แบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพ: การสำรวจ
แบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพ: การสำรวจ [arxiv] (เวอร์ชัน 1: 12/06/2023; เวอร์ชัน 2: 12/23/2023; เวอร์ชัน 3: 01/31/2024; เวอร์ชัน 4: 05/23/2024, กล้องพร้อมการทำธุรกรรมในการวิจัยการเรียนรู้ของเครื่อง))
Zhongwei Wan 1 , Xin Wang 1 , Che Liu 2 , Samiul Alam 1 , Yu Zheng 3 , Jiachen Liu 4 , Zhongnan Qu 5 , Shen Yan 6 , Yi Zhu 7 , Quanlu Zhang 8 , Mosharaf Chowdhury 4 , Mi Zhang 1
1 The Ohio State University, 2 Imperial College London, 3 Michigan State University, 4 University of Michigan, 5 Amazon AWS AI, 6 Google Research, 7 Boson AI, 8 Microsoft Research Asia Asia
⚡NEWS: การสำรวจของเราได้รับการยอมรับอย่างเป็นทางการจากการทำธุรกรรมเกี่ยวกับการวิจัยการเรียนรู้ของเครื่อง (TMLR), พฤษภาคม 2024 รุ่นกล้องพร้อมให้บริการที่: [OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
❤การสนับสนุนชุมชน
ที่เก็บนี้ได้รับการดูแลโดย Tuidan ([email protected]) การตอกย้ำ ([email protected]) Samiul272 ([email protected]) และ มิด ([email protected]) เรายินดีต้อนรับข้อเสนอแนะคำแนะนำและการมีส่วนร่วมที่สามารถช่วยปรับปรุงการสำรวจและที่เก็บนี้เพื่อให้พวกเขามีทรัพยากรที่มีค่าเพื่อเป็นประโยชน์ต่อชุมชนทั้งหมด
เราจะรักษาที่เก็บนี้อย่างแข็งขันโดยรวมการวิจัยใหม่ตามที่เกิดขึ้น หากคุณมีข้อเสนอแนะใด ๆ เกี่ยวกับอนุกรมวิธานของเราค้นหาเอกสารที่ไม่ได้รับหรืออัปเดตกระดาษ preprint arxiv ใด ๆ ที่ได้รับการยอมรับไปยังสถานที่บางแห่งอย่าลังเลที่จะส่งอีเมลถึงเราหรือส่ง คำขอดึง โดยใช้รูปแบบ markdown ต่อไปนี้
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
- การสำรวจนี้เกี่ยวกับอะไร?
แบบจำลองภาษาขนาดใหญ่ (LLMS) ได้แสดงให้เห็นถึงความสามารถที่น่าทึ่งในงานที่สำคัญหลายอย่างและมีศักยภาพที่จะสร้างผลกระทบอย่างมากต่อสังคมของเรา อย่างไรก็ตามความสามารถดังกล่าวมาพร้อมกับความต้องการทรัพยากรจำนวนมากโดยเน้นถึงความต้องการที่แข็งแกร่งในการพัฒนาเทคนิคที่มีประสิทธิภาพสำหรับการจัดการกับความท้าทายด้านประสิทธิภาพที่เกิดจาก LLM ในการสำรวจนี้เราให้การทบทวนอย่างเป็นระบบและครอบคลุมเกี่ยวกับการวิจัย LLM ที่มีประสิทธิภาพ เราจัดระเบียบวรรณกรรมในอนุกรมวิธานซึ่งประกอบด้วยสามหมวดหมู่หลักครอบคลุมหัวข้อ LLM ที่มีประสิทธิภาพที่แตกต่างกัน แต่เชื่อมโยงถึงกันจากมุมมอง ที่เน้นรูปแบบเป็นศูนย์กลาง ข้อมูลเป็นศูนย์กลาง และ กรอบการทำงานเป็นศูนย์กลาง ตามลำดับ เราหวังว่าการสำรวจของเราและพื้นที่เก็บข้อมูล GitHub นี้สามารถใช้เป็นทรัพยากรที่มีค่าเพื่อช่วยให้นักวิจัยและผู้ปฏิบัติงานได้รับความเข้าใจอย่างเป็นระบบเกี่ยวกับการพัฒนาการวิจัยใน LLM ที่มีประสิทธิภาพและเป็นแรงบันดาลใจให้พวกเขามีส่วนร่วมในสาขาที่สำคัญและน่าตื่นเต้นนี้
- เหตุใดจึงจำเป็นต้องมี LLM ที่มีประสิทธิภาพ?
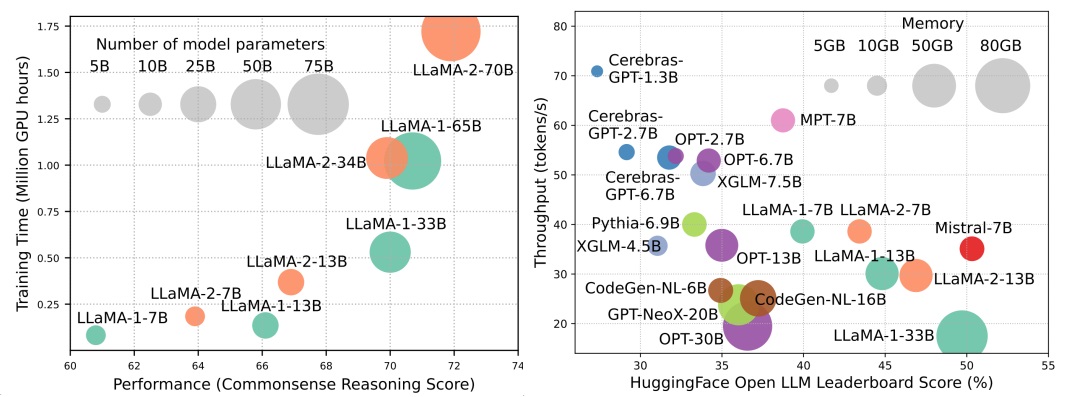
แม้ว่า LLMS จะเป็นผู้นำคลื่นลูกต่อไปของการปฏิวัติ AI แต่ความสามารถที่น่าทึ่งของ LLM นั้นมาจากค่าใช้จ่ายของความต้องการทรัพยากรที่สำคัญของพวกเขา รูปที่ 1 (ซ้าย) แสดงให้เห็นถึงความสัมพันธ์ระหว่างประสิทธิภาพของโมเดลและเวลาการฝึกอบรมแบบจำลองในแง่ของชั่วโมง GPU สำหรับซีรีย์ Llama ซึ่งขนาดของแต่ละวงกลมนั้นเป็นสัดส่วนกับจำนวนพารามิเตอร์แบบจำลอง ดังที่แสดงแม้ว่าโมเดลขนาดใหญ่จะสามารถบรรลุประสิทธิภาพที่ดีขึ้นได้ แต่จำนวนชั่วโมงของ GPU ที่ใช้สำหรับการฝึกอบรมพวกเขาจะเพิ่มขึ้นอย่างทวีคูณเมื่อขนาดของรุ่นเพิ่มขึ้น นอกเหนือจากการฝึกอบรมแล้วการอนุมานยังมีส่วนช่วยอย่างมากต่อค่าใช้จ่ายในการดำเนินงานของ LLMS รูปที่ 2 (ขวา) แสดงให้เห็นถึงความสัมพันธ์ระหว่างประสิทธิภาพของโมเดลและปริมาณการอนุมาน ในทำนองเดียวกันการปรับขนาดขนาดของแบบจำลองช่วยให้ประสิทธิภาพที่ดีขึ้น แต่มาจากค่าใช้จ่ายในการอนุมัติการอนุมานที่ต่ำกว่า (เวลาแฝงการอนุมานที่สูงขึ้น) นำเสนอความท้าทายสำหรับรุ่นเหล่านี้ในการขยายการเข้าถึงฐานลูกค้าที่กว้างขึ้น ความต้องการทรัพยากรสูงของ LLMS เน้นถึงความต้องการที่แข็งแกร่งในการพัฒนาเทคนิคเพื่อเพิ่มประสิทธิภาพของ LLMS ดังที่แสดงในรูปที่ 2 เมื่อเทียบกับ LLAMA-1-33B, MISTRAL-7B ซึ่งใช้ความสนใจแบบกลุ่มและความสนใจของหน้าต่างเลื่อนเพื่อเพิ่มความเร็วในการอนุมานบรรลุประสิทธิภาพที่เทียบเคียงได้และปริมาณงานที่สูงขึ้นมาก ความเหนือกว่านี้เน้นถึงความเป็นไปได้และความสำคัญของการออกแบบเทคนิคประสิทธิภาพสำหรับ LLMS
หนังสือพิมพ์
- - วิธีการแบบจำลองเป็นศูนย์กลาง
- การบีบอัดแบบจำลอง
- การวัดปริมาณ
- การฝึกอบรมหลังการฝึกอบรม
- ปริมาณที่มีน้ำหนักเท่านั้น
- การเปิดใช้งานการเปิดใช้งาน
- การประเมินปริมาณการฝึกอบรมหลังการฝึกอบรม
- การฝึกอบรมเชิงปริมาณ
- การตัดแต่งพารามิเตอร์
- การตัดแต่งกิ่งที่มีโครงสร้าง
- การตัดแต่งกิ่งไม่มีโครงสร้าง
- การประมาณระดับต่ำ
- การกลั่นความรู้
- การแชร์พารามิเตอร์
- การฝึกอบรมก่อน
- การฝึกอบรมแบบผสมผสาน
- โมเดลการปรับขนาด
- เทคนิคการเริ่มต้น
- เครื่องมือเพิ่มประสิทธิภาพการฝึกอบรม
- การปรับจูนที่มีประสิทธิภาพ
- พารามิเตอร์การปรับจูนอย่างมีประสิทธิภาพ
- การปรับแต่งอะแดปเตอร์
- การปรับตัวระดับต่ำ
- การปรับแต่งคำนำหน้า
- การปรับแต่ง
- การปรับจูนหน่วยความจำที่มีประสิทธิภาพ
- MOE การปรับแต่งการปรับแต่งอย่างมีประสิทธิภาพ
- การอนุมานที่มีประสิทธิภาพ
- การถอดรหัสแบบขนาน
- การถอดรหัสการเก็งกำไร
- การเพิ่มประสิทธิภาพ KV-cache
- สถาปัตยกรรมที่มีประสิทธิภาพ
- ความสนใจที่มีประสิทธิภาพ
- การแบ่งปันความสนใจตาม
- การลดข้อมูลคุณสมบัติ
- เคอร์เนลหรือระดับต่ำ
- กลยุทธ์รูปแบบคงที่
- กลยุทธ์รูปแบบที่เรียนรู้ได้
- ส่วนผสมของผู้เชี่ยวชาญ
- LLMS ที่ใช้ MOE
- การเพิ่มประสิทธิภาพ MOE ระดับอัลกอริทึม
- บริบทยาว LLMS
- การคาดการณ์และการแก้ไข
- โครงสร้างกำเริบ
- การแบ่งส่วนและหน้าต่างบานเลื่อน
- การเสริมหน่วยความจำ
- สถาปัตยกรรมทางเลือกของหม้อแปลง
- แบบจำลองพื้นที่ของรัฐ
- รุ่นต่อเนื่องอื่น ๆ
- - วิธีการที่เป็นศูนย์กลางของข้อมูล
- การเลือกข้อมูล
- การเลือกข้อมูลสำหรับการฝึกอบรมล่วงหน้าที่มีประสิทธิภาพ
- การเลือกข้อมูลสำหรับการปรับแต่งอย่างมีประสิทธิภาพ
- วิศวกรรมที่รวดเร็ว
- การกระตุ้นไม่กี่ครั้ง
- องค์กรสาธิต
- การเลือกสาธิต
- การจัดลำดับการสาธิต
- การจัดรูปแบบแม่แบบ
- การสร้างคำสั่ง
- การใช้เหตุผลหลายขั้นตอน
- รุ่นขนาน
- การบีบอัดพร้อม
- การสร้าง
- ? การเพิ่มประสิทธิภาพประสิทธิภาพระดับระบบและเฟรมเวิร์ก LLM
- การเพิ่มประสิทธิภาพประสิทธิภาพระดับระบบ
- การเพิ่มประสิทธิภาพประสิทธิภาพการฝึกอบรมก่อนระดับระบบ
- การเพิ่มประสิทธิภาพประสิทธิภาพการให้บริการระดับระบบ
- การออกแบบระบบให้บริการ
- การเพิ่มประสิทธิภาพประสิทธิภาพ
- การออกแบบร่วมอัลกอริทึม
- เฟรมเวิร์ก LLM
- วิธีการแบบจำลองเป็นศูนย์กลาง
การบีบอัดแบบจำลอง
การวัดปริมาณ
การฝึกอบรมหลังการฝึกอบรม
ปริมาณที่มีน้ำหนักเท่านั้น
- I-LLM: การอนุมานจำนวนเต็มอย่างมีประสิทธิภาพอย่างเดียวสำหรับแบบจำลองภาษาขนาดใหญ่บิตต่ำแบบไม่มีค่าใช้จ่ายเต็มรูปแบบ arxiv, 2024 [กระดาษ]
- IntactKV: การปรับปรุงการหาปริมาณแบบจำลองภาษาขนาดใหญ่โดยรักษาโทเค็นเดือยไว้เหมือนเดิม arxiv, 2024 [กระดาษ]
- imniquant: imniquant: การปรับเทียบปริมาณรอบทิศทางสำหรับแบบจำลองภาษาขนาดใหญ่ ICLR, 2024 [กระดาษ] [รหัส]
- OneBit: ไปสู่แบบจำลองภาษาขนาดใหญ่ที่มีขนาดต่ำมาก arxiv, 2024 [กระดาษ]
- GPTQ: การหาปริมาณที่แม่นยำสำหรับหม้อแปลงที่ผ่านการฝึกอบรมมาก่อน ICLR, 2023 [กระดาษ] [รหัส]
- QUIP: การหาปริมาณแบบ 2 บิตของแบบจำลองภาษาขนาดใหญ่ที่มีการรับประกัน arxiv, 2023 [กระดาษ] [รหัส]
- AWQ: ปริมาณการเปิดใช้งานที่รับรู้สำหรับการบีบอัด LLM และการเร่งความเร็ว arxiv, 2023 [กระดาษ] [รหัส]
- OWQ: บทเรียนที่เรียนรู้จากค่าใช้จ่ายการเปิดใช้งานสำหรับการหาปริมาณน้ำหนักในแบบจำลองภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- SPQR: การเป็นตัวแทนที่เบาบางสำหรับการบีบอัดน้ำหนัก LLM ใกล้สูญเสีย arxiv, 2023 [กระดาษ] [รหัส]
- Finequant: ปลดล็อคประสิทธิภาพด้วยปริมาณที่มีน้ำหนักอย่างเดียวสำหรับ LLMS Neurips-Enlsp, 2023 [กระดาษ]
- llm.int8 (): การคูณเมทริกซ์ 8 บิตสำหรับหม้อแปลงในระดับ Neurlps, 2022 [กระดาษ] [รหัส]
- การบีบอัดสมองที่ดีที่สุด: กรอบการทำงานสำหรับการฝึกอบรมหลังการฝึกอบรมและการตัดแต่งกิ่งที่แม่นยำ Neurips, 2022 [กระดาษ] [รหัส]
- ปริมาณ: การเพิ่มประสิทธิภาพเชิงปริมาณสำหรับแบบจำลองภาษา arxiv, 2023 [กระดาษ] [รหัส]
การเปิดใช้งานการเปิดใช้งาน
- การหมุนและการเปลี่ยนแปลงสำหรับการจัดการค่าผิดปกติขั้นสูงและปริมาณ LLM ที่มีประสิทธิภาพ Neurips, 2024 [กระดาษ]
- imniquant: imniquant: การปรับเทียบปริมาณรอบทิศทางสำหรับแบบจำลองภาษาขนาดใหญ่ ICLR, 2024 [กระดาษ] [รหัส]
- คุณสมบัติที่น่าสนใจของการหาปริมาณในระดับ Neurips, 2023 [กระดาษ]
- Zeroquant-V2: การสำรวจปริมาณการฝึกอบรมหลังการฝึกอบรมใน LLMs จากการศึกษาที่ครอบคลุมถึงการชดเชยระดับต่ำ arxiv, 2023 [กระดาษ] [รหัส]
- Zeroquant-FP: ก้าวกระโดดไปข้างหน้าใน LLMS หลังการฝึกอบรมปริมาณ W4A8 โดยใช้รูปแบบจุดลอยตัว Neurips-Enlsp, 2023 [กระดาษ] [รหัส]
- มะกอก: เร่งรุ่นภาษาขนาดใหญ่ผ่านการหาปริมาณคู่ที่เป็นมิตรกับฮาร์ดแวร์ที่เป็นมิตรกับฮาร์ดแวร์ ISCA, 2023 [กระดาษ] [รหัส]
- RPTQ: การจัดลำดับการฝึกอบรมหลังการฝึกอบรมใหม่สำหรับรุ่นภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- การปราบปราม Outlier+: การหาปริมาณที่แม่นยำของแบบจำลองภาษาขนาดใหญ่โดยการขยับและการปรับขนาดที่ดีที่สุดและเหมาะสมที่สุด arxiv, 2023 [กระดาษ] [รหัส]
- QLLM: การหาปริมาณที่แม่นยำและมีประสิทธิภาพต่ำสำหรับแบบจำลองภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ]
- Smoothquant: การหาปริมาณหลังการฝึกอบรมที่แม่นยำและมีประสิทธิภาพสำหรับแบบจำลองภาษาขนาดใหญ่ ICML, 2023 [กระดาษ] [รหัส]
- Zeroquant: ปริมาณการฝึกอบรมหลังการฝึกอบรมที่มีประสิทธิภาพและราคาไม่แพงสำหรับหม้อแปลงขนาดใหญ่ Neurips, 2022 [กระดาษ]
การประเมินปริมาณการฝึกอบรมหลังการฝึกอบรม
- การประเมินแบบจำลองภาษาขนาดใหญ่เชิงปริมาณ arxiv, 2024 [กระดาษ]
การฝึกอบรมเชิงปริมาณ
- ยุคของ LLMS 1 บิต: แบบจำลองภาษาขนาดใหญ่ทั้งหมดอยู่ใน 1.58 บิต arxiv, 2024 [กระดาษ]
- FP8-LM: การฝึกอบรมแบบจำลองภาษาขนาดใหญ่ FP8 arxiv, 2023 [กระดาษ]
- การฝึกอบรมและการอนุมานของแบบจำลองภาษาขนาดใหญ่โดยใช้จุดลอยตัว 8 บิต arxiv, 2023 [กระดาษ]
- Bitnet: ปรับขนาดหม้อแปลง 1 บิตสำหรับรุ่นภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ]
- LLM-QAT: การฝึกอบรมเชิงปริมาณที่ปราศจากข้อมูลสำหรับแบบจำลองภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- การบีบอัดแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนผ่านการหาปริมาณ ACL, 2022 [กระดาษ]
การตัดแต่งพารามิเตอร์
การตัดแต่งกิ่งที่มีโครงสร้าง
- แบบจำลองภาษาขนาดกะทัดรัดผ่านการตัดแต่งกิ่งและการกลั่นความรู้ arxiv, 2024 [กระดาษ]
- ดูลึกลงไปที่การตัดแต่งความลึกของ LLMS arxiv, 2024 [กระดาษ]
- งงงวยด้วยความงุนงง: การตัดแต่งข้อมูลตามความงุนงงด้วยโมเดลอ้างอิงขนาดเล็ก arxiv, 2024 [กระดาษ]
- Plug-and-play: วิธีการตัดแต่งกิ่งหลังการฝึกอบรมที่มีประสิทธิภาพสำหรับรุ่นภาษาขนาดใหญ่ ICLR, 2024 [กระดาษ]
- BESA: การตัดแต่งโมเดลภาษาขนาดใหญ่ที่มีการจัดสรร Sparsity พารามิเตอร์ที่มีประสิทธิภาพ arxiv, 2024 [กระดาษ]
- shortgpt: เลเยอร์ในรูปแบบภาษาขนาดใหญ่ซ้ำซ้อนมากกว่าที่คุณคาดไว้ arxiv, 2024 [กระดาษ]
- Nuteprune: การตัดแต่งกิ่งแบบก้าวหน้าอย่างมีประสิทธิภาพกับครูจำนวนมากสำหรับรูปแบบภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ]
- SLICEGPT: บีบอัดแบบจำลองภาษาขนาดใหญ่โดยการลบแถวและคอลัมน์ ICLR, 2024 [กระดาษ] [รหัส]
- Lorashear: แบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพการตัดแต่งกิ่งและการกู้คืนความรู้ arxiv, 2023 [กระดาษ]
- LLM-Pruner: ในการตัดแต่งโครงสร้างของแบบจำลองภาษาขนาดใหญ่ Neurips, 2023 [กระดาษ] [รหัส]
- Sheared Llama: การเร่งรูปแบบภาษาก่อนการฝึกอบรมผ่านการตัดแต่งแบบมีโครงสร้าง Neurips-Enlsp, 2023 [กระดาษ] [รหัส]
- LORAPRUNE: การตัดแต่งกิ่งตรงกับการปรับแต่งพารามิเตอร์ระดับต่ำ arxiv, 2023 [กระดาษ]
การตัดแต่งกิ่งไม่มีโครงสร้าง
- Maskllm: sparsity กึ่งโครงสร้างที่เรียนรู้ได้สำหรับแบบจำลองภาษาขนาดใหญ่ NIPS, 2024 [กระดาษ]
- แบบไดนามิกกระจัดกระจายไม่มีการฝึกอบรม: การปรับแต่งการปรับแต่งฟรีสำหรับ LLMS แบบเบาบาง ICLR, 2024 [กระดาษ]
- Sparsegpt: รุ่นภาษาขนาดใหญ่สามารถตัดแต่งได้อย่างแม่นยำในการถ่ายภาพเดียว ICML, 2023 [กระดาษ] [รหัส]
- วิธีการตัดแต่งกิ่งที่เรียบง่ายและมีประสิทธิภาพสำหรับแบบจำลองภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- การตัดแต่งกิ่งแบบผสมที่มีความไวต่อการยิงแบบหนึ่งสำหรับรุ่นภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ]
การประมาณระดับต่ำ
- SVD-LLM: การสลายตัวของค่าเอกพจน์สำหรับการบีบอัดแบบจำลองภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ] [รหัส]
- ASVD: การสลายตัวของการเปิดใช้งานการสลายตัวของเอกพจน์สำหรับการบีบอัดแบบจำลองภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- การบีบอัดแบบจำลองภาษาด้วยการแยกตัวประกอบระดับต่ำ ICLR, 2022 [กระดาษ]
- TENSORGPT: การบีบอัดอย่างมีประสิทธิภาพของชั้นการฝังใน LLMS ตามการสลายตัวของ Tensor-train arxiv, 2023 [กระดาษ]
- LOSPARSE: การบีบอัดที่มีโครงสร้างของแบบจำลองภาษาขนาดใหญ่ขึ้นอยู่กับการประมาณระดับต่ำและเบาบาง ICML, 2023 [กระดาษ] [รหัส]
การกลั่นความรู้
กล่องสีขาว KD
- DDK: การกลั่นความรู้โดเมนสำหรับแบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพ arxiv, 2024 [กระดาษ]
- ทบทวน Kullback-Leibler Divergence ในการกลั่นความรู้สำหรับแบบจำลองภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ]
- Distillm: ไปสู่การกลั่นที่คล่องตัวสำหรับรุ่นภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ] [รหัส]
- ต่อกฎของช่องว่างความสามารถในรูปแบบภาษากลั่น arxiv, 2023 [กระดาษ] [รหัส]
- Baby Llama: การกลั่นความรู้จากวงดนตรีของครูที่ได้รับการฝึกฝนในชุดข้อมูลขนาดเล็กที่ไม่มีการลงโทษประสิทธิภาพ arxiv, 2023 [กระดาษ]
- การกลั่นความรู้ของแบบจำลองภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- GKD: การกลั่นความรู้ทั่วไปสำหรับโมเดลลำดับที่แท้จริง arxiv, 2023 [กระดาษ]
- เผยแพร่การอัปเดตความรู้ไปยัง LMS ผ่านการกลั่น arxiv, 2023 [กระดาษ] [รหัส]
- น้อยกว่ามากขึ้น: การกลั่นแบบเลเยอร์ที่รู้ตัวสำหรับการบีบอัดแบบจำลองภาษา ICML, 2023 [กระดาษ]
- โทเค็นปรับระดับการกลั่นสำหรับโมเดลภาษาที่มีน้ำหนักแบบไตร่ตรอง arxiv, 2023 [กระดาษ]
กล่องดำ KD
- Zephyr: การกลั่นโดยตรงของการจัดตำแหน่ง LM arxiv, 2023 [กระดาษ]
- การปรับแต่งคำแนะนำด้วย GPT-4 arxiv, 2023 [กระดาษ] [รหัส]
- สิงโต: การกลั่นที่เป็นปฏิปักษ์ของรูปแบบภาษาขนาดใหญ่ที่ปิดแหล่งที่มา arxiv, 2023 [กระดาษ] [รหัส]
- เชี่ยวชาญรูปแบบภาษาขนาดเล็กไปสู่การใช้เหตุผลหลายขั้นตอน ICML, 2023 [กระดาษ] [รหัส]
- กลั่นเป็นขั้นตอน! มีประสิทธิภาพสูงกว่าแบบจำลองภาษาขนาดใหญ่ที่มีข้อมูลการฝึกอบรมน้อยลงและขนาดของรุ่นที่เล็กลง ACL, 2023 [กระดาษ]
- แบบจำลองภาษาขนาดใหญ่คือการให้เหตุผลครู ACL, 2023 [กระดาษ] [รหัส]
- สกอตต์: การกลั่นจากห่วงโซ่ที่สอดคล้องกันด้วยตนเอง ACL, 2023 [กระดาษ] [รหัส]
- การกลั่นโซ่แห่งความคิดเชิงสัญลักษณ์: โมเดลขนาดเล็กสามารถ "คิด" ทีละขั้นตอนได้ ACL, 2023 [กระดาษ]
- การกลั่นความสามารถในการใช้เหตุผลในรูปแบบภาษาขนาดเล็ก ACL, 2023 [กระดาษ] [รหัส]
- การกลั่นการเรียนรู้ในบริบท: การถ่ายโอนความสามารถในการเรียนรู้ไม่กี่ครั้งของแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อน arxiv, 2022 [กระดาษ]
- คำอธิบายจากแบบจำลองภาษาขนาดใหญ่ทำให้ผู้มีเหตุผลเล็ก ๆ ดีขึ้น arxiv, 2022 [กระดาษ]
- ดิสโก้: กลั่น counterfactuals ด้วยแบบจำลองภาษาขนาดใหญ่ arxiv, 2022 [กระดาษ] [รหัส]
การแบ่งปันพารามิเตอร์
- MOBILLAMA: ไปสู่ GPT ที่แม่นยำและมีน้ำหนักเบาอย่างเต็มที่ arxiv, 2024 [กระดาษ]
การฝึกอบรมก่อน
การฝึกอบรมแบบผสมผสาน
- การประมวลผล BFLOAT16 สำหรับเครือข่ายประสาท Arith, 2019 [กระดาษ]
- การศึกษา BFLOAT16 สำหรับการฝึกอบรมการเรียนรู้อย่างลึกซึ้ง Arxiv, 2019 [กระดาษ]
- การฝึกอบรมที่แม่นยำผสม ICLR, 2018 [กระดาษ]
โมเดลการปรับขนาด
- มะนาว: การขยายตัวของแบบจำลองที่ไม่สูญเสีย ICLR, 2024 [กระดาษ]
- เตรียมบทเรียนสำหรับการฝึกอบรมแบบก้าวหน้าเกี่ยวกับรูปแบบภาษา Aaai, 2024 [กระดาษ]
- เรียนรู้ที่จะเติบโตแบบจำลองที่ผ่านการฝึกอบรมสำหรับการฝึกอบรมหม้อแปลงที่มีประสิทธิภาพ ICLR, 2023 [กระดาษ] [รหัส]
- แบบจำลองภาษาที่เร็วกว่า 2x ก่อนการฝึกอบรมผ่านการเติบโตของโครงสร้างที่สวมหน้ากาก arxiv, 2023 [กระดาษ]
- นำโมเดลที่ผ่านการฝึกอบรมมาใช้ใหม่โดยผู้ให้บริการหลายเส้นเพื่อการฝึกอบรมที่มีประสิทธิภาพ Neurips, 2023 [กระดาษ]
- FLM-101B: LLM แบบเปิดและวิธีการฝึกอบรมด้วยงบประมาณ $ 100 K arxiv, 2023 [กระดาษ] [รหัส]
- มรดกความรู้สำหรับแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อน NAACL, 2022 [กระดาษ] [รหัส]
- การฝึกอบรมการจัดฉากสำหรับแบบจำลองภาษาหม้อแปลง ICML, 2022 [กระดาษ] [รหัส]
เทคนิคการเริ่มต้น
- DEEPNET: ปรับขนาดหม้อแปลงเป็น 1,000 ชั้น arxiv, 2022 [กระดาษ] [รหัส]
- การเริ่มต้นเป็นศูนย์: การเริ่มต้นเครือข่ายประสาทด้วยศูนย์และเครือข่ายเท่านั้น TMLR, 2022 [กระดาษ] [รหัส]
- Rezero คือทั้งหมดที่คุณต้องการ: การบรรจบกันอย่างรวดเร็วที่ระดับความลึกขนาดใหญ่ UAI, 2021 [กระดาษ] [รหัส]
- แบทช์อคติการทำให้อคติตกค้างที่เหลือไปยังฟังก์ชั่นข้อมูลประจำตัวในเครือข่ายลึก Neurips, 2020 [กระดาษ]
- การปรับปรุงการเพิ่มประสิทธิภาพของหม้อแปลงผ่านการเริ่มต้นที่ดีขึ้น ICML, 2020 [กระดาษ] [รหัส]
- การกำหนดค่าเริ่มต้น Fixup: การเรียนรู้ที่เหลือโดยไม่มีการทำให้เป็นมาตรฐาน ICLR, 2019 [กระดาษ]
- เกี่ยวกับการเริ่มต้นน้ำหนักในเครือข่ายประสาทลึก Arxiv, 2017 [กระดาษ]
เครื่องมือเพิ่มประสิทธิภาพการฝึกอบรม
- สู่การเรียนรู้แบบจำลองภาษาที่ดีที่สุด arxiv, 2024 [กระดาษ] [รหัส]
- การค้นพบสัญลักษณ์ของอัลกอริทึมการเพิ่มประสิทธิภาพ arxiv, 2023 [กระดาษ]
- โซเฟีย: เครื่องมือเพิ่มประสิทธิภาพลำดับที่สองแบบสุ่มที่ปรับขนาดได้สำหรับแบบจำลองภาษาก่อนการฝึกอบรม arxiv, 2023 [กระดาษ] [รหัส]
การปรับจูนที่มีประสิทธิภาพ
การปรับแต่งพารามิเตอร์อย่างละเอียด
การปรับแต่งอะแดปเตอร์
- Opendelta: ไลบรารีแบบปลั๊กแอนด์เพลย์สำหรับการปรับพารามิเตอร์ที่มีประสิทธิภาพของรุ่นที่ผ่านการฝึกอบรมมาก่อน การสาธิต ACL, 2023 [กระดาษ] [รหัส]
- LLM-ADAPTERS: ตระกูลอะแดปเตอร์สำหรับการปรับแต่งพารามิเตอร์อย่างละเอียดของแบบจำลองภาษาขนาดใหญ่ Emnlp, 2023 [กระดาษ] [รหัส]
- pompacter: ชั้นอะแดปเตอร์ hypercomplex ระดับต่ำที่มีประสิทธิภาพ Neurips, 2023 [กระดาษ] [รหัส]
- การปรับจูนพารามิเตอร์แบบไม่กี่พารามิเตอร์นั้นดีกว่าและถูกกว่าการเรียนรู้ในบริบท Neurips, 2022 [กระดาษ] [รหัส]
- Meta-Adapters: พารามิเตอร์การปรับจูนไม่กี่ครั้งผ่านการเรียนรู้ meta-learning Automl, 2022 [กระดาษ]
- Adamix: ส่วนผสมของการปรับเปลี่ยนสำหรับการปรับแต่งโมเดลที่มีประสิทธิภาพพารามิเตอร์ Emnlp, 2022 [กระดาษ] [รหัส]
- Sparseadapter: วิธีง่ายๆในการปรับปรุงประสิทธิภาพพารามิเตอร์ของอะแดปเตอร์ Emnlp, 2022 [กระดาษ] [รหัส]
การปรับตัวระดับต่ำ
- Hydalora: สถาปัตยกรรม Lora แบบไม่สมมาตรสำหรับการปรับแต่งที่มีประสิทธิภาพ Neurips, 2024 [กระดาษ]
- LOFIT: การปรับแต่งการปรับแต่งการเป็นตัวแทน LLM arxiv, 2024 [กระดาษ]
- ส่วนผสมของพื้นผิวในการปรับระดับต่ำ arxiv, 2024 [กระดาษ] [รหัส]
- MEFT: การปรับแต่งหน่วยความจำอย่างละเอียดผ่านอะแดปเตอร์กระจัดกระจาย ACL, 2024 [กระดาษ]
- Lora พบกับการออกกลางคันภายใต้กรอบการทำงานแบบครบวงจร arxiv, 2024 [กระดาษ]
- Star: ข้อ จำกัด Lora ด้วยการเรียนรู้แบบไดนามิกสำหรับการปรับแต่งข้อมูลแบบจำลองภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ]
- LORA+: การปรับระดับต่ำอย่างมีประสิทธิภาพของรุ่นขนาดใหญ่ arxiv, 2024 [กระดาษ]
- LORA-FA: การปรับระดับต่ำของหน่วยความจำสำหรับโมเดลภาษาขนาดใหญ่ปรับแต่ง arxiv, 2023 [กระดาษ]
- LORAHUB: การวางนัยทั่วไปข้ามงานที่มีประสิทธิภาพผ่านองค์ประกอบ LORA แบบไดนามิก arxiv, 2023 [กระดาษ] [รหัส]
- Longlora: การปรับแต่งแบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพยาวนานอย่างมีประสิทธิภาพ arxiv, 2023 [กระดาษ] [รหัส]
- การกำหนดเส้นทางอะแดปเตอร์หลายหัวสำหรับการวางนัยทั่วไปข้ามงาน Neurips, 2023 [กระดาษ] [รหัส]
- การจัดสรรงบประมาณแบบปรับตัวสำหรับการปรับแต่งพารามิเตอร์อย่างละเอียด ICLR, 2023 [กระดาษ]
- Dylora: การปรับค่าพารามิเตอร์ของโมเดลที่ผ่านการฝึกฝนโดยใช้การปรับตัวต่ำแบบไม่ค้นหาแบบไดนามิก EACL, 2023 [กระดาษ] [รหัส]
- TIED-LORA: เพิ่มประสิทธิภาพพารามิเตอร์ของ LORA ด้วยการผูกน้ำหนัก arxiv, 2023 [กระดาษ]
- LORA: การปรับระดับต่ำของแบบจำลองภาษาขนาดใหญ่ ICLR, 2022 [กระดาษ] [รหัส]
การปรับแต่งคำนำหน้า
- LLAMA-ADAPTER: การปรับแต่งแบบจำลองภาษาอย่างมีประสิทธิภาพด้วยความสนใจเป็นศูนย์ arxiv, 2023 [กระดาษ] [รหัส]
- คำนำหน้าการปรับแต่ง: การเพิ่มประสิทธิภาพการแจ้งเตือนอย่างต่อเนื่องสำหรับการสร้าง ACL, 2021 [กระดาษ] [รหัส]
การปรับแต่ง
- บีบอัดจากนั้นพรอมต์: การปรับปรุงการแลกเปลี่ยนความแม่นยำของการอนุมาน LLM ด้วยพรอมต์ที่สามารถถ่ายโอนได้ arxiv, 2023 [กระดาษ]
- GPT ก็เข้าใจเช่นกัน AI เปิด, 2023 [กระดาษ] [รหัส]
- การฝึกอบรมหลายแบบหลายงานของพรอมต์แบบแยกส่วนสำหรับการเรียนรู้ไม่กี่นัด ACL, 2023 [กระดาษ] [รหัส]
- การปรับจูนแบบมัลติทาสก์เปิดใช้งานการเรียนรู้การถ่ายโอนพารามิเตอร์ที่มีประสิทธิภาพ ICLR, 2023 [กระดาษ]
- PPT: การปรับแต่งพร้อมที่ได้รับการฝึกอบรมล่วงหน้าสำหรับการเรียนรู้ไม่กี่นัด ACL, 2022 [กระดาษ] [รหัส]
- การปรับแต่งพารามิเตอร์ที่มีประสิทธิภาพทำให้การดึงข้อความประสาทแบบทั่วไปและสอบเทียบ Emnlp-Findings, 2022 [กระดาษ] [รหัส]
- P-tuning V2: การปรับแต่งพร้อมใช้งานสามารถเทียบได้กับ finetuning ในระดับสากลทั่วทั้งเครื่องชั่งและงาน, ACL-Short, 2022 [กระดาษ] [รหัส]
- กำลังของสเกลสำหรับการปรับแต่งพารามิเตอร์ที่มีประสิทธิภาพ Emnlp, 2021 [กระดาษ]
การปรับจูนหน่วยความจำอย่างละเอียด
- การศึกษาการเพิ่มประสิทธิภาพสำหรับการปรับแต่งแบบจำลองภาษาขนาดใหญ่ arxiv, 2024/ins> [กระดาษ]
- เมทริกซ์กระจัดกระจายในการปรับแต่งแบบจำลองภาษาขนาดใหญ่ arxiv, 2024/ins> [กระดาษ]
- Galore: การฝึก LLM ที่มีประสิทธิภาพโดยหน่วยความจำโดยการฉายระดับต่ำ arxiv, 2024/ins> [กระดาษ]
- Reft: การเป็นตัวแทน finetuning สำหรับแบบจำลองภาษา arxiv, 2024/ins> [กระดาษ]
- Lisa: การสุ่มตัวอย่างความสำคัญแบบเลเยอร์สำหรับการปรับแต่งโมเดลภาษาขนาดใหญ่ที่มีประสิทธิภาพในการปรับแต่ง arxiv, 2024/ins> [กระดาษ]
- Bitdelta: การปรับแต่งของคุณอาจมีค่าเพียงเล็กน้อยเท่านั้น arxiv, 2024/ins> [กระดาษ]
- การสุ่มตัวอย่างแถวคอลัมน์ผู้ชนะทั้งหมดสำหรับการปรับโมเดลภาษาที่มีประสิทธิภาพของหน่วยความจำ Neurips, 2023 [กระดาษ] [รหัส]
- การปรับแต่งการเลือกแบบเลือกอย่างมีประสิทธิภาพ ICML Workshop, 2023 [กระดาษ]
- การปรับแต่งพารามิเตอร์แบบเต็มสำหรับแบบจำลองภาษาขนาดใหญ่ที่มีทรัพยากร จำกัด arxiv, 2023 [กระดาษ] [รหัส]
- แบบจำลองภาษาที่ปรับแต่งด้วยการส่งต่อ Neurips, 2023 [กระดาษ] [รหัส]
- การปรับจูนหน่วยความจำอย่างละเอียดของแบบจำลองภาษาขนาดใหญ่ที่บีบอัดผ่านปริมาณจำนวนเต็มย่อย 4 บิต Neurips, 2023 [กระดาษ]
- LoftQ: Lora-Fine-Tuning-Aware Quantization สำหรับรุ่นภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- QA-LORA: การปรับระดับต่ำของแบบจำลองภาษาขนาดใหญ่ที่รับรู้เชิงปริมาณ arxiv, 2023 [กระดาษ] [รหัส]
- Qlora: การเพิ่มประสิทธิภาพอย่างมีประสิทธิภาพของ LLMs เชิงปริมาณ Neurips, 2023 [กระดาษ] [code1] [code2]
การปรับแต่งแบบ Moe-Epervised-Fine
- ให้ผู้เชี่ยวชาญติดอยู่กับคนสุดท้ายของเขา: การปรับจูนผู้เชี่ยวชาญด้านการปรับแต่งสำหรับแบบจำลองภาษาขนาดใหญ่ทางสถาปัตยกรรมที่กระจัดกระจาย arxiv, 2024 [กระดาษ]
การอนุมานที่มีประสิทธิภาพ
การถอดรหัสแบบขนาน
- CLLMS: แบบจำลองภาษาขนาดใหญ่ที่สอดคล้องกัน arxiv, 2024 [กระดาษ]
- เข้ารหัสหนึ่งครั้งและถอดรหัสแบบขนาน: การถอดรหัสหม้อแปลงที่มีประสิทธิภาพ arxiv, 2024 [กระดาษ]
การถอดรหัสการเก็งกำไร
- MagicDec: ทำลายการแลกเปลี่ยนเวลาแฝงสำหรับการสร้างบริบทที่ยาวนานด้วยการถอดรหัสการเก็งกำไร arxiv, 2024 [กระดาษ]
- DEPT: การถอดรหัสด้วยความสนใจแบบต้นไม้แฟลชสำหรับการอนุมาน LLM ที่มีโครงสร้างต้นไม้ที่มีประสิทธิภาพ arxiv, 2024 [กระดาษ]
- Layerskip: เปิดใช้งานการอนุมานก่อนและการถอดรหัสด้วยตนเอง arxiv, 2024 [กระดาษ]
- Triforce: การเร่งความเร็วแบบไม่สูญเสียของการสร้างลำดับยาวด้วยการถอดรหัสการเก็งกำไรแบบลำดับชั้น arxiv, 2024 [กระดาษ]
- ส่วนที่เหลือ: การถอดรหัสการเก็งกำไรแบบดึงข้อมูล arxiv, 2024 [กระดาษ]
- Tandem Transformers สำหรับการอนุมาน LLM ที่มีประสิทธิภาพ arxiv, 2024 [กระดาษ]
- ผ่าน: การสุ่มตัวอย่างแบบเก็งกำไรแบบขนาน Neurips Workshop, 2023 [กระดาษ]
- เร่งการอนุมานของหม้อแปลงสำหรับการแปลผ่านการถอดรหัสแบบขนาน ACL, 2023 [กระดาษ] [รหัส]
- เมดูซ่า: เฟรมเวิร์กง่าย ๆ สำหรับการเร่งรุ่น LLM ด้วยหัวถอดรหัสหลายหัว บล็อก, 2023 [บล็อก] [รหัส]
- การอนุมานอย่างรวดเร็วจากหม้อแปลงผ่านการถอดรหัสการเก็งกำไร ICML, 2023 [กระดาษ]
- เร่งการอนุมาน LLM ด้วยการถอดรหัสการเก็งกำไร ICML Workshop, 2023 [กระดาษ]
- เร่งการถอดรหัสแบบจำลองภาษาขนาดใหญ่ด้วยการสุ่มตัวอย่างแบบเก็งกำไร arxiv, 2023 [กระดาษ]
- การถอดรหัสการเก็งกำไรด้วยตัวถอดรหัสตัวเล็กขนาดใหญ่ Neurips, 2023 [กระดาษ] [รหัส]
- Specinfer: เร่งความเร็ว LLM ที่ให้บริการด้วยการอนุมานการเก็งกำไรและการตรวจสอบต้นไม้โทเค็น arxiv, 2023 [กระดาษ] [รหัส]
- การอนุมานที่มีการอ้างอิง: การเร่งความเร็วแบบไม่สูญเสียของแบบจำลองภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- เมล็ดพันธุ์: เร่งการก่อสร้างต้นไม้ให้เหตุผลผ่านการถอดรหัสการเก็งกำไรตามกำหนดเวลา arxiv, 2024 [กระดาษ]
การเพิ่มประสิทธิภาพ KV-cache
- VL-CACHE: การบีบอัดแคช KV แบบ Sparsity และ Modality ที่รับรู้สำหรับการเร่งการอนุมานแบบจำลองการมองเห็น arxiv, 2024 [กระดาษ]
- Minerference 1.0: เร่งการเติมเงินล่วงหน้าสำหรับ LLMs บริบทยาวผ่านความสนใจแบบเบาบางแบบไดนามิก arxiv, 2024 [กระดาษ]
- KVSharer: การอนุมานอย่างมีประสิทธิภาพผ่านการแชร์แคช KV ที่แตกต่างกันอย่างชาญฉลาด arxiv, 2024 [กระดาษ]
- DuoAttention: การอนุมาน LLM บริบทยาวที่มีประสิทธิภาพด้วยการดึงและสตรีมมิ่งหัว arxiv, 2024 [กระดาษ]
- Lazyllm: การตัดแต่งโทเค็นแบบไดนามิกสำหรับการอนุมาน LLM บริบทที่มีประสิทธิภาพ arxiv, 2024 [กระดาษ]
- Palu: การบีบอัด KV-cache ด้วยการฉายระดับต่ำ arxiv, 2024 [กระดาษ] [รหัส]
- Look-M: การเพิ่มประสิทธิภาพแบบ look-once ใน KV Cache สำหรับการอนุมานบริบทยาวหลายรูปแบบที่มีประสิทธิภาพ arxiv, 2024 [กระดาษ]
- D2O: การปฏิบัติที่เลือกปฏิบัติแบบไดนามิกสำหรับการอนุมานการกำเนิดที่มีประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ]
- QUEST: Sparsity ที่รับรู้แบบสอบถามสำหรับการอนุมาน LLM บริบทยาวที่มีประสิทธิภาพ ICML, 2024 [กระดาษ]
- ลดขนาดแคชคีย์-ค่าของหม้อแปลงด้วยความสนใจข้ามชั้น arxiv, 2024 [กระดาษ]
- Snapkv: LLM รู้ว่าคุณกำลังมองหาอะไรก่อนรุ่น arxiv, 2024 [กระดาษ]
- แบบจำลองภาษาขนาดใหญ่ที่ยึดตาม arxiv, 2024 [กระดาษ]
- KVQUANT: ไปสู่ความยาวบริบท 10 ล้านการอนุมาน LLM กับ KV Cache Quantization arxiv, 2024 [กระดาษ]
- Gear: สูตรการบีบอัดแคช KV ที่มีประสิทธิภาพสำหรับการอนุมานการกำเนิด LLM ใกล้สูญเสีย arxiv, 2024 [กระดาษ]
- การบีบอัดหน่วยความจำแบบไดนามิก: การติดตั้ง LLM สำหรับการอนุมานแบบเร่งความเร็ว arxiv, 2024 [กระดาษ]
- ไม่มีโทเค็นที่เหลืออยู่ข้างหลัง: การบีบอัดแคช KV ที่เชื่อถือได้ผ่านปริมาณความแม่นยำผสมที่มีความสำคัญ arxiv, 2024 [กระดาษ]
- รับมากขึ้นด้วยน้อยลง: การสังเคราะห์การเกิดซ้ำด้วยการบีบอัดแคช KV สำหรับการอนุมาน LLM ที่มีประสิทธิภาพ arxiv, 2024 [กระดาษ]
- WKVQuant: การหาปริมาณน้ำหนักและคีย์/ค่าแคชสำหรับรุ่นภาษาขนาดใหญ่ได้รับมากขึ้น arxiv, 2024 [กระดาษ]
- เกี่ยวกับประสิทธิภาพของนโยบายการขับไล่สำหรับการอนุมานรูปแบบภาษาที่มีข้อ จำกัด ของคีย์ arxiv, 2024 [กระดาษ]
- Kivi: การปรับปริมาณแบบอสมมาตร 2 บิตแบบไม่สมมาตรสำหรับแคช KV arxiv, 2024 [กระดาษ] [รหัส]
- โมเดลบอกคุณว่าจะทิ้งอะไร: การบีบอัดแคช KV แบบปรับตัวสำหรับ LLMS ICLR, 2024 [กระดาษ]
- skipdecode: การถอดรหัสข้ามแบบอัตโนมัติด้วยการแบทช์และการแคชสำหรับการอนุมาน LLM ที่มีประสิทธิภาพ arxiv, 2023 [กระดาษ]
- H2O: Oracle ผู้ตีหนักเพื่อการอนุมานการกำเนิดที่มีประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่ Neurips, 2023 [กระดาษ]
- Scissorhands: ใช้ประโยชน์จากการคงอยู่ของสมมติฐานความสำคัญสำหรับการบีบอัดแคช LLM KV ในเวลาทดสอบ Neurips, 2023 [กระดาษ]
- การตัดแต่งกิ่งบริบทแบบไดนามิกสำหรับหม้อแปลงอัตโนมัติที่มีประสิทธิภาพและตีความได้ arxiv, 2023 [กระดาษ]
สถาปัตยกรรมที่มีประสิทธิภาพ
ความสนใจที่มีประสิทธิภาพ
การแบ่งปันความสนใจตาม
- Loma: ความสนใจของหน่วยความจำที่ถูกบีบอัดไม่สูญเสีย arxiv, 2024 [กระดาษ]
- Mobilellm: การเพิ่มประสิทธิภาพแบบจำลองภาษาพารามิเตอร์ย่อยสำหรับกรณีการใช้งานบนอุปกรณ์ arxiv, 2024 [กระดาษ]
- GQA: การฝึกอบรมแบบจำลองหม้อแปลงหลายแบบทั่วไปจากจุดตรวจหลายหัว Emnlp, 2023 [กระดาษ]
- การถอดรหัส Transformer Fast: หนึ่งหัวเขียนคือทั้งหมดที่คุณต้องการ Arxiv, 2019 [กระดาษ]
การลดข้อมูลคุณสมบัติ
- Nyströmformer: อัลกอริทึมที่ใช้Nyströmสำหรับการประมาณความตั้งใจของตนเอง Aaai, 2021 [กระดาษ] [รหัส]
- ช่องทาง transformer: การกรองความซ้ำซ้อนตามลำดับสำหรับการประมวลผลภาษาที่มีประสิทธิภาพ Neurips, 2020 [กระดาษ] [รหัส]
- Set Transformer: กรอบการทำงานสำหรับเครือข่ายประสาทแบบพรวดพินน้ำตามความสนใจ ICML, 2019 [กระดาษ]
เคอร์เนลหรือระดับต่ำ
- Loki: คีย์ระดับต่ำสำหรับความสนใจเบาบางที่มีประสิทธิภาพ ICML Workshop, 2023 [กระดาษ]
- Sumformer: การประมาณสากลสำหรับหม้อแปลงที่มีประสิทธิภาพ ICML Workshop, 2023 [กระดาษ]
- Flurka: ความสนใจระดับต่ำและเคอร์เนลที่หลอมรวมเร็ว arxiv, 2023 [กระดาษ]
- Scatterbrain: รวมความสนใจกระจัดกระจายและระดับต่ำ Neurlps, 2021 [กระดาษ] [รหัส]
- ทบทวนความสนใจกับนักแสดง ICLR, 2021 [กระดาษ] [รหัส]
- ความสนใจในคุณสมบัติแบบสุ่ม ICLR, 2021 [กระดาษ]
- Linformer: ความตั้งใจของตนเองด้วยความซับซ้อนเชิงเส้น arxiv, 2020 [กระดาษ] [รหัส]
- การรู้จำเสียงพูดแบบ end-to-end ที่มีน้ำหนักเบาและมีประสิทธิภาพโดยใช้หม้อแปลงระดับต่ำ ICASSP, 2020 [กระดาษ]
- Transformers เป็น RNNS: หม้อแปลงอัตโนมัติที่รวดเร็วด้วยความสนใจเชิงเส้น ICML, 2020 [กระดาษ] [รหัส]
กลยุทธ์รูปแบบคงที่
- แบบจำลองภาษาที่ให้ความสนใจเชิงเส้นอย่างง่ายทำให้เกิดการแลกเปลี่ยนการเรียกคืน arxiv, 2024 [กระดาษ]
- Lightning Attention-2: อาหารกลางวันฟรีสำหรับการจัดการความยาวลำดับไม่ จำกัด ในรุ่นภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ] [รหัส]
- ความสนใจเชิงสาเหตุที่เร็วกว่าลำดับขนาดใหญ่ผ่านความสนใจแฟลชกระจัดกระจาย ICML Workshop, 2023 [กระดาษ]
- PoolingFormer: การสร้างแบบจำลองเอกสารยาวพร้อมความสนใจ ICML, 2021 [กระดาษ]
- Big Bird: Transformers สำหรับลำดับที่ยาวนานขึ้น Neurips, 2020 [กระดาษ] [รหัส]
- Longformer: หม้อแปลงเอกสารยาว arxiv, 2020 [กระดาษ] [รหัส]
- การตั้งใจด้วยตนเองแบบบล็อกสำหรับการทำความเข้าใจเอกสารที่ยาวนาน Emnlp, 2020 [กระดาษ] [รหัส]
- สร้างลำดับยาวด้วยหม้อแปลงเบาบาง Arxiv, 2019 [กระดาษ]
กลยุทธ์รูปแบบที่เรียนรู้ได้
- MOA: ส่วนผสมของความสนใจเบาบางสำหรับการบีบอัดแบบจำลองภาษาขนาดใหญ่อัตโนมัติ arxiv, 2024 [กระดาษ]
- HyperAttention: ความสนใจบริบทยาวในเวลาใกล้เคียง arxiv, 2023 [กระดาษ] [รหัส]
- Clusterformer: การจัดกลุ่มประสาทความสนใจสำหรับหม้อแปลงที่มีประสิทธิภาพและมีประสิทธิภาพ ACL, 2022 [กระดาษ]
- นักปฏิรูป: หม้อแปลงที่มีประสิทธิภาพ ICLR, 2022 [กระดาษ] [รหัส]
- ความสนใจที่กระจัดกระจาย ICML, 2020 [กระดาษ]
- หม้อแปลงเร็วด้วยความสนใจแบบคลัสเตอร์ Neurips, 2020 [กระดาษ] [รหัส]
- ความสนใจที่เบาบางตามเนื้อหาที่มีประสิทธิภาพด้วยหม้อแปลงเส้นทาง tacl, 2020 [กระดาษ] [รหัส]
ส่วนผสมของผู้เชี่ยวชาญ
LLMS ที่ใช้ MOE
- Self-Moe: ไปสู่แบบจำลองภาษาขนาดใหญ่ที่มีความเชี่ยวชาญด้วยตนเอง arxiv, 2024 [กระดาษ]
- Lory: ส่วนผสมของ experts ที่แตกต่างกันอย่างเต็มที่สำหรับโมเดลภาษาแบบอัตโนมัติก่อนการฝึกอบรม, 2024 [กระดาษ]
- Jetmoe: การเข้าถึงประสิทธิภาพของ Llama2 ด้วย 0.1m ดอลลาร์, 2024 [กระดาษ]
- ผู้เชี่ยวชาญมีค่าหนึ่งโทเค็น: การประสาน LLMs ผู้เชี่ยวชาญหลายคนในฐานะผู้ทั่วไปผ่านการกำหนดเส้นทางโทเค็นผู้เชี่ยวชาญ, 2024 [กระดาษ]
- ส่วนผสมของความลึก: การจัดสรรการคำนวณแบบไดนามิกในโมเดลภาษาที่ใช้หม้อแปลง, 2024 [กระดาษ]
- Branch-Train-Mix: Mixing Expert LLMs ลงในส่วนผสมของ Experts LLM, 2024 [กระดาษ]
- Mixtral ของผู้เชี่ยวชาญ arxiv, 2024 [กระดาษ] [รหัส]
- Mistral 7b arxiv, 2023 [กระดาษ] [รหัส]
- Pangu-σ: ไปสู่โมเดลภาษาพารามิเตอร์ล้านล้านด้วยการคำนวณที่แตกต่างกันแบบเบาบาง arxiv, 2023 [กระดาษ]
- Switch Transformers: ปรับสเกลเป็นรุ่นพารามิเตอร์ล้านล้านด้วย sparsity ที่เรียบง่ายและมีประสิทธิภาพ JMLR, 2022 [กระดาษ] [รหัส]
- การสร้างแบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพด้วยส่วนผสมของผู้เชี่ยวชาญ Emnlp, 2022 [กระดาษ] [รหัส]
- เลเยอร์พื้นฐาน: การฝึกฝนแบบจำลองขนาดใหญ่ที่มีขนาดใหญ่ง่าย ICML, 2021 [กระดาษ] [รหัส]
- GSHARD: ปรับขนาดรุ่นยักษ์ที่มีการคำนวณแบบมีเงื่อนไขและการทำลายล้างอัตโนมัติ ICLR, 2021 [กระดาษ]
การเพิ่มประสิทธิภาพ MOE ระดับอัลกอริทึม
- Seer-Moe: ประสิทธิภาพของความเชี่ยวชาญที่กระจัดกระจายผ่านการทำให้เป็นมาตรฐานสำหรับการผสมผสานของ experts arxiv, 2024/ins> [กระดาษ]
- การปรับขนาดกฎหมายสำหรับส่วนผสมของผู้เชี่ยวชาญอย่างละเอียด arxiv, 2024/ins> [กระดาษ]
- ภาษาตลอดชีวิตก่อนหน้านี้กับผู้เชี่ยวชาญด้านการแจกจ่าย ICML, 2023 [กระดาษ]
- ส่วนผสมของผู้เชี่ยวชาญมาพบกับการปรับแต่งคำแนะนำ: การผสมผสานที่ชนะสำหรับรุ่นภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ]
- ส่วนผสมของ experts กับการกำหนดเส้นทางการเลือกผู้เชี่ยวชาญ Neurips, 2022 [กระดาษ]
- StableMoe: กลยุทธ์การกำหนดเส้นทางที่มั่นคงสำหรับการผสมผสานของผู้เชี่ยวชาญ ACL, 2022 [กระดาษ] [รหัส]
- ในการล่มสลายของการผสมผสานของผู้เชี่ยวชาญ Neurips, 2022 [กระดาษ]
บริบทยาว LLMS
การคาดการณ์และการแก้ไข
- หินสองก้อนตีนกหนึ่งตัว: การเข้ารหัสตำแหน่ง Bilevel เพื่อการคาดการณ์ที่ยาวขึ้น ICML, 2024 [กระดาษ]
- ∞-bench: ขยายการประเมินบริบทที่ยาวเกินกว่าโทเค็น 100K arxiv, 2024 [กระดาษ]
- Resonance Rope: การปรับปรุงความยาวบริบททั่วไปของแบบจำลองภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ] [รหัส]
- Longrope: ขยายหน้าต่างบริบท LLM เกิน 2 ล้านโทเค็น arxiv, 2024 [กระดาษ]
- e^2-llm: การขยายความยาวที่มีประสิทธิภาพและรุนแรงของแบบจำลองภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ]
- ปรับขนาดกฎหมายของการคาดการณ์บนเชือก arxiv, 2023 [กระดาษ]
- หม้อแปลงที่มีความยาวพรสวรรค์ ACL, 2023 [กระดาษ] [รหัส]
- ขยายหน้าต่างบริบทของแบบจำลองภาษาขนาดใหญ่ผ่านการแก้ไขตำแหน่ง arxiv, 2023 [กระดาษ]
- การแก้ไข NTK บล็อก, 2023 [Reddit Post]
- เส้นด้าย: การขยายหน้าต่างบริบทที่มีประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- Clex: การคาดการณ์ความยาวอย่างต่อเนื่องสำหรับรุ่นภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- Pose: การขยายหน้าต่างบริบทที่มีประสิทธิภาพของ LLMs ผ่านการฝึกซ้อมแบบข้ามตำแหน่ง arxiv, 2023 [กระดาษ] [รหัส]
- การแก้ไขการทำงานสำหรับตำแหน่งสัมพัทธ์ช่วยปรับปรุงหม้อแปลงบริบทที่ยาวนาน arxiv, 2023 [กระดาษ]
- รถไฟสั้นทดสอบยาว: ความสนใจด้วยอคติเชิงเส้นช่วยให้การคาดการณ์ความยาวอินพุต ICLR, 2022 [กระดาษ] [รหัส]
- สำรวจความยาวทั่วไปในรูปแบบภาษาขนาดใหญ่ Neurips, 2022 [กระดาษ]
โครงสร้างกำเริบ
- เครือข่าย Retentive: ผู้สืบทอดของ Transformer สำหรับโมเดลภาษาขนาดใหญ่ arxiv, 2023 [กระดาษ] [รหัส]
- หม้อแปลงหน่วยความจำกำเริบ Neurips, 2022 [กระดาษ] [รหัส]
- หม้อแปลงกระแสไฟฟ้ากลับคืน Neurips, 2022 [กระดาษ] [รหัส]
- ∞-Former: หม้อแปลงหน่วยความจำที่ไม่มีที่สิ้นสุด ACL, 2022 [กระดาษ] [รหัส]
- Memformer: หม้อแปลงหน่วยความจำที่ไม่ได้รับการแก้ไขสำหรับการสร้างแบบจำลองลำดับ AACL-Findings, 2020 [กระดาษ] [รหัส]
- Transformer-XL: โมเดลภาษาที่เอาใจใส่เกินกว่าบริบทที่มีความยาวคงที่ ACL, 2019 [กระดาษ] [รหัส]
การแบ่งส่วนและหน้าต่างบานเลื่อน
- XL3M: เฟรมเวิร์กที่ปราศจากการฝึกอบรมสำหรับการขยายความยาว LLM ตามการอนุมานส่วนที่ชาญฉลาด arxiv, 2024 [กระดาษ]
- Transformerfam: ความสนใจข้อเสนอแนะคือหน่วยความจำที่ใช้งานได้ arxiv, 2024 [กระดาษ]
- การขยายบริบทที่ไร้เดียงสาของ Bayes สำหรับแบบจำลองภาษาขนาดใหญ่ NAACL, 2024 [กระดาษ]
- ไม่ทิ้งบริบทไว้เบื้องหลัง: หม้อแปลงบริบทที่ไม่มีที่สิ้นสุดที่มีประสิทธิภาพด้วยความสนใจ Infini arxiv, 2024 [กระดาษ]
- การฝึกอบรม LLMS ผ่านข้อความที่ถูกบีบอัดตามธรรมชาติ arxiv, 2024 [กระดาษ]
- LM-Infinite: การวางนัยทั่วไปที่มีความยาวสุดขีดสำหรับแบบจำลองภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ]
- การปรับสเกลบริบทระยะยาวที่ไม่ต้องฝึกอบรมของแบบจำลองภาษาขนาดใหญ่ arxiv, 2024 [กระดาษ] [รหัส]
- การสร้างแบบจำลองภาษาที่มีบริบทยาวพร้อมการเข้ารหัสบริบทแบบขนาน arxiv, 2024 [กระดาษ] [รหัส]
- เพิ่มขึ้นจาก 4K เป็น 400K: ขยายบริบทของ LLM ด้วยการเปิดใช้งาน Beacon arxiv, 2024 [กระดาษ] [รหัส]
- LLM อาจจะ longlm: หน้าต่างบริบท LLM ขยายตัวเองโดยไม่ต้องปรับแต่ง arxiv, 2024 [กระดาษ] [รหัส]
- ขยายหน้าต่างบริบทของแบบจำลองภาษาขนาดใหญ่ผ่านการบีบอัดความหมาย arxiv, 2023 [กระดาษ]
- โมเดลภาษาสตรีมมิ่งที่มีประสิทธิภาพพร้อมอ่างล้างมือ arxiv, 2023 [กระดาษ] [รหัส]
- หน้าต่างบริบทแบบขนานสำหรับโมเดลภาษาขนาดใหญ่ ACL, 2023 [กระดาษ] [รหัส]
- Longnet: ปรับสเกลหม้อแปลงเป็น 1,000,000,000 โทเค็น arxiv, 2023 [กระดาษ] [รหัส]
- ความเข้าใจข้อความยาวที่มีประสิทธิภาพด้วยโมเดลข้อความสั้น ๆ tacl, 2023 [กระดาษ] [รหัส]
การเสริมหน่วยความจำ
- INFLLM: เปิดตัวความสามารถที่แท้จริงของ LLM เพื่อทำความเข้าใจลำดับที่ยาวมากด้วยหน่วยความจำที่ปราศจากการฝึกอบรม arxiv, 2024 [กระดาษ]
- Landmark Attention: Random-Access Infinite Context Length for Transformers, arXiv, 2023 [Paper] [Code]
- Augmenting Language Models with Long-Term Memory, NeurIPS, 2023 [กระดาษ]
- Unlimiformer: Long-Range Transformers with Unlimited Length Input, NeurIPS, 2023 [Paper] [Code]
- Focused Transformer: Contrastive Training for Context Scaling, NeurIPS, 2023 [Paper] [Code]
- Retrieval meets Long Context Large Language Models, arXiv, 2023 [กระดาษ]
- Memorizing Transformers, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
State Space Models
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [กระดาษ]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [กระดาษ]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [กระดาษ]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [กระดาษ]
- Block-State Transformers, NeurIPS, 2023 [กระดาษ]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces, NeurIPS, 2022 [Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [กระดาษ]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [กระดาษ]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [กระดาษ]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [กระดาษ]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [กระดาษ]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [กระดาษ]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [กระดาษ]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [กระดาษ]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [กระดาษ]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [กระดาษ]
- Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [กระดาษ]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [กระดาษ]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [กระดาษ]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [กระดาษ]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [กระดาษ]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [กระดาษ]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [กระดาษ]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [กระดาษ]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [กระดาษ]
Prompt Engineering
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [กระดาษ]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [กระดาษ]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [กระดาษ]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [กระดาษ]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [กระดาษ]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [กระดาษ]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [กระดาษ]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [กระดาษ]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [กระดาษ]
- Learning to Reason with LLMs, Website, 2024 [Html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [กระดาษ]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [กระดาษ]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [กระดาษ]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [กระดาษ]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [กระดาษ]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS, 2022 [กระดาษ]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [กระดาษ]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [กระดาษ]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [กระดาษ]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [กระดาษ]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [กระดาษ]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [กระดาษ]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [กระดาษ]
Prompt Generation
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [กระดาษ]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [กระดาษ]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [กระดาษ]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 , [กระดาษ]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [กระดาษ]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [กระดาษ]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [กระดาษ]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [กระดาษ]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [กระดาษ]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [กระดาษ]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [กระดาษ]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [กระดาษ]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [กระดาษ]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [กระดาษ]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [กระดาษ]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [กระดาษ]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [กระดาษ]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [กระดาษ]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [กระดาษ]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [กระดาษ]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [กระดาษ]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [กระดาษ]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [กระดาษ]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [กระดาษ]
- Fairness in Serving Large Language Models, arXiv, 2023 [กระดาษ]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [กระดาษ]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS, 2022 [Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [Blog]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [กระดาษ]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [กระดาษ]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [กระดาษ]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [กระดาษ]
LLM Frameworks
| Efficient Training | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | | | |
| Megatron [Code] | | | |
| ColossalAI [Code] | | | |
| Nanotron [Code] | | | |
| MegaBlocks [Code] | | | |
| FairScale [Code] | | | |
| Pax [Code] | | | |
| Composer [Code] | | | |
| OpenLLM [Code] | | | |
| LLM-Foundry [Code] | | | |
| vLLM [Code] | | | |
| TensorRT-LLM [Code] | | | |
| TGI [Code] | | | |
| RayLLM [Code] | | | |
| MLC LLM [Code] | | | |
| Sax [Code] | | | |
| Mosec [Code] | | | |


