有效的大语言模型:调查
高效的大语言模型:调查[ARXIV](版本1:12/06/2023;版本2:12/23/2023;版本3:01/31/2024;版本4:05/23/2024,机器学习研究上的摄像机准备版本
Zhongwei Wan 1 ,Xin Wang 1 ,Che Liu 2 ,Samiul Alam 1 ,Yu Zheng 3 ,Jichen Liu 4 ,Zhongnan Qu 5 ,Shen Yan 6 ,Shen Yan 6,Yi Zhu 7 ,Quanlu Zhang 8 ,Mosharaf Chowdhury 4 ,Mi Zhang 1,Mi Zhang 1,Mi Zhang 1
1俄亥俄州立大学,伦敦帝国学院2号,密歇根州立大学3号,密歇根大学4号,亚马逊AWS AI, 6 Google Research, 7 Boson AI, 8 Microsoft Research Asia
News:我们的调查已被机器学习研究(TMLR)的交易正式接受,2024年5月。相机Ready版本可用:[OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
❤️社区支持
该存储库维护Tuidan ([email protected]),维持桥([email protected]), Samiul272 ([email protected])和Mi-Zhang ([email protected])。我们欢迎反馈,建议和贡献,可以帮助改善这一调查和存储库,从而使它们成为有益的资源以使整个社区受益。
我们将通过纳入新的研究来积极维护该存储库。如果您对我们的分类学有任何建议,请找到任何缺失的论文,或更新已接受给某个场所的任何预印纸纸,请随时向我们发送电子邮件或使用以下Markdown格式提交拉动请求。
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
?这项调查是什么?
大型语言模型(LLMS)在许多重要任务中表现出了显着的能力,并有可能对我们的社会产生重大影响。但是,这种功能具有相当大的资源需求,强烈强烈需要开发有效的技术来解决LLMS带来的效率挑战。在这项调查中,我们对有效的LLMS研究进行了系统的全面综述。我们以三个主要类别组成的分类学组织文献,分别涵盖了以模型为中心,以数据为中心和框架的观点,分别涵盖了独特但相互联系的有效LLMS主题。我们希望我们的调查和该GITHUB存储库可以作为宝贵的资源,以帮助研究人员和从业者对有效LLM的研究发展有系统的了解,并激发他们为这个重要而令人兴奋的领域做出贡献。
?为什么需要有效的LLM?
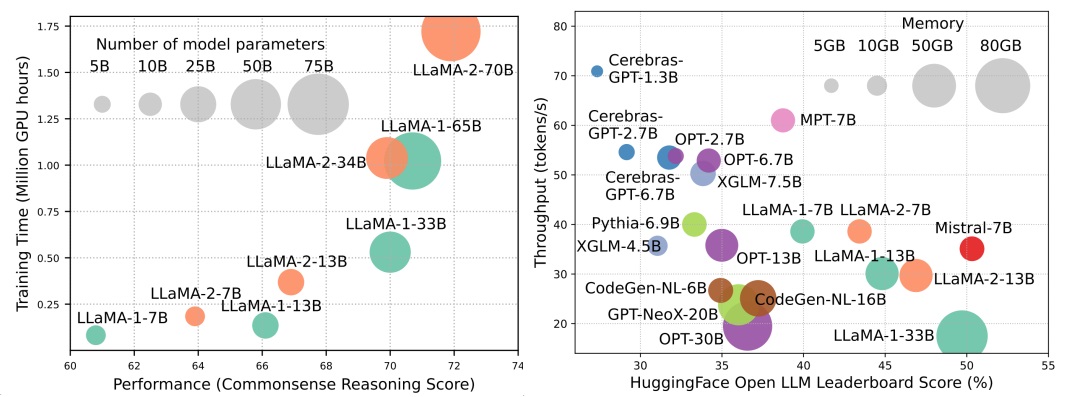
尽管LLM正在领导下一波AI革命,但LLM的显着能力是以其大量资源需求为代价。图1(左)说明了模型性能与模型训练时间之间的关系,即Llama系列的GPU小时,其中每个圆的大小与模型参数的数量成正比。如图所示,尽管较大的模型能够实现更好的性能,但是随着模型尺寸扩大规模,用于训练它们的GPU小时数量成倍增长。除了培训外,推论还对LLM的运营成本做出了很大贡献。图2(右)描绘了模型性能与推理吞吐量之间的关系。同样,扩大模型大小可以实现更好的性能,但以较低的推理吞吐量(推理潜伏期)为代价,对这些模型的挑战提出了将其覆盖范围扩展到更广泛的客户群和以具有成本效益的方式进行的挑战。 LLMS的高资源需求强调了开发技术以提高LLM效率的强大需求。如图2所示,与Llama-1-33b相比,Mismtral-7b(使用分组的疑问和滑动窗口注意来加快推断,实现可比的性能和更高的吞吐量。这种优势强调了LLMS设计效率技术的可行性和意义。
内容表
- ?以模型为中心的方法
- 模型压缩
- 有效的预训练
- 有效的微调
- 有效的推断
- 有效的体系结构
- 有效的关注
- 共享的注意力
- 功能信息减少
- 内核或低级别
- 固定模式策略
- 可学习的模式策略
- 专家的混合物
- 长上下文LLM
- 变压器替代体系结构
- ?以数据为中心的方法
- ?系统级效率优化和LLM框架
- 系统级效率优化
- 系统级训练效率优化
- 系统级服务效率优化
- 算法 - 硬件共同设计
- LLM框架
?以模型为中心的方法
模型压缩
量化
训练后量化
仅重量量化
- i-llm:对完全量化的低位大语言模型的有效整数推断, Arxiv,2024年[纸]
- IntactKV:通过保持枢轴代币完整来改善大型语言模型量化, Arxiv,2024年[纸]
- 无所不在:全语:大语模型的全向校准量化, ICLR,2024 [纸] [代码]
- Onebit:朝着极低的大型语言模型, Arxiv,2024年[纸]
- GPTQ:生成预训练的变压器的准确量化, ICLR,2023年[纸] [代码]
- 讽刺:具有保证的大型语言模型的2位量化, Arxiv,2023年[纸] [代码]
- AWQ:LLM压缩和加速度的激活意识重量量化, Arxiv,2023年[纸] [代码]
- OWQ:从激活异常值中学到的经验教训,用于大语言模型中的权重量化, Arxiv,2023年[纸] [代码]
- SPQR:稀疏定量的表示,用于近乎无效的LLM重量压缩, Arxiv,2023年[纸] [代码]
- 细性:通过使用细颗粒的量量化LLMS的效率,解锁效率, Neurips-enlsp,2023年[纸]
- llm.int8():变形金刚的8位矩阵乘法规模, Neurlps,2022 [纸] [代码]
- 最佳大脑压缩:精确训练后量化和修剪的框架,神经,2022年[纸] [代码]
- 量化:基于优化的语言模型量化, Arxiv,2023年[纸] [代码]
权重激活共量化
- 旋转和排列的高级异常管理和LLM有效量化的旋转和置换,神经,2024年[纸]
- 无所不在:全语:大语模型的全向校准量化, ICLR,2024 [纸] [代码]
- 量化量化的有趣特性,神经,2023年[纸]
- 零V2:探索LLM中从综合研究到低等级补偿的LLM中训练后量化, Arxiv,2023年[纸] [代码]
- 零fp:使用浮点格式,LLMS训练后W4A8量化的LLMS的飞跃, Neurips-enlsp,2023年[纸] [代码]
- Olive:通过硬件友好的离群值对量化加速大型语言模型, ISCA,2023年[纸] [代码]
- RPTQ:大型语言模型的基于重新排序的培训量化, Arxiv,2023年[纸] [代码]
- 异常抑制+:通过等效和最佳缩小和缩放对大语言模型进行准确量化, Arxiv,2023年[纸] [代码]
- QLLM:大语言模型的准确有效的低含宽量化, Arxiv,2023年[纸]
- 平滑:大语言模型的准确有效的训练后量化, ICML,2023 [纸] [代码]
- 零:大规模变压器的有效且负担得起的训练后量化,神经,2022年[纸]
评估训练后量化
- 评估量化的大语言模型, Arxiv,2024年[纸]
量化感知培训
- 1位LLMS的时代:所有大型语言模型均以1.58位, Arxiv,2024年[纸]
- FP8-LM:培训FP8大语言模型, Arxiv,2023年[纸]
- 使用8位浮点培训和推断大型语言模型, Arxiv,2023年[纸]
- 比特网:为大语言模型缩放1位变压器, Arxiv,2023年[纸]
- LLM-QAT:大语言模型的无数据量化培训, Arxiv,2023年[纸] [代码]
- 通过量化压缩生成培训的语言模型, ACL,2022年[纸]
参数修剪
结构化修剪
- 通过修剪和知识蒸馏,紧凑的语言模型, Arxiv,2024年[纸]
- 更深入地看一下LLM的深度修剪, Arxiv,2024年[纸]
- 困惑的困惑:基于困惑的数据修剪,小参考模型, Arxiv,2024年[纸]
- 插件:一种有效的大语言模型的训练后修剪方法, ICLR,2024 [纸]
- BESA:用块参数有效的稀疏分配修剪大型语言模型, Arxiv,2024年[纸]
- 短时:大语言模型中的层数比您预期的要多余, Arxiv,2024年[纸]
- NutePrune:有效的逐步修剪大型语言模型, Arxiv,2024年[纸]
- slicegpt:通过删除行和列来压缩大语言模型, ICLR,2024 [纸] [代码]
- Lorashear:高效的大语言模型结构修剪和知识恢复, Arxiv,2023年[纸]
- LLM-Pruner:关于大语言模型的结构修剪,神经,2023年[纸] [代码]
- 剪切的美洲驼:通过结构化修剪预训练的加速语言模型, Neurips-enlsp,2023年[纸] [代码]
- Loraprune:修剪符合低级参数效率微调, Arxiv,2023年[纸]
非结构化的修剪
- maskllm:大语言模型的可学习半结构化稀疏性, NIP,2024年[纸]
- 动态稀疏无培训:稀疏LLM的无培训微调, ICLR,2024 [纸]
- 稀疏:大规模的语言模型可以单次精确修剪, ICML,2023 [纸] [代码]
- 大型语言模型的一种简单有效的修剪方法, Arxiv,2023年[纸] [代码]
- 对大语言模型的单发灵敏度感知的混合稀疏性修剪, Arxiv,2023年[纸]
低级别近似
- SVD-LLM:大语言模型压缩的单数值分解, Arxiv,2024年[纸] [代码]
- ASVD:用于压缩大语言模型的激活感知值分解, Arxiv,2023年[纸] [代码]
- 语言模型压缩和加权低级分解, ICLR,2022 [纸]
- 张量:基于张量 - 训练分解,在LLMS中嵌入层的有效压缩, Arxiv,2023年[纸]
- Losparse:基于低级别和稀疏近似的大语言模型的结构化压缩, ICML,2023 [纸] [代码]
知识蒸馏
白盒KD
- DDK:蒸馏域知识的高效大语言模型Arxiv,2024年[纸]
- 重新考虑大语模型知识蒸馏中的kullback-leibler差异Arxiv,2024年[纸]
- Distillm:迈向大型语言模型的简化蒸馏, Arxiv,2024年[纸] [代码]
- 在蒸馏语言模型中达到能力差距的法则, Arxiv,2023年[纸] [代码]
- 婴儿骆驼:从没有表现惩罚的小型数据集中训练的老师合奏的知识蒸馏, Arxiv,2023年[纸]
- 大型语言模型的知识蒸馏, Arxiv,2023年[纸] [代码]
- GKD:自动回归序列模型的广义知识蒸馏, Arxiv,2023年[纸]
- 通过蒸馏传播对LMS的知识更新, Arxiv,2023年[纸] [代码]
- 少更多:语言模型压缩的任务感知层蒸馏, ICML,2023 [纸]
- 三元重量生成语言模型的令牌标准logit蒸馏, Arxiv,2023年[纸]
Black-Box KD
- Zephyr:直接蒸馏LM对齐, Arxiv,2023年[纸]
- 使用GPT-4进行指导调整, Arxiv,2023年[纸] [代码]
- 狮子:封闭源大型语言模型的对抗性蒸馏, Arxiv,2023年[纸] [代码]
- 专门针对多步推理的较小语言模型, ICML,2023 [纸] [代码]
- 逐步蒸馏!超过较小的培训数据和较小的模型大小的较大语言模型, ACL,2023年[纸]
- 大型语言模型是推理教师, ACL,2023年[纸] [代码]
- Scott:自以赴的链条蒸馏, ACL,2023年[纸] [代码]
- 符号链蒸馏:小型模型也可以逐步“思考”, ACL,2023年[纸]
- 将推理功能提炼成较小的语言模型, ACL,2023年[纸] [代码]
- 在内部的学习蒸馏:转移预训练的语言模型的几次学习能力, Arxiv,2022年[纸]
- 大型语言模型的解释使小推理器变得更好, Arxiv,2022年[纸]
- 迪斯科:用大语言模型提炼反事实, Arxiv,2022年[纸] [代码]
参数共享
- Mobillama:朝着准确且轻巧的完全透明的GPT, Arxiv,2024年[纸]
有效的预训练
混合精度训练
- Bfloat16神经网络处理, Arith,2019年[纸]
- Bfloat16的研究用于深度学习培训, Arxiv,2019年[纸]
- 混合精度训练, ICLR,2018年[纸]
缩放模型
- 柠檬:无损模型扩展, ICLR,2024 [纸]
- 准备在语言模型上进行渐进培训的课程, AAAI,2024年[纸]
- 学习成长预贴模型以进行有效的变压器培训, ICLR,2023年[纸] [代码]
- 2倍通过掩盖结构增长预训练的语言模型更快, Arxiv,2023年[纸]
- 多线性操作员重复使用预估计的模型进行有效的培训,神经,2023年[纸]
- FLM-101B:开放LLM以及如何用$ 100 K预算培训它, Arxiv,2023年[纸] [代码]
- 对预训练的语言模型的知识继承, NAACL,2022年[纸] [代码]
- 针对变压器语言模型的培训, ICML,2022 [纸] [代码]
初始化技术
- 深网:将变压器缩放到1,000层, Arxiv,2022年[纸] [代码]
- 零初始化:只有零和一个初始化神经网络, TMLR,2022 [纸] [代码]
- Rezero就是您所需要的:大深度快速收敛, UAI,2021年[纸] [代码]
- 批处理归一化偏向于深网中的身份函数的残留块,神经,2020年[纸]
- 通过更好的初始化来改善变压器优化, ICML,2020年[纸] [代码]
- 修复初始化:剩余学习没有归一化, ICLR,2019年[纸]
- 关于深度神经网络的重量初始化, Arxiv,2017年[纸]
培训优化器
- 旨在最佳学习语言模型, Arxiv,2024年[纸] [代码]
- 优化算法的符号发现, Arxiv,2023年[纸]
- Sophia:用于语言模型预训练的可扩展随机二阶优化器, Arxiv,2023年[纸] [代码]
有效的微调
参数有效的微调
基于适配器的调整
- OPENDELTA:用于预训练模型的参数效率改编的插件库, ACL演示,2023年[纸] [代码]
- LLM-适配器:用于大型语言模型参数有效微调的适配器家族, Emnlp,2023年[纸] [代码]
- 兼容者:有效的低级超复合适配器层,神经,2023年[纸] [代码]
- 几乎没有弹出参数的微调比在文化学习中更好,更便宜,神经,2022年[纸] [代码]
- 元适配器:参数有效地通过元学习进行了几次微调, Automl,2022年[纸]
- Adamix:用于参数有效模型调整的适应性混合物, Emnlp,2022年[纸] [代码]
- Sparseadapter:一种简单的方法,用于提高适配器的参数效率, Emnlp,2022年[纸] [代码]
低级适应
- hydralora:一种不对称的洛拉结构,用于有效微调,神经,2024年[纸]
- LOFIT:LLM表示局部微调, Arxiv,2024年[纸]
- 低级适应中的贝面混合物, Arxiv,2024年[纸] [代码]
- MEFT:通过稀疏适配器进行记忆有效的微调, ACL,2024年[纸]
- 洛拉在统一框架下遇到辍学Arxiv,2024年[纸]
- 星:洛拉(Lora Arxiv,2024年[纸]
- 洛拉+:大型模型的有效低级适应Arxiv,2024年[纸]
- Lora-fa:大型语言模型微调的记忆效率低级适应, Arxiv,2023年[纸]
- Lorahub:通过动态Lora组成有效的跨任务概括, Arxiv,2023年[纸] [代码]
- LONGLORA:长篇文化大型语言模型的有效微调, Arxiv,2023年[纸] [代码]
- 多头适配器路由以进行交叉任务概括,神经,2023年[纸] [代码]
- 自适应预算分配用于参数有效微调, ICLR,2023年[纸]
- Dylora:使用动态无搜索低级适应的预处理模型的参数调整, EACL,2023年[纸] [代码]
- 绑定洛拉:通过重量绑扎提高洛拉的参数效率, Arxiv,2023年[纸]
- 洛拉:大语言模型的低级改编, ICLR,2022 [纸] [代码]
前缀调整
- 骆驼适配:有效地对语言模型的有效微调,请注意, Arxiv,2023年[纸] [代码]
- 前缀调整:优化发电的连续提示ACL,2021 [纸] [代码]
及时调整
- 压缩,然后提示:通过可转让的提示提高LLM推断的准确性效率折衷, Arxiv,2023年[纸]
- GPT也明白AI开放,2023年[纸] [代码]
- 模块化提示的多任务预训练,以进行几次学习ACL,2023年[纸] [代码]
- 多任务提示调整启用参数有效的传输学习, ICLR,2023年[纸]
- PPT:预先训练的及时调整以进行几次学习, ACL,2022年[纸] [代码]
- 参数有效的及时调整使广义和校准的神经文本夺回器, Emnlp-findings,2022年[纸] [代码]
- p-Tuning V2:提示调整可以与跨量表和任务普遍普遍的FINETUNS相提并论, ACL-Short,2022 [纸] [代码]
- 参数有效及时调整的比例功能, Emnlp,2021年[纸]
记忆有效的微调
- 一项针对微调大语言模型的优化研究, Arxiv,2024/ins> [纸]
- 大语言模型微调的稀疏矩阵, Arxiv,2024/ins> [纸]
- 盛大:通过梯度低级投影的记忆效率LLM训练, Arxiv,2024/ins> [纸]
- REFT:语言模型的表示列表, Arxiv,2024/ins> [纸]
- LISA:对内存有效的大语言模型微调的层次重要性采样, Arxiv,2024/ins> [纸]
- Bitdelta:您的微调可能只有一点点, Arxiv,2024/ins> [纸]
- 获奖者 - 全列行采样用于内存有效适应语言模型的采样,神经,2023年[纸] [代码]
- 记忆有效的选择性微调, ICML研讨会,2023年[纸]
- 用于有限资源的大型语言模型的完整参数微调, Arxiv,2023年[纸] [代码]
- 带有正向通过的微调语言模型,神经,2023年[纸] [代码]
- 通过低4位整数量化对压缩大语模型的记忆有效的微调,神经,2023年[纸]
- Loftq:大语言模型的Lora-Fine-tuning-tauning-Aware-Awaring-Aware-Awaring-Awaring-Awaring-Awaring-Awaring-taining-warme量化Arxiv,2023年[纸] [代码]
- QA-LORA:大型语言模型的量化低级适应, Arxiv,2023年[纸] [代码]
- QLORA:量化LLM的有效捕获,神经,2023年[Paper] [Code1] [Code2]
Moe有效的预定效果
- 让专家坚持他的最后一个:专家专业的微调,以稀疏建筑大型语言模型, Arxiv,2024年[纸]
有效的推断
平行解码
- CLLM:一致性大语言模型, Arxiv,2024年[纸]
- 一次编码并并行解码:有效的变压器解码, Arxiv,2024年[纸]
投机解码
- MagicDec:通过投机解码来打破长篇小说生成的延迟交换权权衡, Arxiv,2024年[纸]
- 杰出:用闪光树专注解码,以实现有效的树结构的LLM推理, Arxiv,2024年[纸]
- LayersKip:实现早期出口推理和自我指导, Arxiv,2024年[纸]
- Triforce:通过分层投机解码的长序列产生的无损加速度, Arxiv,2024年[纸]
- 休息:基于检索的投机解码, Arxiv,2024年[纸]
- 推理有效LLM的串联变压器, Arxiv,2024年[纸]
- 通过:平行投机抽样, Neurips研讨会,2023年[纸]
- 加速变压器推断通过并行解码,用于翻译, ACL,2023年[纸] [代码]
- 美杜莎:简单的框架,用于加速LLM具有多个解码头的生成,博客,2023年[博客] [代码]
- 通过投机解码从变形金刚快速推断, ICML,2023 [纸]
- 加速LLM推断分阶段的投机解码, ICML研讨会,2023年[纸]
- 加速使用投机抽样的大型语言模型解码, Arxiv,2023年[纸]
- 用大小解码器进行投机解码,神经,2023年[纸] [代码]
- SpecInfer:加速具有投机推理和令牌树验证的生成LLM, Arxiv,2023年[纸] [代码]
- 参考的推断:大语言模型的无损加速度, Arxiv,2023年[纸] [代码]
- 种子:通过计划的投机解码加速推理树的建设, Arxiv,2024年[纸]
KV-CACHE优化
- VL-CACHE:视觉模型推理加速度的稀疏性和模态感知的KV缓存压缩, Arxiv,2024年[纸]
- 临界1.0:通过动态稀疏注意力加速长篇文化LLM的预填充, Arxiv,2024年[纸]
- KVSharer:通过层次不同的KV缓存共享有效推断, Arxiv,2024年[纸]
- 二重奏:有效的长篇小写LLM与检索和流式脑的推理, Arxiv,2024年[纸]
- lazyllm:用于有效的长上下文推理的动态令牌修剪, Arxiv,2024年[纸]
- PALU:通过低级投影压缩KV-CACHE, Arxiv,2024年[纸] [代码]
- Look-M:在KV缓存中的外观优化,以进行有效的多模式长篇小说推断, Arxiv,2024年[纸]
- D2O:动态判别操作,用于有效地推断大语言模型的生成推断, Arxiv,2024年[纸]
- 任务:查询意识到的稀疏性对于有效的长篇小写LLM推断, ICML,2024 [纸]
- 减少变压器钥匙值高速缓存大小,并以跨层的注意, Arxiv,2024年[纸]
- snapkv:llm知道您在世代之前正在寻找什么, Arxiv,2024年[纸]
- 基于锚的大语言模型, Arxiv,2024年[纸]
- kvquant:使用KV缓存量化的1000万个上下文长度LLM推断, Arxiv,2024年[纸]
- 齿轮:一种有效的KV缓存压缩配方Arxiv,2024年[纸]
- 动态内存压缩:加速推理的翻新LLMS, Arxiv,2024年[纸]
- 没有留下的令牌:可靠的KV缓存通过重要性感知的混合精度量化, Arxiv,2024年[纸]
- 少获取更多:通过有效LLM推断的KV CACHE压缩的合成复发, Arxiv,2024年[纸]
- wkvquant:量化大型语言模型的重量和键/值缓存更多, Arxiv,2024年[纸]
- 关于驱逐策略对密钥价值约束生成语言模型推论的功效, Arxiv,2024年[纸]
- KIVI:KV缓存的无调的不对称2bit量化, Arxiv,2024年[纸] [代码]
- 模型告诉您要丢弃什么:llms的自适应KV缓存压缩, ICLR,2024 [纸]
- Skipdecode:自动回旋跳过解码,用于批处理和缓存,以进行有效的LLM推理, Arxiv,2023年[纸]
- H2O:重击甲骨文以有效地推断大语言模型,神经,2023年[纸]
- 剪刀:利用在测试时为LLM KV缓存压缩的重要性假设的持续性,神经,2023年[纸]
- 动态环境修剪有效且可解释的自动回归变压器, Arxiv,2023年[纸]
有效的体系结构
有效的关注
共享的注意力
- 洛马:无损压缩记忆的关注, Arxiv,2024年[纸]
- MOBILELL:优化数十亿个参数语言模型用于设备上的用例, Arxiv,2024年[纸]
- GQA:训练多头检查点的广义多电量变压器模型, Emnlp,2023年[纸]
- 快速变压器解码:一个写头是您所需要的, Arxiv,2019年[纸]
功能信息减少
- NYSTRöMformer:一种基于Nyström的算法,用于近似自我注意力, AAAI,2021年[纸] [代码]
- 漏斗转换器:滤除有效语言处理的顺序冗余,神经,2020年[纸] [代码]
- 设置变压器:基于注意的置换不变性神经网络的框架, ICML,2019年[纸]
内核或低级别
- Loki:低级钥匙,有效稀疏注意, ICML研讨会,2023年[纸]
- sumformer:有效变压器的通用近似,, ICML研讨会,2023年[纸]
- Flurka:快速融合的低级和内核的注意, Arxiv,2023年[纸]
- 散射脑:统一稀疏和低等级的注意力, Neurlps,2021 [纸] [代码]
- 重新思考表演者的关注, ICLR,2021 [纸] [代码]
- 随机特征注意, ICLR,2021 [纸]
- Linformer:线性复杂性的自我注意力, Arxiv,2020年[纸] [代码]
- 使用低级变压器的轻巧,高效的端到端语音识别, ICASSP,2020年[纸]
- 变形金刚是RNN:具有线性注意的快速自回归变压器, ICML,2020年[纸] [代码]
固定模式策略
- 简单的线性注意力语言模型平衡了召回折衷方案, Arxiv,2024年[纸]
- Lightning Coative-2:免费午餐,用于处理大语言模型中无限序列长度的免费午餐, Arxiv,2024年[纸] [代码]
- 通过稀疏的闪光灯注意,在大序列上更快的因果关注, ICML研讨会,2023年[纸]
- 集合形式:长文档建模,集合注意力, ICML,2021 [纸]
- 大鸟:变压器更长的序列,神经,2020年[纸] [代码]
- longformer:长期变压器, Arxiv,2020年[纸] [代码]
- 长期文档理解的自我注意力, Emnlp,2020年[纸] [代码]
- 用稀疏的变压器生成长序列, Arxiv,2019年[纸]
可学习的模式策略
- MOA:自动大型语言模型压缩的稀疏注意力的混合物, Arxiv,2024年[纸]
- 超级注意:在接近线性的时间内长期关注, Arxiv,2023年[纸] [代码]
- 聚类形式:神经聚类的注意力,以提高高效变压器, ACL,2022年[纸]
- 改革者:有效的变压器, ICLR,2022 [纸] [代码]
- 稀疏的sindhorn注意力, ICML,2020年[纸]
- 快速的变压器引起关注,神经,2020年[纸] [代码]
- 通过路由变压器,有效的基于内容的稀疏注意力, TACL,2020年[纸] [代码]
专家的混合物
基于MOE的LLM
- 自我摩托:迈向具有自专业专家的构图大语模型, Arxiv,2024年[纸]
- Lory:自回归语言模型预训练的充分区分混合物,2024 [Paper]
- JETMOE:以0.10万美元的价格达到Llama2性能,2024 [纸]
- 专家是值得一个令牌的:通过专家令牌路由协同为多个专家LLM,2024年[Paper]
- 深入的混合物:在基于变压器的语言模型中动态分配计算,2024 [Paper]
- 分支机构混合:将专家LLM混合到Experts LLM的混合物中,2024 [Paper]
- 专家的混合Arxiv,2024年[纸] [代码]
- Mistral 7b, Arxiv,2023年[纸] [代码]
- pangu-σ:使用稀疏异质计算的数万亿个参数语言模型, Arxiv,2023年[纸]
- 开关变压器:具有简单有效的稀疏性的缩放到万亿个参数模型, JMLR,2022年[纸] [代码]
- 有效的大规模语言建模与专家的混合物, Emnlp,2022年[纸] [代码]
- 基层:简化大型稀疏模型的培训, ICML,2021 [纸] [代码]
- GSHARD:使用条件计算和自动碎片的尺度缩放巨型模型, ICLR,2021 [纸]
算法级MUE优化
- Seer-Moe:通过正规化的专家效率稀少Arxiv,2024/ins> [纸]
- 为专家的细粒度混合物的缩放法律, Arxiv,2024/ins> [纸]
- 终身用分销专家预测的语言, ICML,2023 [纸]
- Experts的混合物符合教学调整:大型语言模型的获胜组合, Arxiv,2023年[纸]
- 与专家选择路由相混合的混合物,神经,2022年[纸]
- Stablemoe:专家混合的稳定路由策略, ACL,2022年[纸] [代码]
- 关于专家稀疏混合物的代表崩溃,神经,2022年[纸]
长上下文LLM
外推和插值
- 两块石头击中一只鸟:双杆位置编码,以提高长度的外推, ICML,2024 [纸]
- ∞基础:将长上下文评估延长超过100k令牌, Arxiv,2024年[纸]
- 共振绳:改善上下文长度概括大型语言模型, Arxiv,2024年[纸] [代码]
- longrope:将LLM上下文窗口延长超过200万个令牌, Arxiv,2024年[纸]
- e^2-llm:大语模型的高效和极端长度扩展, Arxiv,2024年[纸]
- 基于绳索外推的缩放定律, Arxiv,2023年[纸]
- 一个长度驱动变压器, ACL,2023年[纸] [代码]
- 通过位置插值扩展大型语言模型的上下文窗口, Arxiv,2023年[纸]
- NTK插值,博客,2023年[Reddit帖子]
- 纱线:大语模型的有效上下文窗口扩展, Arxiv,2023年[纸] [代码]
- clex:大语言模型的连续长度外推, Arxiv,2023年[纸] [代码]
- 姿势:通过位置跳过训练的LLM的有效上下文窗口扩展, Arxiv,2023年[纸] [代码]
- 相对位置的功能插值可改善长上下文变压器, Arxiv,2023年[纸]
- 训练短,测试长:带有线性偏见的注意力可以使输入长度外推, ICLR,2022 [纸] [代码]
- 探索大语模型中的长度概括,神经,2022年[纸]
复发结构
- 保留网络:大型语言模型变压器的继任者, Arxiv,2023年[纸] [代码]
- 经常性内存变压器,神经,2022年[纸] [代码]
- 块状变压器,神经,2022年[纸] [代码]
- ∞组:无限内存变压器, ACL,2022年[纸] [代码]
- memformer:用于序列建模的内存增强变压器, aacl-findings,2020年[纸] [代码]
- Transformer-XL:超出固定长度上下文的细心语言模型, ACL,2019年[纸] [代码]
细分和滑动窗口
- XL3M:基于细分推断的LLM长度扩展的无训练框架, Arxiv,2024年[纸]
- Transformerfam:反馈注意是工作记忆, Arxiv,2024年[纸]
- 基于天真的贝叶斯的上下文扩展大语模型, NAACL,2024年[纸]
- 没有留下背景Arxiv,2024年[纸]
- 对神经压缩文本的培训LLM, Arxiv,2024年[纸]
- LM侵犯:大语言模型的零射击极端概括, Arxiv,2024年[纸]
- 大型语言模型的无培训长篇小说缩放, Arxiv,2024年[纸] [代码]
- 使用并行上下文编码的长篇小写语言建模, Arxiv,2024年[纸] [代码]
- 从4K飙升至400k:通过激活信标扩展LLM的上下文, Arxiv,2024年[纸] [代码]
- llm也许是longlm:自我扩展llm上下文窗口而无需调整, Arxiv,2024年[纸] [代码]
- 通过语义压缩扩展大型语言模型的上下文窗口, Arxiv,2023年[纸]
- 有效的流式语言模型,带有注意力下沉, Arxiv,2023年[纸] [代码]
- 大型语言模型的并行上下文窗口, ACL,2023年[纸] [代码]
- Longnet:将变形金刚缩放到1,000,000,000个令牌, Arxiv,2023年[纸] [代码]
- 有效的长文本模型的有效理解, TACL,2023年[纸] [代码]
内存回程增强
- INFLLM:揭示LLM的内在能力,以理解无训练记忆的极长序列, Arxiv,2024年[纸]
- 具有里程碑意义的关注:变压器的随机访问无限上下文长度, Arxiv,2023年[纸] [代码]
- 具有长期记忆的增强语言模型,神经,2023年[纸]
- 无形者:无限长度输入的远程变压器,神经,2023年[纸] [代码]
- 专注的变压器:上下文缩放的对比培训,神经,2023年[纸] [代码]
- 检索符合长上下文大语言模型, Arxiv,2023年[纸]
- 记忆变压器, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
状态空间模型
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [纸]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [纸]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [纸]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [纸]
- Block-State Transformers, NeurIPS, 2023 [纸]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces,神经,2022年[Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [纸]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [纸]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [纸]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [纸]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [纸]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [纸]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [纸]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [纸]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [纸]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [纸]
? Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [纸]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [纸]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [纸]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [纸]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [纸]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [纸]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [纸]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [纸]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [纸]
Prompt Engineering
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [纸]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [纸]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [纸]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [纸]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [纸]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [纸]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [纸]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [纸]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [纸]
- Learning to Reason with LLMs, Website, 2024 [html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [纸]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [纸]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [纸]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [纸]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [纸]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,神经,2022年[纸]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [纸]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [纸]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [纸]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [纸]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [纸]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [纸]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [纸]
迅速产生
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [纸]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [纸]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [纸]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 , [纸]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [纸]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [纸]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [纸]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [纸]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [纸]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [纸]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [纸]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [纸]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [纸]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [纸]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [纸]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [纸]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [纸]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [纸]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [纸]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [纸]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [纸]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [纸]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [纸]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [纸]
- Fairness in Serving Large Language Models, arXiv, 2023 [纸]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [纸]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,神经,2022年[Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [博客]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [纸]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [纸]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [纸]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [纸]
LLM Frameworks
| 有效的培训 | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | ✅ | ✅ | ✅ |
| Megatron [Code] | ✅ | ✅ | ✅ |
| ColossalAI [Code] | ✅ | ✅ | ✅ |
| Nanotron [Code] | ✅ | ✅ | ✅ |
| MegaBlocks [Code] | ✅ | ✅ | ✅ |
| FairScale [Code] | ✅ | ✅ | ✅ |
| Pax [Code] | ✅ | ✅ | ✅ |
| Composer [Code] | ✅ | ✅ | ✅ |
| OpenLLM [Code] | | ✅ | ✅ |
| LLM-Foundry [Code] | | ✅ | ✅ |
| vLLM [Code] | | ✅ | |
| TensorRT-LLM [Code] | | ✅ | |
| TGI [Code] | | ✅ | |
| RayLLM [Code] | | ✅ | |
| MLC LLM [Code] | | ✅ | |
| Sax [Code] | | ✅ | |
| Mosec [Code] | | ✅ | |


