رمزًا واحدًا: تآزر LLMs متعددة الخبراء كخبير عام عبر توجيه رمز الخبراء ، 2024 [ورقة]
- مزيج من العمق: تخصيص الحساب ديناميكيا في نماذج اللغة القائمة على المحولات ، 2024 [ورقة]
- MIX الفرع: خلط LLMs الخبراء في مزيج من الخبراء LLM ، 2024 [ورقة]
- مختلط من الخبراء ، Arxiv ، 2024 [ورقة] [رمز]
- MISTRAL 7B ، Arxiv ، 2023 [ورقة] [رمز]
- Pangu-σ: نحو نموذج لغة تريليون معلمة مع حوسبة غير متجانسة متفرقة ، Arxiv ، 2023 [ورق]
- محولات التبديل: التحجيم إلى نماذج المعلمات تريليون مع تباين بسيط وفعال ، JMLR ، 2022 [ورقة] [رمز]
- نمذجة لغوية واسعة النطاق فعالة مع مزيج من الخبراء ، EMNLP ، 2022 [ورقة] [رمز]
- الطبقات الأساسية: تبسيط التدريب على نماذج كبيرة متناثرة ، ICML ، 2021 [ورقة] [رمز]
- GSHARD: تحجيم النماذج العملاقة مع الحساب الشرطي والتشويش التلقائي ، ICLR ، 2021 [ورق]
تحسين مستوى الخوارزمية
- SEER-MOE: كفاءة الخبراء المتفرقة من خلال التنظيم لخليط الخبراء ، Arxiv ، 2024/INS> [ورقة]
- قوانين تحجيم مزيج من الخبراء الدقيق ، Arxiv ، 2024/INS> [ورقة]
- اللغة المستمرة مدى الحياة مع الخبراء المتخصصين في التوزيع ، ICML ، 2023 [ورق]
- يفي بخطوط الخبرة بضبط التعليمات: مزيج رابح لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورق]
- مزيج من الخبراء مع توجيه اختيار الخبراء ، Neupips ، 2022 [ورق]
- Stablemoe: استراتيجية توجيه مستقرة لمزيج من الخبراء ، ACL ، 2022 [ورقة] [رمز]
- على تمثيل انهيار المزيج المتفرق من الخبراء ، Neupips ، 2022 [ورق]
سياق طويل LLMS
الاستقراء والاستيفاء
- ضربت الحجارة طير واحد: ترميز الموضعي في بليل لاستقراء أفضل ، ICML ، 2024 [ورق]
- ∞ مقاعد: تمديد تقييم السياق الطويل بما يتجاوز 100 ألف رمز ، Arxiv ، 2024 [ورق]
- حبل الرنين: تحسين تعميم طول السياق لنماذج اللغة الكبيرة ، Arxiv ، 2024 [ورقة] [رمز]
- Longrope: تمديد نافذة سياق LLM تتجاوز 2 مليون رمز ، Arxiv ، 2024 [ورق]
- e^2-llm: امتداد ذو طول فعال ومتطرف لنماذج اللغة الكبيرة ، Arxiv ، 2024 [ورق]
- قوانين تحجيم الاستقراء القائم على الحبل ، Arxiv ، 2023 [ورق]
- محول الطول الطول ، ACL ، 2023 [ورقة] [رمز]
- تمديد نافذة السياق لنماذج اللغة الكبيرة عبر الاستيفاء الموضعي ، Arxiv ، 2023 [ورق]
- استيفاء NTK ، مدونة ، 2023 [رديت بوست]
- الغزل: امتداد نافذة سياق فعال لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- Clex: الاستقراء المستمر للطول لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- وضع: امتداد نافذة سياق فعال لـ LLMS عبر التدريب الموضعي ، Arxiv ، 2023 [ورقة] [رمز]
- الاستيفاء الوظيفي للمواقف النسبية يحسن محولات السياق الطويلة ، Arxiv ، 2023 [ورق]
- تدريب قصير ، اختبار طويل: الانتباه مع التحيزات الخطية يتيح استقراء طول الإدخال ، ICLR ، 2022 [ورقة] [رمز]
- استكشاف تعميم الطول في نماذج اللغة الكبيرة ، Neupips ، 2022 [ورق]
بنية متكررة
- الشبكة الاحتفالية: خليفة للمحول لنماذج اللغة الكبيرة ، Arxiv ، 2023 [ورقة] [رمز]
- محول الذاكرة المتكرر ، Neupips ، 2022 [ورقة] [رمز]
- محولات تكرار الكتلة ، Neupips ، 2022 [ورقة] [رمز]
- ∞-former: محول الذاكرة اللانهائي ، ACL ، 2022 [ورقة] [رمز]
- MEMFORMER: محول تم تجهيز الذاكرة لنمذجة التسلسل ، AACL-Findings ، 2020 [ورقة] [رمز]
- Transformer-XL: نماذج لغة منتبهة تتجاوز سياق الطول الثابت ، ACL ، 2019 [ورقة] [رمز]
تجزئة ونافذة منزلق
- XL3M: إطار عمل خالي من التدريب لتمديد طول LLM استنادًا إلى الاستدلال الحكيمة ، Arxiv ، 2024 [ورق]
- Transformerfam: اهتمام ردود الفعل هو الذاكرة العاملة ، Arxiv ، 2024 [ورق]
- امتداد السياق الساذج القائم على بايز لنماذج اللغة الكبيرة ، NAACL ، 2024 [ورق]
- لا تترك أي سياق وراء: محولات سياق غير محدودة فعالة مع الالتحاق اللانهائي ، Arxiv ، 2024 [ورق]
- تدريب LLMs على النص المضغوط العصبي ، Arxiv ، 2024 [ورق]
- LM-Infinite: تعميم الطول المتطرف الصفري لنماذج اللغة الكبيرة ، Arxiv ، 2024 [ورق]
- تحجيم السياق الطويل الخالي من التدريب لنماذج اللغة الكبيرة ، Arxiv ، 2024 [ورقة] [رمز]
- نمذجة لغة السياق الطويلة مع ترميز السياق المتوازي ، Arxiv ، 2024 [ورقة] [رمز]
- ارتفاع من 4K إلى 400K: توسيع سياق LLM مع منارة التنشيط ، Arxiv ، 2024 [ورقة] [رمز]
- LLM ربما LongLM: نافذة سياق LLM Self Self دون ضبط ، Arxiv ، 2024 [ورقة] [رمز]
- تمديد نافذة السياق لنماذج اللغة الكبيرة عن طريق الضغط الدلالي ، Arxiv ، 2023 [ورق]
- نماذج لغة البث الفعالة مع مغسلة الانتباه ، Arxiv ، 2023 [ورقة] [رمز]
- نوافذ السياق الموازية لنماذج اللغة الكبيرة ، ACL ، 2023 [ورقة] [رمز]
- Longnet: تحجيم المحولات إلى 1،000،000،000 رمز ، Arxiv ، 2023 [ورقة] [رمز]
- فهم فعال للنص طويل مع نماذج النص القصير ، TACL ، 2023 [ورقة] [رمز]
تكبير الذاكرة البارز
- Infllm: كشف النقاب عن القدرة الجوهرية لـ LLMs لفهم تسلسلات طويلة للغاية مع ذاكرة خالية من التدريب ، Arxiv ، 2024 [ورق]
- Landmark Attention: Random-Access Infinite Context Length for Transformers, arXiv, 2023 [Paper] [Code]
- Augmenting Language Models with Long-Term Memory, NeurIPS, 2023 [ورق]
- Unlimiformer: Long-Range Transformers with Unlimited Length Input, NeurIPS, 2023 [Paper] [Code]
- Focused Transformer: Contrastive Training for Context Scaling, NeurIPS, 2023 [Paper] [Code]
- Retrieval meets Long Context Large Language Models, arXiv, 2023 [ورق]
- Memorizing Transformers, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
State Space Models
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [ورق]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [ورق]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [ورق]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [ورق]
- Block-State Transformers, NeurIPS, 2023 [ورق]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces, NeurIPS, 2022 [Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [ورق]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [ورق]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [ورق]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [ورق]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [ورق]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [ورق]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [ورق]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [ورق]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [ورق]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [ورق]
؟ Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [ورق]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [ورق]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [ورق]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [ورق]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [ورق]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [ورق]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [ورق]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [ورق]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [ورق]
Prompt Engineering
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [ورق]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [ورق]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [ورق]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [ورق]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [ورق]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [ورق]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [ورق]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [ورق]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [ورق]
- Learning to Reason with LLMs, Website, 2024 [Html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [ورق]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [ورق]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [ورق]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [ورق]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [ورق]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS, 2022 [ورق]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [ورق]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [ورق]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [ورق]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [ورق]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [ورق]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [ورق]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [ورق]
Prompt Generation
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [ورق]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [ورق]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [ورق]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 ، [ورق]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [ورق]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [ورق]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [ورق]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [ورق]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [ورق]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [ورق]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [ورق]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [ورق]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [ورق]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [ورق]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [ورق]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [ورق]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [ورق]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [ورق]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [ورق]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [ورق]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [ورق]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [ورق]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [ورق]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [ورق]
- Fairness in Serving Large Language Models, arXiv, 2023 [ورق]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [ورق]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS, 2022 [Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [مدونة]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [ورق]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [ورق]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [ورق]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [ورق]
LLM Frameworks
| Efficient Training | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | ✅ | ✅ | ✅ |
| Megatron [Code] | ✅ | ✅ | ✅ |
| ColossalAI [Code] | ✅ | ✅ | ✅ |
| Nanotron [Code] | ✅ | ✅ | ✅ |
| MegaBlocks [Code] | ✅ | ✅ | ✅ |
| FairScale [Code] | ✅ | ✅ | ✅ |
| Pax [Code] | ✅ | ✅ | ✅ |
| Composer [Code] | ✅ | ✅ | ✅ |
| OpenLLM [Code] | | ✅ | ✅ |
| LLM-Foundry [Code] | | ✅ | ✅ |
| vLLM [Code] | | ✅ | |
| TensorRT-LLM [Code] | | ✅ | |
| TGI [Code] | | ✅ | |
| RayLLM [Code] | | ✅ | |
| MLC LLM [Code] | | ✅ | |
| Sax [Code] | | ✅ | |
| Mosec [Code] | | ✅ | |


