Modelos de idiomas grandes eficientes: una encuesta
Modelos de lenguaje grandes eficientes: una encuesta [ARXIV] (Versión 1: 2/06/2023; Versión 2: 23/12/2023; Versión 3: 21/01/2024; Versión 4: 23/05/2024, Versión de la cámara de transacciones en la investigación de aprendizaje automático)
Zhongwei Wan 1 , Xin Wang 1 , Che Liu 2 , Samiul Alam 1 , Yu Zheng 3 , Jiachen Liu 4 , Zhongnan Qu 5 , Shen Yan 6 , Yi Zhu 7 , Quanlu Zhang 8 , Mosharaf Chowdhury 4 , Mi Zhang 1
1 La Universidad Estatal de Ohio, 2 Imperial College London, 3 Michigan State University, 4 University of Michigan, 5 Amazon AWS AI, 6 Google Research, 7 Boson AI, 8 Microsoft Research Asia
⚡News: Nuestra encuesta ha sido aceptada oficialmente por Transactions on Machine Learning Research (TMLR), mayo de 2024. La versión lista para la cámara está disponible en: [OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
Soporte comunitario ❤️
Este repositorio se mantiene por tuidano ([email protected]), Sostenimiento ([email protected]), samiul272 ([email protected]), y mi-zhang ([email protected]). Agradecemos comentarios, sugerencias y contribuciones que pueden ayudar a mejorar esta encuesta y el repositorio para que los haga recursos valiosos para beneficiar a toda la comunidad.
Mantendremos activamente este repositorio incorporando una nueva investigación a medida que surja. Si tiene alguna sugerencia con respecto a nuestra taxonomía, encuentre los documentos perdidos o actualice cualquier artículo de prepins Arxiv que haya sido aceptado en algún lugar, no dude en enviarnos un correo electrónico o enviar una solicitud de extracción utilizando el siguiente formato de marca.
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
? ¿De qué es esta encuesta?
Los modelos de idiomas grandes (LLM) han demostrado capacidades notables en muchas tareas importantes y tienen el potencial de tener un impacto sustancial en nuestra sociedad. Sin embargo, tales capacidades vienen con considerables demandas de recursos, destacando la fuerte necesidad de desarrollar técnicas efectivas para abordar los desafíos de eficiencia planteados por LLMS. En esta encuesta, proporcionamos una revisión sistemática e integral de la investigación eficiente de LLMS. Organizamos la literatura en una taxonomía que consta de tres categorías principales, que cubre temas de LLMS eficientes distintos pero interconectados desde una perspectiva centrada en el modelo , centrada en datos y centrada en el marco , respectivamente. Esperamos que nuestra encuesta y este repositorio de GitHub puedan servir como recursos valiosos para ayudar a los investigadores y profesionales a obtener una comprensión sistemática de los desarrollos de investigación en LLM eficientes e inspirarlos a contribuir a este campo importante y emocionante.
? ¿Por qué se necesitan LLM eficientes?
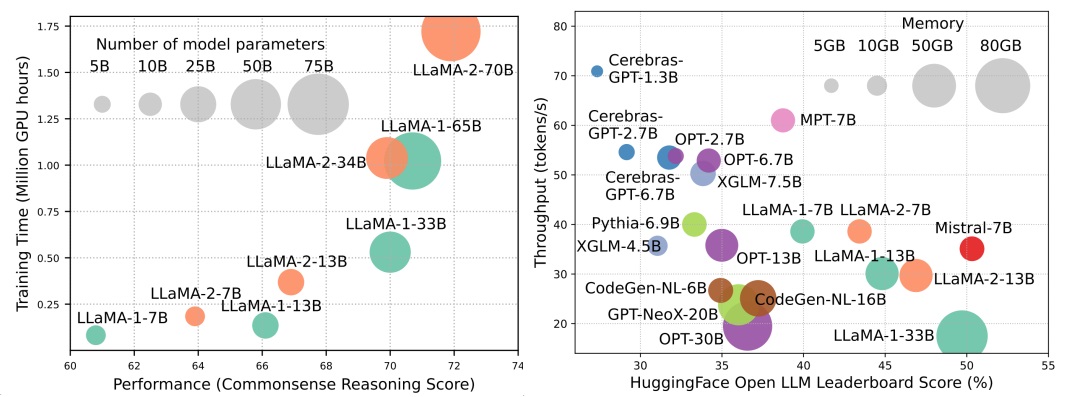
Aunque los LLM están liderando la próxima ola de revolución AI, las capacidades notables de los LLM tienen costo de sus demandas de recursos sustanciales. La Figura 1 (izquierda) ilustra la relación entre el rendimiento del modelo y el tiempo de entrenamiento del modelo en términos de horas de GPU para la serie LLAMA, donde el tamaño de cada círculo es proporcional al número de parámetros del modelo. Como se muestra, aunque los modelos más grandes pueden lograr un mejor rendimiento, las cantidades de horas de GPU utilizadas para entrenarlos crecen exponencialmente a medida que se amplían los tamaños del modelo. Además de la capacitación, la inferencia también contribuye bastante significativamente al costo operativo de LLM. La Figura 2 (derecha) representa la relación entre el rendimiento del modelo y el rendimiento de la inferencia. Del mismo modo, ampliar el tamaño del modelo permite un mejor rendimiento, pero tiene un costo de un rendimiento de inferencia más bajo (mayor latencia de inferencia), presentando desafíos para estos modelos para ampliar su alcance a una base de clientes más amplia y diversas aplicaciones de una manera rentable. Las altas demandas de recursos de LLM resaltan la fuerte necesidad de desarrollar técnicas para mejorar la eficiencia de los LLM. Como se muestra en la Figura 2, en comparación con LLAMA-1-33B, Mistral-7B, que utiliza atención agrupada y de la ventana deslizante para acelerar la inferencia, logra un rendimiento comparable y un rendimiento mucho más alto. Esta superioridad destaca la viabilidad y la importancia de diseñar técnicas de eficiencia para LLM.
Tabla de contenido
- ? Métodos centrados en el modelo
- Compresión modelo
- Cuantificación
- Cuantificación posterior al entrenamiento
- Cuantificación de solo peso
- Co-cuantización de la activación de peso
- Evaluación de la cuantización posterior al entrenamiento
- Capacitación consciente de cuantización
- Poda de parámetros
- Poda estructurada
- Poda no estructurada
- Aproximación de bajo rango
- Destilación de conocimiento
- Box White KD
- KD de caja negra
- Intercambio de parámetros
- Pre-entrenamiento eficiente
- Entrenamiento de precisión mixta
- Modelos de escala
- Técnicas de inicialización
- Optimizadores de entrenamiento
- Ajuste fino eficiente
- Parámetros ajustados eficientes
- Ajuste basado en adaptadores
- Adaptación de bajo rango
- Ajuste de prefijo
- Ajuste rápido
- Ajuste fino eficiente de memoria
- MOE Eficiente supervisado ajustado
- Inferencia eficiente
- Decodificación paralela
- Decodificación especulativa
- Optimización de KV-Cache
- Arquitectura eficiente
- Atención eficiente
- Compartir atención basada
- Reducción de información sobre características
- Kernelización o bajo rango
- Estrategias de patrones fijos
- Estrategias de patrones aprendibles
- Mezcla de expertos
- LLMS con sede en MOE
- Optimización de MOE a nivel de algoritmo
- Contexto largo LLMS
- Extrapolación e interpolación
- Estructura recurrente
- Segmentación y ventana corredera
- Aumento de la memoria
- Arquitectura alternativa de transformador
- Modelos de espacio de estado
- Otros modelos secuenciales
- ? Métodos centrados en datos
- Selección de datos
- Selección de datos para un pre-entrenamiento eficiente
- Selección de datos para ajuste fino eficiente
- Ingeniería rápida
- Pocas de disparo
- Organización de demostración
- Selección de demostración
- Orden de demostración
- Formato de plantilla
- Generación de instrucciones
- Razonamiento de múltiples pasos
- Generación paralela
- Compresión rápida
- Generación rápida
- ? Optimización de eficiencia a nivel de sistema y marcos LLM
- Optimización de eficiencia a nivel de sistema
- Optimización de eficiencia previa a la capacitación a nivel de sistema
- Optimización de eficiencia de servicio a nivel de sistema
- Diseño del sistema de servicio
- Servir la optimización del rendimiento
- Algoritmo-hardware codiseño
- Marcos LLM
? Métodos centrados en el modelo
Compresión modelo
Cuantificación
Cuantificación posterior al entrenamiento
Cuantificación de solo peso
- I-llm: inferencia eficiente solo entero para modelos de lenguaje de bajo bits de baja bits totalmente cuantiados, Arxiv, 2024 [Papel]
- Intactkv: mejora de la cuantización del modelo de lenguaje grande manteniendo intactos tokens pivot, Arxiv, 2024 [Papel]
- Omniquant: omniquant: cuantificación calibrada omnidireccional para modelos de idiomas grandes, ICLR, 2024 [Documento] [código]
- Onebit: Hacia modelos de lenguaje grande de bits extremadamente bajo, Arxiv, 2024 [Papel]
- GPTQ: cuantización precisa para transformadores generativos previamente capacitados, ICLR, 2023 [Documento] [código]
- Quip: cuantificación de 2 bits de modelos de idiomas grandes con garantías, Arxiv, 2023 [Documento] [código]
- AWQ: cuantificación de peso consciente de activación para la compresión y aceleración de LLM, Arxiv, 2023 [Documento] [código]
- OWQ: Lecciones aprendidas de los valores atípicos de activación para la cuantificación de peso en modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- SPQR: una representación de escasez de escasas para la compresión de peso LLM casi sin pérdida, Arxiv, 2023 [Documento] [código]
- Finequant: eficiencia de desbloqueo con cuantización de solo peso de grano fino para LLMS, Neurips-ENLSP, 2023 [Papel]
- Llm.int8 (): multiplicación matriz de 8 bits para transformadores a escala, Neurlps, 2022 [Documento] [código]
- Compresión cerebral óptima: un marco para cuantización y poda posterior al entrenamiento, Neurips, 2022 [Documento] [código]
- Cuantise: cuantización basada en la optimización para modelos de lenguaje, Arxiv, 2023 [Documento] [código]
Co-cuantización de la activación de peso
- Rotación y permutación para la gestión avanzada de valores atípicos y cuantificación eficiente de LLMS, Neurips, 2024 [Papel]
- Omniquant: omniquant: cuantificación calibrada omnidireccional para modelos de idiomas grandes, ICLR, 2024 [Documento] [código]
- Propiedades intrigantes de la cuantización a escala, Neurips, 2023 [Papel]
- Zeroquant-V2: Explorando la cuantización posterior al entrenamiento en LLMS desde un estudio integral hasta una compensación de bajo rango, Arxiv, 2023 [Documento] [código]
- Zeroquant-FP: un salto hacia adelante en la cuantificación W4A8 después de la capacitación LLMS utilizando formatos de punto flotante, Neurips-ENLSP, 2023 [Documento] [código]
- Oliva: acelerando modelos de lenguaje grande a través de cuantización de par de víctimas valientes para hardware, ISCA, 2023 [Documento] [código]
- RPTQ: cuantificación posterior a la capacitación basada en reorden para modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- Supresión atípica+: cuantización precisa de modelos de lenguaje grande por cambio y escalamiento equivalente y óptimo, Arxiv, 2023 [Documento] [código]
- QLLM: Cuantización precisa y eficiente de bajo ancho de bits para modelos de idiomas grandes, Arxiv, 2023 [Papel]
- Smoothquant: cuantización precisa y eficiente posterior a la capacitación para modelos de idiomas grandes, ICML, 2023 [Documento] [código]
- Zeroquant: cuantificación de post-entrenamiento eficiente y asequible para transformadores a gran escala, Neurips, 2022 [Papel]
Evaluación de la cuantización posterior al entrenamiento
- Evaluación de modelos de lenguaje grande cuantificados, Arxiv, 2024 [Papel]
Capacitación consciente de cuantización
- La era de las LLM de 1 bits: todos los modelos de lenguaje grande están en 1.58 bits, Arxiv, 2024 [Papel]
- FP8-LM: capacitación de modelos de lenguaje grande FP8, Arxiv, 2023 [Papel]
- Capacitación e inferencia de modelos de lenguaje grande que usan un punto flotante de 8 bits, Arxiv, 2023 [Papel]
- Bitnet: escala de transformadores de 1 bits para modelos de idiomas grandes, Arxiv, 2023 [Papel]
- LLM-QAT: capacitación consciente de cuantificación sin datos para modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- Compresión de modelos de lenguaje previamente capacitados generativos a través de cuantización, ACL, 2022 [Papel]
Poda de parámetros
Poda estructurada
- Modelos de lenguaje compacto a través de la poda y la destilación de conocimiento, Arxiv, 2024 [Papel]
- Una mirada más profunda a la poda de profundidad de LLMS, Arxiv, 2024 [Papel]
- Perplejo por perplejidad: poda de datos basada en la perplejidad con pequeños modelos de referencia, Arxiv, 2024 [Papel]
- Plug-and-play: un método eficiente de poda posterior al entrenamiento para modelos de lenguaje grandes, ICLR, 2024 [Papel]
- BESA: podando modelos de lenguaje grande con asignación de escasez de parámetros de bloques, asignación de escasez, Arxiv, 2024 [Papel]
- ShortGPT: las capas en modelos de lenguaje grande son más redundantes de lo que esperas, Arxiv, 2024 [Papel]
- Nuteprune: poda progresiva eficiente con numerosos maestros para modelos de idiomas grandes, Arxiv, 2024 [Papel]
- SLICEPPT: comprimir modelos de lenguaje grandes eliminando filas y columnas, ICLR, 2024 [Documento] [código]
- Lorashear: poda y recuperación de conocimiento de mayor poda y conocimiento del modelo de lenguaje grande, Arxiv, 2023 [Papel]
- LLM-PRIMER: Sobre la poda estructural de modelos de idiomas grandes, Neurips, 2023 [Documento] [código]
- Llama Sheared: acelerar el modelo de lenguaje previa a la poda estructurada, Neurips-ENLSP, 2023 [Documento] [código]
- Loraprune: la poda cumple con el ajuste fino de los parámetros de bajo rango, Arxiv, 2023 [Papel]
Poda no estructurada
- MASKLLM: Sparsidad semiestructurada aprendida para modelos de idiomas grandes, NIPS, 2024 [Papel]
- Dynamic Sfire No Training: ajuste fino sin entrenamiento para LLMS escasos, ICLR, 2024 [Papel]
- SPARSEGPT: los modelos de lenguaje masivo se pueden podar con precisión en un solo disparo, ICML, 2023 [Documento] [código]
- Un enfoque de poda simple y efectivo para modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- Poda de escasez mixta de sensibilidad de un solo disparo para modelos de idiomas grandes, Arxiv, 2023 [Papel]
Aproximación de bajo rango
- SVD-LLM: descomposición del valor singular para la compresión del modelo de lenguaje grande, Arxiv, 2024 [Documento] [código]
- ASVD: descomposición del valor singular consciente de la activación para comprimir modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- Compresión del modelo de lenguaje con factorización ponderada de bajo rango, ICLR, 2022 [Papel]
- Tensorgpt: compresión eficiente de la capa de incrustación en LLM basada en la descomposición del tren tensor, Arxiv, 2023 [Papel]
- Losparse: compresión estructurada de modelos de lenguaje grande basados en una aproximación de bajo rango y escaso, ICML, 2023 [Documento] [código]
Destilación de conocimiento
Box White KD
- DDK: conocimiento del dominio de destilación para modelos de idiomas grandes eficientes Arxiv, 2024 [Papel]
- Repensar la divergencia de Kullback-Leíbler en la destilación del conocimiento para modelos de idiomas grandes Arxiv, 2024 [Papel]
- Distillm: hacia la destilación simplificada para modelos de idiomas grandes, Arxiv, 2024 [Documento] [código]
- Hacia la ley de la brecha de capacidad en los modelos de idiomas de destilación, Arxiv, 2023 [Documento] [código]
- Baby Llama: Destilación del conocimiento de un conjunto de maestros entrenados en un pequeño conjunto de datos sin penalización de rendimiento, Arxiv, 2023 [Papel]
- Destilación del conocimiento de modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- GKD: destilación de conocimiento generalizado para modelos de secuencia auto-regresiva, Arxiv, 2023 [Papel]
- Propagando actualizaciones de conocimiento a LMS a través de la destilación, Arxiv, 2023 [Documento] [código]
- Menos es más: destilación de capas consciente de tareas para la compresión del modelo de lenguaje, ICML, 2023 [Papel]
- Destilación logit a escala de tokens para modelos de lenguaje generativo de peso ternario, Arxiv, 2023 [Papel]
KD de caja negra
- Zephyr: destilación directa de la alineación de LM, Arxiv, 2023 [Papel]
- Ajuste de instrucciones con GPT-4, Arxiv, 2023 [Documento] [código]
- León: destilación adversaria del modelo de lenguaje grande de código cerrado, Arxiv, 2023 [Documento] [código]
- Especializar modelos de idiomas más pequeños para un razonamiento de varios pasos, ICML, 2023 [Documento] [código]
- ¡Destilar paso a paso! Superar modelos de lenguaje más grandes con menos datos de capacitación y tamaños de modelos más pequeños, ACL, 2023 [Papel]
- Los grandes modelos de idiomas son maestros de razonamiento, ACL, 2023 [Documento] [código]
- Scott: destilación autoconsistente de la cadena de pensamiento, ACL, 2023 [Documento] [código]
- Destilación simbólica de la cadena de pensamiento: los modelos pequeños también pueden "pensar" paso a paso, ACL, 2023 [Papel]
- Destilación de capacidades de razonamiento en modelos de idiomas más pequeños, ACL, 2023 [Documento] [código]
- Destilación de aprendizaje en contexto: transferir la capacidad de aprendizaje de pocos disparos de los modelos de idiomas previamente capacitados, Arxiv, 2022 [Papel]
- Las explicaciones de los modelos de idiomas grandes mejoran los pequeños razonadores, Arxiv, 2022 [Papel]
- Disco: destilación de contrafactuales con modelos de lenguaje grandes, Arxiv, 2022 [Documento] [código]
Intercambio de parámetros
- Mobillama: hacia GPT, totalmente transparente preciso y liviano, Arxiv, 2024 [Papel]
Pre-entrenamiento eficiente
Entrenamiento de precisión mixta
- Procesamiento BFLOAT16 para redes neuronales, ARITH, 2019 [Papel]
- Un estudio de BFLOAT16 para capacitación de aprendizaje profundo, Arxiv, 2019 [Papel]
- Entrenamiento de precisión mixto, ICLR, 2018 [Papel]
Modelos de escala
- limón: expansión del modelo sin pérdidas, ICLR, 2024 [Papel]
- Preparación de lecciones para capacitación progresiva en modelos de idiomas, AAAI, 2024 [Papel]
- Aprender a cultivar modelos previos a la capacitación de transformadores eficientes, ICLR, 2023 [Documento] [código]
- 2x Modelo de lenguaje más rápido pretruante a través de un crecimiento estructural enmascarado, Arxiv, 2023 [Papel]
- Reutilizando modelos previos a los pretrados por operadores múltiples para capacitación eficiente, Neurips, 2023 [Papel]
- FLM-101B: An Open LLM y cómo entrenarlo con un presupuesto de $ 100 K, Arxiv, 2023 [Documento] [código]
- Herencia de conocimiento para modelos lingüísticos previamente capacitados, NAACL, 2022 [Documento] [código]
- Capacitación escenificada para modelos de lenguaje de transformador, ICML, 2022 [Documento] [código]
Técnicas de inicialización
- Deepnet: escalar transformadores a 1,000 capas, Arxiv, 2022 [Documento] [código]
- Inicialización cero: inicialización de redes neuronales con solo ceros y otros, TMLR, 2022 [Documento] [código]
- Rezero es todo lo que necesitas: convergencia rápida a gran profundidad, Uai, 2021 [Documento] [código]
- Normalización por lotes sesgos bloques residuales hacia la función de identidad en redes profundas, Neurips, 2020 [Papel]
- Mejora de la optimización del transformador a través de una mejor inicialización, ICML, 2020 [Documento] [código]
- Inicialización de fijación: aprendizaje residual sin normalización, ICLR, 2019 [Papel]
- Sobre la inicialización de peso en redes neuronales profundas, ARXIV, 2017 [Papel]
Optimizadores de entrenamiento
- Hacia el aprendizaje óptimo de los modelos de idiomas, Arxiv, 2024 [Documento] [código]
- Descubrimiento simbólico de algoritmos de optimización, Arxiv, 2023 [Papel]
- Sophia: un optimizador estocástico de segundo orden escalable para el modelo de planificación del modelo de lenguaje, Arxiv, 2023 [Documento] [código]
Ajuste fino eficiente
Ajuste fino de los parámetros
Ajuste basado en adaptadores
- Opendelta: una biblioteca plug-and-play para la adaptación de los parámetros de los modelos previamente capacitados, ACL Demo, 2023 [Documento] [código]
- Adaptadores de LLM: una familia adaptadora para ajuste fino de los parámetros de modelos de idiomas grandes, EMNLP, 2023 [Documento] [código]
- Compacter: capas de adaptador hipercomplex de bajo rango eficiente, Neurips, 2023 [Documento] [código]
- El ajuste fino eficiente de los parámetros de shot es mejor y más barato que el aprendizaje en contexto, Neurips, 2022 [Documento] [código]
- MetAdapters: parámetros de pocos disparos eficientes a través de meta-learning, Automl, 2022 [Papel]
- Adamix: Mezcla de adaptaciones para ajuste del modelo de parámetros, EMNLP, 2022 [Documento] [código]
- Sparseadapter: un enfoque fácil para mejorar la eficiencia de parámetros de los adaptadores, EMNLP, 2022 [Documento] [código]
Adaptación de bajo rango
- Hydralora: una arquitectura de lora asimétrica para un ajuste fino eficiente, Neurips, 2024 [Papel]
- Lofit: ajuste fino localizado en representaciones de LLM, Arxiv, 2024 [Papel]
- Mezcla de sus espacios en la adaptación de bajo rango, Arxiv, 2024 [Documento] [código]
- MEFT: ajuste fino eficiente en memoria a través del adaptador disperso, ACL, 2024 [Papel]
- Lora se reúne con abandono bajo un marco unificado, Arxiv, 2024 [Papel]
- Star: restricción lora con aprendizaje activo dinámico para ajuste fino eficiente de datos de modelos de idiomas grandes, Arxiv, 2024 [Papel]
- Lora+: Adaptación eficiente de bajo rango de modelos grandes, Arxiv, 2024 [Papel]
- Lora-FA: Adaptación de bajo rango de memoria eficiente para la memoria para modelos de lenguaje grande, ajuste, ajuste, Arxiv, 2023 [Papel]
- Lorahub: Generalización eficiente de la tarea cruzada a través de la composición dinámica de lora, Arxiv, 2023 [Documento] [código]
- Longlora: ajuste fino eficiente de modelos de lenguaje grande de contexto largo, Arxiv, 2023 [Documento] [código]
- Enrutamiento adaptador de múltiples cabezas para la generalización de la tarea cruzada, Neurips, 2023 [Documento] [código]
- Asignación de presupuesto adaptativo para el ajuste fino de los parámetros, ICLR, 2023 [Papel]
- Dylora: ajuste de parámetros de modelos previos a la aparición utilizando una adaptación dinámica de bajo rango libre de búsqueda, EACL, 2023 [Documento] [código]
- Atado-lora: mejora de la eficiencia de los parámetros de lora con atado de peso, Arxiv, 2023 [Papel]
- Lora: adaptación de bajo rango de modelos de idiomas grandes, ICLR, 2022 [Documento] [código]
Ajuste de prefijo
- LLAMA-Adapter: ajuste fino eficiente de modelos de lenguaje con atención de cero pulgadas, Arxiv, 2023 [Documento] [código]
- Ajuste de prefijo: optimización de indicaciones continuas para la generación ACL, 2021 [Documento] [código]
Ajuste rápido
- Comprimir, luego rápido: mejorar la compensación de la eficiencia de precisión de la inferencia de LLM con el aviso transferible, Arxiv, 2023 [Papel]
- GPT también entiende, Ai Open, 2023 [Documento] [código]
- Prerrevenimiento de la tarea múltiple de aviso modular para el aprendizaje de pocos disparos ACL, 2023 [Documento] [código]
- El ajuste de solicitud de múltiples tareas permite el aprendizaje de transferencia de parámetros-eficiente, ICLR, 2023 [Papel]
- PPT: ajuste de pedido previamente capacitado para un aprendizaje de pocos disparos, ACL, 2022 [Documento] [código]
- La sintonización rápida de los parámetros hace que los recolectores de texto neuronales generalizados y calibrados, EMNLP-Findings, 2022 [Documento] [código]
- P-ajuste V2: el ajuste de inmediato puede ser comparable a Finetuning universalmente a través de escalas y tareas, ACL-Short, 2022 [Documento] [código]
- El poder de la escala para el ajuste de inmediato de los parámetros, EMNLP, 2021 [Papel]
Ajuste fino de la memoria
- Un estudio de optimizaciones para ajustar modelos de idiomas grandes, ARXIV, 2024/INS> [PAPEL]
- Matriz dispersa en modelo de lenguaje grande ajustado, ARXIV, 2024/INS> [PAPEL]
- En abundancia: entrenamiento de LLM de memoria de memoria por proyección de bajo rango de gradiente, ARXIV, 2024/INS> [PAPEL]
- Reft: representación Finetuning para modelos de idiomas, ARXIV, 2024/INS> [PAPEL]
- Lisa: muestreo de importancia de capa para el modelo de lenguaje grande eficiente en la memoria, ajuste, ajustado, ajustado, ARXIV, 2024/INS> [PAPEL]
- Bitdelta: tu tune fino solo puede valer un poco, ARXIV, 2024/INS> [PAPEL]
- Muestreo de la fila de columna de ganadores para todos para la adaptación de la memoria eficiente del modelo de lenguaje, Neurips, 2023 [Documento] [código]
- Ajuste selectivo de memoria de memoria, Taller ICML, 2023 [Papel]
- Parámetro completo ajustado para modelos de idiomas grandes con recursos limitados, Arxiv, 2023 [Documento] [código]
- Modelos de lenguaje ajustados con solo pases hacia adelante, Neurips, 2023 [Documento] [código]
- Ajuste fino eficiente de memoria de modelos de lenguaje grande comprimido a través de cuantización entera de sub-4 bits, Neurips, 2023 [Papel]
- Loftq: cuantificación consciente del ajuste de Lora para modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- Qa-lora: adaptación de bajo rango de cuantificación de modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- Qlora: Fineting eficiente de LLM cuantificados, Neurips, 2023 [Documento] [Código1] [Código2]
MOE-eficiente-supervisado-fino-ajuste
- Deje que el experto se adhiera a su último: ajuste de fino especializado para expertos para modelos arquitectónicos de grandes idiomas, Arxiv, 2024 [Papel]
Inferencia eficiente
Decodificación paralela
- CLLMS: consistencia modelos de lenguaje grande, Arxiv, 2024 [Papel]
- Codificar una vez y decodificar en paralelo: decodificación de transformador eficiente, Arxiv, 2024 [Papel]
Decodificación especulativa
- MagicDec: Rompiendo la compensación de latencia-tope para una generación de contexto larga con decodificación especulativa, Arxiv, 2024 [Papel]
- Hetft: decodificación con atención de árbol de flash para una inferencia LLM estructurada con árboles eficientes, Arxiv, 2024 [Papel]
- Capaskip: habilitando inferencia de salida temprana y decodificación autopeculativa, Arxiv, 2024 [Papel]
- Triforce: aceleración sin pérdidas de la generación de secuencia larga con decodificación especulativa jerárquica, Arxiv, 2024 [Papel]
- REST: decodificación especulativa basada en recuperación, Arxiv, 2024 [Papel]
- Transformadores en tándem para LLM de inferencia de inferencia, Arxiv, 2024 [Papel]
- Pase: muestreo especulativo paralelo, Taller Neurips, 2023 [Papel]
- Inferencia del transformador de aceleración para la traducción a través de la decodificación paralela, ACL, 2023 [Documento] [código]
- Medusa: Marco simple para acelerar la generación de LLM con múltiples cabezas de decodificación, Blog, 2023 [Blog] [Código]
- Inferencia rápida de transformadores a través de la decodificación especulativa, ICML, 2023 [Papel]
- Acelerar la inferencia de LLM con decodificación especulativa por etapas, Taller ICML, 2023 [Papel]
- Acelerar la decodificación del modelo de lenguaje grande con muestreo especulativo, Arxiv, 2023 [Papel]
- Decodificación especulativa con gran decodificador, Neurips, 2023 [Documento] [código]
- Especinfer: acelerar el servicio generativo de LLM con inferencia especulativa y verificación de árbol de token, Arxiv, 2023 [Documento] [código]
- Inferencia con referencia: aceleración sin pérdidas de modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- Semilla: aceleración de la construcción de árboles de razonamiento a través de una decodificación especulativa programada, Arxiv, 2024 [Papel]
Optimización de KV-Cache
- VL-Cache: compresión de caché de KV de escasez y modalidad para la aceleración de inferencia del modelo en idioma de visión, Arxiv, 2024 [Papel]
- Minferencia 1.0: Acelerar el relleno previo para LLM de contexto largo a través de una atención escasa dinámica, Arxiv, 2024 [Papel]
- KVSHARER: Inferencia eficiente a través de la capa de caché de KV diferente de la capa. Arxiv, 2024 [Papel]
- Duoatent: eficiente inferencia de contexto largo LLM con cabezas de recuperación y transmisión, Arxiv, 2024 [Papel]
- Lazyllm: poda de token dinámico para una inferencia eficiente de contexto largo LLM, Arxiv, 2024 [Papel]
- Palu: comprimir la cache de KV con proyección de bajo rango, Arxiv, 2024 [Documento] [código]
- Look-M: Optimización de Mire once en caché de KV para una inferencia de contexto multimodal eficiente, Arxiv, 2024 [Papel]
- D2O: Operaciones discriminativas dinámicas para una inferencia generativa eficiente de modelos de idiomas grandes, Arxiv, 2024 [Papel]
- Quest: Sparsity de consulta para una inferencia eficiente de larga duración LLM, ICML, 2024 [Papel]
- Reducir el tamaño de la caché del valor clave del transformador con la atención de la capa cruzada, Arxiv, 2024 [Papel]
- Snapkv: LLM sabe lo que está buscando antes de la generación, Arxiv, 2024 [Papel]
- Modelos de idiomas grandes basados en ancla, Arxiv, 2024 [Papel]
- KVQUANT: Hacia 10 millones de inferencia de longitud de contexto LLM con cuantización de caché de KV, Arxiv, 2024 [Papel]
- Gear: una receta eficiente de compresión de caché de KV para inferencia generativa casi sin pérdida de LLM, Arxiv, 2024 [Papel]
- Compresión de memoria dinámica: modernización de LLM para inferencia acelerada, Arxiv, 2024 [Papel]
- No se queda el token: compresión de caché de KV confiable a través de cuantización de precisión mixta de importancia, Arxiv, 2024 [Papel]
- Obtenga más con menos: sintetizar recurrencia con compresión de caché de KV para una inferencia de LLM eficiente, Arxiv, 2024 [Papel]
- Wkvquant: cuantificación de peso y caché de llave/valor para modelos de idiomas grandes obtiene más, Arxiv, 2024 [Papel]
- Sobre la eficacia de la política de desalojo para la inferencia del modelo de lenguaje generativo restringido de valor clave, Arxiv, 2024 [Papel]
- Kivi: una cuantización asimétrica de 2 bits sin ajuste para caché de KV, Arxiv, 2024 [Documento] [código]
- El modelo le dice qué descartar: compresión adaptativa de caché de KV para LLMS, ICLR, 2024 [Papel]
- SkipDecode: decodificación de omisión autorregresiva con lotes y almacenamiento en caché para una inferencia de LLM eficiente, Arxiv, 2023 [Papel]
- H2O: Oracle de hits pesados para una inferencia generativa eficiente de modelos de idiomas grandes, Neurips, 2023 [Papel]
- SCISSORHANDS: explotando la persistencia de hipótesis de importancia para la compresión de caché LLM KV en el tiempo de prueba, Neurips, 2023 [Papel]
- Poda de contexto dinámico para transformadores autorregresivos eficientes e interpretables, Arxiv, 2023 [Papel]
Arquitectura eficiente
Atención eficiente
Compartir atención basada
- Loma: atención de memoria comprimida sin pérdidas, Arxiv, 2024 [Papel]
- Mobilellm: optimización de modelos de lenguaje de parámetros de menor miles de millones para casos de uso en el dispositivo, Arxiv, 2024 [Papel]
- GQA: capacitación de modelos de transformadores múltiples generalizados desde puntos de control de múltiples cabezas, EMNLP, 2023 [Papel]
- Decodificación de transformador rápido: una cabeza de escritura es todo lo que necesitas, Arxiv, 2019 [Papel]
Reducción de información sobre características
- Nyströmformer: un algoritmo basado en Nyström para aproximar la autoatención, AAAI, 2021 [Documento] [código]
- Funnel-Transformer: filtrar la redundancia secuencial para un procesamiento eficiente del lenguaje, Neurips, 2020 [Documento] [código]
- Set Transformer: un marco para las redes neuronales invariantes de permutación basada en la atención, ICML, 2019 [Papel]
Kernelización o bajo rango
- Loki: teclas de bajo rango para una atención escasa eficiente, Taller ICML, 2023 [Papel]
- Sumformer: Aproximación universal para transformadores eficientes, Taller ICML, 2023 [Papel]
- Flurka: atención rápida de bajo rango y núcleo, Arxiv, 2023 [Papel]
- Dispersbrain: atención unificadora y de bajo rango, Neurlps, 2021 [Documento] [código]
- Repensar la atención con los artistas, ICLR, 2021 [Documento] [código]
- Atención de características aleatorias, ICLR, 2021 [Papel]
- Linformer: autoatención con complejidad lineal, arxiv, 2020 [Documento] [código]
- Reconocimiento de voz de extremo a extremo ligero y eficiente utilizando transformador de bajo rango, Icassp, 2020 [Papel]
- Los transformadores son RNN: transformadores autorregresivos rápidos con atención lineal, ICML, 2020 [Documento] [código]
Estrategias de patrones fijos
- Los modelos de lenguaje de atención lineal simples equilibran la compensación de recuperación-throughput, Arxiv, 2024 [Papel]
- Lightning Attle-2: Un almuerzo gratis para manejar longitudes de secuencia ilimitadas en modelos de idiomas grandes, Arxiv, 2024 [Documento] [código]
- Atención causal más rápida sobre grandes secuencias a través de la atención de flash escasa, Taller ICML, 2023 [Papel]
- Poolingformer: modelado de documentos largos con atención de la agrupación, ICML, 2021 [Papel]
- Big Bird: Transformers para secuencias más largas, Neurips, 2020 [Documento] [código]
- Longformer: el transformador de documento largo, arxiv, 2020 [Documento] [código]
- Autoatención de bloques para una larga comprensión de documentos, EMNLP, 2020 [Documento] [código]
- Generando secuencias largas con transformadores dispersos, Arxiv, 2019 [Papel]
Estrategias de patrones aprendibles
- MOA: Mezcla de atención escasa para la compresión automática del modelo de lenguaje grande, Arxiv, 2024 [Papel]
- Hiperatención: atención de contexto largo en tiempo casi lineal, Arxiv, 2023 [Documento] [código]
- ClusterFormer: Atención de agrupación neuronal para un transformador eficiente y efectivo, ACL, 2022 [Papel]
- Reformador: el transformador eficiente, ICLR, 2022 [Documento] [código]
- Atención escasa de Funbyhorn, ICML, 2020 [Papel]
- Transformadores rápidos con atención agrupada, Neurips, 2020 [Documento] [código]
- Atención escasa eficiente basada en el contenido con transformadores de enrutamiento, TACL, 2020 [Documento] [código]
Mezcla de expertos
LLMS con sede en MOE
- Self-MOE: hacia los modelos de lenguaje grande composicional con expertos autopecializados, Arxiv, 2024 [Papel]
- Lory: Mezcla de expertos totalmente diferenciable para el pre-entrenamiento del modelo de lenguaje autorregresivo, 2024 [documento]
- Jetmoe: alcanzar el rendimiento de Llama2 con 0.1m dólares, 2024 [papel]
- Un experto vale un token: sinergia de múltiples LLM de expertos como generalista a través de la ruta del token experto, 2024 [documento]
- Mezcla de Dephs: asignación dinámica de cómputo en modelos de lenguaje basados en transformadores, 2024 [documento]
- Brix-Mix-Mix: Mezcle experto LLM en una mezcla de expertos LLM, 2024 [papel]
- Mixtrral de expertos, Arxiv, 2024 [Documento] [código]
- Mistral 7b, Arxiv, 2023 [Documento] [código]
- Pangu-dσ: Hacia el modelo de lenguaje de parámetros de billones con computación heterogénea escasa, Arxiv, 2023 [Papel]
- Transformadores de interruptor: escala a modelos de parámetros de billones de parámetros con escasez simple y eficiente, JMLR, 2022 [Documento] [código]
- Modelado de lenguaje a gran escala eficiente con mezclas de expertos, EMNLP, 2022 [Documento] [código]
- Capas base: entrenamiento simplificador de modelos grandes y escasos, ICML, 2021 [Documento] [código]
- GSHARD: Modelos gigantes de escala con cálculo condicional y fragmentos automáticos, ICLR, 2021 [Papel]
Optimización de MOE a nivel de algoritmo
- SEER-MOE: escasa eficiencia de expertos a través de la regularización para la mezcla de expertos, ARXIV, 2024/INS> [PAPEL]
- Leyes de escala para la mezcla de expertos de grano fino, ARXIV, 2024/INS> [PAPEL]
- Lenguaje de toda la vida previa a la altura con expertos especializados en distribución, ICML, 2023 [Papel]
- La mezcla de expertos cumple con el ajuste de instrucciones: una combinación ganadora para modelos de idiomas grandes, Arxiv, 2023 [Papel]
- Mezcla de expertos con enrutamiento de elección de expertos, Neurips, 2022 [Papel]
- STABLEMOE: Estrategia de enrutamiento estable para la mezcla de expertos, ACL, 2022 [Documento] [código]
- Sobre el colapso de la representación de la mezcla escasa de expertos, Neurips, 2022 [Papel]
Contexto largo LLMS
Extrapolación e interpolación
- Dos piedras golpean un pájaro: codificación posicional de nivel bille para extrapolación de mejor longitud, ICML, 2024 [Papel]
- ∞ Bench: extender una larga evaluación del contexto más allá de 100k tokens, Arxiv, 2024 [Papel]
- Cordera de resonancia: Mejora de la generalización de la duración del contexto de modelos de idiomas grandes, Arxiv, 2024 [Documento] [código]
- Longrope: Extendiendo la ventana de contexto de LLM más allá de los 2 millones de tokens, Arxiv, 2024 [Papel]
- E^2-llm: extensión eficiente y de longitud extrema de modelos de lenguaje grandes, Arxiv, 2024 [Papel]
- Leyes de escala de extrapolación basada en la cuerda, Arxiv, 2023 [Papel]
- Un transformador de longitud y explotable, ACL, 2023 [Documento] [código]
- Extender la ventana de contexto de los modelos de lenguaje grande a través de la interpolación posicional, Arxiv, 2023 [Papel]
- Interpolación NTK, Blog, 2023 [Reddit Post]
- Hilo: extensión de ventana de contexto eficiente de modelos de lenguaje grandes, Arxiv, 2023 [Documento] [código]
- CLEX: Extrapolación de longitud continua para modelos de idiomas grandes, Arxiv, 2023 [Documento] [código]
- Pose: Eficiente extensión de la ventana de contexto de LLM a través del entrenamiento posicional de Skip-Wise, Arxiv, 2023 [Documento] [código]
- La interpolación funcional para posiciones relativas mejora los transformadores de contexto largos, Arxiv, 2023 [Papel]
- Train corto, prueba larga: la atención con sesgos lineales permite extrapolación de longitud de entrada, ICLR, 2022 [Documento] [código]
- Explorar la generalización de la longitud en modelos de idiomas grandes, Neurips, 2022 [Papel]
Estructura recurrente
- Red retentiva: un sucesor para transformador para grandes modelos de idiomas, Arxiv, 2023 [Documento] [código]
- Transformador de memoria recurrente, Neurips, 2022 [Documento] [código]
- Transformadores de recurrencia de bloques, Neurips, 2022 [Documento] [código]
- ∞-former: transformador de memoria infinita, ACL, 2022 [Documento] [código]
- MEMFORMER: un transformador acuático de memoria para el modelado de secuencia, AACL-FINDINGS, 2020 [Documento] [código]
- Transformer-XL: modelos de lenguaje atento más allá de un contexto de longitud fija, ACL, 2019 [Documento] [código]
Segmentación y ventana corredera
- XL3M: un marco sin capacitación para la extensión de longitud de LLM basada en la inferencia en términos de segmento, Arxiv, 2024 [Papel]
- TransformerFam: la atención de la retroalimentación es la memoria de trabajo, Arxiv, 2024 [Papel]
- Extensión de contexto basada en Bayes Naive para modelos de idiomas grandes, NAACL, 2024 [Papel]
- No deje contexto: transformadores de contexto infinitos eficientes con infini-asistencia, Arxiv, 2024 [Papel]
- Entrenamiento de LLM sobre texto neuralmente comprimido, Arxiv, 2024 [Papel]
- LM-Infinite: generalización de longitud extrema de disparo cero para modelos de idiomas grandes, Arxiv, 2024 [Papel]
- Escalado de contexto largo sin entrenamiento de modelos de idiomas grandes, Arxiv, 2024 [Documento] [código]
- Modelado de lenguaje de contexto largo con codificación de contexto paralelo, Arxiv, 2024 [Documento] [código]
- Avando de 4K a 400K: extender el contexto de LLM con Beacon de activación, Arxiv, 2024 [Documento] [código]
- LLM quizás longlm: ventana de contexto de autoextend LLM sin ajuste, Arxiv, 2024 [Documento] [código]
- Extender la ventana de contexto de los modelos de idiomas grandes a través de la compresión semántica, Arxiv, 2023 [Papel]
- Modelos de lenguaje de transmisión eficientes con sumideros de atención, Arxiv, 2023 [Documento] [código]
- Windows de contexto paralelo para modelos de idiomas grandes, ACL, 2023 [Documento] [código]
- Longnet: escalando transformadores a 1,000,000,000 de tokens, Arxiv, 2023 [Documento] [código]
- Comprensión eficiente de texto largo con modelos de texto corto, TACL, 2023 [Documento] [código]
Aumento de la memoria
- Infllm: revelando la capacidad intrínseca de los LLM para comprender secuencias extremadamente largas con memoria libre de entrenamiento, Arxiv, 2024 [Papel]
- Landmark Attention: Random-Access Infinite Context Length for Transformers, arXiv, 2023 [Paper] [Code]
- Augmenting Language Models with Long-Term Memory, NeurIPS, 2023 [Papel]
- Unlimiformer: Long-Range Transformers with Unlimited Length Input, NeurIPS, 2023 [Paper] [Code]
- Focused Transformer: Contrastive Training for Context Scaling, NeurIPS, 2023 [Paper] [Code]
- Retrieval meets Long Context Large Language Models, arXiv, 2023 [Papel]
- Memorizing Transformers, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
State Space Models
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [Papel]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [Papel]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [Papel]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [Papel]
- Block-State Transformers, NeurIPS, 2023 [Papel]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces, NeurIPS, 2022 [Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [Papel]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [Papel]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [Papel]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [Papel]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [Papel]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [Papel]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [Papel]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [Papel]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [Papel]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [Papel]
? Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [Papel]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [Papel]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [Papel]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [Papel]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [Papel]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [Papel]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [Papel]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [Papel]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [Papel]
Prompt Engineering
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [Papel]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [Papel]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [Papel]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [Papel]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [Papel]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [Papel]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [Papel]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [Papel]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [Papel]
- Learning to Reason with LLMs, Website, 2024 [Html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [Papel]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [Papel]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [Papel]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [Papel]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [Papel]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS, 2022 [Papel]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [Papel]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [Papel]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [Papel]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [Papel]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [Papel]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [Papel]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [Papel]
Prompt Generation
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [Papel]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [Papel]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [Papel]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 , [Papel]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [Papel]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [Papel]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [Papel]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [Papel]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [Papel]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [Papel]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [Papel]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [Papel]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [Papel]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [Papel]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [Papel]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [Papel]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [Papel]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [Papel]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [Papel]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [Papel]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [Papel]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [Papel]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [Papel]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [Papel]
- Fairness in Serving Large Language Models, arXiv, 2023 [Papel]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [Papel]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS, 2022 [Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [Blog]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [Papel]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [Papel]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [Papel]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [Papel]
LLM Frameworks
| Efficient Training | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | ✅ | ✅ | ✅ |
| Megatron [Code] | ✅ | ✅ | ✅ |
| ColossalAI [Code] | ✅ | ✅ | ✅ |
| Nanotron [Code] | ✅ | ✅ | ✅ |
| MegaBlocks [Code] | ✅ | ✅ | ✅ |
| FairScale [Code] | ✅ | ✅ | ✅ |
| Pax [Code] | ✅ | ✅ | ✅ |
| Composer [Code] | ✅ | ✅ | ✅ |
| OpenLLM [Code] | | ✅ | ✅ |
| LLM-Foundry [Code] | | ✅ | ✅ |
| vLLM [Code] | | ✅ | |
| TensorRT-LLM [Code] | | ✅ | |
| TGI [Code] | | ✅ | |
| RayLLM [Code] | | ✅ | |
| MLC LLM [Code] | | ✅ | |
| Sax [Code] | | ✅ | |
| Mosec [Code] | | ✅ | |


