効率的な大規模な言語モデル:調査
効率的な大規模な言語モデル:調査[ARXIV](バージョン1:12/06/2023;バージョン2:12/23/2023;バージョン3:01/31/2024;バージョン4:05/23/2024、機械学習研究のトランザクションのカメラ対応バージョン)
Zhongwei Wan 1 、Xin Wang 1 、Che Liu 2 、Samiul Alam 1 、Yu Zheng 3 、Jiachen Liu 4 、Zhongnan Qu 5 、Shen Yan 6 、Yi Zhu 7 、Quanlu Zhang 8 、Mosharaf Chowdhury 4 、Mi Zhang 1
1オハイオ州立大学、 2インペリアルカレッジロンドン、 3ミシガン州立大学、 4ミシガン大学、 5 Amazon AWS AI、 6 Google Research、 7 Boson AI、 8 Microsoft Research Asia
News:私たちの調査は、2024年5月、機械学習研究(TMLR)のトランザクションによって正式に受け入れられました。
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
Community Support
このリポジトリは維持されますトゥイダン([email protected])、 Sustechbruce ([email protected])、 Samiul272 ([email protected])、およびMi-Zhang ([email protected])。この調査とリポジトリを改善して、コミュニティ全体に利益をもたらす貴重なリソースにするためのフィードバック、提案、貢献を歓迎します。
このリポジトリは、新しい研究が出現したときに積極的に維持します。当社の分類法に関する提案がある場合、見逃された論文を見つけたり、一部の会場に受け入れられたPreprint Arxivペーパーを更新したりする場合は、次のMarkdown形式を使用して電子メールを送信するか、プルリクエストを送信してください。
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
?この調査は何ですか?
大規模な言語モデル(LLM)は、多くの重要なタスクで顕著な能力を実証しており、私たちの社会に大きな影響を与える可能性があります。ただし、このような機能にはかなりのリソースの要求が伴い、LLMSによってもたらされる効率的な課題に対処するための効果的な技術を開発するための強いニーズを強調しています。この調査では、効率的なLLMS研究の体系的かつ包括的なレビューを提供します。私たちは、3つの主要なカテゴリで構成される分類法で文献を組織し、それぞれモデル中心、データ中心、およびフレームワーク中心の視点からの明確で相互接続された効率的なLLMSトピックをカバーしています。私たちの調査とこのGitHubリポジトリが、研究者と実践者が効率的なLLMの研究開発を体系的に理解し、この重要で刺激的な分野に貢献するように促すための貴重なリソースとして役立つことを願っています。
?なぜ効率的なLLMが必要なのですか?
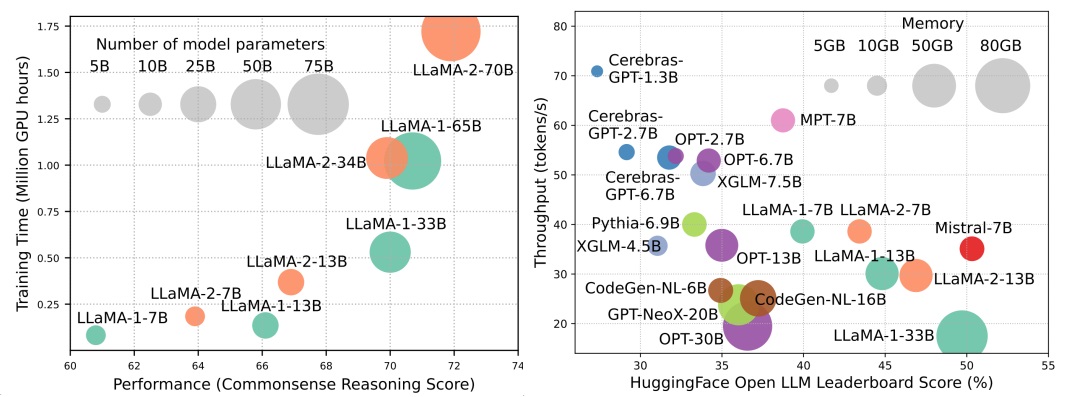
LLMはAI革命の次の波をリードしていますが、LLMの顕著な能力は、実質的なリソースの要求を犠牲にしてもたらされます。図1(左)は、各円のサイズがモデルパラメーターの数に比例するLlamaシリーズのGPU時間の観点から、モデルのパフォーマンスとモデルトレーニング時間の関係を示しています。示されているように、より大きなモデルはより良いパフォーマンスを実現することができますが、モデルサイズのスケールアップとしてトレーニングに使用されるGPU時間の量は指数関数的に成長します。トレーニングに加えて、推論はLLMSの運用コストにも大きく貢献します。図2(右)は、モデルのパフォーマンスと推論スループットの関係を示しています。同様に、モデルサイズをスケーリングすると、パフォーマンスが向上しますが、推論スループットの低下(より高い推論潜時)のコストが発生し、これらのモデルの範囲をより広範な顧客ベースに拡大し、費用対効果の高いアプリケーションを拡大する際に課題を提示します。 LLMSの高いリソース需要は、LLMSの効率を高めるための技術を開発する強いニーズを強調しています。図2に示すように、LLAMA-1-33Bと比較して、グループ化されたクエリの注意とスライドウィンドウの注意を使用して推論を高速化するMistral-7Bは、同等のパフォーマンスとはるかに高いスループットを達成します。この優位性は、LLMSの効率技術を設計することの実現可能性と重要性を強調しています。
コンテンツの表
- ?モデル中心の方法
- モデル圧縮
- 量子化
- トレーニング後の量子化
- 体重のみの量子化
- 重量活性化の共同定量化
- トレーニング後の量子化の評価
- 量子化対象トレーニング
- パラメーター剪定
- 低ランク近似
- 知識の蒸留
- パラメーター共有
- 効率的なトレーニング
- 混合精密トレーニング
- スケーリングモデル
- 初期化手法
- トレーニングオプティマイザー
- 効率的な微調整
- パラメーター効率的な微調整
- アダプターベースのチューニング
- 低ランクの適応
- プレフィックスチューニング
- 迅速なチューニング
- メモリ効率的な微調整
- MOE効率的な監視された微調整
- 効率的な推論
- 効率的なアーキテクチャ
- 効率的な注意
- 共有ベースの注意
- 機能情報削減
- カーネル化または低ランク
- パターン戦略を固定しました
- 学習可能なパターン戦略
- 専門家の混合
- MOEベースのLLMS
- アルゴリズムレベルのMOE最適化
- 長いコンテキストllms
- 外挿と補間
- 再発構造
- セグメンテーションとスライドウィンドウ
- 記憶網の増強
- トランスの代替アーキテクチャ
- ?データ中心の方法
- データ選択
- 効率的なトレーニングのためのデータ選択
- 効率的な微調整のためのデータ選択
- 迅速なエンジニアリング
- 少数のショットプロンプト
- デモンストレーション組織
- テンプレートのフォーマット
- プロンプト圧縮
- プロンプト生成
- ?システムレベルの効率の最適化とLLMフレームワーク
- システムレベルの効率最適化
- システムレベルのトレーニング効率の最適化
- システムレベルのサービス効率の最適化
- サービングシステム設計
- パフォーマンスの最適化を提供します
- アルゴリズムハードウェアの共同設計
- LLMフレームワーク
?モデル中心の方法
モデル圧縮
量子化
トレーニング後の量子化
体重のみの量子化
- I-llm:完全に定量化された低ビットの大手言語モデルに対する効率的な整数のみの推論、 Arxiv、2024 [紙]
- IntactKV:ピボットトークンをそのまま維持することにより、大規模な言語モデルの量子化を改善する、 Arxiv、2024 [紙]
- 概要:遍歴:大規模な言語モデルの全方向性校正量子化、 ICLR、2024 [紙] [コード]
- OneBit:非常に低いビットの大手言語モデルに向けて、 Arxiv、2024 [紙]
- GPTQ:生成事前に訓練された変圧器の正確な量子化、 ICLR、2023 [紙] [コード]
- QUIP:保証付きの大規模な言語モデルの2ビット量子化、 Arxiv、2023 [紙] [コード]
- AWQ:LLM圧縮と加速のためのアクティベーションアウェア重量量子化、 Arxiv、2023 [紙] [コード]
- OWQ:大規模な言語モデルでの重量量子化のための活性化外れ値から学んだ教訓、 Arxiv、2023 [紙] [コード]
- SPQR:losslessに近いLLM重量圧縮のためのまばらな定量化された表現、 Arxiv、2023 [紙] [コード]
- FineQuant:LLMSの細粒の体重のみの量子化を伴う効率のロック解除、 Neurips-enlsp、2023 [紙]
- llm.int8():大規模な変圧器の8ビットマトリックス乗算、 Neurlps、2022 [紙] [コード]
- 最適な脳圧縮:トレーニング後の正確な量子化と剪定のフレームワーク、ニューリップ、2022 [紙] [コード]
- Quantease:言語モデルの最適化ベースの量子化、 Arxiv、2023 [紙] [コード]
重量活性化の共同定量化
- 高度な外れ値管理とLLMの効率的な量子化の回転と順列、ニューリップ、2024年[紙]
- 概要:遍歴:大規模な言語モデルの全方向性校正量子化、 ICLR、2024 [紙] [コード]
- 大規模な量子化の興味深い特性、ニューリップス、2023年[紙]
- ZeroQuant-V2:包括的な研究から低ランク補償までのLLMSでのトレーニング後の量子化の調査、 Arxiv、2023 [紙] [コード]
- ZeroQuant-FP:トレーニング後のLLMSでの飛躍W4A8量子化フローティングポイント形式を使用した、 Neurips-enlsp、2023 [紙] [コード]
- Olive:ハードウェアに優しい外れ値とvictimペアの量子化を介して大規模な言語モデルを加速し、 ISCA、2023 [紙] [コード]
- RPTQ:大規模な言語モデルのための再注文ベースのトレーニング量子化、 Arxiv、2023 [紙] [コード]
- 異常値の抑制+:同等の最適なシフトとスケーリングによる大きな言語モデルの正確な量子化、 Arxiv、2023 [紙] [コード]
- QLLM:大規模な言語モデルの正確で効率的な低ビット幅の量子化、 Arxiv、2023 [紙]
- SmoothQuant:大規模な言語モデルのための正確で効率的なトレーニング後の量子化、 ICML、2023 [紙] [コード]
- ゼロクアント:大規模な変圧器のための効率的で手頃なトレーニング後の量子化、ニューリップ、2022 [紙]
トレーニング後の量子化の評価
- 量子化された大手言語モデルの評価、 Arxiv、2024 [紙]
量子化対象トレーニング
- 1ビットLLMSのERA:すべての大きな言語モデルは1.58ビットです、 Arxiv、2024 [紙]
- FP8-LM:トレーニングFP8大手言語モデル、 Arxiv、2023 [紙]
- 8ビットフローティングポイントを使用した大規模な言語モデルのトレーニングと推論、 Arxiv、2023 [紙]
- ビットネット:大規模な言語モデル用の1ビット変圧器のスケーリング、 Arxiv、2023 [紙]
- LLM-QAT:大規模な言語モデルのためのデータフリー量子化認識トレーニング、 Arxiv、2023 [紙] [コード]
- 量子化による生成事前訓練モデルの圧縮、 ACL、2022 [紙]
パラメーター剪定
構造化された剪定
- 剪定と知識の蒸留によるコンパクトな言語モデル、 Arxiv、2024 [紙]
- LLMSの深さの剪定をより深く見ると、 Arxiv、2024 [紙]
- 困惑した困惑:小さな参照モデルを備えた困惑ベースのデータ剪定、 Arxiv、2024 [紙]
- プラグアンドプレイ:大規模な言語モデル用の効率的なトレーニング後の剪定方法、 ICLR、2024 [紙]
- BESA:ブロックワイズパラメーター効率の高いスパースの割り当てを備えた大規模な言語モデルの剪定、 Arxiv、2024 [紙]
- Shortgpt:大きな言語モデルのレイヤーは、予想よりも冗長です、 Arxiv、2024 [紙]
- Nuteprune:大規模な言語モデルのために多数の教師との効率的なプログレッシブプルーニング、 Arxiv、2024 [紙]
- slicegpt:行と列を削除して、大きな言語モデルを圧縮し、 ICLR、2024 [紙] [コード]
- Lorashear:効率的な大手言語モデル構造化された剪定と知識回復、 Arxiv、2023 [紙]
- LLM-Pruner:大規模な言語モデルの構造的剪定について、ニューリップス、2023年[紙] [コード]
- せん断されたラマ:構造化された剪定を介して事前トレーニングを加速する言語モデル、 Neurips-enlsp、2023 [紙] [コード]
- loraprune:剪定は低ランクのパラメーター効率の高い微調整に出会う、 Arxiv、2023 [紙]
非構造化された剪定
- maskllm:大規模な言語モデルのために学習可能な半構造化されたスパースNIPS、2024 [紙]
- ダイナミックスパーストレーニングなし:スパースLLMのためのトレーニングフリーの微調整、 ICLR、2024 [紙]
- Sparsegpt:大規模な言語モデルは、ワンショットで正確に剪定できます。 ICML、2023 [紙] [コード]
- 大規模な言語モデルのためのシンプルで効果的な剪定アプローチ、 Arxiv、2023 [紙] [コード]
- 大規模な言語モデルのためのワンショット感度認識混合スパース剪定、 Arxiv、2023 [紙]
低ランク近似
- SVD-LLM:大規模な言語モデル圧縮のための単数値分解、 Arxiv、2024 [紙] [コード]
- ASVD:大規模な言語モデルを圧縮するためのアクティベーション認識の特異値分解、 Arxiv、2023 [紙] [コード]
- 重み付き低ランク因数分解による言語モデルの圧縮、 ICLR、2022 [紙]
- Tensorgpt:テンソルトレイン分解に基づくLLMSの埋め込み層の効率的な圧縮、 Arxiv、2023 [紙]
- Losparse:低ランクおよびスパース近似に基づいた大規模な言語モデルの構造的圧縮、 ICML、2023 [紙] [コード]
知識の蒸留
ホワイトボックスKD
- DDK:効率的な大型言語モデルのための蒸留ドメイン知識Arxiv、2024 [紙]
- 大規模な言語モデルの知識蒸留におけるKullback-Leiblerの発散を再考するArxiv、2024 [紙]
- 蒸留:大規模な言語モデルの合理化された蒸留に向けて、 Arxiv、2024 [紙] [コード]
- 言語モデルを蒸留する容量ギャップの法則に向けて、 Arxiv、2023 [紙] [コード]
- ベイビーラマ:パフォーマンスペナルティなしで小さなデータセットで訓練された教師のアンサンブルからの知識の蒸留、 Arxiv、2023 [紙]
- 大きな言語モデルの知識蒸留、 Arxiv、2023 [紙] [コード]
- GKD:自己回帰シーケンスモデルの一般化された知識蒸留、 Arxiv、2023 [紙]
- 蒸留によるLMSへの知識の更新を伝播する、 Arxiv、2023 [紙] [コード]
- 少ないです:言語モデルの圧縮のためのタスクに触れるレイヤーごとの蒸留、 ICML、2023 [紙]
- 三元重量生成言語モデルのトークンスケールロジット蒸留、 Arxiv、2023 [紙]
ブラックボックスKD
- Zephyr:LMアライメントの直接蒸留、 Arxiv、2023 [紙]
- GPT-4での指導チューニング、 Arxiv、2023 [紙] [コード]
- ライオン:クローズドソースの大規模な言語モデルの敵対的蒸留、 Arxiv、2023 [紙] [コード]
- 多段階の推論に向けて小言語モデルを専門とする、 ICML、2023 [紙] [コード]
- ステップバイステップを蒸留します!トレーニングデータが少なく、モデルサイズが小さく、より大きな言語モデルを上回り、 ACL、2023 [紙]
- 大規模な言語モデルは教師を推論しています、 ACL、2023 [紙] [コード]
- スコット:自己無意味なチェーンの蒸留、 ACL、2023 [紙] [コード]
- 象徴的な考え方の蒸留:小さなモデルは、段階的に「考える」こともできます。 ACL、2023 [紙]
- 推論能力をより小さな言語モデルに蒸留する、 ACL、2023 [紙] [コード]
- コンテキスト内学習蒸留:事前に訓練された言語モデルの少数の学習能力の転送、 Arxiv、2022 [紙]
- 大規模な言語モデルからの説明は、小さな推論をより良くします、 Arxiv、2022 [紙]
- ディスコ:大規模な言語モデルで反事実を蒸留する、 Arxiv、2022 [紙] [コード]
パラメーター共有
- Mobillama:正確で軽量の完全に透明なGPTに向けて、 Arxiv、2024 [紙]
効率的なトレーニング
混合精密トレーニング
- Neural NetworksのBFLOAT16処理、アリス、2019年[紙]
- 深い学習トレーニングのためのBFLOAT16の研究、 Arxiv、2019年[紙]
- 混合精密トレーニング、 ICLR、2018年[紙]
スケーリングモデル
- レモン:ロスレスモデルの拡張、 ICLR、2024 [紙]
- 言語モデルに関する進歩的なトレーニングのためのレッスンの準備、 AAAI、2024 [紙]
- 効率的な変圧器トレーニングのための前提型モデルを栽培することを学ぶ、 ICLR、2023 [紙] [コード]
- マスクされた構造成長を介した2倍高速な言語モデル事前トレーニング、 Arxiv、2023 [紙]
- 効率的なトレーニングのために、多系統演算子による事前処理モデルを再利用する、ニューリップス、2023年[紙]
- FLM-101B:オープンLLMと100ドルの予算で訓練する方法、 Arxiv、2023 [紙] [コード]
- 事前に訓練された言語モデルの知識継承、 NAACL、2022 [紙] [コード]
- トランス語モデルの段階的なトレーニング、 ICML、2022 [紙] [コード]
初期化手法
- ディープネット:トランスを1,000層にスケーリングし、 Arxiv、2022 [紙] [コード]
- ゼロ初期化:ゼロのみを使用したニューラルネットワークの初期化、 TMLR、2022 [紙] [コード]
- Rezeroはあなたが必要とするすべてです:大きな深さでの速い収束、 UAI、2021 [紙] [コード]
- バッチ正規化バイアスディープネットワークのアイデンティティ関数に向けて残差ブロックをバイアスします。ニューリップ、2020 [紙]
- より良い初期化による変圧器の最適化の改善、 ICML、2020 [紙] [コード]
- 修正初期化:正規化なしの残留学習、 ICLR、2019年[紙]
- 深いニューラルネットワークの重量初期化について、 Arxiv、2017年[紙]
トレーニングオプティマイザー
- 言語モデルの最適な学習に向けて、 Arxiv、2024 [紙] [コード]
- 最適化アルゴリズムの象徴的な発見、 Arxiv、2023 [紙]
- Sophia:言語モデルのトレーニング前のスケーラブルな確率的2次オプティマイザー、 Arxiv、2023 [紙] [コード]
効率的な微調整
パラメーター効率の高い微調整
アダプターベースのチューニング
- Opendelta:事前に訓練されたモデルのパラメーター効率の高い適応のためのプラグアンドプレイライブラリ、 ACLデモ、2023 [紙] [コード]
- LLM-Adapters:大規模な言語モデルのパラメーター効率の高い微調整のためのアダプターファミリ、 EMNLP、2023 [紙] [コード]
- コンパクター:効率的な低ランクハイパーコンプレックスアダプターレイヤー、ニューリップス、2023年[紙] [コード]
- 少ないショットパラメーター効率の高い微調整は、コンテキスト内学習よりも優れており、安価です。ニューリップ、2022 [紙] [コード]
- メタアダプター:メタラーニングを通じてパラメーター効率的な少数のショット微調整、 Automl、2022 [紙]
- Adamix:パラメーター効率の高いモデルチューニングのための適応の混合、 EMNLP、2022 [紙] [コード]
- Sparseadapter:アダプターのパラメーター効率を改善するための簡単なアプローチ、 EMNLP、2022 [紙] [コード]
低ランクの適応
- Hydralora:効率的な微調整のための非対称LORAアーキテクチャ、ニューリップ、2024年[紙]
- Lofit:LLM表現のローカライズされた微調整、 Arxiv、2024 [紙]
- 低ランクの適応における混合物の間スペース、 Arxiv、2024 [紙] [コード]
- Meft:まばらなアダプターを介したメモリ効率の高い微調整、 ACL、2024 [紙]
- ロラは統一されたフレームワークの下でドロップアウトに会います、 Arxiv、2024 [紙]
- 星:大規模な言語モデルのデータ効率の良い微調整のための動的アクティブ学習を備えた制約ロラ、 Arxiv、2024 [紙]
- LORA+:大規模なモデルの効率的な低ランク適応、 Arxiv、2024 [紙]
- LORA-FA:大規模な言語モデルのためのメモリ効率の高い低ランク適応微調整、 Arxiv、2023 [紙]
- Lorahub:ダイナミックロラ組成による効率的なクロスタスク一般化、 Arxiv、2023 [紙] [コード]
- Longlora:ロングコンテキストの大型言語モデルの効率的な微調整、 Arxiv、2023 [紙] [コード]
- クロスタスク一般化のためのマルチヘッドアダプタールーティング、ニューリップス、2023年[紙] [コード]
- パラメーター効率の高い微調整のための適応予算配分、 ICLR、2023 [紙]
- Dylora:動的な検索フリーの低ランク適応を使用した前提型モデルのパラメーター効率の高いチューニング、 EACL、2023 [紙] [コード]
- Tied-Lora:重量を結んでLORAのパラメーター効率を向上させる、 Arxiv、2023 [紙]
- LORA:大規模な言語モデルの低ランク適応、 ICLR、2022 [紙] [コード]
プレフィックスチューニング
- llama-adapter:関心がゼロの言語モデルの効率的な微調整、 Arxiv、2023 [紙] [コード]
- プレフィックス調整:生成の連続プロンプトの最適化ACL、2021 [紙] [コード]
迅速なチューニング
- 圧縮、プロンプト:転送可能なプロンプトを使用したLLM推論の精度効率のトレードオフの改善、 Arxiv、2023 [紙]
- GPTも理解していますAI Open、2023 [紙] [コード]
- 少数のショット学習のためのモジュラープロンプトのマルチタスク事前トレーニングACL、2023 [紙] [コード]
- マルチタスクプロンプトチューニングは、パラメーター効率の高い転送学習を可能にします。 ICLR、2023 [紙]
- PPT:いくつかのショット学習のための事前に訓練されたプロンプトチューニング、 ACL、2022 [紙] [コード]
- パラメーター効率の高いプロンプトチューニングにより、一般化および校正されたニューラルテキストレトリバーが作成されます。 emnlp-findings、2022 [紙] [コード]
- P-Tuning V2:迅速なチューニングは、スケールやタスク全体で普遍的に微調整することに匹敵する可能性があります。 ACL-Short、2022 [紙] [コード]
- パラメーター効率の高いプロンプトチューニングのスケールの力、 EMNLP、2021 [紙]
メモリ効率の高い微調整
- 大型言語モデルを微調整するための最適化の研究、 arxiv、2024/ins> [紙]
- 大規模な言語モデルの微調整のスパースマトリックス、 arxiv、2024/ins> [紙]
- Galore:グラデーション低ランク投影によるメモリ効率の高いLLMトレーニング、 arxiv、2024/ins> [紙]
- reft:言語モデルの表現微調整、 arxiv、2024/ins> [紙]
- リサ:メモリ効率の高い大手言語モデルの微調整のためのレイヤーワイズの重要性サンプリング、 arxiv、2024/ins> [紙]
- Bitdelta:微調整は少しだけの価値があるかもしれません、 arxiv、2024/ins> [紙]
- メモリのためのwinner-take-all-take-all列の行サンプリング言語モデルの効率的な適応、ニューリップス、2023年[紙] [コード]
- メモリ効率の高い選択的微調整、 ICMLワークショップ、2023年[紙]
- 限られたリソースを備えた大規模な言語モデル向けの完全なパラメーター微調整、 Arxiv、2023 [紙] [コード]
- ただフォワードパスを備えた微調整言語モデル、ニューリップス、2023年[紙] [コード]
- サブ4ビット整数量子化を介した圧縮された大型言語モデルのメモリ効率の高い微調整、ニューリップス、2023年[紙]
- LoftQ:大規模な言語モデルのためのロラファインチューニングアウェア量子化、 Arxiv、2023 [紙] [コード]
- QA-LORA:大規模な言語モデルの量子化 - 低ランク適応、 Arxiv、2023 [紙] [コード]
- Qlora:量子化されたLLMの効率的な微調整、ニューリップス、2023年[紙] [code1] [code2]
MOE効率の高い監視ファインチューニング
- 専門家が彼の最後に固執しましょう:まばらな建築の大手言語モデルのための専門的な専門の微調整、 Arxiv、2024 [紙]
効率的な推論
平行デコード
- CLLMS:一貫性の大きな言語モデル、 Arxiv、2024 [紙]
- 1回エンコードし、並行してデコードします:効率的なトランスデコード、 Arxiv、2024 [紙]
投機的デコード
- MagicDec:推測的なデコードで長いコンテキスト生成のためのレイテンシスループットのトレードオフを破る、 Arxiv、2024 [紙]
- deft:効率的なツリー構造LLM推論のためのフラッシュツリーアテンションによるデコード、 Arxiv、2024 [紙]
- layerskip:早期出口推論と自己識別デコードを有効にする、 Arxiv、2024 [紙]
- Triforce:階層的な投機的デコードを使用した長いシーケンス生成のロスレス加速度、 Arxiv、2024 [紙]
- 休憩:検索ベースの投機的デコード、 Arxiv、2024 [紙]
- 推論のためのタンデム変圧器、効率的なLLMS、 Arxiv、2024 [紙]
- パス:並列投機サンプリング、ニューリップスワークショップ、2023年[紙]
- 並列デコードを介した翻訳のための加速変圧器推論、 ACL、2023 [紙] [コード]
- Medusa:複数のデコードヘッドでLLM生成を加速するための簡単なフレームワーク、ブログ、2023 [ブログ] [コード]
- 投機的デコードを介したトランスからの高速推論、 ICML、2023 [紙]
- 段階的な投機的デコードによるLLM推論の加速、 ICMLワークショップ、2023年[紙]
- 投機的なサンプリングでデコードする大きな言語モデルの加速、 Arxiv、2023 [紙]
- 大きな小さなデコーダーでの投機的デコード、ニューリップス、2023年[紙] [コード]
- SpecInfer:投機的推論とトークンツリーの検証を備えた生成LLMの加速、 Arxiv、2023 [紙] [コード]
- 参照による推論:大規模な言語モデルのロスレス加速度、 Arxiv、2023 [紙] [コード]
- シード:スケジュールされた投機的デコードを介して、推論のツリー構造を加速し、 Arxiv、2024 [紙]
KVキャッシュの最適化
- VL-cache:視覚言語モデルの推論の加速のためのスパース性とモダリティアウェアKVキャッシュ圧縮、 Arxiv、2024 [紙]
- Minference 1.0:ダイナミックスパースの注意を介して、ロングコンテキストLLMの事前充填を加速、 Arxiv、2024 [紙]
- KVSharer:レイヤーごとの異なるKVキャッシュ共有を介した効率的な推論、 Arxiv、2024 [紙]
- DuoAttention:検索ヘッドとストリーミングヘッドを使用した効率的な長いコンテキストLLM推論、 Arxiv、2024 [紙]
- lazyllm:効率的な長いコンテキストLLM推論のためのダイナミックトークンプルーニング、 Arxiv、2024 [紙]
- Palu:低ランク投影でKVキャッシュを圧縮し、 Arxiv、2024 [紙] [コード]
- Look-M:効率的なマルチモーダルの長いコンテキスト推論のためのKVキャッシュのLook-Once Optimization、 Arxiv、2024 [紙]
- D2O:大規模な言語モデルの効率的な生成推論のための動的識別操作、 Arxiv、2024 [紙]
- クエスト:効率的な長いコンテキストLLM推論のためのクエリアウェアスパース、 ICML、2024 [紙]
- トランスのキー価値のキャッシュサイズを削減するクロス層の注意を払う、 Arxiv、2024 [紙]
- Snapkv:LLMは、世代前に探しているものを知っています、 Arxiv、2024 [紙]
- アンカーベースの大手言語モデル、 Arxiv、2024 [紙]
- KVQUANT:KVキャッシュ量子化による1,000万のコンテキスト長LLM推論に向けて、 Arxiv、2024 [紙]
- ギア:LLMの近くに紛れもない生成推論のための効率的なKVキャッシュ圧縮レシピ、 Arxiv、2024 [紙]
- 動的メモリ圧縮:加速された推論のためのLLMSを改造、 Arxiv、2024 [紙]
- 残されたトークンはありません:重要な認識された混合精度の量子化による信頼性の高いKVキャッシュ圧縮、 Arxiv、2024 [紙]
- より少ない量を得る:効率的なLLM推論のためにKVキャッシュ圧縮で再発を合成する、 Arxiv、2024 [紙]
- wkvquant:大規模な言語モデルの重量とキー/バリューキャッシュの量子化Arxiv、2024 [紙]
- キー値が制約された生成言語モデルの推論に対する立ち退きポリシーの有効性について、 Arxiv、2024 [紙]
- Kivi:KVキャッシュ用のチューニングフリーの非対称2ビット量子化、 Arxiv、2024 [紙] [コード]
- モデルは、何を破棄するかを教えてくれます:LLMSの適応KVキャッシュ圧縮、 ICLR、2024 [紙]
- SKIPDECODE:効率的なLLM推論のためにバッチとキャッシュを使用した自動脱着スキップデコード、 Arxiv、2023 [紙]
- H2O:大規模な言語モデルの効率的な生成的推論のためのヘビーヒッターのオラクル、ニューリップス、2023年[紙]
- SCISSORHANDS:テスト時にLLM KVキャッシュ圧縮の重要性仮説の持続性を活用する、ニューリップス、2023年[紙]
- 効率的で解釈可能な自動回帰トランスのための動的コンテキスト剪定、 Arxiv、2023 [紙]
効率的なアーキテクチャ
効率的な注意
共有ベースの注意
- ロマ:ロスレス圧縮メモリの注意、 Arxiv、2024 [紙]
- Mobilellm:デバイス上のユースケースのために、数十億ドルのパラメーター言語モデルを最適化する、 Arxiv、2024 [紙]
- GQA:マルチヘッドチェックポイントから一般化されたマルチクエリトランスモデルのトレーニング、 EMNLP、2023 [紙]
- 高速トランスデコード:1つの書き込みが必要です。 Arxiv、2019年[紙]
機能情報削減
- nyströmformer:自己告知を近似するためのNyströmベースのアルゴリズム、 AAAI、2021 [紙] [コード]
- ファンネル変換器:効率的な言語処理のためのシーケンシャルな冗長性をフィルタリングする、ニューリップ、2020 [紙] [コード]
- セットトランス:注意ベースの順列不変のニューラルネットワークのフレームワーク、 ICML、2019年[紙]
カーネル化または低ランク
- Loki:効率的なまばらな注意のための低ランクキー、 ICMLワークショップ、2023年[紙]
- Sumformer:効率的な変圧器のユニバーサル近似、 ICMLワークショップ、2023年[紙]
- Flurka:高速融合低ランクとカーネルの注意、 Arxiv、2023 [紙]
- ScatterBrain:まばらで低いランクの注意を統合する、 Neurlps、2021 [紙] [コード]
- パフォーマーとの注意を再考する、 ICLR、2021 [紙] [コード]
- ランダムな機能の注意、 ICLR、2021 [紙]
- Linformer:直線的な複雑さを伴う自己関節、 Arxiv、2020 [紙] [コード]
- 低ランク変圧器を使用した軽量で効率的なエンドツーエンドの音声認識、 ICASSP、2020 [紙]
- 変圧器はRNNSです:直線的な注意を払った高速オートレーフレフな変圧器、 ICML、2020 [紙] [コード]
パターン戦略を固定しました
- シンプルな線形注意言語モデルのバランスリコールスループットトレードオフ、 Arxiv、2024 [紙]
- Lightning Attention-2:大規模な言語モデルで無制限のシーケンス長を処理するための無料のランチ、 Arxiv、2024 [紙] [コード]
- まばらなフラッシュの注意を介した大きなシーケンスに対するより速い因果関係、 ICMLワークショップ、2023年[紙]
- プーリングフォーマー:プーリングの注意を払った長いドキュメントモデリング、 ICML、2021 [紙]
- 大きな鳥:長いシーケンスのためのトランスニューリップ、2020 [紙] [コード]
- Longformer:ロングドキュメントトランスArxiv、2020 [紙] [コード]
- 長い文書の理解のためのブロックワイズの自己関節、 EMNLP、2020 [紙] [コード]
- スパーストランスで長いシーケンスを生成し、 Arxiv、2019年[紙]
学習可能なパターン戦略
- MOA:自動大型言語モデルの圧縮のためのまばらな注意の混合、 Arxiv、2024 [紙]
- ハイパーアテナンス:近い時間における長いコンテキストの注意、 Arxiv、2023 [紙] [コード]
- クラスターフォーマー:効率的で効果的なトランスのためのニューラルクラスタリングの注意、 ACL、2022 [紙]
- 改革者:効率的な変圧器、 ICLR、2022 [紙] [コード]
- スパースシンクホーンの注意、 ICML、2020 [紙]
- クラスター化された注意を払った高速な変圧器、ニューリップ、2020 [紙] [コード]
- ルーティングトランスを使用した効率的なコンテンツベースのまばらな注意、 TACL、2020 [紙] [コード]
専門家の混合
MOEベースのLLMS
- セルフモー:自己専門の専門家を持つ作曲の大手言語モデルに向けて、 Arxiv、2024 [紙]
- Lory:自動再生言語モデルのための完全に微分可能な混合物、プリトレーニング、2024 [Paper]
- Jetmoe:0.1mドルでllama2パフォーマンスに到達する、2024 [紙]
- 専門家は1つのトークンの価値があります:複数の専門家LLMをエキスパートトークンルーティングを介してジェネラリストとして相乗的に、2024 [Paper]
- 詳細な混合:トランスベースの言語モデルでのコンピューティングを動的に割り当てる、2024 [Paper]
- Branch-Train-Mix:専門家LLMを混合物の混合LLMに混ぜ、2024 [Paper]
- 専門家のミックストラル、 Arxiv、2024 [紙] [コード]
- ミストラル7b、 Arxiv、2023 [紙] [コード]
- Pangu-σ:まばらな不均一なコンピューティングを備えた兆パラメーター言語モデルに向けて、 Arxiv、2023 [紙]
- スイッチトランス:シンプルで効率的なスパースを備えた兆パラメーターモデルへのスケーリング、 JMLR、2022 [紙] [コード]
- 専門家の混合物を使用した効率的な大規模な言語モデリング、 EMNLP、2022 [紙] [コード]
- 基本層:大規模でスパースモデルのトレーニングを簡素化する、 ICML、2021 [紙] [コード]
- GSHARD:条件付き計算と自動シャードを備えた巨大モデルのスケーリング、 ICLR、2021 [紙]
アルゴリズムレベルのMOE最適化
- Seer-Moe:専門家の混合物の正則化によるまばらな専門家の効率、 arxiv、2024/ins> [紙]
- 専門家のきめの細かい混合物のための法則のスケーリング、 arxiv、2024/ins> [紙]
- 分布専門家による生涯の言語前削除、 ICML、2023 [紙]
- 混合の専門家は指導の調整を満たしています:大規模な言語モデルの勝利の組み合わせ、 Arxiv、2023 [紙]
- 専門家の選択ルーティングを備えた専門家の混合物、ニューリップ、2022 [紙]
- Stablemoe:専門家の混合のための安定したルーティング戦略、 ACL、2022 [紙] [コード]
- 専門家のまばらな混合物の表現崩壊について、ニューリップ、2022 [紙]
長いコンテキストllms
外挿と補間
- 2つの石が1つの鳥に当たりました:より良い長さの外挿のための二重型位置エンコード、 ICML、2024 [紙]
- ∞ベンチ:長いコンテキスト評価を100kトークンを超えて拡張し、 Arxiv、2024 [紙]
- 共鳴ロープ:コンテキスト長の改善大規模な言語モデルの一般化、 Arxiv、2024 [紙] [コード]
- Longrope:LLMコンテキストウィンドウを200万トークンを超えて拡張し、 Arxiv、2024 [紙]
- e^2-llm:大規模な言語モデルの効率的で極端な長さの拡張、 Arxiv、2024 [紙]
- ロープベースの外挿の法則のスケーリング、 Arxiv、2023 [紙]
- 長さの抽出可能な変圧器、 ACL、2023 [紙] [コード]
- 位置の補間を介して、大きな言語モデルのコンテキストウィンドウを拡張し、 Arxiv、2023 [紙]
- NTK補間、ブログ、2023 [Reddit Post]
- 糸:大規模な言語モデルの効率的なコンテキストウィンドウ拡張、 Arxiv、2023 [紙] [コード]
- CLEX:大規模な言語モデルの連続長の外挿、 Arxiv、2023 [紙] [コード]
- ポーズ:ポジショナルスキップワイズトレーニングを介したLLMSの効率的なコンテキストウィンドウ拡張、 Arxiv、2023 [紙] [コード]
- 相対位置の機能的補間は、長いコンテキストトランスを改善し、 Arxiv、2023 [紙]
- 短いトレーニング、長いテスト:線形バイアスを使用した注意は、入力の長さの外挿を可能にし、 ICLR、2022 [紙] [コード]
- 大規模な言語モデルでの長さの一般化の調査、ニューリップ、2022 [紙]
再発構造
- 保持ネットワーク:大規模な言語モデルのためのトランスの後継者、 Arxiv、2023 [紙] [コード]
- 再発メモリトランス、ニューリップ、2022 [紙] [コード]
- ブロック再生トランスニューリップ、2022 [紙] [コード]
- ∞-フォーマー:無限のメモリトランスACL、2022 [紙] [コード]
- MEMFORMER:シーケンスモデリング用のメモリの高級変圧器、 Aacl-findings、2020 [紙] [コード]
- Transformer-XL:固定長のコンテキストを超えた丁寧な言語モデル、 ACL、2019年[紙] [コード]
セグメンテーションとスライドウィンドウ
- XL3M:セグメントごとの推論に基づくLLM長拡張のためのトレーニングフリーフレームワーク、 Arxiv、2024 [紙]
- トランスファム:フィードバックの注意はワーキングメモリです、 Arxiv、2024 [紙]
- 大規模な言語モデルの素朴なベイズベースのコンテキスト拡張、 NAACL、2024 [紙]
- コンテキストを残しないでください:無限の無限のコンテキストトランスArxiv、2024 [紙]
- Newally Pruspended Textを介したLLMSのトレーニング、 Arxiv、2024 [紙]
- LM-infinite:大規模な言語モデルのゼロショット極端な長さの一般化、 Arxiv、2024 [紙]
- 大規模な言語モデルのトレーニングなしの長いコンテキストスケーリング、 Arxiv、2024 [紙] [コード]
- 並列コンテキストエンコードを備えた長いコンテキスト言語モデリング、 Arxiv、2024 [紙] [コード]
- 4Kから400Kまでの高騰:活性化ビーコンとのLLMのコンテキストを拡張し、 Arxiv、2024 [紙] [コード]
- LLM Muyce LongLM:チューニングせずにLLMコンテキストウィンドウを拡張する、 Arxiv、2024 [紙] [コード]
- セマンティック圧縮を介して、大きな言語モデルのコンテキストウィンドウを拡張し、 Arxiv、2023 [紙]
- 注意シンクを備えた効率的なストリーミング言語モデル、 Arxiv、2023 [紙] [コード]
- 大規模な言語モデルの並列コンテキストウィンドウ、 ACL、2023 [紙] [コード]
- Longnet:トランスを1,000,000,000トークンにスケーリングする、 Arxiv、2023 [紙] [コード]
- ショートテキストモデルを使用した効率的なロングテキストの理解、 TACL、2023 [紙] [コード]
記憶網の増強
- INFLLM:トレーニングなしのメモリを使用して非常に長いシーケンスを理解するためにLLMSの固有の能力を発表する、 Arxiv、2024 [紙]
- ランドマークの注意:変圧器のランダムアクセス無限コンテキスト長、 Arxiv、2023 [紙] [コード]
- 長期的なメモリで言語モデルを増強する、ニューリップス、2023年[紙]
- Unlimiformer: Long-Range Transformers with Unlimited Length Input, NeurIPS, 2023 [Paper] [Code]
- Focused Transformer: Contrastive Training for Context Scaling, NeurIPS, 2023 [Paper] [Code]
- Retrieval meets Long Context Large Language Models, arXiv, 2023 [紙]
- Memorizing Transformers, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
State Space Models
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [紙]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [紙]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [紙]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [紙]
- Block-State Transformers, NeurIPS, 2023 [紙]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces, NeurIPS, 2022 [Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [紙]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [紙]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [紙]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [紙]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [紙]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [紙]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [紙]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [紙]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [紙]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [紙]
? Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [紙]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [紙]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [紙]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [紙]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [紙]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [紙]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [紙]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [紙]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [紙]
迅速なエンジニアリング
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [紙]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [紙]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [紙]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [紙]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [紙]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [紙]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [紙]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [紙]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [紙]
- Learning to Reason with LLMs, Website, 2024 [Html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [紙]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [紙]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [紙]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [紙]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [紙]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS, 2022 [紙]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [紙]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [紙]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [紙]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [紙]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [紙]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [紙]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [紙]
プロンプト生成
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [紙]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [紙]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [紙]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 、 [紙]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [紙]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [紙]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [紙]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [紙]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [紙]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [紙]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [紙]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [紙]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [紙]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [紙]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [紙]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [紙]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [紙]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [紙]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [紙]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [紙]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [紙]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [紙]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [紙]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [紙]
- Fairness in Serving Large Language Models, arXiv, 2023 [紙]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [紙]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS, 2022 [Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [Blog]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [紙]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [紙]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [紙]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [紙]
LLM Frameworks
| Efficient Training | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | ✅ | ✅ | ✅ |
| Megatron [Code] | ✅ | ✅ | ✅ |
| ColossalAI [Code] | ✅ | ✅ | ✅ |
| Nanotron [Code] | ✅ | ✅ | ✅ |
| MegaBlocks [Code] | ✅ | ✅ | ✅ |
| FairScale [Code] | ✅ | ✅ | ✅ |
| Pax [Code] | ✅ | ✅ | ✅ |
| Composer [Code] | ✅ | ✅ | ✅ |
| OpenLLM [Code] | | ✅ | ✅ |
| LLM-Foundry [Code] | | ✅ | ✅ |
| vLLM [Code] | | ✅ | |
| TensorRT-LLM [Code] | | ✅ | |
| TGI [Code] | | ✅ | |
| RayLLM [Code] | | ✅ | |
| MLC LLM [Code] | | ✅ | |
| Sax [Code] | | ✅ | |
| Mosec [Code] | | ✅ | |


