Эффективные крупные языковые модели: опрос
Эффективные крупные языковые модели: опрос [arxiv] (версия 1: 06/06/2023; версия 2: 23.02.2023; версия 3: 01.01.2024; версия 4: 23.05.2024, версия транзакций, готовая к камере, на исследовании машинного обучения)
Zhongwei Wan 1 , Xin Wang 1 , Che Liu 2 , Samiul Alam 1 , Yu Zheng 3 , Jiachen Liu 4 , Zhongnan Qu 5 , Shen Yan 6 , Yi Zhu 7 , Quanlu Zhang 8 , Mosharaf Chowdhury 4 , Mi Zhang 1
1 Университет штата Огайо, 2 Имперский колледж Лондон, 3 Мичиганского государственного университета, 4 Университета Мичигана, 5 Amazon AWS AI, 6 Google Research, 7 бозон AI, 8 Microsoft Research Asia
⚡News: Наш опрос был официально принят транзакциями по исследованиям машинного обучения (TMLR), май 2024 г.. Версия готовой к камере доступна по адресу: [OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
❤ поддержка сообщества
Этот репозиторий поддерживается Туидан ([email protected]), Способность ([email protected]), SAMIUL272 ([email protected]) и Ми-Зхан ([email protected]). Мы приветствуем обратную связь, предложения и вклады, которые могут помочь улучшить этот опрос и хранилище, чтобы сделать их ценными ресурсами в пользу всего сообщества.
Мы будем активно поддерживать этот репозиторий, включив новые исследования по мере его появления. Если у вас есть какие -либо предложения, касающиеся нашей таксономии, найдите какие -либо пропущенные документы или обновите любую бумагу Arxiv Preprint, которая была принята на какое -то место, не стесняйтесь отправлять нам электронное письмо или отправить запрос на привлечение, используя следующий формат отметки.
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
? О чем этот опрос?
Большие языковые модели (LLM) продемонстрировали замечательные возможности во многих важных задачах и могут оказать существенное влияние на наше общество. Такие возможности, однако, имеют значительные требования к ресурсам, подчеркивая сильную необходимость разработки эффективных методов решения проблем эффективности, связанных с LLMS. В этом опросе мы предоставляем систематический и всесторонний обзор эффективных исследований LLMS. Мы организуем литературу в таксономии, состоящей из трех основных категорий, охватывающих различные, но взаимосвязанные эффективные темы LLMS с ориентированной на модель , ориентированной на данные и ориентированная на структуру перспективы соответственно. Мы надеемся, что наш опрос и этот репозиторий GitHub могут служить ценными ресурсами, чтобы помочь исследователям и практикующим лицам получить систематическое понимание исследований в области эффективных LLMS и вдохновлять их на эту важную и захватывающую область.
? Почему эффективные LLMS нужны?
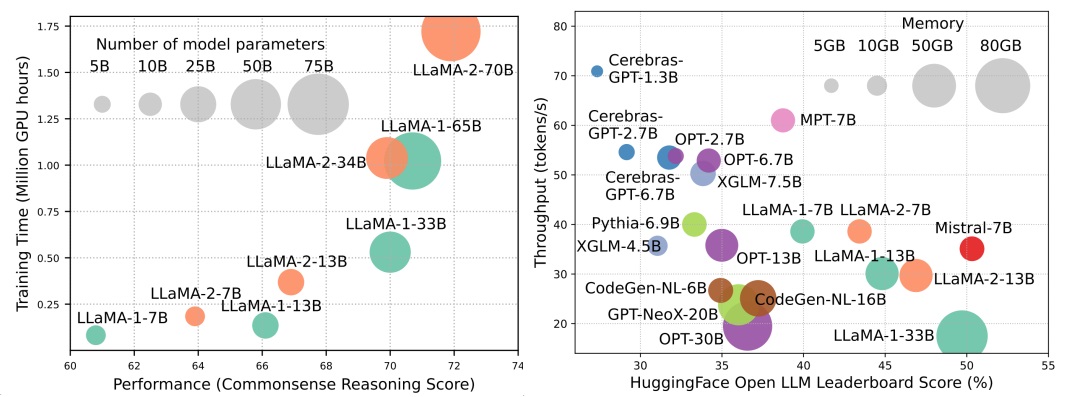
Хотя LLMs возглавляют следующую волну революции ИИ, замечательные возможности LLMS приходят за счет их существенных требований к ресурсам. Рисунок 1 (слева) иллюстрирует взаимосвязь между производительностью модели и временем обучения модели с точки зрения графических часов для серии Llama, где размер каждого круга пропорционален количеству параметров модели. Как показано, хотя более крупные модели способны достичь лучшей производительности, количество часов GPU, используемых для их обучения в геометрической прогрессии, растут по мере увеличения размеров моделей. В дополнение к обучению, вывод также вносит значительный вклад в эксплуатационную стоимость LLMS. На рисунке 2 (справа) изображена взаимосвязь между производительности модели и пропускной способностью вывода. Аналогичным образом, масштабирование размера модели обеспечивает повышение производительности, но по сравнению с пропускной способностью более низкой пропускной способности (более высокая задержка вывода), представляя проблемы для этих моделей при расширении их охвата до более широкой клиентской базы и разнообразных приложений экономически эффективным образом. Высокие потребности в ресурсах LLM подчеркивают сильную необходимость разработки методов для повышения эффективности LLMS. Как показано на рисунке 2, по сравнению с Llama-1-33B, Mistral-7B, которая использует внимание сгруппированного вопроса и внимание скользящего окна, чтобы ускорить вывод, достигает сопоставимой производительности и гораздо более высокой пропускной способности. Это превосходство подчеркивает осуществимость и значение разработки методов эффективности для LLMS.
Таблица контента
- ? Модельные методы
- Модель сжатия
- Квантование
- Квантование после тренировки
- Квантование только для веса
- Совместная активация веса
- Оценка квантования после тренировки
- Обучение квантованию
- Обрезка параметров
- Структурированная обрезка
- Неструктурированная обрезка
- Низкое приближение
- Знания дистилляция
- Белый короб Kd
- Черный бокс К.Д.
- Распределение параметров
- Эффективная предварительная тренировка
- Смешанная точная тренировка
- Масштабирование моделей
- Методы инициализации
- Оптимизаторы обучения
- Эффективная тонкая настройка
- Параметр эффективная тонкая настройка
- Настройка на основе адаптера
- Низкая адаптация
- Префикс настройка
- Быстрое настройка
- Эффективная точная настройка памяти
- MoE Efficifive контролируется тонкая настройка
- Эффективный вывод
- Параллельное декодирование
- Спекулятивное декодирование
- Оптимизация кв-кэша
- Эффективная архитектура
- Эффективное внимание
- Обмен внимания
- Снижение информации функции
- Ядра или низкий рейтинг
- Фиксированные стратегии шаблона
- Учебные стратегии шаблона
- Смесь экспертов
- LLMS на основе MOE
- Оптимизация MOE уровня алгоритма
- Long Context LLMS
- Экстраполяция и интерполяция
- Повторяющаяся структура
- Сегментация и скользящее окно
- Увеличение памяти
- Альтернативная архитектура трансформатора
- Государственные космические модели
- Другие последовательные модели
- ? Методы, ориентированные на данные
- Выбор данных
- Выбор данных для эффективного предварительного обучения
- Выбор данных для эффективной тонкой настройки
- Оперативная инженерия
- Несколько выстрелов
- Демонстрационная организация
- Демонстрационный выбор
- Демонстрационный заказ
- Форматирование шаблона
- Поколение инструкций
- Многоэтапные рассуждения
- Параллельное поколение
- Быстрое сжатие
- Быстрое поколение
- ? Оптимизация эффективности системы и рамки LLM
- Оптимизация эффективности системного уровня
- Оптимизация эффективности предварительного обучения на уровне системного уровня
- Оптимизация эффективности обслуживания системного уровня
- Проектирование системы обслуживания
- Оптимизация производительности обслуживания
- Алгоритм-хард-программный обеспечение
- LLM Frameworks
? Модельные методы
Модель сжатия
Квантование
Квантование после тренировки
Квантование только для веса
- I-LLM: эффективный вывод только для целочисленного только для полностью квалифицированных моделей с низким содержанием больших языков, Arxiv, 2024 [Бумага]
- IntactKV: улучшение квантования модели большой языка, сохраняя токены шар Arxiv, 2024 [Бумага]
- Всеобъемлющий: всемогущий: вседидиально калиброванное квантование для моделей крупных языков, ICLR, 2024 [Paper] [Код]
- Onebit: к очень низкому большим языковым моделям, Arxiv, 2024 [Бумага]
- GPTQ: точное квантование для генеративных предварительно обученных трансформаторов, ICLR, 2023 [Paper] [Код]
- QUIP: 2-битная квантование больших языковых моделей с гарантиями, Arxiv, 2023 [Paper] [Код]
- AWQ: квантование веса активации для сжатия и ускорения LLM, Arxiv, 2023 [Paper] [Код]
- OWQ: уроки, извлеченные из выбросов активации для квантования веса в моделях крупных языков, Arxiv, 2023 [Paper] [Код]
- SPQR: разреженное представление для сжатия веса LLM, почти без луча, Arxiv, 2023 [Paper] [Код]
- Finequant: эффективность разблокировки с мелкозернистым квантованием только для веса для LLM, Neurips-enlsp, 2023 [Бумага]
- Llm.int8 (): 8-битная матрица умножение для трансформаторов в масштабе, Neurelps, 2022 [Paper] [Код]
- Оптимальное сжатие мозга: структура для точного квантования после тренировки и обрезки, Neurips, 2022 [Paper] [Код]
- Количество: квантование на основе оптимизации для языковых моделей, Arxiv, 2023 [Paper] [Код]
Совместная активация веса
- Ротация и перестановка для продвинутого управления выбросами и эффективного квантования LLM, Neurips, 2024 [Бумага]
- Всеобъемлющий: всемогущий: вседидиально калиброванное квантование для моделей крупных языков, ICLR, 2024 [Paper] [Код]
- Интригующие свойства квантования в масштабе, Neurips, 2023 [Бумага]
- Zeroquant-V2: изучение квантования после тренировки в LLM от комплексного исследования до компенсации с низким рангом, Arxiv, 2023 [Paper] [Код]
- Zeroquant-FP: прыжок вперед в квантовании W4A8 LLMS с использованием форматов с плавающей точкой, Neurips-enlsp, 2023 [Paper] [Код]
- Оливковая: ускорение крупных языковых моделей с помощью квантования пары выбросов, а также для оборудования для оборудования для оборудования, ISCA, 2023 [Paper] [Код]
- RPTQ: пост-тренировочный квантизация на основе повторного заказа для моделей крупных языков, Arxiv, 2023 [Paper] [Код]
- Подавление выбросов+: точное квантование крупных языковых моделей путем эквивалентного и оптимального смещения и масштабирования, Arxiv, 2023 [Paper] [Код]
- QLLM: точное и эффективное квантование с низким содержанием прошивки для больших языковых моделей, Arxiv, 2023 [Бумага]
- Плавное: точное и эффективное пост-тренировочное квантование для крупных языковых моделей, ICML, 2023 [Paper] [Код]
- Zeroquant: эффективная и доступная пост-тренировочная квантование для крупномасштабных трансформаторов, Neurips, 2022 [Бумага]
Оценка квантования после тренировки
- Оценка квантованных крупных языковых моделей, Arxiv, 2024 [Бумага]
Обучение квантованию
- Эра 1-битного LLMS: все большие языковые модели находятся в 1,58 бит, Arxiv, 2024 [Бумага]
- FP8-LM: обучение на больших языковых моделях FP8, Arxiv, 2023 [Бумага]
- Обучение и вывод крупных языковых моделей с использованием 8-битной плавающей запятой, Arxiv, 2023 [Бумага]
- Bitnet: масштабирование 1-битных трансформаторов для больших языковых моделей, Arxiv, 2023 [Бумага]
- LLM-QAT: Обучение квантованию без данных для крупных языковых моделей, Arxiv, 2023 [Paper] [Код]
- Сжатие генеративных предварительно обученных языковых моделей посредством квантования, ACL, 2022 [Бумага]
Обрезка параметров
Структурированная обрезка
- Компактные языковые модели с помощью обрезки и дистилляции знаний, Arxiv, 2024 [Бумага]
- Более глубокий взгляд на обрезку LLMS, Arxiv, 2024 [Бумага]
- Озадачен недоумением: обрезка данных на основе недоумения с небольшими эталонными моделями, Arxiv, 2024 [Бумага]
- Plug-and-Play: эффективный метод пост-тренировки для больших языковых моделей, ICLR, 2024 [Бумага]
- Беса: обрезка больших языковых моделей с блокируемым параметром, эффективно распределение редкости, Arxiv, 2024 [Бумага]
- Shortgpt: слои в больших языковых моделях более избыточны, чем вы ожидаете, Arxiv, 2024 [Бумага]
- Nuteprune: эффективная прогрессивная обрезка с многочисленными учителями для крупных языковых моделей, Arxiv, 2024 [Бумага]
- Slicegpt: сжатие больших языковых моделей путем удаления рядов и столбцов, ICLR, 2024 [Paper] [Код]
- Lorashear: Эффективная модель крупной языковой модели структурированная обрезка и восстановление знаний, Arxiv, 2023 [Бумага]
- LLM-Pruner: О структурной обрезке крупных языковых моделей, Neurips, 2023 [Paper] [Код]
- Сдвиг лама: ускоряющая языковая модель предварительной тренировки через структурированную обрезку, Neurips-enlsp, 2023 [Paper] [Код]
- Loraprune: обрезка соответствует низководному параметрам-эффективному точной настройке, Arxiv, 2023 [Бумага]
Неструктурированная обрезка
- Maskllm: Learnable полуструктурированная разреженность для крупных языковых моделей, Nips, 2024 [Бумага]
- Dynamic Sparse No Training: бесплатная настраиваемая настройка для Sparse LLMS, ICLR, 2024 [Бумага]
- SPARSEGPT: массивные языковые модели могут быть точно обрезаны в одном выстреле, ICML, 2023 [Paper] [Код]
- Простой и эффективный подход обрезки для больших языковых моделей, Arxiv, 2023 [Paper] [Код]
- Одно выстрел с чувствительностью к чувствительности обрезка смешанного разреженности для больших языковых моделей, Arxiv, 2023 [Бумага]
Низкое приближение
- SVD-LLM: разложение единственного значения для сжатия модели большого языка, Arxiv, 2024 [Paper] [Код]
- ASVD: активация-активационная единичная стоимость разложения для сжатия крупных языковых моделей, Arxiv, 2023 [Paper] [Код]
- Языковая модель сжатие с взвешенной факторизацией с низким уровнем ранга, ICLR, 2022 [Бумага]
- Tensorgpt: эффективное сжатие встроенного слоя в LLM на основе разложения тензора, Arxiv, 2023 [Бумага]
- Losparse: Структурированное сжатие моделей крупных языков на основе низкодовольного и разреженного приближения, ICML, 2023 [Paper] [Код]
Знания дистилляция
Белый короб Kd
- DDK: Знание домены дистилляции для эффективных крупных языковых моделей Arxiv, 2024 [Бумага]
- Переосмысление дивергенции Kullback-Leibler в дистилляции знаний для крупных языковых моделей Arxiv, 2024 [Бумага]
- Distillm: к обтекаемой дистилляции для больших языковых моделей, Arxiv, 2024 [Paper] [Код]
- К закону разрыва в пропускной способности в дистилляционных языковых моделях, Arxiv, 2023 [Paper] [Код]
- Baby Llama: перегонка знаний от ансамбля учителей, обученных небольшому набору данных без штрафа за производительность, Arxiv, 2023 [Бумага]
- Знания дистилляция крупных языковых моделей, Arxiv, 2023 [Paper] [Код]
- GKD: Обобщенная дистилляция знаний для моделей авторегрессивных последовательностей, Arxiv, 2023 [Бумага]
- Распространять обновления знаний в LMS через дистилляцию, Arxiv, 2023 [Paper] [Код]
- Меньше больше: с учетом задачи по задаче дистилляции для сжатия языковой модели, ICML, 2023 [Бумага]
- Токеновая дистилляция логита для тройного веса генеративных языковых моделей, Arxiv, 2023 [Бумага]
Черный бокс К.Д.
- Зефир: Прямая перегонка выравнивания LM, Arxiv, 2023 [Бумага]
- Настройка инструкции с GPT-4, Arxiv, 2023 [Paper] [Код]
- Лев: состязательная дистилляция модели с крупной языком с закрытым исходным кодом, Arxiv, 2023 [Paper] [Код]
- Специализация меньших языковых моделей в направлении многоэтапных рассуждений, ICML, 2023 [Paper] [Код]
- Распределил шаг за шагом! Опережать более крупные языковые модели с меньшими учебными данными и меньшими размерами модели, ACL, 2023 [Бумага]
- Большие языковые модели рассуждают учителя, ACL, 2023 [Paper] [Код]
- Скотт: самосогласованная цепочка с размышлением, дистилляция, ACL, 2023 [Paper] [Код]
- Символическая цепь дистилляции: небольшие модели также могут «думать» пошаготь, ACL, 2023 [Бумага]
- Распределение распределения в более мелкие языковые модели, ACL, 2023 [Paper] [Код]
- Внутренняя дистилляция обучения: перенос нескольких выстрелов в обучении моделей с предварительно обученными языками, Arxiv, 2022 [Бумага]
- Объяснения из крупных языковых моделей улучшают небольшие рассуждения, лучше, Arxiv, 2022 [Бумага]
- Disco: дистилляция контрфактов с большими языковыми моделями, Arxiv, 2022 [Paper] [Код]
Обмен параметром
- Mobillama: к точному и легкому полностью прозрачному GPT, Arxiv, 2024 [Бумага]
Эффективная предварительная тренировка
Смешанная точная тренировка
- Обработка BFLOAT16 для нейронных сетей, Арит, 2019 [Бумага]
- Изучение BFLOAT16 для обучения глубокому обучению, Arxiv, 2019 [Бумага]
- Смешанная точная тренировка, ICLR, 2018 [Бумага]
Масштабирование моделей
- Лимон: расширение модели без потерь, ICLR, 2024 [Бумага]
- Подготовка уроков для прогрессивного обучения по языковым моделям, AAAI, 2024 [Бумага]
- Научиться выращивать предварительные модели для эффективного обучения трансформаторам, ICLR, 2023 [Paper] [Код]
- 2x быстрее языковая модель перед тренировкой с помощью структурного роста в масках, Arxiv, 2023 [Бумага]
- Повторное использование предварительно подготовленных моделей многолинейными операторами для эффективного обучения, Neurips, 2023 [Бумага]
- FLM-101B: открытый LLM и как тренировать его с бюджетом на 100 долларов США, Arxiv, 2023 [Paper] [Код]
- Занаждение знания для предварительно обученных языковых моделей, NAACL, 2022 [Paper] [Код]
- Поэтапно обучение для преобразовательных языковых моделей, ICML, 2022 [Paper] [Код]
Методы инициализации
- DeepNet: масштабирование трансформаторов до 1000 слоев, Arxiv, 2022 [Paper] [Код]
- Нулевая инициализация: инициализация нейронных сетей только с нулями и одному, TMLR, 2022 [Paper] [Код]
- Rezero - это все, что вам нужно: быстрая конвергенция на большей глубине, UAI, 2021 [Paper] [Код]
- Остаточные блоки нормализации пакетной нормализации в направлении функции идентификации в глубоких сетях, Neurips, 2020 [Бумага]
- Улучшение оптимизации трансформаторов за счет лучшей инициализации, ICML, 2020 [Paper] [Код]
- Инициализация фиксации: остаточное обучение без нормализации, ICLR, 2019 [Бумага]
- О инициализации веса в глубоких нейронных сетях, Arxiv, 2017 [Бумага]
Оптимизаторы обучения
- К оптимальному изучению языковых моделей, Arxiv, 2024 [Paper] [Код]
- Символическое обнаружение алгоритмов оптимизации, Arxiv, 2023 [Бумага]
- София: масштабируемый стохастический оптимизатор второго порядка для предварительной тренировки языка, Arxiv, 2023 [Paper] [Код]
Эффективная тонкая настройка
Параметр-эффективная тонкая настройка
Настройка на основе адаптера
- Opendelta: библиотека подключаемой и игры для адаптации параметров предварительно обученных моделей, ACL Demo, 2023 [Paper] [Код]
- Адаптеры LLM: семейство адаптеров для эффективной точной настройки крупных языковых моделей, EMNLP, 2023 [Paper] [Код]
- Компактер: эффективные слои гиперкомплекса с низким уровнем ранга, Neurips, 2023 [Paper] [Код]
- Несколько выстрелов, эффективная тонкая настройка лучше и дешевле, чем в контекстом обучении, Neurips, 2022 [Paper] [Код]
- Мета-адаптеры: эффективная параметром с небольшой настройкой через мета-обучение, Automl, 2022 [Бумага]
- Adamix: смеси адаптации для параметров-эффективной настройки модели, EMNLP, 2022 [Paper] [Код]
- Sparseadapter: простой подход к повышению эффективности параметров адаптеров, EMNLP, 2022 [Paper] [Код]
Низкая адаптация
- Hydralora: асимметричная архитектура Lora для эффективной тонкой настройки, Neurips, 2024 [Бумага]
- LOFIT: локализованная тонкая настройка на представлениях LLM, Arxiv, 2024 [Бумага]
- Смеси-предыдующие пространства в адаптации с низким уровнем ранга, Arxiv, 2024 [Paper] [Код]
- MEFT: эффективная настройка памяти через редкий адаптер, ACL, 2024 [Бумага]
- Лора встречает отсечение под унифицированным рамками, Arxiv, 2024 [Бумага]
- Звезда: ограничение LORA динамическим активным обучением для эффективной настройки больших языковых моделей, Arxiv, 2024 [Бумага]
- LORA+: Эффективная адаптация крупных моделей с низким рангом, Arxiv, 2024 [Бумага]
- LORA-FA: Эффективная память адаптация с низким уровнем ранга для крупных языковых моделей тонкая настройка, Arxiv, 2023 [Бумага]
- Lorahub: эффективное обобщение по перекрестной задаче через динамическую композицию Lora, Arxiv, 2023 [Paper] [Код]
- Longlora: эффективная тонкая настройка моделей больших языков с длинным контекстом, Arxiv, 2023 [Paper] [Код]
- Маршрутизация многопользовательской адаптер для обобщения по перекрестной задаче, Neurips, 2023 [Paper] [Код]
- Адаптивное распределение бюджета для эффективного настройки параметров, ICLR, 2023 [Бумага]
- Dylora: Параметр-эффективная настройка предварительных моделей с использованием динамической адаптации с низким рангом без поиска, EACL, 2023 [Paper] [Код]
- Tied-Lora: повышение эффективности параметров LORA с привязыванием веса, Arxiv, 2023 [Бумага]
- Лора: адаптация с низким уровнем моделей крупных языков, ICLR, 2022 [Paper] [Код]
Префикс настройка
- Лама-адаптер: эффективная тонкая настройка языковых моделей с нулевым вниманием, Arxiv, 2023 [Paper] [Код]
- Настройка префикса: оптимизация непрерывных подсказок для генерации ACL, 2021 [Paper] [Код]
Быстрое настройка
- Сжатие, затем быстро: повышение компромисса по эффективности точности вывода LLM с помощью переносимой подсказки, Arxiv, 2023 [Бумага]
- GPT тоже понимает, AI Open, 2023 [Paper] [Код]
- Многозадачное предварительное обучение модульной подсказки для нескольких выстрелов ACL, 2023 [Paper] [Код]
- Многозадачная настройка быстрого настройки обеспечивает эффективное переносное обучение. ICLR, 2023 [Бумага]
- PPT: предварительно обученная настройка для нескольких выстрелов, ACL, 2022 [Paper] [Код]
- Параметр-эффективная настройка быстрого приглашения делает обобщенные и калиброванные ретриверы нейронного текста, EMNLP-итоги, 2022 [Paper] [Код]
- P-tuning v2: быстрое настройка может быть сравнимой с универсальностью в масштабах и задачах ,. ACL-Short, 2022 [Paper] [Код]
- Мощность масштабирования для настройки параметров, настройка, EMNLP, 2021 [Бумага]
Эффективная память тонкая настройка
- Изучение оптимизации для тонкой настройки больших языковых моделей, arxiv, 2024/ins> [бумага]
- Sparse Matrix в большой языковой модели тонкая настройка, arxiv, 2024/ins> [бумага]
- В изобилии: эффективность памяти LLM тренинги с градиентной проекцией с низким уровнем ранга, arxiv, 2024/ins> [бумага]
- RefT: Prevation Panetuning для языковых моделей, arxiv, 2024/ins> [бумага]
- LISA: Выборочная выборка по значимости для значения для значительной памяти arxiv, 2024/ins> [бумага]
- Bitdelta: Ваша тонкая настройка может стоить всего лишь немного, arxiv, 2024/ins> [бумага]
- Выборка сборов столбцов с победителем-повествой для эффективной адаптации языковой модели памяти, Neurips, 2023 [Paper] [Код]
- Эффективная память селективная тонкая настройка, ICML Workshop, 2023 [Бумага]
- Полный параметр точная настройка для крупных языковых моделей с ограниченными ресурсами, Arxiv, 2023 [Paper] [Код]
- Тонкие языковые модели с прямыми проходами, Neurips, 2023 [Paper] [Код]
- Эффективная память тонкая настройка сжатых крупных языковых моделей с помощью суб-4-битного целочисленного квантования, Neurips, 2023 [Бумага]
- LOFTQ: квантование LORA-Fine-Tuning Aware для больших языковых моделей, Arxiv, 2023 [Paper] [Код]
- Qa-Lora: квантование с низкой адаптацией крупных языковых моделей, Arxiv, 2023 [Paper] [Код]
- Qlora: эффективное создание квантованных LLM, Neurips, 2023 [Paper] [code1] [code2]
Moeeffient-Supervised-Fine-Tuning
- Пусть эксперт придерживается его последнего: специализированная на экспертной настройке для редких архитектурных крупных языковых моделей, Arxiv, 2024 [Бумага]
Эффективный вывод
Параллельное декодирование
- CLLMS: консистенция больших языковых моделей, Arxiv, 2024 [Бумага]
- Кодировать один раз и декодировать параллельно: эффективное декодирование трансформатора, Arxiv, 2024 [Бумага]
Спекулятивное декодирование
- MagicDec: нарушение компромисса задержки для длительного генерации контекста со спекулятивным декодированием, Arxiv, 2024 [Бумага]
- Ловкость: декодирование с помощью привлечения флэш-деревье Arxiv, 2024 [Бумага]
- Layerskip: обеспечение раннего выхода и самовидно-спекулятивного декодирования, Arxiv, 2024 [Бумага]
- Triforce: без потерь ускорение генерации длинных последовательностей с иерархическим спекулятивным декодированием, Arxiv, 2024 [Бумага]
- Отдых: спекулятивное декодирование на основе поиска, Arxiv, 2024 [Бумага]
- Тандемные трансформаторы для вывода эффективного LLM, Arxiv, 2024 [Бумага]
- Проход: параллельная спекулятивная выборка, Neurips Workshop, 2023 [Бумага]
- Ускорение вывод трансформатора для перевода через параллельное декодирование, ACL, 2023 [Paper] [Код]
- Medusa: простая структура для ускорения генерации LLM с несколькими декодирующими головками, Блог, 2023 [Блог] [Код]
- Быстрый вывод от трансформаторов через спекулятивное декодирование, ICML, 2023 [Бумага]
- Ускорение вывода LLM с поставленным спекулятивным декодированием, ICML Workshop, 2023 [Бумага]
- Ускорение крупного языкового декодирования с помощью спекулятивной выборки, Arxiv, 2023 [Бумага]
- Спекулятивное декодирование с большим маленьким декодером, Neurips, 2023 [Paper] [Код]
- Specinfer: ускорение генеративного LLM служащего с спекулятивным выводом и проверкой дерева токенов, Arxiv, 2023 [Paper] [Код]
- Вывод со ссылкой: без потерь ускорение крупных языковых моделей, Arxiv, 2023 [Paper] [Код]
- Семя: ускоряющая конструкция дерева рассуждений с помощью запланированного спекулятивного декодирования, Arxiv, 2024 [Бумага]
Оптимизация кв-кэша
- VL-Cache: Sparsity и Modility Aware KV Cache Compression для вывода модели на языке зрительного языка Ускорение, Arxiv, 2024 [Бумага]
- Minference 1.0: ускорение предварительного заполнения для LLM с длинным контекстом через динамическое разреженное внимание, Arxiv, 2024 [Бумага]
- KVSharer: эффективный вывод через распределение в районе уровня KV Cache, Arxiv, 2024 [Бумага]
- Duoattention: эффективный вывод LLM с длинным контекстом с помощью поиска и потоковых голов, Arxiv, 2024 [Бумага]
- Lazyllm: динамическая обрезка токенов для эффективного длинного контекста LLM вывод, Arxiv, 2024 [Бумага]
- Палу: сжатие кв-кэша с низкой проекцией, Arxiv, 2024 [Paper] [Код]
- Look-M: Оптимизация смотрите в кэше KV для эффективного мультимодального вывода с длинным контекстом, Arxiv, 2024 [Бумага]
- D2O: динамические дискриминационные операции для эффективного генеративного вывода моделей крупных языков, Arxiv, 2024 [Бумага]
- Квест: Query Aware Sparsity для эффективного вывода LLM с длинным контекстом, ICML, 2024 [Бумага]
- Уменьшение размера кэша с ключами трансформатора с помощью кроссового внимания, Arxiv, 2024 [Бумага]
- Snapkv: LLM знает, что вы ищете до поколения, Arxiv, 2024 [Бумага]
- На основе якоря большие языковые модели, Arxiv, 2024 [Бумага]
- Kvquant: к 10 миллионам вывода длины контекста LLM с квантованием кэша KV, Arxiv, 2024 [Бумага]
- Передача: эффективный рецепт сжатия кэша кэша для генеративного вывода, почти без луча, LLM, Arxiv, 2024 [Бумага]
- Динамическое сжатие памяти: модернизация LLMS для ускоренного вывода, Arxiv, 2024 [Бумага]
- Не осталось токенов: надежное сжатие кэша KV через смешанную точную квантизация с точностью до важности, Arxiv, 2024 [Бумага]
- Получите больше с меньшим количеством: синтезирование рецидива с сжатием кэша KV для эффективного вывода LLM, Arxiv, 2024 [Бумага]
- WKVQUANT: квантование веса и кэш ключей/значения для моделей крупных языков приобретает больше, Arxiv, 2024 [Бумага]
- Об эффективности политики выселения для вывода модели с ограниченным генеративным языком, ограниченного генеративным языком, Arxiv, 2024 [Бумага]
- Kivi: асимметричное 2-битное квантование для кэша, без настройки, для кеша KV, Arxiv, 2024 [Paper] [Код]
- Модель рассказывает вам, что выбрать: адаптивное сжатие кэша кэша для LLMS, ICLR, 2024 [Бумага]
- SkipDecode: авторегрессивный декодирование скипа с помощью партии и кэширования для эффективного вывода LLM, Arxiv, 2023 [Бумага]
- H2O: Oracle с тяжелым нападающим для эффективного генеративного вывода крупных языковых моделей, Neurips, 2023 [Бумага]
- Ножницы: использование гипотезы о постоянстве важности для сжатия кэша LLM KV во время тестирования, Neurips, 2023 [Бумага]
- Динамическая обрезка контекста для эффективных и интерпретируемых авторегрессивных трансформаторов, Arxiv, 2023 [Бумага]
Эффективная архитектура
Эффективное внимание
Обмен внимания
- Лома: сжатая сжатая память Внимание, Arxiv, 2024 [Бумага]
- Mobilellm: оптимизация языковых моделей параметров на сумму Arxiv, 2024 [Бумага]
- GQA: Обучение обобщенных моделей многопрофильных трансформаторов с многоуровневых контрольных точек, EMNLP, 2023 [Бумага]
- Быстрое декодирование трансформатора: одна из них-это все, что вам нужно, Arxiv, 2019 [Бумага]
Снижение информации функции
- Nyströmformer: алгоритм на основе Nyström для аппроксимации самопринятия, AAAI, 2021 [Paper] [Код]
- Ворон-трансформатор: фильтрация последовательной избыточности для эффективной обработки языка, Neurips, 2020 [Paper] [Код]
- Set Transformer: основа для нейронных сетей, основанных на перзаскате, основанных на внимании, ICML, 2019 [Бумага]
Ядра или низкий рейтинг
- Локи: Низкие клавиши для эффективного разреженного внимания, ICML Workshop, 2023 [Бумага]
- Sumformer: универсальное приближение для эффективных трансформаторов, ICML Workshop, 2023 [Бумага]
- Flurka: Быстрое слитое внимание на низком уровне и ядра, Arxiv, 2023 [Бумага]
- ScatterBrain: объединение редкого и низкого внимания, Neurelps, 2021 [Paper] [Код]
- Переосмысливая внимание с исполнителями, ICLR, 2021 [Paper] [Код]
- Случайное внимание внимания, ICLR, 2021 [Бумага]
- Linformer: Самоубийство с линейной сложностью, Arxiv, 2020 [Paper] [Код]
- Легкий и эффективное распознавание речи с использованием трансформатора с низким уровнем ранга, ICASSP, 2020 [Бумага]
- Трансформеры - это RNN: быстрые авторегрессивные трансформаторы с линейным вниманием, ICML, 2020 [Paper] [Код]
Фиксированные стратегии шаблона
- Простые линейные языковые модели языка сбалансировки уравновешивают компромисс, пропускной способности, Arxiv, 2024 [Бумага]
- Lightning внимание-2: бесплатный обед для обработки неограниченной длины последовательностей в моделях больших языков, Arxiv, 2024 [Paper] [Код]
- Более быстрое причинно -следственное внимание к большим последовательностям с помощью редкого внимания, внимания, ICML Workshop, 2023 [Бумага]
- Публикация: длинное моделирование документов с помощью внимания, ICML, 2021 [Бумага]
- Большая птица: трансформаторы для более длинных последовательностей, Neurips, 2020 [Paper] [Код]
- Longformer: длинный документ трансформатор, Arxiv, 2020 [Paper] [Код]
- Блоковое самоуничтожение за длинное понимание документов, EMNLP, 2020 [Paper] [Код]
- Генерирование длинных последовательностей с редкими трансформаторами, Arxiv, 2019 [Бумага]
Учебные стратегии шаблона
- MOA: Смесь редкого внимания для автоматического сжатия модели с большой языком, Arxiv, 2024 [Бумага]
- Гиператция: внимание в длинном контере в почти линейное время, Arxiv, 2023 [Paper] [Код]
- Кластерформатор: нейронная кластеризация внимания для эффективного и эффективного трансформатора, ACL, 2022 [Бумага]
- Реформатор: Эффективный трансформатор, ICLR, 2022 [Paper] [Код]
- Редкое внимание удручения, ICML, 2020 [Бумага]
- Быстрые трансформаторы с кластерным вниманием, Neurips, 2020 [Paper] [Код]
- Эффективное разреженное внимание на основе контента с трансформаторами маршрутизации, Такл, 2020 [Paper] [Код]
Смесь экспертов
LLMS на основе MOE
- Самостоятельно: к композиционным большим языковым моделям с самоспециальными экспертами, Arxiv, 2024 [Бумага]
- Лори: Полностью дифференцируемая смеси экспертов для предварительной тренировки на авторегрессии языка, 2024 [Paper]
- Jetmoe: достижение производительности Llama2 с 0,1 млн долларов, 2024 [Paper]
- Эксперт стоит одного токена: синергирование нескольких экспертных LLM в качестве генералиста через маршрутизацию экспертов, 2024 [Paper]
- Смесь глубины: динамическое распределение вычислительных якосителей на основе трансформатора, 2024 [Paper]
- Mranch-Train-Mix: смешивание эксперта LLM в смеси Experts LLM, 2024 [Paper]
- Смеситель экспертов, Arxiv, 2024 [Paper] [Код]
- Мишстраль 7b, Arxiv, 2023 [Paper] [Код]
- Pangu-σ: к модели языка параметров триллиона с разреженными гетерогенными вычислениями, Arxiv, 2023 [Бумага]
- Трансформаторы переключения: масштабирование до моделей параметров триллиона с простой и эффективной разрешением, JMLR, 2022 [Paper] [Код]
- Эффективное крупномасштабное моделирование языка со смесями экспертов, EMNLP, 2022 [Paper] [Код]
- Базовые слои: упрощение тренировок крупных, редких моделей, ICML, 2021 [Paper] [Код]
- GSHARD: масштабирующие гигантские модели с условными вычислениями и автоматическим шардингом, ICLR, 2021 [Бумага]
Оптимизация MOE уровня алгоритма
- Seer-Moe: редкая экспертная эффективность посредством регуляризации для смеси экспертов, arxiv, 2024/ins> [бумага]
- Масштабирование законов для мелкозернистой смеси экспертов, arxiv, 2024/ins> [бумага]
- Язык на всю жизнь предварительно подготовлен с экспертами, специфичными для распределения, ICML, 2023 [Бумага]
- Смесь экспертов соответствует настройке инструкций: выигрышная комбинация для больших языковых моделей, Arxiv, 2023 [Бумага]
- Смеси экспертов с экспертным выбором маршрутизации, Neurips, 2022 [Бумага]
- StableMoe: стабильная стратегия маршрутизации для смешивания экспертов, ACL, 2022 [Paper] [Код]
- О крахе редкой смеси экспертов Neurips, 2022 [Бумага]
Long Context LLMS
Экстраполяция и интерполяция
- Два камня попали в одну птицу: двузначная позиционная кодирование для лучшей экстраполяции длины, ICML, 2024 [Бумага]
- ∞-Bench: расширение длинной оценки контекста за пределами 100K токенов, Arxiv, 2024 [Бумага]
- Резонансная веревка: улучшение контекста длина длина генерализации крупных языковых моделей, Arxiv, 2024 [Paper] [Код]
- Longrope: расширение окна контекста LLM за пределами 2 миллионов токенов, Arxiv, 2024 [Бумага]
- E^2-llm: эффективное и экстремальное расширение моделей крупных языков, Arxiv, 2024 [Бумага]
- Масштабирование законов экстраполяции на основе веревки, Arxiv, 2023 [Бумага]
- Экстраполютируемый трансформатор длиной, ACL, 2023 [Paper] [Код]
- Расширение контекстного окна крупных языковых моделей через позиционную интерполяцию, Arxiv, 2023 [Бумага]
- Ntk interpolation, Блог, 2023 [Reddit post]
- Пряжа: эффективное расширение окна контекста больших языковых моделей, Arxiv, 2023 [Paper] [Код]
- Clex: непрерывная длина экстраполяция для моделей крупных языков, Arxiv, 2023 [Paper] [Код]
- Поза: эффективное расширение окна контекста LLM с помощью позиционного обучения по пропуску, Arxiv, 2023 [Paper] [Код]
- Функциональная интерполяция для относительных положений улучшает длительные контекстные трансформаторы, Arxiv, 2023 [Бумага]
- Тренируйся короткий, тест долго: внимание с линейными смещениями обеспечивает экстраполяцию входной длины, ICLR, 2022 [Paper] [Код]
- Изучение обобщения длины в моделях крупных языков, Neurips, 2022 [Бумага]
Повторяющаяся структура
- Удерживающая сеть: преемник трансформатора для больших языковых моделей, Arxiv, 2023 [Paper] [Код]
- Повторяющийся трансформатор памяти, Neurips, 2022 [Paper] [Код]
- Трансформеры-блокировки, Neurips, 2022 [Paper] [Код]
- ∞-формамер: бесконечный трансформатор памяти, ACL, 2022 [Paper] [Код]
- Memformer: Abomented Memory Transformer для моделирования последовательности, AACL-сайты, 2020 [Paper] [Код]
- Transformer-XL: внимательные языковые модели за пределами контекста с фиксированной длиной, ACL, 2019 [Paper] [Код]
Сегментация и скользящее окно
- Xl3m: платформа без тренировок для расширения длины LLM на основе сегментных выводов, Arxiv, 2024 [Бумага]
- Transformerfam: Внимание обратной связи - это рабочая память, Arxiv, 2024 [Бумага]
- Наивное байесовское расширение контекста для больших языковых моделей, NAACL, 2024 [Бумага]
- Не оставлять контекста позади: эффективные бесконечные контекстные трансформеры с индивидуальным вниманием, Arxiv, 2024 [Бумага]
- Обучение LLMS над сжатым текстом, Arxiv, 2024 [Бумага]
- Инфинит LM: обобщение экстремальной длины с нулевой выстрелом для больших языковых моделей, Arxiv, 2024 [Бумага]
- Без тренировок бездействие с длинным контекстным масштабированием больших языковых моделей, Arxiv, 2024 [Paper] [Код]
- Моделирование языка с длинным контекстом с параллельным кодированием контекста, Arxiv, 2024 [Paper] [Код]
- Растет с 4K до 400K: расширение контекста LLM с помощью Activation Beacon, Arxiv, 2024 [Paper] [Код]
- LLM, может быть, Longlm: SelfExtend LLM Context Window без настройки, Arxiv, 2024 [Paper] [Код]
- Расширение окна контекста крупных языковых моделей через семантическое сжатие, Arxiv, 2023 [Бумага]
- Эффективные потоковые языковые модели с утоплениями внимания, Arxiv, 2023 [Paper] [Код]
- Параллельные контекст окна для больших языковых моделей, ACL, 2023 [Paper] [Код]
- Longnet: масштабирование трансформаторов до 1 000 000 000 токенов, Arxiv, 2023 [Paper] [Код]
- Эффективное давно текстовое понимание с короткими моделями, TACL, 2023 [Paper] [Код]
Увеличение памяти
- INFLLM: раскрыть внутреннюю способность LLMS для понимания чрезвычайно длинных последовательностей с воспоминаниями без тренировок, Arxiv, 2024 [Бумага]
- Landmark Attention: Random-Access Infinite Context Length for Transformers, arXiv, 2023 [Paper] [Code]
- Augmenting Language Models with Long-Term Memory, NeurIPS, 2023 [Бумага]
- Unlimiformer: Long-Range Transformers with Unlimited Length Input, NeurIPS, 2023 [Paper] [Code]
- Focused Transformer: Contrastive Training for Context Scaling, NeurIPS, 2023 [Paper] [Code]
- Retrieval meets Long Context Large Language Models, arXiv, 2023 [Бумага]
- Memorizing Transformers, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
State Space Models
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [Бумага]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [Бумага]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [Бумага]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [Бумага]
- Block-State Transformers, NeurIPS, 2023 [Бумага]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces, NeurIPS, 2022 [Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [Бумага]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [Бумага]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [Бумага]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [Бумага]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [Бумага]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [Бумага]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [Бумага]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [Бумага]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [Бумага]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [Бумага]
? Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [Бумага]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [Бумага]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [Бумага]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [Бумага]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [Бумага]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [Бумага]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [Бумага]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [Бумага]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [Бумага]
Prompt Engineering
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [Бумага]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [Бумага]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [Бумага]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [Бумага]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [Бумага]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [Бумага]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [Бумага]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [Бумага]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [Бумага]
- Learning to Reason with LLMs, Website, 2024 [Html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [Бумага]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [Бумага]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [Бумага]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [Бумага]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [Бумага]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS, 2022 [Бумага]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [Бумага]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [Бумага]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [Бумага]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [Бумага]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [Бумага]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [Бумага]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [Бумага]
Prompt Generation
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [Бумага]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [Бумага]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [Бумага]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 , [Бумага]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [Бумага]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [Бумага]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [Бумага]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [Бумага]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [Бумага]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [Бумага]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [Бумага]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [Бумага]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [Бумага]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [Бумага]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [Бумага]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [Бумага]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [Бумага]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [Бумага]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [Бумага]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [Бумага]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [Бумага]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [Бумага]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [Бумага]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [Бумага]
- Fairness in Serving Large Language Models, arXiv, 2023 [Бумага]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [Бумага]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS, 2022 [Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [Blog]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [Бумага]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [Бумага]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [Бумага]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [Бумага]
LLM Frameworks
| Efficient Training | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | ✅ | ✅ | ✅ |
| Megatron [Code] | ✅ | ✅ | ✅ |
| ColossalAI [Code] | ✅ | ✅ | ✅ |
| Nanotron [Code] | ✅ | ✅ | ✅ |
| MegaBlocks [Code] | ✅ | ✅ | ✅ |
| FairScale [Code] | ✅ | ✅ | ✅ |
| Pax [Code] | ✅ | ✅ | ✅ |
| Composer [Code] | ✅ | ✅ | ✅ |
| OpenLLM [Code] | | ✅ | ✅ |
| LLM-Foundry [Code] | | ✅ | ✅ |
| vLLM [Code] | | ✅ | |
| TensorRT-LLM [Code] | | ✅ | |
| TGI [Code] | | ✅ | |
| RayLLM [Code] | | ✅ | |
| MLC LLM [Code] | | ✅ | |
| Sax [Code] | | ✅ | |
| Mosec [Code] | | ✅ | |


