Modelos de linguagem grandes eficientes: uma pesquisa
Modelos de idiomas grandes eficientes: uma pesquisa [arxiv] (versão 1: 12/06/2023; versão 2: 23/12/2023; versão 3: 31/01/2024; versão 4: 23/05/2024, versão pronta para câmera das transações sobre pesquisa de aprendizado de máquina)
Zhongwei Wan 1 , Xin Wang 1 , Che Liu 2 , Samiul Alam 1 , Yu Zheng 3 , Jiachen Liu 4 , Zhongnan Qu 5 , Shen Yan 6 , Yi Zhu 7 , Quanlu Zhang 8 , Mosharaf Chowdhury 4 , Mi Zhang 1
1 A Universidade Estadual de Ohio, 2 Imperial College London, 3 Michigan State University, 4 Universidade de Michigan, 5 Amazon AWS AI, 6 Google Research, 7 Boson AI, 8 Microsoft Research Asia
⚡news: Nossa pesquisa foi oficialmente aceita por transações sobre pesquisa de aprendizado de máquina (TMLR), maio de 2024. A versão pronta para a câmera está disponível em: [OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
❤️ Suporte da comunidade
Este repositório é mantido por Tuidan ([email protected]), Sustechbruce ([email protected]), Samiul272 ([email protected]) e Mi-Zhang ([email protected]). Congratulamo -nos com feedback, sugestões e contribuições que podem ajudar a melhorar esta pesquisa e repositório, a fim de torná -los recursos valiosos para beneficiar toda a comunidade.
Manteremos ativamente esse repositório incorporando novas pesquisas à medida que surgir. Se você tiver alguma sugestão sobre nossa taxonomia, encontre os documentos perdidos ou atualize qualquer documento ARXIV de pré -impressão que tenha sido aceito em algum local, fique à vontade para nos enviar um email ou enviar uma solicitação de tração usando o seguinte formato de marcação.
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
? Sobre o que é esta pesquisa?
Os grandes modelos de linguagem (LLMs) demonstraram capacidades notáveis em muitas tarefas importantes e têm o potencial de causar um impacto substancial em nossa sociedade. Tais recursos, no entanto, vêm com consideráveis demandas de recursos, destacando a forte necessidade de desenvolver técnicas eficazes para enfrentar os desafios de eficiência colocados pelo LLMS. Nesta pesquisa, fornecemos uma revisão sistemática e abrangente da pesquisa eficiente da LLMS. Organizamos a literatura em uma taxonomia que consiste em três categorias principais, cobrindo tópicos de LLMs eficientes distintos, porém interconectados, da perspectiva centrada no modelo , centrada em dados e centros de estrutura , respectivamente. Esperamos que nossa pesquisa e este repositório do GitHub possam servir como recursos valiosos para ajudar pesquisadores e profissionais a obter uma compreensão sistemática dos desenvolvimentos da pesquisa em LLMs eficientes e inspirá -los a contribuir para esse campo importante e emocionante.
? Por que são necessários LLMs eficientes?
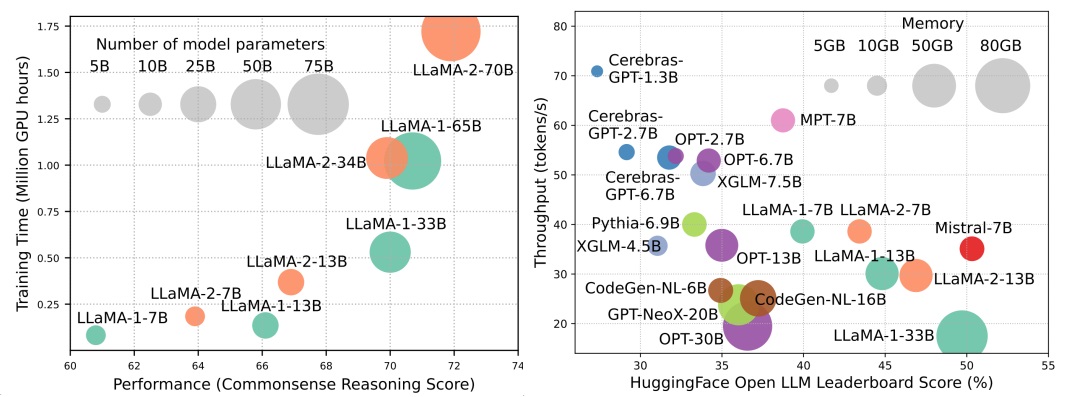
Embora os LLMs estejam liderando a próxima onda da revolução da IA, as notáveis capacidades do LLMS têm o custo de suas demandas substanciais de recursos. A Figura 1 (à esquerda) ilustra a relação entre o desempenho do modelo e o tempo de treinamento do modelo em termos de horas da GPU para a série LLAMA, onde o tamanho de cada círculo é proporcional ao número de parâmetros do modelo. Como mostrado, embora modelos maiores sejam capazes de obter um melhor desempenho, as quantidades das horas de GPU usadas para treiná -las crescem exponencialmente à medida que os tamanhos dos modelos aumentam. Além do treinamento, a inferência também contribui significativamente para o custo operacional do LLMS. A Figura 2 (à direita) descreve a relação entre o desempenho do modelo e a taxa de transferência de inferência. Da mesma forma, a ampliação do tamanho do modelo permite melhor desempenho, mas tem o custo de menor rendimento de inferência (maior latência de inferência), apresentando desafios para esses modelos na expansão de seu alcance para uma base de clientes mais ampla e diversas aplicações de maneira econômica. As altas demandas de recursos do LLMS destacam a forte necessidade de desenvolver técnicas para melhorar a eficiência do LLMS. Conforme mostrado na Figura 2, em comparação com a LLAMA-1-33B, Mistral-7b, que usa atenção em margem agrupada e atenção da janela deslizante para acelerar a inferência, atinge o desempenho comparável e o rendimento muito maior. Essa superioridade destaca a viabilidade e o significado do projeto de técnicas de eficiência para o LLMS.
Tabela de conteúdo
- ? Métodos centrados no modelo
- Modelo de compactação
- Quantização
- Quantização pós-treinamento
- Quantização somente de peso
- Co-montização de ativação de peso
- Avaliação da quantização pós-treinamento
- Treinamento com reconhecimento de quantização
- Poda de parâmetro
- Poda estruturada
- Poda não estruturada
- Aproximação de baixo rank
- Destilação do conhecimento
- Compartilhamento de parâmetros
- Pré-treinamento eficiente
- Treinamento de precisão mista
- Modelos de escala
- Técnicas de inicialização
- Otimizadores de treinamento
- Ajuste fino eficiente
- Parâmetro eficiente ajuste fino
- Ajuste baseado em adaptador
- Adaptação de baixo rank
- Ajuste prefixo
- Ajuste imediato
- Ajuste fino eficiente em memória
- MOE Eficiente supervisionou o ajuste fino
- Inferência eficiente
- Decodificação paralela
- Decodificação especulativa
- Otimização de cache KV
- Arquitetura eficiente
- Atenção eficiente
- Atenção baseada em compartilhamento
- Redução de informações sobre recursos
- Kernelização ou baixo rank
- Estratégias de padrões fixos
- Estratégias de padrões aprendidos
- Mistura de especialistas
- LLMS baseado em MOE
- Otimização de MOE no nível do algoritmo
- Long Context LLMS
- Extrapolação e interpolação
- Estrutura recorrente
- Segmentação e janela deslizante
- Aumentação para realidade com memória
- Arquitetura alternativa do transformador
- Modelos de espaço de estado
- Outros modelos seqüenciais
- ? Métodos centrados em dados
- Seleção de dados
- Seleção de dados para pré-treinamento eficiente
- Seleção de dados para ajustes finos eficientes
- Engenharia rápida
- Poucos pedidos de tiro
- Organização de demonstração
- Seleção de demonstração
- Pedido de demonstração
- Formatação de modelos
- Geração de instruções
- Raciocínio de várias etapas
- Geração paralela
- Compactação imediata
- Geração imediata
- Otimização de eficiência no nível do sistema e estruturas LLM
- Otimização de eficiência no nível do sistema
- Otimização de eficiência pré-treinamento no nível do sistema
- Otimização de eficiência no nível do sistema
- Design do sistema de servir
- Servindo otimização de desempenho
- Algoritmo-hardware Co-Design
- LLM Frameworks
? Métodos centrados no modelo
Modelo de compactação
Quantização
Quantização pós-treinamento
Quantização somente de peso
- I-llm: inferência eficiente apenas para modelos de linguagem de baixo bit de baixo bit, de baixo bit, Arxiv, 2024 [Papel]
- Intactkv: melhorando a quantização do modelo de grande linguagem, mantendo intactos os tokens de pivô, Arxiv, 2024 [Papel]
- Omniquante: Omniquante: Quantização onidirecionalmente calibrada para grandes modelos de linguagem, ICLR, 2024 [Papel] [Código]
- Onebit: em direção a modelos de linguagem grandes extremamente baixos, Arxiv, 2024 [Papel]
- GPTQ: quantização precisa para transformadores generativos pré-treinados, ICLR, 2023 [Papel] [Código]
- Quip: quantização de 2 bits de grandes modelos de linguagem com garantias, Arxiv, 2023 [Papel] [Código]
- AWQ: quantização de peso com consciência de ativação para compactação e aceleração de LLM, Arxiv, 2023 [Papel] [Código]
- OWQ: lições aprendidas com outliers de ativação para quantização de peso em grandes modelos de idiomas, Arxiv, 2023 [Papel] [Código]
- SPQR: Uma representação desconhecida para a compressão de peso LLM quase sem perdas, Arxiv, 2023 [Papel] [Código]
- Finequant: desbloquear eficiência com quantização apenas de peso de granulação para LLMS, Neurips-enlsp, 2023 [Papel]
- Llm.int8 (): multiplicação de matriz de 8 bits para transformadores em escala, Neurlps, 2022 [Papel] [Código]
- Compressão cerebral ideal: uma estrutura para quantização e poda precisas de treinamento pós-treinamento, Neurips, 2022 [Papel] [Código]
- Quantidade: quantização baseada em otimização para modelos de idiomas, Arxiv, 2023 [Papel] [Código]
Co-montização de ativação de peso
- Rotação e permutação para gerenciamento outlier avançado e quantização eficiente de LLMs, Neurips, 2024 [Papel]
- Omniquante: Omniquante: Quantização onidirecionalmente calibrada para grandes modelos de linguagem, ICLR, 2024 [Papel] [Código]
- Propriedades intrigantes de quantização em escala, Neurips, 2023 [Papel]
- ZeroQuant-V2: Explorando a quantização pós-treinamento em LLMs de estudo abrangente para compensação de baixa classificação, Arxiv, 2023 [Papel] [Código]
- Zeroquant-FP: um salto para a frente em LLMS pós-treinamento W4A8 Quantização usando formatos de ponto flutuante, Neurips-enlsp, 2023 [Papel] [Código]
- Azeite: acelerando grandes modelos de linguagem por meio de quantização de pares de vítimas outlier-victim, amigável para hardware, ISCA, 2023 [Papel] [Código]
- RPTQ: Quantização pós-treinamento baseada em reordenação para grandes modelos de idiomas, Arxiv, 2023 [Papel] [Código]
- Supressão externa+: quantização precisa de grandes modelos de linguagem por mudança e escala equivalentes e ótimas, Arxiv, 2023 [Papel] [Código]
- QLLM: quantização precisa e eficiente de baixa largura de bittwidth para grandes modelos de idiomas, Arxiv, 2023 [Papel]
- Smoothquant: quantização pós-treinamento precisa e eficiente para modelos de linguagem grandes, ICML, 2023 [Papel] [Código]
- Zeroquant: quantização pós-treinamento eficiente e acessível para transformadores em larga escala, Neurips, 2022 [Papel]
Avaliação da quantização pós-treinamento
- Avaliando modelos de linguagem quantizados grandes, Arxiv, 2024 [Papel]
Treinamento com reconhecimento de quantização
- A era dos LLMs de 1 bit: todos os grandes modelos de linguagem estão em 1,58 bits, Arxiv, 2024 [Papel]
- FP8-LM: Treinando FP8 grandes modelos de linguagem, Arxiv, 2023 [Papel]
- Treinamento e inferência de grandes modelos de linguagem usando ponto flutuante de 8 bits, Arxiv, 2023 [Papel]
- BitNet: dimensionar transformadores de 1 bit para grandes modelos de idiomas, Arxiv, 2023 [Papel]
- LLM-QAT: Treinamento consciente da quantização livre de dados para grandes modelos de idiomas, Arxiv, 2023 [Papel] [Código]
- Compressão de modelos generativos de linguagem pré-treinados via quantização, ACL, 2022 [Papel]
Poda de parâmetro
Poda estruturada
- Modelos de linguagem compactos por meio de poda e destilação de conhecimento, Arxiv, 2024 [Papel]
- Uma visão mais profunda da poda de profundidade do LLMS, Arxiv, 2024 [Papel]
- Perplexo pela perplexidade: dados de dados baseados em perplexidade com pequenos modelos de referência, Arxiv, 2024 [Papel]
- Plug-and-play: um método de poda pós-treinamento eficiente para grandes modelos de idiomas, ICLR, 2024 [Papel]
- BESA: podando grandes modelos de idiomas com alocação de escassez de parâmetro Blockwise, Blockwise, Arxiv, 2024 [Papel]
- Shortgpt: camadas em grandes modelos de linguagem são mais redundantes do que você espera, Arxiv, 2024 [Papel]
- NutePrune: poda progressiva eficiente com vários professores para grandes modelos de idiomas, Arxiv, 2024 [Papel]
- SliceGPT: comprime modelos de linguagem grandes excluindo linhas e colunas, ICLR, 2024 [Papel] [Código]
- Lorashear: Modelo de linguagem grande eficiente de poda estruturada e recuperação de conhecimento, Arxiv, 2023 [Papel]
- LLM-PRUNER: Sobre a poda estrutural de grandes modelos de linguagem, Neurips, 2023 [Papel] [Código]
- Lhama cisalhada: acelerando o modelo de idioma pré-treinamento por meio de poda estruturada, Neurips-enlsp, 2023 [Papel] [Código]
- Loraprune: A poda atende ao ajuste fino com eficiente de parâmetros de baixo rank, Arxiv, 2023 [Papel]
Poda não estruturada
- Maskllm: Sparsidade semiestruturada aprendida para grandes modelos de idiomas, Nips, 2024 [Papel]
- Dinâmico Sparso Sem Treinamento: Treinamento Free Tuning para Sparse LLMS, ICLR, 2024 [Papel]
- Sparsegpt: Modelos de linguagem maciços podem ser podados com precisão em um tiro, ICML, 2023 [Papel] [Código]
- Uma abordagem de poda simples e eficaz para grandes modelos de linguagem, Arxiv, 2023 [Papel] [Código]
- Aparação mista com sensibilidade de um tiro de uma poda mista para modelos de idiomas grandes, Arxiv, 2023 [Papel]
Aproximação de baixo rank
- SVD-LLM: decomposição de valor singular para grande compactação de modelos de idiomas, Arxiv, 2024 [Papel] [Código]
- ASVD: decomposição de valor singular com reconhecimento de ativação para compactar modelos de grandes linguagens, Arxiv, 2023 [Papel] [Código]
- Compressão do modelo de idioma com fatoração ponderada de baixa rank, ICLR, 2022 [Papel]
- Tensorgpt: Compressão eficiente da camada de incorporação no LLMS com base na decomposição do treino tensor Arxiv, 2023 [Papel]
- LOSPARSE: Compressão estruturada de grandes modelos de linguagem baseados em aproximação de baixo rank e escassa, ICML, 2023 [Papel] [Código]
Destilação do conhecimento
Branca KD
- DDK: Distilação do conhecimento do domínio para modelos de linguagem eficientes grandes Arxiv, 2024 [Papel]
- Repensando a divergência de Kullback-Leibler na destilação do conhecimento para grandes modelos de linguagem Arxiv, 2024 [Papel]
- Destillm: em direção à destilação simplificada para grandes modelos de linguagem, Arxiv, 2024 [Papel] [Código]
- Em direção à lei da lacuna de capacidade em destilar modelos de linguagem, Arxiv, 2023 [Papel] [Código]
- Baby Lhama: Destilação do Conhecimento de um conjunto de professores treinados em um pequeno conjunto de dados sem penalidade de desempenho, Arxiv, 2023 [Papel]
- Destilação de conhecimento de grandes modelos de linguagem, Arxiv, 2023 [Papel] [Código]
- GKD: Destilação generalizada de conhecimento para modelos de sequência auto-regressiva, Arxiv, 2023 [Papel]
- Propagando atualizações de conhecimento para o LMS através da destilação, Arxiv, 2023 [Papel] [Código]
- Menos é mais: destilação com conhecimento de tarefas de tarefas para compactação de modelos de idiomas, ICML, 2023 [Papel]
- Destilação de logit com escala de tokens para modelos de linguagem generativa de peso ternário, Arxiv, 2023 [Papel]
Black-Box KD
- Zephyr: destilação direta do alinhamento de LM, Arxiv, 2023 [Papel]
- Ajuste de instrução com GPT-4, Arxiv, 2023 [Papel] [Código]
- Leão: destilação adversária do modelo de linguagem grande de código fechado, Arxiv, 2023 [Papel] [Código]
- Especializando modelos de linguagem menores para raciocínio em várias etapas, ICML, 2023 [Papel] [Código]
- Destilando passo a passo! Superando modelos de linguagem maiores com menos dados de treinamento e tamanhos de modelo menores, ACL, 2023 [Papel]
- Modelos de idiomas grandes são professores de raciocínio, ACL, 2023 [Papel] [Código]
- Scott: Destilação da cadeia de pensamento autoconsistente, ACL, 2023 [Papel] [Código]
- Destilação simbólica da cadeia de pensamento: pequenos modelos também podem "pensar" passo a passo, ACL, 2023 [Papel]
- Destilar recursos de raciocínio em modelos de linguagem menores, ACL, 2023 [Papel] [Código]
- Destilação de aprendizagem no contexto: transferindo a capacidade de aprendizado de poucas fotos dos modelos de idiomas pré-treinados, Arxiv, 2022 [Papel]
- Explicações de grandes modelos de linguagem melhoram os pequenos motivos, Arxiv, 2022 [Papel]
- Disco: destilar contrafactuais com grandes modelos de linguagem, Arxiv, 2022 [Papel] [Código]
Compartilhamento de parâmetros
- Mobillama: Rumo ao GPT totalmente transparente, preciso e totalmente transparente, Arxiv, 2024 [Papel]
Pré-treinamento eficiente
Treinamento de precisão mista
- Processamento BFLOAT16 para redes neurais, Arith, 2019 [Papel]
- Um estudo do BFLOAT16 para treinamento de aprendizado profundo, Arxiv, 2019 [Papel]
- Treinamento de precisão mista, ICLR, 2018 [Papel]
Modelos de escala
- Limão: expansão do modelo sem perdas, ICLR, 2024 [Papel]
- Preparando lições para treinamento progressivo em modelos de idiomas, AAAI, 2024 [Papel]
- Aprendendo a cultivar modelos pré -traídos para treinamento eficiente de transformadores, ICLR, 2023 [Papel] [Código]
- 2x modelo de linguagem mais rápido pré-treinamento por meio de crescimento estrutural mascarado, Arxiv, 2023 [Papel]
- Reutilizando modelos pré-traidos por operadores multi-lineares para treinamento eficiente, Neurips, 2023 [Papel]
- FLM-101B: um LLM aberto e como treiná-lo com orçamento de US $ 100 K, Arxiv, 2023 [Papel] [Código]
- Herança de conhecimento para modelos de idiomas pré-treinados, Naacl, 2022 [Papel] [Código]
- Treinamento encenado para modelos de linguagem de transformadores, ICML, 2022 [Papel] [Código]
Técnicas de inicialização
- Deepnet: dimensionar transformadores para 1.000 camadas, Arxiv, 2022 [Papel] [Código]
- Inicialização zero: inicializando redes neurais apenas com zeros e outros, TMLR, 2022 [Papel] [Código]
- ReZero é tudo que você precisa: convergência rápida em grande parte, UAI, 2021 [Papel] [Código]
- A normalização do lote viés Neurips, 2020 [Papel]
- Melhorando a otimização do transformador por meio de melhor inicialização, ICML, 2020 [Papel] [Código]
- Fixup Inicialização: aprendizado residual sem normalização, ICLR, 2019 [Papel]
- Na inicialização do peso em redes neurais profundas, Arxiv, 2017 [Papel]
Otimizadores de treinamento
- Para o aprendizado ideal de modelos de linguagem, Arxiv, 2024 [Papel] [Código]
- Descoberta simbólica de algoritmos de otimização, Arxiv, 2023 [Papel]
- Sophia: um otimizador estocástico de segunda ordem escalável para pré-treinamento de modelos de idiomas, Arxiv, 2023 [Papel] [Código]
Ajuste fino eficiente
Ajuste fino com eficiência de parâmetro
Ajuste baseado em adaptador
- Opendelta: uma biblioteca plug-and-play para adaptação eficiente em parâmetro de modelos pré-treinados, Demoção da ACL, 2023 [Papel] [Código]
- LLM-AdApters: Uma família adaptadora para ajuste fino com eficiência de parâmetro de grandes modelos de idiomas, EMNLP, 2023 [Papel] [Código]
- Compacter: camadas de adaptadores de hipercomplex de baixo rank eficientes, Neurips, 2023 [Papel] [Código]
- A afinação com poucos eficientes de parâmetro é melhor e mais barata do que o aprendizado no contexto, Neurips, 2022 [Papel] [Código]
- Meta-adaptadores: Parâmetro eficiente de um ajuste de poucos tiro através de meta-aprendizagem, Automl, 2022 [Papel]
- Adamix: Mistura de adaptações para ajuste de modelo eficiente de parâmetro, EMNLP, 2022 [Papel] [Código]
- SparsAdapter: uma abordagem fácil para melhorar a eficiência de parâmetros dos adaptadores, EMNLP, 2022 [Papel] [Código]
Adaptação de baixo rank
- Hydralora: Uma arquitetura Lora assimétrica para ajustes finos eficientes, Neurips, 2024 [Papel]
- Lofit: ajuste fino localizado nas representações LLM, Arxiv, 2024 [Papel]
- Mistura de subspaces na adaptação de baixo rank, Arxiv, 2024 [Papel] [Código]
- Meft: ajuste fino com eficiência de memória através do adaptador esparso, ACL, 2024 [Papel]
- Lora encontra o abandono sob uma estrutura unificada, Arxiv, 2024 [Papel]
- Estrela: restrição Lora com aprendizado ativo dinâmico para ajuste fino com eficiência de dados de grandes modelos de linguagem, Arxiv, 2024 [Papel]
- Lora+: adaptação eficiente de baixa classificação de grandes modelos, Arxiv, 2024 [Papel]
- Lora-fa: adaptação de baixo rank com eficiência de memória para grandes modelos de idiomas, ajuste fino, Arxiv, 2023 [Papel]
- Lorahub: generalização eficiente de tarefas cruzadas por composição dinâmica de Lora, Arxiv, 2023 [Papel] [Código]
- LONGLORA: Ajuste fino eficiente de modelos de linguagem grande de longo contexto, Arxiv, 2023 [Papel] [Código]
- Roteamento de adaptadores de várias cabeças para generalização cruzada de tarefas, Neurips, 2023 [Papel] [Código]
- Alocação de orçamento adaptável para ajuste fino com eficiência de parâmetro, ICLR, 2023 [Papel]
- Dylora: ajuste com eficiência de parâmetros de modelos pré-tenhados usando adaptação dinâmica de baixa classificação, sem pesquisa, EACL, 2023 [Papel] [Código]
- Tied-Lora: Aprimorando a eficiência do parâmetro de Lora com empate de peso, Arxiv, 2023 [Papel]
- Lora: adaptação de baixo rank de grandes modelos de linguagem, ICLR, 2022 [Papel] [Código]
Ajuste prefixo
- Adapador de Lhama: ajuste fino eficiente de modelos de linguagem com atenção zero, Arxiv, 2023 [Papel] [Código]
- Tuneamento de prefixos: otimizando instruções contínuas para geração ACL, 2021 [Papel] [Código]
Ajuste imediato
- Compressa, depois Prompt: Melhorando a troca de eficiência da precisão da inferência de LLM com prompt transferível, Arxiv, 2023 [Papel]
- GPT entende também, AI Open, 2023 [Papel] [Código]
- Pré-treinamento com várias tarefas de prompt modular para aprendizado de poucos anos ACL, 2023 [Papel] [Código]
- O ajuste rápido de várias tarefas permite o aprendizado de transferência com eficiência de parâmetro, ICLR, 2023 [Papel]
- PPT: ajuste rápido pré-treinado para aprendizado de poucos anos, ACL, 2022 [Papel] [Código]
- O ajuste rápido com eficiência de parâmetro faz retrievers generalizados e calibrados de texto neural, EMNLP-INDINGS, 2022 [Papel] [Código]
- P-tuning v2: ajuste imediato pode ser comparável ao Finetuning universalmente em escalas e tarefas , ACL-Short, 2022 [Papel] [Código]
- O poder de escala para ajuste rápido com eficiência de parâmetro, EMNLP, 2021 [Papel]
Ajuste fino com economia de memória
- Um estudo de otimizações para modelos de linguagem de grande ajuste, Arxiv, 2024/ins> [papel]
- Matriz esparsa em grande modelo de linguagem, ajuste fino, Arxiv, 2024/ins> [papel]
- Galore: treinamento LLM com eficiência de memória por projeção de baixo rank de gradiente, Arxiv, 2024/ins> [papel]
- Reft: Representação Finetuning for Language Models, Arxiv, 2024/ins> [papel]
- Lisa: amostragem de importância em camadas para um modelo de linguagem de grande linguagem com eficiência de memória, ajuste fino, Arxiv, 2024/ins> [papel]
- Bitdelta: sua tune fine pode valer apenas um pouco, Arxiv, 2024/ins> [papel]
- Amostragem de linha de coluna de vencedor-Take-All para adaptação eficiente em memória do modelo de linguagem, Neurips, 2023 [Papel] [Código]
- Ajuste fino seletivo com eficiência de memória, Workshop ICML, 2023 [Papel]
- Parâmetro completo ajuste para modelos de idiomas grandes com recursos limitados, Arxiv, 2023 [Papel] [Código]
- Modelos de linguagem de ajuste fino com apenas passes para a frente, Neurips, 2023 [Papel] [Código]
- Ajuste fino com eficiência de memória de modelos de linguagem grande compactada via quantização inteira sub-4 bits, Neurips, 2023 [Papel]
- Loftq: quantização de consciência de Lora-Fine-Tuning para modelos de idiomas grandes, Arxiv, 2023 [Papel] [Código]
- QA-LORA: Adaptação de baixo rank de quantização de quantização de grandes modelos de linguagem, Arxiv, 2023 [Papel] [Código]
- Qlora: finetuning eficiente de LLMs quantizados, Neurips, 2023 [Paper] [Code1] [Code2]
MOE-Eficiente Supervisionado-Fine-Tuning
- Deixe o especialista seguir seu último: ajuste fino especializado em especialistas para modelos de grandes idiomas arquitetônicos esparsos, Arxiv, 2024 [Papel]
Inferência eficiente
Decodificação paralela
- CLLMS: Modelos de linguagem grande de consistência, Arxiv, 2024 [Papel]
- Codificar uma vez e decodificar em paralelo: decodificação eficiente do transformador, Arxiv, 2024 [Papel]
Decodificação especulativa
- MagicDec: quebrando a compensação de latência-tração para geração de contexto de longa data com decodificação especulativa, Arxiv, 2024 [Papel]
- Deft: Decodificação com atendimento de árvores Flash para inferência eficiente de LLM estruturada em árvores, Arxiv, 2024 [Papel]
- Layerskip: permitindo a inferência de saída precoce e decodificação auto-especulativa, Arxiv, 2024 [Papel]
- Triforce: aceleração sem perdas da geração de sequência longa com decodificação especulativa hierárquica, Arxiv, 2024 [Papel]
- REST: decodificação especulativa baseada em recuperação, Arxiv, 2024 [Papel]
- Transformadores em tandem para LLMs eficientes de inferência, Arxiv, 2024 [Papel]
- Passagem: amostragem especulativa paralela, Neurips Workshop, 2023 [Papel]
- Acelerando a inferência do transformador pela tradução via decodificação paralela, ACL, 2023 [Papel] [Código]
- Medusa: estrutura simples para acelerar a geração LLM com várias cabeças de decodificação, Blog, 2023 [Blog] [código]
- Inferência rápida dos transformadores por meio de decodificação especulativa, ICML, 2023 [Papel]
- Acelerar a inferência LLM com decodificação especulativa em fase, Workshop ICML, 2023 [Papel]
- Acelerar o grande modelo de linguagem decodificação com amostragem especulativa, Arxiv, 2023 [Papel]
- Decodificação especulativa com grande decodificador, Neurips, 2023 [Papel] [Código]
- Especinfer: acelerando LLM generativo que serve com inferência especulativa e verificação de árvores de token, Arxiv, 2023 [Papel] [Código]
- Inferência com referência: aceleração sem perdas de grandes modelos de linguagem, Arxiv, 2023 [Papel] [Código]
- Semente: acelerando a construção de árvores de raciocínio por meio de decodificação especulativa programada, Arxiv, 2024 [Papel]
Otimização de cache KV
- VL-cache: compactação de cache KV com reconhecimento de modalidade e modalidade para aceleração de inferência do modelo de linguagem de visão, Arxiv, 2024 [Papel]
- Minference 1.0: Acelerando o preenchimento de LLMs de longo contexto por meio de atenção escassa dinâmica, Arxiv, 2024 [Papel]
- Kvsharer: inferência eficiente por meio de compartilhamento de cache de KV diferente em camadas, Arxiv, 2024 [Papel]
- DUOATTENÇÃO: Inferência eficiente de longo contexto LLM nas cabeças de recuperação e streaming, Arxiv, 2024 [Papel]
- Lazyllm: poda de token dinâmica para uma inferência eficiente de contexto de longo prazo, Arxiv, 2024 [Papel]
- Palu: comprimindo KV-cache com projeção de baixo rank, Arxiv, 2024 [Papel] [Código]
- Look-M: Otimização de look-Once no cache KV para inferência multimodal eficiente de longo contexto, Arxiv, 2024 [Papel]
- D2O: Operações discriminativas dinâmicas para uma inferência generativa eficiente de grandes modelos de linguagem, Arxiv, 2024 [Papel]
- Quest: Sparsidade com reconhecimento de consulta para inferência eficiente de longo contexto LLM, ICML, 2024 [Papel]
- Reduzindo o tamanho do cache do valor-chave do transformador com atenção da camada cruzada, Arxiv, 2024 [Papel]
- Snapkv: LLM sabe o que você está procurando antes da geração, Arxiv, 2024 [Papel]
- Modelos de linguagem grande baseada em âncora, Arxiv, 2024 [Papel]
- Kvquant: em direção a 10 milhões de comprimento de contexto LLM Inferência na quantização de cache de kv, Arxiv, 2024 [Papel]
- Engrenagem: uma receita eficiente de compressão de cache KV para inferência generativa quase sem perda de LLM, Arxiv, 2024 [Papel]
- Compressão de memória dinâmica: retrofitting llms para inferência acelerada, Arxiv, 2024 [Papel]
- Sem token deixado para trás: Compressão confiável de cache de kv por meio de quantização de precisão mista com conhecimento de importância, Arxiv, 2024 [Papel]
- Obtenha mais com menos: sintetizando a recorrência com compactação de cache KV para inferência eficiente de LLM, Arxiv, 2024 [Papel]
- WKVQUANT: Quantizando peso e cache de chave/valor para grandes modelos de linguagem ganha mais, Arxiv, 2024 [Papel]
- Sobre a eficácia da política de despejo para a inferência generativa de modelo de linguagem generativa de valor-chave, Arxiv, 2024 [Papel]
- Kivi: uma quantização assimétrica de 2 bits sem ajuste para cache de kv, Arxiv, 2024 [Papel] [Código]
- Model diz o que descartar: compactação de cache de kv adaptável para LLMS, ICLR, 2024 [Papel]
- SkipDecode: decodificação autoregressiva de pular com lotes e cache para inferência eficiente de LLM, Arxiv, 2023 [Papel]
- H2O: Oracle de rebatedor pesado para uma inferência generativa eficiente de grandes modelos de linguagem, Neurips, 2023 [Papel]
- Scissorhands: explorando a persistência da hipótese de importância para a compactação de cache de LLM KV no momento do teste, Neurips, 2023 [Papel]
- Pruagem de contexto dinâmico para transformadores autoregressivos eficientes e interpretáveis, Arxiv, 2023 [Papel]
Arquitetura eficiente
Atenção eficiente
Atenção baseada em compartilhamento
- Loma: Atenção de memória compactada sem perdas, Arxiv, 2024 [Papel]
- MOBILELLM: Otimizando modelos de linguagem de parâmetros de sub-bilhões para casos de uso no dispositivo, Arxiv, 2024 [Papel]
- GQA: Treinando modelos generalizados de transformadores multi-query de pontos de verificação de várias cabeças, EMNLP, 2023 [Papel]
- Decodificação rápida do transformador: uma cabeça de gravação é tudo que você precisa, Arxiv, 2019 [Papel]
Redução de informações sobre recursos
- Nyströmformer: um algoritmo baseado em Nyström para aproxima-se da auto-distribuição, AAAI, 2021 [Papel] [Código]
- Funil-Transformer: filtrando redundância seqüencial para processamento de linguagem eficiente, Neurips, 2020 [Papel] [Código]
- Set Transformer: uma estrutura para redes neurais invariantes de permutação baseadas na atenção, ICML, 2019 [Papel]
Kernelização ou baixo rank
- Loki: teclas de baixo rank para atenção esparsa eficiente, Workshop ICML, 2023 [Papel]
- Sumformer: aproximação universal para transformadores eficientes, Workshop ICML, 2023 [Papel]
- Flurka: Atenção de baixo rank e kernel fundido rápido, Arxiv, 2023 [Papel]
- ScatterBrain: UNIFICAÇÃO SPAROS E BAIXA ATENÇÃO RANK, Neurlps, 2021 [Papel] [Código]
- Repensando a atenção com artistas, ICLR, 2021 [Papel] [Código]
- Atenção aleatória, atenção, ICLR, 2021 [Papel]
- Linformer: ATATENÇÃO COM COMPLEXIDADE LINEAR, Arxiv, 2020 [Papel] [Código]
- Reconhecimento de fala de ponta a ponta leve e eficiente usando o transformador de baixo rank, ICASSP, 2020 [Papel]
- Transformadores são RNNs: transformadores autorregressivos rápidos com atenção linear, ICML, 2020 [Papel] [Código]
Estratégias de padrões fixos
- Modelos de linguagem de atenção linear simples equilibram a troca de recall-troughput, Arxiv, 2024 [Papel]
- Lightning Atenção-2: um almoço grátis para lidar com comprimentos de sequência ilimitados em grandes modelos de idiomas, Arxiv, 2024 [Papel] [Código]
- Atenção causal mais rápida sobre grandes seqüências através da atenção esparsa do flash, Workshop ICML, 2023 [Papel]
- PoolingFormer: Modelagem de documentos longos com atenção, ICML, 2021 [Papel]
- Big Bird: Transformers para sequências mais longas, Neurips, 2020 [Papel] [Código]
- Longformer: o transformador de documentos de longa data, Arxiv, 2020 [Papel] [Código]
- Blockwise Auto-ATENÇÃO PARA UM LONGO DOCUMENTE EXPENHO, EMNLP, 2020 [Papel] [Código]
- Gerando sequências longas com transformadores esparsos, Arxiv, 2019 [Papel]
Estratégias de padrões aprendidos
- MOA: Mistura de atenção esparsa para compactação automática de modelos de linguagem grande, Arxiv, 2024 [Papel]
- HIPERATENTENTE: ATENÇÃO DO CONTEXO DE LONGO EM TEMPO PRÓXIMO Linear, Arxiv, 2023 [Papel] [Código]
- ClusterFormer: atenção de agrupamento neural para transformadores eficientes e eficazes, ACL, 2022 [Papel]
- Reformador: o transformador eficiente, ICLR, 2022 [Papel] [Código]
- Atenção esparsa de Sinkhorn, ICML, 2020 [Papel]
- Transformadores rápidos com atenção agrupada, Neurips, 2020 [Papel] [Código]
- Atenção esparsa e eficiente baseada em conteúdo com transformadores de roteamento, TACL, 2020 [Papel] [Código]
Mistura de especialistas
LLMS baseado em MOE
- Auto-MOE: em direção a modelos de linguagem grande composicional com especialistas auto-especializados, Arxiv, 2024 [Papel]
- Lory: Mistura de especialização totalmente diferenciável para o modelo de linguagem autoregressiva pré-treinamento, 2024 [Paper]
- Jetmoe: atingindo a apresentação do LLAMA2 com 0,1 milhão de dólares, 2024 [papel]
- Um especialista vale um token: sinergizando vários LLMs de especialistas como generalista por meio do roteamento de token de especialistas, 2024 [Paper]
- Mistura de profundidades: alocando dinamicamente a computação em modelos de idiomas baseados em transformadores, 2024 [papel]
- Ramo-Mix: Mixing Expert LLMs em uma mistura de especialistas LLM, 2024 [Paper]
- Mixtral de especialistas, Arxiv, 2024 [Papel] [Código]
- Mistral 7b, Arxiv, 2023 [Papel] [Código]
- Pangu-σ: Rumo a trilhão de linguagem de parâmetros Modelo de linguagem com computação heterogênea esparsa, Arxiv, 2023 [Papel]
- Transformadores de comutação: dimensionando para trilhões de modelos de parâmetros com escassez simples e eficiente, JMLR, 2022 [Papel] [Código]
- Modelagem de linguagem em larga escala eficiente com misturas de especialistas, EMNLP, 2022 [Papel] [Código]
- Camadas básicas: simplificando o treinamento de modelos grandes e esparsos, ICML, 2021 [Papel] [Código]
- GSHARD: Modelos gigantes de dimensionamento com computação condicional e sharding automático, ICLR, 2021 [Papel]
Otimização de MOE no nível do algoritmo
- Seer-MOE: Eficiência de especialista escassa por meio da regularização para mistura de especialistas, Arxiv, 2024/ins> [papel]
- Escala de leis para mistura de especialistas em grão fino, Arxiv, 2024/ins> [papel]
- Idioma ao longo da vida pré-treinamento com especialistas em especialização de distribuição, ICML, 2023 [Papel]
- A mistura de especialistas atende à sintonia de instruções: uma combinação vencedora para grandes modelos de idiomas, Arxiv, 2023 [Papel]
- Mistura de especialistas com roteamento de escolha de especialistas, Neurips, 2022 [Papel]
- StableMoe: estratégia de roteamento estável para mistura de especialistas, ACL, 2022 [Papel] [Código]
- No colapso da representação da mistura esparsa de especialistas, Neurips, 2022 [Papel]
Long Context LLMS
Extrapolação e interpolação
- Duas pedras atingem um pássaro: codificação posicional de bilevel para melhor extrapolação de comprimento, ICML, 2024 [Papel]
- ∞ banco: estendendo a avaliação de contexto longa além de 100 mil tokens, Arxiv, 2024 [Papel]
- Cupro de ressonância: melhorando a generalização do comprimento do contexto de grandes modelos de linguagem, Arxiv, 2024 [Papel] [Código]
- Longrope: estendendo a janela de contexto LLM além de 2 milhões de tokens, Arxiv, 2024 [Papel]
- E^2-llm: extensão de comprimento eficiente e extrema de grandes modelos de linguagem, Arxiv, 2024 [Papel]
- Escala leis de extrapolação baseada em corda, Arxiv, 2023 [Papel]
- Um transformador de comprimento extrapolável, ACL, 2023 [Papel] [Código]
- Estendendo a janela de contexto de grandes modelos de linguagem por meio de interpolação posicional, Arxiv, 2023 [Papel]
- Interpolação NTK, Blog, 2023 [Post Reddit]
- Fio: Extensão eficiente de janelas de contexto de grandes modelos de linguagem, Arxiv, 2023 [Papel] [Código]
- CLEX: extrapolação de comprimento contínuo para grandes modelos de linguagem, Arxiv, 2023 [Papel] [Código]
- Pose: Extensão eficiente da janela de contexto de LLMs por meio de treinamento posicional de pular pular, Arxiv, 2023 [Papel] [Código]
- Interpolação funcional para posições relativas melhora os transformadores de contexto longo, Arxiv, 2023 [Papel]
- Trem curto, teste longo: atenção com vieses lineares permite extrapolação de comprimento de entrada, ICLR, 2022 [Papel] [Código]
- Explorando generalização de comprimento em grandes modelos de idiomas, Neurips, 2022 [Papel]
Estrutura recorrente
- Rede retentiva: um sucessor de transformadores para grandes modelos de idiomas, Arxiv, 2023 [Papel] [Código]
- Transformador de memória recorrente, Neurips, 2022 [Papel] [Código]
- Transformadores-recorrentes de bloco, Neurips, 2022 [Papel] [Código]
- ∞-formador: Transformador de memória infinita, ACL, 2022 [Papel] [Código]
- Memformer: um transformador agitado de memória para modelagem de seqüências, AACL-INCILINGS, 2020 [Papel] [Código]
- Transformer-xl: modelos de idiomas atentos além de um contexto de comprimento fixo, ACL, 2019 [Papel] [Código]
Segmentação e janela deslizante
- XL3M: Uma estrutura sem treinamento para extensão de comprimento LLM com base na inferência no segmento, Arxiv, 2024 [Papel]
- Transformerfam: Atenção de feedback é a memória de trabalho, Arxiv, 2024 [Papel]
- Extensão de contexto baseada em Bayes ingênua para grandes modelos de linguagem, Naacl, 2024 [Papel]
- Não deixe o contexto para trás: transformadores de contexto infinitos eficientes com infini-atention, Arxiv, 2024 [Papel]
- Treinamento LLMS sobre texto comprimido neuralmente, Arxiv, 2024 [Papel]
- LM-Infinite: generalização de comprimento extremo zero para modelos de idiomas grandes, Arxiv, 2024 [Papel]
- Escala de longo contexto livre de treinamento de grandes modelos de linguagem, Arxiv, 2024 [Papel] [Código]
- Modelagem de idiomas de longo contexto com codificação de contexto paralelo, Arxiv, 2024 [Papel] [Código]
- Swearing de 4K a 400k: estendendo o contexto da LLM com o farol de ativação, Arxiv, 2024 [Papel] [Código]
- LLM talvez Longlm: Janela de contexto LLM Auto-Extend sem ajustar, Arxiv, 2024 [Papel] [Código]
- Estendendo a janela de contexto de grandes modelos de linguagem via compactação semântica, Arxiv, 2023 [Papel]
- Modelos de linguagem de streaming eficientes com afundamentos de atenção, Arxiv, 2023 [Papel] [Código]
- Janelas de contexto paralelo para grandes modelos de idiomas, ACL, 2023 [Papel] [Código]
- Longnet: dimensionar transformadores para 1.000.000.000 de tokens, Arxiv, 2023 [Papel] [Código]
- Entendimento de texto longo eficiente com modelos de texto curto, TACL, 2023 [Papel] [Código]
Aumentação para realidade com memória
- Infllm: revelando a capacidade intrínseca do LLMS para entender sequências extremamente longas com memória sem treinamento, Arxiv, 2024 [Papel]
- Landmark Attention: Random-Access Infinite Context Length for Transformers, arXiv, 2023 [Paper] [Code]
- Augmenting Language Models with Long-Term Memory, NeurIPS, 2023 [Papel]
- Unlimiformer: Long-Range Transformers with Unlimited Length Input, NeurIPS, 2023 [Paper] [Code]
- Focused Transformer: Contrastive Training for Context Scaling, NeurIPS, 2023 [Paper] [Code]
- Retrieval meets Long Context Large Language Models, arXiv, 2023 [Papel]
- Memorizing Transformers, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
State Space Models
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [Papel]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [Papel]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [Papel]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [Papel]
- Block-State Transformers, NeurIPS, 2023 [Papel]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces, NeurIPS, 2022 [Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [Papel]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [Papel]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [Papel]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [Papel]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [Papel]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [Papel]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [Papel]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [Papel]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [Papel]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [Papel]
? Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [Papel]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [Papel]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [Papel]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [Papel]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [Papel]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [Papel]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [Papel]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [Papel]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [Papel]
Prompt Engineering
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [Papel]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [Papel]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [Papel]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [Papel]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [Papel]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [Papel]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [Papel]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [Papel]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [Papel]
- Learning to Reason with LLMs, Website, 2024 [Html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [Papel]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [Papel]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [Papel]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [Papel]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [Papel]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS, 2022 [Papel]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [Papel]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [Papel]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [Papel]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [Papel]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [Papel]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [Papel]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [Papel]
Prompt Generation
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [Papel]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [Papel]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [Papel]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 , [Papel]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [Papel]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [Papel]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [Papel]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [Papel]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [Papel]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [Papel]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [Papel]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [Papel]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [Papel]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [Papel]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [Papel]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [Papel]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [Papel]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [Papel]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [Papel]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [Papel]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [Papel]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [Papel]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [Papel]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [Papel]
- Fairness in Serving Large Language Models, arXiv, 2023 [Papel]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [Papel]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS, 2022 [Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [Blog]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [Papel]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [Papel]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [Papel]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [Papel]
LLM Frameworks
| Efficient Training | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | ✅ | ✅ | ✅ |
| Megatron [Code] | ✅ | ✅ | ✅ |
| ColossalAI [Code] | ✅ | ✅ | ✅ |
| Nanotron [Code] | ✅ | ✅ | ✅ |
| MegaBlocks [Code] | ✅ | ✅ | ✅ |
| FairScale [Code] | ✅ | ✅ | ✅ |
| Pax [Code] | ✅ | ✅ | ✅ |
| Composer [Code] | ✅ | ✅ | ✅ |
| OpenLLM [Code] | | ✅ | ✅ |
| LLM-Foundry [Code] | | ✅ | ✅ |
| vLLM [Code] | | ✅ | |
| TensorRT-LLM [Code] | | ✅ | |
| TGI [Code] | | ✅ | |
| RayLLM [Code] | | ✅ | |
| MLC LLM [Code] | | ✅ | |
| Sax [Code] | | ✅ | |
| Mosec [Code] | | ✅ | |


