Modèles efficaces de grande langue: une enquête
Modèles efficaces de grande langue: une enquête [ARXIV] (Version 1: 12/06/2023; Version 2: 23/12/2023; Version 3: 01/3/2024; Version 4: 05/23/2024, version de la caméra Ready of Transactions on Machine Learning Research)
Zhongwei Wan 1 , Xin Wang 1 , Che Liu 2 , Samiul Alam 1 , Yu Zheng 3 , Jiachen Liu 4 , Zhongnan Qu 5 , Shen Yan 6 , Yi Zhu 7 , Quanlu Zhang 8 , Mosharaf Chowdhury 4 , Mi Zhang 1
1 The Ohio State University, 2 Imperial College London, 3 Michigan State University, 4 University of Michigan, 5 Amazon AWS AI, 6 Google Research, 7 Boson AI, 8 Microsoft Research Asia
⚡News: Notre enquête a été officiellement acceptée par les transactions sur la recherche sur l'apprentissage automatique (TMLR), mai 2024. La version de la caméra est disponible sur: [OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
❤️ Support communautaire
Ce référentiel est maintenu par tuidan ([email protected]), SUTISCHBRUCE ([email protected]), Samiul272 ([email protected]), et mi-zhang ([email protected]). Nous accueillons des commentaires, des suggestions et des contributions qui peuvent aider à améliorer ce sondage et ce référentiel afin de leur faire de précieuses ressources au profit de toute la communauté.
Nous maintiendrons activement ce référentiel en incorporant de nouvelles recherches au fur et à mesure qu'elle émerge. Si vous avez des suggestions concernant notre taxonomie, trouvez tous les papiers manqués ou mettez à jour tout document Préimpression arxiv qui a été accepté dans un lieu, n'hésitez pas à nous envoyer un e-mail ou à soumettre une demande de traction en utilisant le format de démarrage suivant.
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
? De quoi parle cette enquête?
Les modèles de grandes langues (LLM) ont démontré des capacités remarquables dans de nombreuses tâches importantes et ont le potentiel d'avoir un impact substantiel sur notre société. Ces capacités, cependant, sont livrées avec des demandes de ressources considérables, soulignant le fort besoin de développer des techniques efficaces pour relever les défis d'efficacité posés par les LLM. Dans cette enquête, nous fournissons une revue systématique et complète de la recherche LLMS efficace. Nous organisons la littérature dans une taxonomie composée de trois catégories principales, couvrant les sujets LLMS efficaces distincts mais interconnectés de la perspective centrée sur le modèle , centrée sur les données et axée sur le cadre , respectivement. Nous espérons que notre enquête et ce référentiel GitHub pourront servir de ressources précieuses pour aider les chercheurs et les praticiens à acquérir une compréhension systématique des développements de recherche dans des LLM efficaces et les inspirer à contribuer à ce domaine important et passionnant.
? Pourquoi des LLM efficaces sont-elles nécessaires?
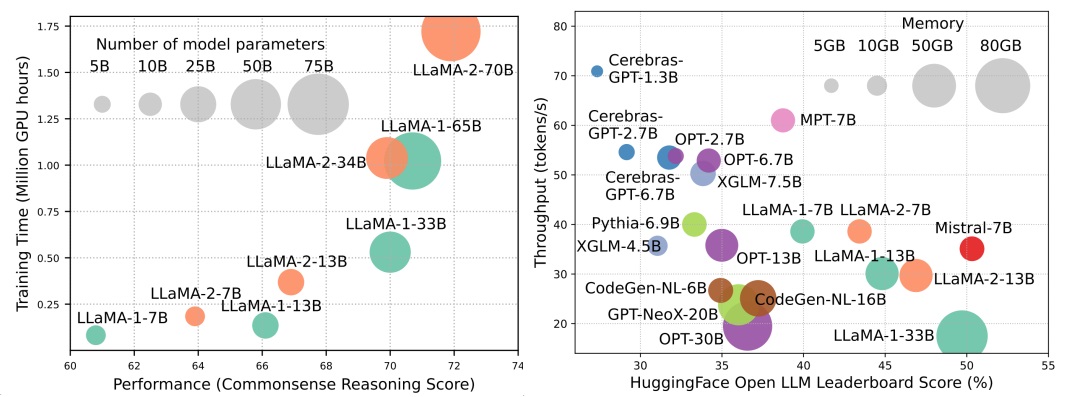
Bien que les LLM mènent la prochaine vague de révolution de l'IA, les capacités remarquables des LLM sont au prix de leurs demandes de ressources substantielles. La figure 1 (à gauche) illustre la relation entre les performances du modèle et le temps de formation du modèle en termes d'heures de GPU pour la série LLAMA, où la taille de chaque cercle est proportionnelle au nombre de paramètres du modèle. Comme indiqué, bien que les modèles plus grands puissent obtenir de meilleures performances, les quantités des heures de GPU utilisées pour les entraîner augmentent de façon exponentielle à mesure que les tailles de modèle augmentent. En plus de la formation, l'inférence contribue également de manière significative au coût opérationnel des LLM. La figure 2 (à droite) illustre la relation entre les performances du modèle et le débit d'inférence. De même, la mise à l'échelle de la taille du modèle permet de meilleures performances, mais se fait au prix du débit d'inférence plus faible (latence d'inférence plus élevée), présentant des défis pour ces modèles pour étendre leur portée à une clientèle plus large et à des applications diverses de manière rentable. Les exigences de ressources élevées des LLM mettent en évidence la forte nécessité de développer des techniques pour améliorer l'efficacité des LLM. Comme le montre la figure 2, par rapport à LLAMA-1-33B, Mistral-7B, qui utilise l'attention groupée et la glissement de la fenêtre glissante sur l'inférence accélérée, atteint des performances comparables et un débit beaucoup plus élevé. Cette supériorité met en évidence la faisabilité et la signification de la conception de techniques d'efficacité pour les LLM.
Tableau de contenu
- ? Méthodes centrées sur le modèle
- Compression du modèle
- Quantification
- Quantification post-entraînement
- Quantification de poids uniquement
- Co-activation du poids
- Évaluation de la quantification post-formation
- Formation consciente de la quantification
- Élagage des paramètres
- Élagage structuré
- Élagage non structuré
- Approximation de faible rang
- Distillation des connaissances
- KD à boîte blanche
- KD à boîte noire
- Partage des paramètres
- Pré-formation efficace
- Formation de précision mixte
- Modèles d'échelle
- Techniques d'initialisation
- Optimisateurs de formation
- Amende efficace
- Paramètre Efficient Fineding
- Réglage basé sur l'adaptateur
- Adaptation de faible rang
- Réglage du préfixe
- Réglage rapide
- Mémoire efficace au réglage fin
- MOE efficace au réglage fin supervisé
- Inférence efficace
- Décodage parallèle
- Décodage spéculatif
- Optimisation de KV-Cache
- Architecture efficace
- Attention efficace
- Attention au partage
- Réduction des informations sur les fonctionnalités
- Kernization ou faible rang
- Stratégies de modèle fixe
- Stratégies de motifs apprenables
- Mélange d'experts
- LLMS basés sur MOE
- Optimisation de MOE au niveau de l'algorithme
- LLMS de contexte long
- Extrapolation et interpolation
- Structure récurrente
- Segmentation et fenêtre coulissante
- Augmentation de la mémoire-rétractable
- Architecture alternative du transformateur
- Modèles d'état d'espace
- Autres modèles séquentiels
- ? Méthodes centrées sur les données
- Sélection de données
- Sélection de données pour une pré-formation efficace
- Sélection de données pour un réglage fin efficace
- Ingénierie rapide
- Invitation à quelques coups
- Organisation de démonstration
- Sélection de démonstration
- Commande de démonstration
- Formatage du modèle
- Génération d'instructions
- Raisonnement en plusieurs étapes
- Génération parallèle
- Compression rapide
- Génération rapide
- ? Optimisation d'efficacité au niveau du système et cadres LLM
- Optimisation d'efficacité au niveau du système
- Optimisation d'efficacité pré-formation au niveau du système
- Optimisation d'efficacité au niveau du système
- Conception du système de service
- Servir l'optimisation des performances
- Algorithme-hardware co-conception
- Frameworks LLM
? Méthodes centrées sur le modèle
Compression du modèle
Quantification
Quantification post-entraînement
Quantification de poids uniquement
- I-llm: inférence efficace en entier uniquement pour les modèles de langage à faible teneur en pleine qualité, Arxiv, 2024 [Papier]
- IntactKV: Amélioration de la quantification du modèle de langue importante en gardant des jetons de pivot intacts, Arxiv, 2024 [Papier]
- Omnictant: omniquant: quantification calibrée de manière omnidirectionnelle pour les modèles de langage grand ICLR, 2024 [Papier] [Code]
- Onebit: Vers des modèles de langues très faibles à faible bit, Arxiv, 2024 [Papier]
- GPTQ: quantification précise pour les transformateurs génératifs pré-formés, ICLR, 2023 [Papier] [Code]
- Quip: quantification 2 bits de modèles de gros langues avec garanties, Arxiv, 2023 [Papier] [Code]
- AWQ: quantification du poids conscient de l'activation pour la compression et l'accélération LLM, Arxiv, 2023 [Papier] [Code]
- OWQ: leçons apprises des valeurs aberrantes d'activation pour la quantification du poids dans les modèles de langues importants, Arxiv, 2023 [Papier] [Code]
- SPQR: une représentation clairsemée pour la compression de poids LLM presque sans perte Arxiv, 2023 [Papier] [Code]
- Finebant: déverrouillage de l'efficacité avec une quantification de poids unique à grain à grain pour les LLM, Neirips-ENLSP, 2023 [Papier]
- Llm.int8 (): multiplication matricielle 8 bits pour les transformateurs à l'échelle, Neurlps, 2022 [Papier] [Code]
- Compression optimale du cerveau: un cadre pour la quantification et l'élagage post-entraînement précises, NEIRIPS, 2022 [Papier] [Code]
- Quantonase: quantification basée sur l'optimisation pour les modèles de langage, Arxiv, 2023 [Papier] [Code]
Co-activation du poids
- Rotation et permutation pour la gestion avancée des valeurs aberrantes et la quantification efficace des LLM, Neirips, 2024 [Papier]
- Omnictant: omniquant: quantification calibrée de manière omnidirectionnelle pour les modèles de langage grand ICLR, 2024 [Papier] [Code]
- Propriétés intrigantes de la quantification à l'échelle, NEIRIPS, 2023 [Papier]
- ZeroQuant-V2: Exploration de la quantification post-entraînement dans les LLM, d'une étude complète à une compensation à faible rang, Arxiv, 2023 [Papier] [Code]
- FP à zéro: un bond en avant dans la quantification W4A8 post-entraînement LLMS à l'aide de formats à virgule flottante, Neirips-ENLSP, 2023 [Papier] [Code]
- Olive: accélérer les modèles de gros langues via la quantification des paires de valeurs aberrantes adaptées au matériel, ISCA, 2023 [Papier] [Code]
- RPTQ: quantification post-entraînement basée sur les réorganisations pour les modèles de grande langue, Arxiv, 2023 [Papier] [Code]
- Suppression des valeurs aberrantes +: quantification précise des modèles de grands langues par un changement et une mise à l'échelle équivalentes et optimales, Arxiv, 2023 [Papier] [Code]
- QLLM: quantification précise et efficace de faible largeur pour les modèles de langage, Arxiv, 2023 [Papier]
- Smoothand: Quantification post-formation précise et efficace pour les modèles de gros langues, ICML, 2023 [Papier] [Code]
- Zeroquant: quantification post-formation efficace et abordable pour les transformateurs à grande échelle, NEIRIPS, 2022 [Papier]
Évaluation de la quantification post-formation
- Évaluation de modèles de grande langue quantifiés, Arxiv, 2024 [Papier]
Formation consciente de la quantification
- L'ère des LLMS 1 bits: tous les modèles de grande langue sont en 1,58 bits, Arxiv, 2024 [Papier]
- FP8-LM: formation FP8 Modèles de grande langue, Arxiv, 2023 [Papier]
- Formation et inférence de grands modèles de langue en utilisant un point flottant 8 bits, Arxiv, 2023 [Papier]
- Bitnet: mise à l'échelle des transformateurs 1 bits pour les grands modèles de langue, Arxiv, 2023 [Papier]
- LLM-QAT: Formation de conscience de quantification sans données pour les modèles de gros langues, Arxiv, 2023 [Papier] [Code]
- Compression des modèles de langage pré-formés génératifs via la quantification, ACL, 2022 [Papier]
Élagage des paramètres
Élagage structuré
- Modèles de langue compacts via l'élagage et la distillation des connaissances, Arxiv, 2024 [Papier]
- Un regard plus profond sur l'élagage en profondeur des LLMS, Arxiv, 2024 [Papier]
- Perplexe par perplexité: élagage des données basé sur la perplexité avec de petits modèles de référence, Arxiv, 2024 [Papier]
- Plug-and-play: une méthode d'élagage post-formation efficace pour les modèles de grands langues, ICLR, 2024 [Papier]
- Besa: élagage de grands modèles de langage avec allocation de rareté économe en blocs, Arxiv, 2024 [Papier]
- Shortgpt: les couches dans les modèles de grande langue sont plus redondantes que prévu, Arxiv, 2024 [Papier]
- NUTEPRUNE: élagage progressif efficace avec de nombreux enseignants pour les grands modèles de langue, Arxiv, 2024 [Papier]
- SliceGpt: Comprimer les modèles de grande langue en supprimant les lignes et les colonnes, ICLR, 2024 [Papier] [Code]
- Lorashear: élagage structuré de grande langue efficace et récupération des connaissances, Arxiv, 2023 [Papier]
- LLM-PRUNER: Sur l'élagage structurel des grands modèles de langue, NEIRIPS, 2023 [Papier] [Code]
- Llama cisaillé: accélération du modèle de langue pré-formation via l'élagage structuré, Neirips-ENLSP, 2023 [Papier] [Code]
- Loraprune: l'élagage répond à un réglage fin et économe en paramètres, Arxiv, 2023 [Papier]
Élagage non structuré
- Maskllm: rareté semi-structurée apprenable pour les grands modèles de langue, Nips, 2024 [Papier]
- Dynamique clairsemé sans formation: réglage fin sans formation pour les LLM clairsemés, ICLR, 2024 [Papier]
- Sparsegpt: les modèles de langage massifs peuvent être élagués avec précision en un seul coup, ICML, 2023 [Papier] [Code]
- Une approche d'élagage simple et efficace pour les modèles de grands langues, Arxiv, 2023 [Papier] [Code]
- Élagage de rareté mixte d'une sensibilité à un coup pour les modèles de gros langues, Arxiv, 2023 [Papier]
Approximation de faible rang
- SVD-LLM: Décomposition de la valeur singulière pour la compression du modèle de langue grande, Arxiv, 2024 [Papier] [Code]
- ASVD: Décomposition de la valeur singulière consciente de l'activation pour comprimer les modèles de langues importants, Arxiv, 2023 [Papier] [Code]
- Compression du modèle de langue avec factorisation de faible rang pondéré, ICLR, 2022 [Papier]
- Tensorgpt: compression efficace de la couche d'incorporation dans les LLMS basée sur la décomposition du format tensor-train, Arxiv, 2023 [Papier]
- LOSPARSE: Compression structurée de modèles de grands langues basés sur une approximation de faible rang et clairsemé, ICML, 2023 [Papier] [Code]
Distillation des connaissances
KD à boîte blanche
- DDK: Distiller les connaissances du domaine pour des modèles efficaces de grande langue Arxiv, 2024 [Papier]
- Repenser la divergence de Kullback-Lebler dans la distillation des connaissances pour les modèles de grande langue Arxiv, 2024 [Papier]
- Distillm: vers une distillation rationalisée pour les modèles de grands langues, Arxiv, 2024 [Papier] [Code]
- Vers la loi de la capacité de la capacité dans les modèles de langage de distillation, Arxiv, 2023 [Papier] [Code]
- Baby Llama: Distillation des connaissances d'un ensemble d'enseignants formés sur un petit ensemble de données sans pénalité de performance, Arxiv, 2023 [Papier]
- Distillation des connaissances des modèles de grande langue, Arxiv, 2023 [Papier] [Code]
- GKD: Distillation de connaissances généralisée pour les modèles de séquence auto-régressive, Arxiv, 2023 [Papier]
- Propager les mises à jour des connaissances en LMS par distillation, Arxiv, 2023 [Papier] [Code]
- Moins c'est plus: distillation par la couche consciente des tâches pour la compression du modèle de langue, ICML, 2023 [Papier]
- Distillation logit à l'échelle de jetons pour les modèles de langage génératif de poids ternaire, Arxiv, 2023 [Papier]
KD à boîte noire
- Zephyr: distillation directe de l'alignement LM, Arxiv, 2023 [Papier]
- Réglage des instructions avec GPT-4, Arxiv, 2023 [Papier] [Code]
- Lion: distillation adversaire du modèle de langue à source fermée, Arxiv, 2023 [Papier] [Code]
- Spécialiser des modèles de langue plus petits vers le raisonnement en plusieurs étapes, ICML, 2023 [Papier] [Code]
- Distillant étape par étape! Surperformant des modèles de langage plus grands avec moins de données d'entraînement et des tailles de modèles plus petites, ACL, 2023 [Papier]
- Les grands modèles de langue sont des enseignants, ACL, 2023 [Papier] [Code]
- Scott: distillation auto-cohérente de la chaîne de pensée, ACL, 2023 [Papier] [Code]
- Distillation symbolique chaîne de pensées: les petits modèles peuvent également "penser" étape par étape, ACL, 2023 [Papier]
- Capacités de raisonnement distillant en modèles de langage plus petits, ACL, 2023 [Papier] [Code]
- Distillation d'apprentissage dans le contexte: transférer la capacité d'apprentissage à quelques coups des modèles de langue pré-formés, Arxiv, 2022 [Papier]
- Les explications des modèles de gros langues rendent les petits raisonneurs meilleurs, Arxiv, 2022 [Papier]
- Disco: distillation contrefactuels avec de grands modèles de langue, Arxiv, 2022 [Papier] [Code]
Partage des paramètres
- Mobillama: vers un GPT précis et léger entièrement transparent, Arxiv, 2024 [Papier]
Pré-formation efficace
Formation de précision mixte
- BFLOAT16 Traitement des réseaux de neurones, Arith, 2019 [Papier]
- Une étude de BFLOAT16 pour la formation d'apprentissage en profondeur, Arxiv, 2019 [Papier]
- Formation de précision mixte, ICLR, 2018 [Papier]
Modèles d'échelle
- citron: extension du modèle sans perte, ICLR, 2024 [Papier]
- Préparer des leçons pour une formation progressive sur les modèles de langue, AAAI, 2024 [Papier]
- Apprendre à développer des modèles pré-tracés pour une formation efficace sur les transformateurs, ICLR, 2023 [Papier] [Code]
- 2x Modèle de langage plus rapide pré-formation via la croissance structurelle masquée, Arxiv, 2023 [Papier]
- Réutiliser des modèles pré-entraînés par des opérateurs multi-linéaires pour une formation efficace, NEIRIPS, 2023 [Papier]
- FLM-101B: un LLM ouvert et comment le former avec un budget de 100 $, Arxiv, 2023 [Papier] [Code]
- Héritage des connaissances pour les modèles de langue pré-formés, NAACL, 2022 [Papier] [Code]
- Formation mise en scène pour les modèles de langue des transformateurs, ICML, 2022 [Papier] [Code]
Techniques d'initialisation
- DeepNet: Échelle des transformateurs en 1 000 couches, Arxiv, 2022 [Papier] [Code]
- Initialisation zéro: initialisation des réseaux de neurones avec seulement des zéros et des zéros, TMLR, 2022 [Papier] [Code]
- Rezero est tout ce dont vous avez besoin: convergence rapide à grande profondeur, Uai, 2021 [Papier] [Code]
- Les biais de normalisation par lots biais les blocs résiduels vers la fonction d'identité dans les réseaux profonds, Neirips, 2020 [Papier]
- Amélioration de l'optimisation du transformateur par une meilleure initialisation, ICML, 2020 [Papier] [Code]
- Initialisation de la fixation: apprentissage résiduel sans normalisation, ICLR, 2019 [Papier]
- Sur l'initialisation du poids dans les réseaux de neurones profonds, Arxiv, 2017 [Papier]
Optimisateurs de formation
- Vers un apprentissage optimal des modèles de langue, Arxiv, 2024 [Papier] [Code]
- Découverte symbolique d'algorithmes d'optimisation, Arxiv, 2023 [Papier]
- Sophia: un optimiseur stochastique de second ordre évolutif pour la pré-formation du modèle de langue, Arxiv, 2023 [Papier] [Code]
Amende efficace
Affinement final à paramètres
Réglage basé sur l'adaptateur
- OpenLta: une bibliothèque de plug-and-play pour une adaptation économe en paramètres des modèles pré-formés, Demo ACL, 2023 [Papier] [Code]
- LLM-adaptrices: une famille d'adaptateurs pour le réglage fin économe en paramètres des modèles de gros langues, EMNLP, 2023 [Papier] [Code]
- Compacter: couches d'adaptateur hypercomplexe de faible rang efficace, NEIRIPS, 2023 [Papier] [Code]
- Le réglage fin à quelques coups économe en paramètres est meilleur et moins cher que l'apprentissage dans le contexte, NEIRIPS, 2022 [Papier] [Code]
- Méta-adaptateurs: paramètre Efficient à quelques coups fins à travers le méta-apprentissage, Automl, 2022 [Papier]
- Adamix: mélange d'adaptations pour le réglage du modèle économe en paramètres, EMNLP, 2022 [Papier] [Code]
- SparsEadapter: une approche facile pour améliorer l'efficacité des paramètres des adaptateurs, EMNLP, 2022 [Papier] [Code]
Adaptation de faible rang
- Hydralora: une architecture LORA asymétrique pour un réglage fin efficace, Neirips, 2024 [Papier]
- LOFIT: réglage fin localisé sur les représentations LLM, Arxiv, 2024 [Papier]
- Mélange de sous-espaces dans une adaptation de faible rang, Arxiv, 2024 [Papier] [Code]
- MEFT: Fonction d'adaptation raffinée économe en mémoire, ACL, 2024 [Papier]
- Lora rencontre un abandon dans un cadre unifié, Arxiv, 2024 [Papier]
- Star: Contrainte Lora avec un apprentissage actif dynamique pour un réglage fin économe en données de modèles de langue importants, Arxiv, 2024 [Papier]
- LORA +: adaptation efficace de bas rang des grands modèles, Arxiv, 2024 [Papier]
- LORA-FA: Adaptation de faible rang économe en mémoire pour les modèles de grande langue, le réglage fin, Arxiv, 2023 [Papier]
- Lorahub: généralisation efficace de la tâche croisée via la composition dynamique de LORA, Arxiv, 2023 [Papier] [Code]
- Longlora: affineur efficace des modèles de langage grand contexte à long contexte, Arxiv, 2023 [Papier] [Code]
- Routage des adaptateurs multiples pour la généralisation de la tâche croisée, NEIRIPS, 2023 [Papier] [Code]
- Allocation budgétaire adaptative pour le réglage fin et efficace des paramètres, ICLR, 2023 [Papier]
- Dylora: réglage économe en paramètres des modèles pré-entraînés en utilisant une adaptation à bas rang sans recherche dynamique, EACL, 2023 [Papier] [Code]
- Tied-lora: renforcement l'efficacité des paramètres de LORA avec un lien de poids, Arxiv, 2023 [Papier]
- LORA: Adaptation de faible rang des modèles de grands langues, ICLR, 2022 [Papier] [Code]
Réglage du préfixe
- LLAMA-ADAPTER: Fonction efficace des modèles de langue avec une attention nul, Arxiv, 2023 [Papier] [Code]
- Préfixe-réglage: optimisation des invites continues pour la génération ACL, 2021 [Papier] [Code]
Réglage rapide
- Compress, puis Prompt: Amélioration du compromis de l'exactitude de l'efficacité de l'inférence LLM avec une invite transférable, Arxiv, 2023 [Papier]
- GPT comprend aussi, AI Open, 2023 [Papier] [Code]
- Pré-entraînement multi-tâches de l'invite modulaire pour l'apprentissage à quelques coups ACL, 2023 [Papier] [Code]
- Le réglage invite multitâche permet l'apprentissage de transfert économe en paramètres, ICLR, 2023 [Papier]
- PPT: réglage rapide pré-entraîné pour l'apprentissage à quelques tirs, ACL, 2022 [Papier] [Code]
- Le réglage rapide économe en paramètres fait des retrievers de texte neuronal généralisés et calibrés, EMNLP-Findings, 2022 [Papier] [Code]
- P-TUNING V2: L'installation rapide peut être comparable à la finetun universellement à travers les échelles et les tâches , ACL-Short, 2022 [Papier] [Code]
- La puissance de l'échelle pour le réglage rapide économe en paramètres, EMNLP, 2021 [Papier]
Affinement fine économe en mémoire
- Une étude des optimisations pour les modèles de grande langue fins, Arxiv, 2024 / Ins> [papier]
- Matrice clairsemée dans un modèle de réglage de grande langue, Arxiv, 2024 / Ins> [papier]
- Galore: formation LLM économe en mémoire par projection de gradient de faible rang, Arxiv, 2024 / Ins> [papier]
- Reft: représentation Finetuning pour les modèles de langue, Arxiv, 2024 / Ins> [papier]
- Lisa: Échantillonnage d'importance à la couches pour le modèle de modélisation à grande langue économe en mémoire, Arxiv, 2024 / Ins> [papier]
- Bitdelta: votre amende ne vaut peut-être qu'un seul morceau, Arxiv, 2024 / Ins> [papier]
- Échantillonnage de lignes de colonne Winner-All pour l'adaptation efficace de la mémoire du modèle de langue, NEIRIPS, 2023 [Papier] [Code]
- Affinement sélectif économe en mémoire, Atelier ICML, 2023 [Papier]
- Fonction des paramètres complets pour les modèles de grandes langues avec des ressources limitées, Arxiv, 2023 [Papier] [Code]
- Modèles de langage affinés avec des passes juste en avant, NEIRIPS, 2023 [Papier] [Code]
- Affinement finochable à la mémoire des modèles de langage de grande envergure compressés via une quantification entière de sous-4 bits, NEIRIPS, 2023 [Papier]
- LOFTQ: LORA-FINE-TUNING-AWARE TIMATION POUR Arxiv, 2023 [Papier] [Code]
- QA-LORA: Adaptation de faible rang consciente de la quantification des modèles de grands langues, Arxiv, 2023 [Papier] [Code]
- Qlora: Finetuning efficace des LLM quantifiés, NEIRIPS, 2023 [Paper] [Code1] [Code2]
Moe-Efficient-SuperVissed-Fineing
- Laissez l'expert s'en tenir à son dernier: le réglage fin spécialisé par l'expert pour les modèles de grande langue architecturaux clairsemés, Arxiv, 2024 [Papier]
Inférence efficace
Décodage parallèle
- CLLMS: cohérence des grands modèles de langue, Arxiv, 2024 [Papier]
- Encoder une fois et décoder en parallèle: décodage de transformateur efficace, Arxiv, 2024 [Papier]
Décodage spéculatif
- MagicDec: Breaking the latency-throughput comprosioff pour une longue génération de contexte avec décodage spéculatif, Arxiv, 2024 [Papier]
- Détal: décodage avec une mise en garde des arbres flash pour une inférence LLM structurée efficace, Arxiv, 2024 [Papier]
- Coucheskip: activer l'inférence de sortie précoce et le décodage auto-spécialisé, Arxiv, 2024 [Papier]
- Triforce: Accélération sans perte de la génération de séquences longues avec décodage spéculatif hiérarchique, Arxiv, 2024 [Papier]
- Repos: décodage spéculatif basé sur la récupération, Arxiv, 2024 [Papier]
- Transformers en tandem pour les LLMS efficaces dans l'inférence, Arxiv, 2024 [Papier]
- Passer: échantillonnage spéculatif parallèle, Atelier de Neirips, 2023 [Papier]
- Accélérer l'inférence du transformateur pour la traduction via le décodage parallèle, ACL, 2023 [Papier] [Code]
- Medusa: Framework simple pour accélérer la génération LLM avec plusieurs têtes de décodage, Blog, 2023 [Blog] [Code]
- Inférence rapide des transformateurs via le décodage spéculatif, ICML, 2023 [Papier]
- Accélérer l'inférence LLM avec le décodage spéculatif mis en scène, Atelier ICML, 2023 [Papier]
- Accélérer le décodage du modèle de langue grand avec un échantillonnage spéculatif, Arxiv, 2023 [Papier]
- Décodage spéculatif avec un grand petit décodeur, NEIRIPS, 2023 [Papier] [Code]
- SCECINFER: Accélération de LLM générative servant avec une inférence spéculative et une vérification des arbres à jeton, Arxiv, 2023 [Papier] [Code]
- Inférence avec référence: accélération sans perte de modèles de gros langues, Arxiv, 2023 [Papier] [Code]
- Graines: accélération de la construction d'arbres de raisonnement via le décodage spéculatif prévu, Arxiv, 2024 [Papier]
Optimisation de KV-Cache
- VL-cache: compression de cache KV à la rareté et à la modalité pour l'accélération d'inférence du modèle de langue visuelle, Arxiv, 2024 [Papier]
- Minférence 1.0: Accélération du pré-remplissage pour les LLM à long contexte via une attention clairsemée dynamique, Arxiv, 2024 [Papier]
- KVSHARER: inférence efficace via le partage de cache KV dissemblable par couche, Arxiv, 2024 [Papier]
- DuoAttentie: Inférence LLM efficace à long terme avec les têtes de récupération et de streaming, Arxiv, 2024 [Papier]
- Lazyllm: élagage de jeton dynamique pour une inférence efficace de contexte long, Arxiv, 2024 [Papier]
- Palu: compression de KV-Cache avec projection de faible rang, Arxiv, 2024 [Papier] [Code]
- Look-m: optimisation look-once dans le cache KV pour une inférence multimodale à long contexte efficace, Arxiv, 2024 [Papier]
- D2O: opérations discriminatoires dynamiques pour une inférence générative efficace des modèles de langues importants, Arxiv, 2024 [Papier]
- Quest: la rareté de la requête pour une inférence LLM à long terme efficace, ICML, 2024 [Papier]
- Réduire la taille du cache de valeur clé du transformateur avec l'attention de la couche transversale, Arxiv, 2024 [Papier]
- Snapkv: LLM sait ce que vous recherchez avant la génération, Arxiv, 2024 [Papier]
- Modèles de grande langue basés sur l'ancrage, Arxiv, 2024 [Papier]
- Kvant: Vers 10 millions de personnes de contexte LLM inférence avec la quantification du cache KV, Arxiv, 2024 [Papier]
- Équipement: une recette efficace de compression de cache KV pour une inférence générative presque sans perte de llm, Arxiv, 2024 [Papier]
- Compression dynamique de la mémoire: Retrofitt LLMS pour l'inférence accélérée, Arxiv, 2024 [Papier]
- Pas de jeton laissé pour compte: compression fiable du cache KV via une quantification de précision mixte à l'importance, Arxiv, 2024 [Papier]
- Obtenez plus avec moins: synthèse de récidive avec une compression de cache KV pour une inférence LLM efficace, Arxiv, 2024 [Papier]
- WKVQUANT: La quantification du poids et du cache de clé / valeur pour les modèles de gros langage en gagne plus, Arxiv, 2024 [Papier]
- Sur l'efficacité de la politique d'expulsion pour l'inférence du modèle de langage génératif contraint, Arxiv, 2024 [Papier]
- Kivi: une quantification asymétrique 2 bits sans réglage pour le cache KV, Arxiv, 2024 [Papier] [Code]
- Le modèle vous dit quoi rejeter: compression adaptative du cache KV pour LLMS, ICLR, 2024 [Papier]
- Skipdecode: décodage de sauts autorégressif avec lots et mise en cache pour une inférence LLM efficace, Arxiv, 2023 [Papier]
- H2O: oracle de frappeurs lourds pour une inférence générative efficace des modèles de gros langues, NEIRIPS, 2023 [Papier]
- Scissorhands: Exploiter l'hypothèse de la persistance de l'importance pour la compression du cache LLM KV au moment du test, NEIRIPS, 2023 [Papier]
- Élagage de contexte dynamique pour les transformateurs autorégressifs efficaces et interprétables, Arxiv, 2023 [Papier]
Architecture efficace
Attention efficace
Attention au partage
- Loma: Attention à la mémoire comprimée sans perte, Arxiv, 2024 [Papier]
- Mobilellm: Optimisation des modèles de langage de paramètres inférieurs aux milliards pour les cas d'utilisation à disque, Arxiv, 2024 [Papier]
- GQA: Formation des modèles de transformateurs multi-couches généralisés à partir de points de contrôle multiples, EMNLP, 2023 [Papier]
- Décodage du transformateur rapide: une tête d'écriture est tout ce dont vous avez besoin, Arxiv, 2019 [Papier]
Réduction des informations sur les fonctionnalités
- Nyströmformer: un algorithme à base de Nyström pour approximation de l'auto-attention, AAAI, 2021 [Papier] [Code]
- Transformateur en entonnoir: filtrage de la redondance séquentielle pour un traitement efficace du langage, Neirips, 2020 [Papier] [Code]
- Set Transformer: un cadre pour les réseaux de neurones invariants basés sur l'attention, ICML, 2019 [Papier]
Kernization ou faible rang
- Loki: clés de faible rang pour une attention clairsemée efficace, Atelier ICML, 2023 [Papier]
- SUMFORMER: approximation universelle pour les transformateurs efficaces, Atelier ICML, 2023 [Papier]
- Flurka: Attention rapide à faible rang et noyau, Arxiv, 2023 [Papier]
- Brain de dispersion: unificateur clairsemé et faible attention, Neurlps, 2021 [Papier] [Code]
- Repenser l'attention avec les artistes, ICLR, 2021 [Papier] [Code]
- Attention aux fonctionnalités aléatoires, ICLR, 2021 [Papier]
- LinFormer: auto-attention avec complexité linéaire, Arxiv, 2020 [Papier] [Code]
- Reconnaissance vocale de bout en bout légère et efficace en utilisant un transformateur de bas rang, ICASSP, 2020 [Papier]
- Les transformateurs sont des RNN: Transformers autorégressifs rapides avec une attention linéaire, ICML, 2020 [Papier] [Code]
Stratégies de modèle fixe
- Les modèles de langage d'attention linéaire simple équilibrent le compromis de rappel, Arxiv, 2024 [Papier]
- Lightning Attention-2: Un déjeuner gratuit pour gérer les longueurs de séquence illimitées dans les modèles de gros langues, Arxiv, 2024 [Papier] [Code]
- Une attention causale plus rapide sur de grandes séquences grâce à l'attention des flashs clairsemés, Atelier ICML, 2023 [Papier]
- PooringFormer: modélisation longue des documents avec l'attention de la mise en commun, ICML, 2021 [Papier]
- Big Bird: Transformers pour les séquences plus longues, Neirips, 2020 [Papier] [Code]
- LongFormer: le transformateur de document à longue date, Arxiv, 2020 [Papier] [Code]
- Aménagement en bloc pour une longue compréhension des documents, EMNLP, 2020 [Papier] [Code]
- Générer de longues séquences avec des transformateurs clairsemés, Arxiv, 2019 [Papier]
Stratégies de motifs apprenables
- MOA: mélange d'une attention clairsemée pour la compression automatique du modèle de langue, Arxiv, 2024 [Papier]
- Hyperattention: Attention à long contexte en temps quasi linéaire, Arxiv, 2023 [Papier] [Code]
- ClusterFormer: l'attention du regroupement neural pour un transformateur efficace et efficace, ACL, 2022 [Papier]
- Réformateur: le transformateur efficace, ICLR, 2022 [Papier] [Code]
- Attention clairsemée, ICML, 2020 [Papier]
- Transformers rapides avec une attention en grappe, Neirips, 2020 [Papier] [Code]
- Une attention claire efficace basée sur le contenu avec les transformateurs de routage, Tacl, 2020 [Papier] [Code]
Mélange d'experts
LLMS basés sur MOE
- Auto-mi-mi-fuues modèles de grande langue avec des experts auto-spécialisé Arxiv, 2024 [Papier]
- Lory: Mélange d'Experts entièrement différenciable pour le modèle de langage autorégressif pré-formation, 2024 [papier]
- Jetmoe: Atteindre les performances de Llama2 avec 0,1 m de dollars, 2024 [papier]
- Un expert vaut un jeton: synergiser plusieurs LLM experts en tant que généraliste via un routage de jetons experts, 2024 [document]
- Mélange de dépassement: allocation dynamique du calcul dans les modèles de langage basés sur les transformateurs, 2024 [papier]
- Branch-Train-mix: Mélanger les LLM experts dans un mélange de LLM des experts, 2024 [papier]
- Mixtral d'experts, Arxiv, 2024 [Papier] [Code]
- Mistral 7b, Arxiv, 2023 [Papier] [Code]
- Pangu-σ: Vers un modèle de langage de paramètres de milliards avec l'informatique hétérogène clairsemée, Arxiv, 2023 [Papier]
- Transformeurs de commutation: mise à l'échelle des modèles de paramètres de milliards avec une rareté simple et efficace, JMLR, 2022 [Papier] [Code]
- Modélisation efficace du langage à grande échelle avec des mélanges d'experts, EMNLP, 2022 [Papier] [Code]
- Couches de base: simplifier la formation des grands modèles clairsemés, ICML, 2021 [Papier] [Code]
- GSHARD: Échelle des modèles géants avec calcul conditionnel et rupture automatique, ICLR, 2021 [Papier]
Optimisation de MOE au niveau de l'algorithme
- SEER-MOE: Efficacité experte clairsemée par régularisation pour le mélange de temps, Arxiv, 2024 / Ins> [papier]
- Échelle des lois pour le mélange d'experts à grain fin, Arxiv, 2024 / Ins> [papier]
- Langue permanente à vie avec des experts spécialisés à la distribution, ICML, 2023 [Papier]
- Mélange des experts rencontre le réglage des instructions: une combinaison gagnante pour les modèles de grande langue, Arxiv, 2023 [Papier]
- Mélange des experts avec un routage de choix expert, NEIRIPS, 2022 [Papier]
- Stable: stratégie de routage stable pour le mélange d'experts, ACL, 2022 [Papier] [Code]
- Sur l'effondrement de la représentation d'un mélange clairsemé d'experts, NEIRIPS, 2022 [Papier]
LLMS de contexte long
Extrapolation et interpolation
- Deux pierres ont frappé un oiseau: codage de position de Bilevel pour une meilleure longueur d'extrapolation, ICML, 2024 [Papier]
- ∞-Bench: étendant une longue évaluation de contexte au-delà des jetons de 100K, Arxiv, 2024 [Papier]
- Corde à résonance: amélioration de la généralisation de la longueur du contexte des modèles de grands langues, Arxiv, 2024 [Papier] [Code]
- Longrope: extension de la fenêtre de contexte LLM au-delà de 2 millions de jetons, Arxiv, 2024 [Papier]
- E ^ 2-llm: extension efficace et extrême de la longueur des grands modèles de langue, Arxiv, 2024 [Papier]
- Échelle des lois de l'extrapolation basée sur la corde, Arxiv, 2023 [Papier]
- Un transformateur extrapable de longueur, ACL, 2023 [Papier] [Code]
- Extension de la fenêtre de contexte des grands modèles de langue via une interpolation positionnelle, Arxiv, 2023 [Papier]
- Interpolation NTK, Blog, 2023 [Post Reddit]
- YARN: Extension de fenêtre de contexte efficace des grands modèles de langue, Arxiv, 2023 [Papier] [Code]
- CLEX: Extrapolation de longueur continue pour les modèles de grands langues, Arxiv, 2023 [Papier] [Code]
- Pose: extension de fenêtre de contexte efficace des LLM via une formation positionnelle sur le saut, Arxiv, 2023 [Papier] [Code]
- L'interpolation fonctionnelle pour les positions relatives améliore les transformateurs de contexte longs, Arxiv, 2023 [Papier]
- Train court, test long: l'attention avec des biais linéaires permet une extrapolation de la longueur d'entrée, ICLR, 2022 [Papier] [Code]
- Exploration de la généralisation de la longueur dans les modèles de grande langue, NEIRIPS, 2022 [Papier]
Structure récurrente
- Réseau de rétention: un successeur de Transformer pour les modèles de grande langue, Arxiv, 2023 [Papier] [Code]
- Transformateur de mémoire récurrent, NEIRIPS, 2022 [Papier] [Code]
- Transformers de bloc-récurrent, NEIRIPS, 2022 [Papier] [Code]
- ∞ Former: transformateur de mémoire infinie, ACL, 2022 [Papier] [Code]
- Memformer: un transformateur augmenté à la mémoire pour la modélisation de séquences, AACL-Findings, 2020 [Papier] [Code]
- Transformateur-xl: modèles de langage attentif au-delà d'un contexte de longueur fixe, ACL, 2019 [Papier] [Code]
Segmentation et fenêtre coulissante
- XL3M: un cadre sans formation pour l'extension de la longueur LLM basée sur l'inférence sur le segment, Arxiv, 2024 [Papier]
- TransformerFam: l'attention de la rétroaction est la mémoire de travail, Arxiv, 2024 [Papier]
- Extension de contexte naïf de Bayes pour les modèles de grands langues, Naacl, 2024 [Papier]
- Ne laisse aucun contexte derrière: des transformateurs de contexte infini efficaces avec une infini-attention, Arxiv, 2024 [Papier]
- Training LLMS sur du texte comprimé neurally, Arxiv, 2024 [Papier]
- LM-infinite: généralisation de longueur extrême zéro pour les modèles de gros langues, Arxiv, 2024 [Papier]
- Échelle à long contexte sans formation des modèles de grands langues, Arxiv, 2024 [Papier] [Code]
- Modélisation du langage à long terme avec codage de contexte parallèle, Arxiv, 2024 [Papier] [Code]
- Polant de 4k à 400k: étendant le contexte de LLM avec une balise d'activation, Arxiv, 2024 [Papier] [Code]
- Llm peut-être longlm: fenêtre de contexte LLM auto-atext sans réglage, Arxiv, 2024 [Papier] [Code]
- Extension de la fenêtre de contexte de grands modèles de langue via la compression sémantique, Arxiv, 2023 [Papier]
- Des modèles de langage de streaming efficaces avec des puits d'attention, Arxiv, 2023 [Papier] [Code]
- Windows de contexte parallèle pour les modèles de grande langue, ACL, 2023 [Papier] [Code]
- Longnet: Échelle des transformateurs à 1 000 000 000 de jetons, Arxiv, 2023 [Papier] [Code]
- Compréhension efficace de texte à long terme avec des modèles de texte court, Tacl, 2023 [Papier] [Code]
Augmentation de la mémoire-rétractable
- Infllm: dévoiler la capacité intrinsèque des LLM pour comprendre les séquences extrêmement longues avec une mémoire sans formation, Arxiv, 2024 [Papier]
- Landmark Attention: Random-Access Infinite Context Length for Transformers, arXiv, 2023 [Paper] [Code]
- Augmenting Language Models with Long-Term Memory, NeurIPS, 2023 [Papier]
- Unlimiformer: Long-Range Transformers with Unlimited Length Input, NeurIPS, 2023 [Paper] [Code]
- Focused Transformer: Contrastive Training for Context Scaling, NeurIPS, 2023 [Paper] [Code]
- Retrieval meets Long Context Large Language Models, arXiv, 2023 [Papier]
- Memorizing Transformers, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
State Space Models
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [Papier]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [Papier]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [Papier]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [Papier]
- Block-State Transformers, NeurIPS, 2023 [Papier]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces, NeurIPS, 2022 [Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [Papier]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [Papier]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [Papier]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [Papier]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [Papier]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [Papier]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [Papier]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [Papier]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [Papier]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [Papier]
? Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [Papier]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [Papier]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [Papier]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [Papier]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [Papier]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [Papier]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [Papier]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [Papier]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [Papier]
Prompt Engineering
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [Papier]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [Papier]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [Papier]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [Papier]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [Papier]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [Papier]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [Papier]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [Papier]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [Papier]
- Learning to Reason with LLMs, Website, 2024 [Html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [Papier]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [Papier]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [Papier]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [Papier]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [Papier]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS, 2022 [Papier]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [Papier]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [Papier]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [Papier]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [Papier]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [Papier]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [Papier]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [Papier]
Prompt Generation
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [Papier]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [Papier]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [Papier]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 , [Papier]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [Papier]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [Papier]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [Papier]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [Papier]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [Papier]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [Papier]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [Papier]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [Papier]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [Papier]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [Papier]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [Papier]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [Papier]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [Papier]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [Papier]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [Papier]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [Papier]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [Papier]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [Papier]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [Papier]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [Papier]
- Fairness in Serving Large Language Models, arXiv, 2023 [Papier]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [Papier]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS, 2022 [Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [Blog]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [Papier]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [Papier]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [Papier]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [Papier]
LLM Frameworks
| Efficient Training | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | ✅ | ✅ | ✅ |
| Megatron [Code] | ✅ | ✅ | ✅ |
| ColossalAI [Code] | ✅ | ✅ | ✅ |
| Nanotron [Code] | ✅ | ✅ | ✅ |
| MegaBlocks [Code] | ✅ | ✅ | ✅ |
| FairScale [Code] | ✅ | ✅ | ✅ |
| Pax [Code] | ✅ | ✅ | ✅ |
| Composer [Code] | ✅ | ✅ | ✅ |
| OpenLLM [Code] | | ✅ | ✅ |
| LLM-Foundry [Code] | | ✅ | ✅ |
| vLLM [Code] | | ✅ | |
| TensorRT-LLM [Code] | | ✅ | |
| TGI [Code] | | ✅ | |
| RayLLM [Code] | | ✅ | |
| MLC LLM [Code] | | ✅ | |
| Sax [Code] | | ✅ | |
| Mosec [Code] | | ✅ | |


