효율적인 대형 언어 모델 : 설문 조사
효율적인 대형 언어 모델 : 설문 조사 [ARXIV] (버전 1 : 12/06/2023; 버전 2 : 12/23/2023; 버전 3 : 01/31/2024; 버전 4 : 05/23/2024, 기계 학습 연구에서 트랜잭션의 카메라 준비 버전)
Zhongwei Wan 1 , Xin Wang 1 , Che Liu 2 , Samiul Alam 1 , Yu Zheng 3 , Jiachen Liu 4 , Zhongnan Qu 5 , Shen Yan 6 , Yi Zhu 7 , Quanlu Zhang 8 , Mosharaf Chowdhury 4 , Mi Zhang 1
1 오하이오 주립 대학, 2 Imperial College London, 3 미시간 주립 대학교, 4 명의 미시간 대학교, 5 Amazon AWS AI, 6 Google Research, 7 Boson AI, 8 Microsoft Research Asia
➢ News : 2024 년 5 월 TMLR (Machine Learning Research)의 트랜잭션에 의해 설문 조사가 공식적으로 수락되었습니다. 카메라 준비 버전은 다음과 같습니다. [OpenReview]
@article{wan2023efficient,
title={Efficient large language models: A survey},
author={Wan, Zhongwei and Wang, Xin and Liu, Che and Alam, Samiul and Zheng, Yu and others},
journal={arXiv preprint arXiv:2312.03863},
volume={1},
year={2023},
publisher={no}
}
❤️ 커뮤니티 지원
이 저장소는 유지 관리됩니다 Tuidan ([email protected]), sustechbruce ([email protected]), samiul272 ([email protected]) 및 미조 ([email protected]). 우리는이 설문 조사 및 저장소를 개선하여 전체 커뮤니티에 혜택을 줄 수있는 귀중한 자원을 제공 할 수있는 피드백, 제안 및 기부금을 환영합니다.
우리는 새로운 연구가 등장함에 따라이 저장소를 적극적으로 유지할 것입니다. 분류법에 관한 제안이 있거나 누락 된 서류를 찾거나 일부 장소에 수락 된 Preprint Arxiv 종이를 업데이트하고 다음 마크 다운 형식을 사용하여 이메일을 보내거나 풀 요청을 제출하십시오.
Paper Title, < ins >Conference/Journal/Preprint, Year</ ins > [[ pdf ] ( link )] [[ other resources ] ( link )] .
? 이 설문 조사는 무엇입니까?
LLMS (Largin Language Models)는 많은 중요한 작업에서 놀라운 기능을 보여 주었으며 우리 사회에 실질적인 영향을 줄 수있는 잠재력을 가지고 있습니다. 그러나 이러한 기능에는 상당한 자원 수요가있어 LLM이 제기 한 효율성 문제를 해결하기위한 효과적인 기술을 개발할 수있는 강력한 필요성을 강조합니다. 이 설문 조사에서 우리는 효율적인 LLMS 연구에 대한 체계적이고 포괄적 인 검토를 제공합니다. 우리는 모델 중심 , 데이터 중심 및 프레임 워크 중심의 관점에서 각각 뚜렷하지만 상호 연결된 효율적인 LLMS 주제를 다루는 세 가지 주요 범주로 구성된 분류법으로 문헌을 구성합니다. 우리는 우리의 설문 조사 와이 Github 저장소가 연구자와 실무자가 효율적인 LLM의 연구 개발에 대한 체계적인 이해를 얻고이 중요하고 흥미로운 분야에 기여하도록 영감을 줄 수있는 귀중한 자원으로 사용될 수 있기를 바랍니다.
? 효율적인 LLM이 필요한 이유는 무엇입니까?
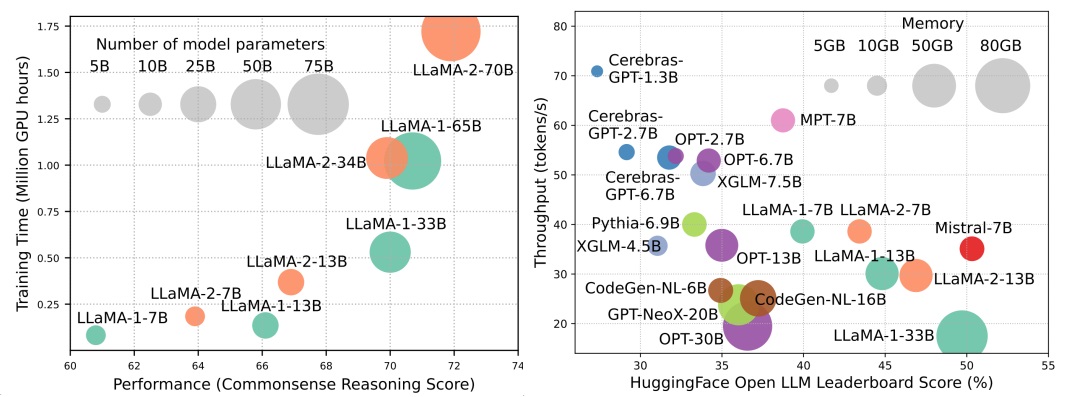
LLM이 다음 AI 혁명의 물결을 이끌고 있지만, LLM의 놀라운 기능은 실질적인 자원 요구의 비용으로옵니다. 그림 1 (왼쪽)은 LLAMA 시리즈의 GPU 시간 측면에서 모델 성능과 모델 교육 시간의 관계를 보여줍니다. 각 원의 크기는 모델 매개 변수 수에 비례합니다. 도시 된 바와 같이, 대형 모델은 더 나은 성능을 달성 할 수 있지만, 모델 크기가 확장됨에 따라 훈련에 사용되는 GPU 시간의 양은 기하 급수적으로 성장합니다. 훈련 외에도 추론은 LLM의 운영 비용에 상당히 크게 기여합니다. 그림 2 (오른쪽)는 모델 성능과 추론 처리량 간의 관계를 보여줍니다. 마찬가지로 모델 크기를 확장하면 성능이 향상되지만 추론 처리량 (높은 추론 대기 시간)의 비용으로 인해 비용이 많이 드는 방식으로 광범위한 고객 기반 및 다양한 애플리케이션을 확장하는 데 이러한 모델에 대한 과제를 제시합니다. LLM의 높은 자원 수요는 LLM의 효율성을 향상시키기위한 기술을 개발 해야하는 강력한 필요성을 강조합니다. 도 2에 도시 된 바와 같이, LLAMA-1-33B와 비교하여, 그룹화 된 쿼리주의 및 슬라이딩 윈도우주의를 사용하여 추론 속도를 높이기 위해 비슷한 성능과 훨씬 높은 처리량을 달성합니다. 이 우월성은 LLM의 효율성 설계 기술의 타당성과 중요성을 강조합니다.
내용 테이블
- ? 모델 중심 방법
- 모델 압축
- 양자화
- 훈련 후 양자화
- 체중 전용 양자화
- 체중 활성화 공동 정량
- 훈련 후 양자화의 평가
- 양자 인식 훈련
- 매개 변수 가지 치기
- 구조화 된 가지 치기
- 구조화되지 않은 가지 치기
- 낮은 순위 근사
- 지식 증류
- 매개 변수 공유
- 효율적인 사전 훈련
- 혼합 정밀 훈련
- 스케일링 모델
- 초기화 기술
- 교육 최적화기
- 효율적인 미세 조정
- 매개 변수 효율적인 미세 조정
- 어댑터 기반 튜닝
- 낮은 순위 적응
- 접두사 튜닝
- 프롬프트 튜닝
- 메모리 효율적인 미세 조정
- MOE 효율적인 감독 미세 조정
- 효율적인 추론
- 효율적인 아키텍처
- 효율적인 관심
- 기반주의를 공유합니다
- 기능 정보 감소
- 커널 화 또는 낮은 순위
- 고정 된 패턴 전략
- 학습 가능한 패턴 전략
- 전문가의 혼합
- MOE 기반 LLM
- 알고리즘 수준 MOE 최적화
- 긴 맥락 llms
- 외삽 및 보간
- 반복 구조
- 세분화 및 슬라이딩 윈도우
- 메모리-레트리어 확대
- 변압기 대체 아키텍처
- ? 데이터 중심 방법
- 데이터 선택
- 효율적인 사전 훈련을위한 데이터 선택
- 효율적인 미세 조정을위한 데이터 선택
- 프롬프트 엔지니어링
- ? iciency 시스템 수준 효율 최적화 및 LLM 프레임 워크
- 시스템 수준 효율 최적화
- 시스템 수준 사전 훈련 효율 최적화
- 시스템 수준 서빙 효율 최적화
- 알고리즘 하드웨어 공동 디자인
- LLM 프레임 워크
? 모델 중심 방법
모델 압축
양자화
훈련 후 양자화
체중 전용 양자화
- I-LLM : 완전히 정량화 된 저급 대형 언어 모델에 대한 효율적인 정수 전용 추론, Arxiv, 2024 [종이]
- intactkv : 피벗 토큰을 그대로 유지하여 대형 언어 모델 양자화 개선, Arxiv, 2024 [종이]
- 전능 한 : 전능 한 : 대형 언어 모델에 대한 전 방향 교정 양자화, ICLR, 2024 [종이] [코드]
- Onebit : 매우 낮은 비트 대형 언어 모델을 향해 Arxiv, 2024 [종이]
- GPTQ : 생성 미리 훈련 된 변압기를위한 정확한 양자화, ICLR, 2023 [종이] [코드]
- quip : 보장 된 대형 언어 모델의 2 비트 양자화, Arxiv, 2023 [종이] [코드]
- AWQ : LLM 압축 및 가속을위한 활성화 인식 중량 양자화, Arxiv, 2023 [종이] [코드]
- OWQ : 큰 언어 모델에서 체중 양자화를위한 활성화 특이점에서 배운 교훈, Arxiv, 2023 [종이] [코드]
- SPQR : 거의 손실이없는 LLM 중량 압축을위한 희박한 정량 표현, Arxiv, 2023 [종이] [코드]
- FineQuant : LLM의 세밀한 체중 전용 양자화로 효율성 잠금을 해제, Neurips-enlsp, 2023 [종이]
- llm.int8 () : 스케일의 변압기에 대한 8 비트 행렬 곱셈, Neurlps, 2022 [종이] [코드]
- 최적의 뇌 압축 : 정확한 훈련 후 양자화 및 가지 치기를위한 프레임 워크, Neurips, 2022 [종이] [코드]
- 양자 : 언어 모델에 대한 최적화 기반 양자화, Arxiv, 2023 [종이] [코드]
체중 활성화 공동 정량
- LLM의 고급 범위 관리 및 효율적인 양자화를위한 회전 및 순열, Neurips, 2024 [종이]
- 전능 한 : 전능 한 : 대형 언어 모델에 대한 전 방향 교정 양자화, ICLR, 2024 [종이] [코드]
- 규모로 양자화의 흥미로운 특성, Neurips, 2023 [종이]
- Zeroquant-V2 : 포괄적 인 연구에서 저급 보상에 이르기까지 LLM의 훈련 후 양자화 탐색, Arxiv, 2023 [종이] [코드]
- Zeroquant-FP : 부동 소수점 형식을 사용하여 LLMS 후 훈련 W4A8 양자화의 도약 Neurips-enlsp, 2023 [종이] [코드]
- 올리브 : 하드웨어 친화적 인 Order-Victim 쌍 양자화를 통한 대형 언어 모델 가속화, ISCA, 2023 [종이] [코드]
- RPTQ : 대형 언어 모델에 대한 재주문 기반 사후 훈련 양자화, Arxiv, 2023 [종이] [코드]
- Outlier Suppression+: 동등하고 최적의 변화 및 스케일링에 의한 대형 언어 모델의 정확한 양자화, Arxiv, 2023 [종이] [코드]
- QLLM : 대형 언어 모델에 대한 정확하고 효율적인 저비역 정량화, Arxiv, 2023 [종이]
- SmoothQuant : 대형 언어 모델에 대한 정확하고 효율적인 사후 훈련 양자화, ICML, 2023 [종이] [코드]
- Zeroquant : 대규모 변압기를위한 효율적이고 저렴한 훈련 후 양자화, Neurips, 2022 [종이]
훈련 후 양자화의 평가
- 양자화 된 대형 언어 모델 평가, Arxiv, 2024 [종이]
양자 인식 훈련
- 1 비트 LLM의 시대 : 모든 대형 언어 모델은 1.58 비트이며 Arxiv, 2024 [종이]
- FP8-LM : FP8 대형 언어 모델 교육, Arxiv, 2023 [종이]
- 8 비트 플로팅 포인트를 사용한 대형 언어 모델의 훈련 및 추론, Arxiv, 2023 [종이]
- 비트넷 : 대형 언어 모델의 1 비트 변압기 스케일링, Arxiv, 2023 [종이]
- LLM-QAT : 대형 언어 모델에 대한 데이터가없는 양자화 인식, Arxiv, 2023 [종이] [코드]
- 양자화를 통한 생성 미리 훈련 된 언어 모델의 압축, ACL, 2022 [종이]
매개 변수 가지 치기
구조화 된 가지 치기
- 가지 치기 및 지식 증류를 통한 소형 언어 모델, Arxiv, 2024 [종이]
- LLM의 깊이 가지 치기를 더 깊이 살펴보면 Arxiv, 2024 [종이]
- 당황 스러움에 의해 당황 : 작은 참조 모델과의 당황 기반 데이터 가지 치기, Arxiv, 2024 [종이]
- 플러그 앤 플레이 : 대형 언어 모델에 대한 효율적인 훈련 사후 치기 방법, ICLR, 2024 [종이]
- BESA : 블록 파라미터 효율적인 희소성 할당으로 대형 언어 모델을 가지 치기, Arxiv, 2024 [종이]
- 단점 : 대형 언어 모델의 레이어는 예상보다 중복됩니다. Arxiv, 2024 [종이]
- NutePrune : 대형 언어 모델에 대한 수많은 교사들과의 효율적인 진보적 가지 치기, Arxiv, 2024 [종이]
- SliceGpt : 행과 열을 삭제하여 대형 언어 모델을 압축하고, ICLR, 2024 [종이] [코드]
- Lorashear : 효율적인 대형 언어 모델 구조화 된 가지 치기 및 지식 회복, Arxiv, 2023 [종이]
- LLM-Pruner : 대형 언어 모델의 구조적 가지 치기에, Neurips, 2023 [종이] [코드]
- 전단 라마 : 구조화 된 가지 치기를 통한 언어 모델 가속화, 사전 훈련, Neurips-enlsp, 2023 [종이] [코드]
- Loraprune : 가지 치기는 저급 매개 변수 효율적인 미세 조정을 충족합니다. Arxiv, 2023 [종이]
구조화되지 않은 가지 치기
- Maskllm : 대형 언어 모델에 대한 학습 가능한 반 구조적 희소, NIPS, 2024 [종이]
- Dynamic Sparse No Training : Sparse LLM을위한 교육이없는 미세 조정, ICLR, 2024 [종이]
- sparsegpt : 대규모 언어 모델은 원샷에서 정확하게 가지 치기 할 수 있습니다. ICML, 2023 [종이] [코드]
- 대형 언어 모델에 대한 간단하고 효과적인 가지 치기 접근 방식, Arxiv, 2023 [종이] [코드]
- 대형 언어 모델에 대한 원샷 민감도 인식 혼합 희소 정리, Arxiv, 2023 [종이]
낮은 순위 근사
- SVD-LLM : 대형 언어 모델 압축을위한 단일 가치 분해, Arxiv, 2024 [종이] [코드]
- ASVD : 대형 언어 모델을 압축하기위한 활성화 인식 단일 가치 분해, Arxiv, 2023 [종이] [코드]
- 가중 저 순위 인수화로 언어 모델 압축, ICLR, 2022 [종이]
- Tensorg : Tensor-Train 분해에 기초한 LLM에서 임베딩 층의 효율적인 압축, Arxiv, 2023 [종이]
- LOSPARSE : 저 순위 및 희소 근사를 기반으로하는 대형 언어 모델의 구조화 된 압축, ICML, 2023 [종이] [코드]
지식 증류
화이트 박스 KD
- DDK : 효율적인 대형 언어 모델을위한 증류 도메인 지식 Arxiv, 2024 [종이]
- 대형 언어 모델에 대한 지식 증류에서 Kullback-Leibler Divergence를 다시 생각합니다. Arxiv, 2024 [종이]
- Distillm : 대형 언어 모델의 간소화 증류를 향해 Arxiv, 2024 [종이] [코드]
- 증류 언어 모델의 용량 격차 법칙을 향해 Arxiv, 2023 [종이] [코드]
- Baby Llama : 성과 페널티없이 작은 데이터 세트에 대해 훈련 된 교사의 앙상블에서 지식 증류, Arxiv, 2023 [종이]
- 큰 언어 모델의 지식 증류, Arxiv, 2023 [종이] [코드]
- GKD : 자동 반복 시퀀스 모델을위한 일반화 된 지식 증류, Arxiv, 2023 [종이]
- 증류를 통해 LM에 대한 지식 업데이트 전파, Arxiv, 2023 [종이] [코드]
- 더 적은 것은 더 많습니다 : 언어 모델 압축에 대한 작업 인식 계층 별 증류, ICML, 2023 [종이]
- 3 원 중량 생성 언어 모델에 대한 토큰 규모 로이트 증류, Arxiv, 2023 [종이]
블랙 박스 KD
- Zephyr : LM 정렬의 직접 증류, Arxiv, 2023 [종이]
- GPT-4로 지시 조정, Arxiv, 2023 [종이] [코드]
- 라이온 : 폐쇄 소스 대형 언어 모델의 적대 증류, Arxiv, 2023 [종이] [코드]
- 다단계 추론을 향한 작은 언어 모델 전문, ICML, 2023 [종이] [코드]
- 단계별 증류! 교육 데이터가 적고 더 작은 모델 크기로 대규모 언어 모델을 능가합니다. ACL, 2023 [종이]
- 큰 언어 모델은 추론 교사이며 ACL, 2023 [종이] [코드]
- Scott : 일관된 사슬의 증류 체인, ACL, 2023 [종이] [코드]
- 상징적 인 증류 체인 : 소규모 모델도 단계별로 "생각"할 수 있습니다. ACL, 2023 [종이]
- 소규모 언어 모델로 추론 기능을 증류하고 ACL, 2023 [종이] [코드]
- 텍스트 내 학습 증류 증류 : 미리 훈련 된 언어 모델의 소수의 학습 능력 전달, Arxiv, 2022 [종이]
- 큰 언어 모델의 설명은 작은 추론자를 더 좋게 만듭니다. Arxiv, 2022 [종이]
- Disco : 큰 언어 모델을 사용하여 반대를 증류합니다. Arxiv, 2022 [종이] [코드]
매개 변수 공유
- Mobillama : 정확하고 가벼운 완전히 투명한 GPT를 향해 Arxiv, 2024 [종이]
효율적인 사전 훈련
혼합 정밀 훈련
- 신경망의 BFLOAT16 처리, Arith, 2019 [종이]
- 딥 러닝 훈련을위한 bfloat16에 대한 연구, Arxiv, 2019 [종이]
- 혼합 정밀 훈련, ICLR, 2018 [종이]
스케일링 모델
- 레몬 : 무한 모델 확장, ICLR, 2024 [종이]
- 언어 모델에 대한 진보적 인 교육을위한 교훈 준비, AAAI, 2024 [종이]
- 효율적인 변압기 훈련을위한 사전 취향 모델을 성장시키는 법을 배우고 ICLR, 2023 [종이] [코드]
- 마스크 구조 성장을 통한 2 배 더 빠른 언어 모델 사전 훈련, Arxiv, 2023 [종이]
- 효율적인 교육을 위해 다층 연산자의 사전 취사 모델 재사용, Neurips, 2023 [종이]
- FLM-101B : 오픈 LLM 및 $ 100K 예산으로 훈련하는 방법, Arxiv, 2023 [종이] [코드]
- 미리 훈련 된 언어 모델에 대한 지식 상속, Naacl, 2022 [종이] [코드]
- 변압기 언어 모델을위한 무대 교육, ICML, 2022 [종이] [코드]
초기화 기술
- DeepNet : 변압기를 1,000 층으로 스케일링하고 Arxiv, 2022 [종이] [코드]
- 제로 초기화 : 제로와 네트워크만으로 신경망 초기화, TMLR, 2022 [종이] [코드]
- Rezero는 필요한 전부입니다. 빠른 깊이의 빠른 수렴, UAI, 2021 [종이] [코드]
- 일괄 정규화 바이어스 딥 네트워크에서 정체 함수를 향한 잔류 블록, Neurips, 2020 [종이]
- 더 나은 초기화를 통한 변압기 최적화 향상, ICML, 2020 [종이] [코드]
- Fixup 초기화 : 정상화가없는 잔여 학습, ICLR, 2019 [종이]
- 깊은 신경망의 체중 초기화에 대해 Arxiv, 2017 [종이]
교육 최적화기
- 언어 모델에 대한 최적의 학습을 위해 Arxiv, 2024 [종이] [코드]
- 최적화 알고리즘의 상징적 발견, Arxiv, 2023 [종이]
- 소피아 : 언어 모델 사전 훈련을위한 확장 가능한 확률 론적 2 차 옵티마이저 Arxiv, 2023 [종이] [코드]
효율적인 미세 조정
매개 변수 효율적인 미세 조정
어댑터 기반 튜닝
- Opendelta : 미리 훈련 된 모델의 매개 변수 효율적인 적응을위한 플러그 앤 플레이 라이브러리, ACL 데모, 2023 [종이] [코드]
- LLM 자리터 : 대형 언어 모델의 매개 변수 효율적인 미세 조정을위한 어댑터 제품군, Emnlp, 2023 [종이] [코드]
- Compacter : 효율적인 저 순위의 하이퍼 콤플렉스 어댑터 층, Neurips, 2023 [종이] [코드]
- 소수의 매개 변수 효율적인 미세 조정은 텍스트 내 학습보다 더 좋고 저렴합니다. Neurips, 2022 [종이] [코드]
- 메타 어택터 : 메타 학습을 통한 파라미터 효율적인 소수의 미세 조정, Automl, 2022 [종이]
- Adamix : 매개 변수 효율적인 모델 튜닝을위한 혼합 적응, Emnlp, 2022 [종이] [코드]
- SparseAdapter : 어댑터의 매개 변수 효율성 향상을위한 쉬운 접근 방식, Emnlp, 2022 [종이] [코드]
낮은 순위 적응
- Hydralora : 효율적인 미세 조정을위한 비대칭 LORA 아키텍처, Neurips, 2024 [종이]
- LOFIT : LLM 표현에 대한 현지 미세 조정, Arxiv, 2024 [종이]
- 저급 적응의 혼합 공간, Arxiv, 2024 [종이] [코드]
- MEFT : 스파 스 어댑터를 통한 메모리 효율적인 미세 조정, ACL, 2024 [종이]
- Lora는 통합 프레임 워크에서 드롭 아웃을 충족합니다. Arxiv, 2024 [종이]
- 별 : 대형 언어 모델의 데이터 효율적인 미세 조정을위한 동적 능동 학습을 가진 제약 LORA, Arxiv, 2024 [종이]
- LORA+: 대형 모델의 효율적인 저급 적응, Arxiv, 2024 [종이]
- LORA-FA : 큰 언어 모델 미세 조정에 대한 메모리 효율적인 저급 적응, Arxiv, 2023 [종이]
- Lorahub : Dynamic Lora Composition을 통한 효율적인 크로스 작업 일반화, Arxiv, 2023 [종이] [코드]
- longlora : 장기 텍스트 대형 언어 모델의 효율적인 미세 조정, Arxiv, 2023 [종이] [코드]
- 교차 작업 일반화를위한 멀티 헤드 어댑터 라우팅, Neurips, 2023 [종이] [코드]
- 매개 변수 효율적인 미세 조정에 대한 적응 예산 할당, ICLR, 2023 [종이]
- Dylora : 동적 검색이없는 저 순위 적응을 사용하여 사전에 사전 된 모델의 매개 변수 효율적인 튜닝, EACL, 2023 [종이] [코드]
- Tied-Lora : 체중 묶음으로 LORA의 매개 변수 효율 향상, Arxiv, 2023 [종이]
- LORA : 대형 언어 모델의 낮은 순위 적응, ICLR, 2022 [종이] [코드]
접두사 튜닝
- Llama-Adapter : 관심이없는 언어 모델의 효율적인 미세 조정, Arxiv, 2023 [종이] [코드]
- 접두사 조정 : 세대를위한 연속 프롬프트 최적화 ACL, 2021 [종이] [코드]
프롬프트 튜닝
- 압축, 프롬프트 : 전송 가능한 프롬프트와의 LLM 추론의 정확도 효율성 트레이드 오프 개선, Arxiv, 2023 [종이]
- GPT도 이해합니다. Ai Open, 2023 [종이] [코드]
- 소수의 학습을위한 모듈 식 프롬프트의 멀티 태스킹 사전 훈련 ACL, 2023 [종이] [코드]
- 멀티 태스킹 프롬프트 튜닝은 매개 변수 효율적인 전송 학습을 가능하게합니다. ICLR, 2023 [종이]
- PPT : 소수의 학습을위한 미리 훈련 된 프롬프트 튜닝, ACL, 2022 [종이] [코드]
- 매개 변수 효율적인 프롬프트 튜닝은 일반화되고 보정 된 신경 텍스트 리트리버를 만듭니다. Emnlp-findings, 2022 [종이] [코드]
- P- 튜닝 v2 : 프롬프트 튜닝은 스케일 및 작업에서 보편적으로 미세 조정하는 것과 비교할 수 있습니다. ACL-SHORT, 2022 [종이] [코드]
- 매개 변수 효율적인 프롬프트 튜닝을위한 스케일의 전력, Emnlp, 2021 [종이]
메모리 효율적인 미세 조정
- 대형 언어 모델을 미세 조정하기위한 최적화에 대한 연구, Arxiv, 2024/ins> [종이]
- 큰 언어 모델 미세 조정의 희소 매트릭스, Arxiv, 2024/ins> [종이]
- GALORE : 그라디언트 저 순위 프로젝션에 의한 메모리 효율적인 LLM 교육, Arxiv, 2024/ins> [종이]
- REFT : 언어 모델에 대한 표현 미세 조정, Arxiv, 2024/ins> [종이]
- LISA : 메모리 효율적인 대형 언어 모델 미세 조정을위한 계층별 중요도 샘플링, Arxiv, 2024/ins> [종이]
- Bitdelta : 미세 조정은 한 번만 가치가있을 수 있습니다. Arxiv, 2024/ins> [종이]
- 언어 모델의 메모리 효율적인 적응을위한 우승자-모든 열 행 샘플링, Neurips, 2023 [종이] [코드]
- 메모리 효율적인 선택적 미세 조정, ICML 워크숍, 2023 [종이]
- 자원이 제한된 대형 언어 모델에 대한 전체 매개 변수 미세 조정, Arxiv, 2023 [종이] [코드]
- 전진 패스가있는 미세 조정 언어 모델, Neurips, 2023 [종이] [코드]
- 4 비트 이하의 정수 양자화를 통해 압축 된 대형 언어 모델의 메모리 효율적인 미세 조정, Neurips, 2023 [종이]
- LOFTQ : 대형 언어 모델에 대한 LORA-FINE-TUNING-AWARE Quantization, Arxiv, 2023 [종이] [코드]
- QA-Lora : 대형 언어 모델의 양자 인식 저 순위 적응, Arxiv, 2023 [종이] [코드]
- Qlora : 양자화 된 LLM의 효율적인 양조 Neurips, 2023 [논문] [Code1] [Code2]
MOE- 효율적인 감독 촉진
- 전문가가 그의 마지막을 고수하게하십시오 : 희소 건축 대형 언어 모델을위한 전문가 특정 미세 조정, Arxiv, 2024 [종이]
효율적인 추론
평행 디코딩
- CLLMS : 일관성 큰 언어 모델, Arxiv, 2024 [종이]
- 한 번 인코딩하고 병렬로 디코딩 : 효율적인 변압기 디코딩, Arxiv, 2024 [종이]
투기 디코딩
- MAGICDEC : 투기 디코딩으로 긴 상황에 맞는 대기 시간 대기 시간 트레이드 오프 나누기, Arxiv, 2024 [종이]
- DEFT : 효율적인 트리 구조화 된 LLM 추론을위한 플래시 트리-디테일로 디코딩, Arxiv, 2024 [종이]
- Layerskip : 조기 출구 추론 및 자체 형성 디코딩 가능 Arxiv, 2024 [종이]
- TRIFORCE : 계층 적 투기 디코딩으로 긴 시퀀스 생성의 무손실 가속도, Arxiv, 2024 [종이]
- REST : 검색 기반 투기 디코딩, Arxiv, 2024 [종이]
- 추론 효율적인 LLM을위한 탠덤 변압기, Arxiv, 2024 [종이]
- 패스 : 병렬 투기 샘플링, Neurips Workshop, 2023 [종이]
- 병렬 디코딩을 통한 변환에 대한 변압기 추론 가속, ACL, 2023 [종이] [코드]
- Medusa : 다중 디코딩 헤드로 LLM 생성을 가속화하기위한 간단한 프레임 워크, 블로그, 2023 [블로그] [코드]
- 투기 디코딩을 통해 변압기로부터 빠른 추론, ICML, 2023 [종이]
- 단계별 투기 디코딩으로 LLM 추론 가속화, ICML 워크숍, 2023 [종이]
- 투기 샘플링으로 대형 언어 모델 디코딩 가속화, Arxiv, 2023 [종이]
- 큰 작은 디코더로 투기 디코딩, Neurips, 2023 [종이] [코드]
- Specinfer : 투기 적 추론 및 토큰 트리 검증으로 제공되는 생성 LLM 가속화, Arxiv, 2023 [종이] [코드]
- 참조와의 추론 : 큰 언어 모델의 무손실 가속도, Arxiv, 2023 [종이] [코드]
- 씨앗 : 예정된 투기 디코딩을 통한 추론 트리 구성 가속화, Arxiv, 2024 [종이]
KV 캐시 최적화
- VL-Cache : 비전 언어 모델 추론 가속을위한 희소성 및 양식 인식 KV 캐시 압축, Arxiv, 2024 [종이]
- MINDERENCE 1.0 : 역동적 인 스파 스주의를 통해 장거리 텍스트 LLM에 대한 사전 충전 가속화, Arxiv, 2024 [종이]
- KVSHARER : 계층 별 비 유사한 KV 캐시 공유를 통한 효율적인 추론, Arxiv, 2024 [종이]
- 공동 복제 : 검색 및 스트리밍 헤드와의 효율적인 장거리 LLM 추론, Arxiv, 2024 [종이]
- Lazyllm : 효율적인 긴 맥락 LLM 추론을위한 동적 토큰 가지 치기, Arxiv, 2024 [종이]
- Palu : 저 순위 프로젝션으로 KV 캐시 압축, Arxiv, 2024 [종이] [코드]
- Look-M : 효율적인 멀티 모달 장거리 텍스트 추론을위한 KV 캐시의 Look-once 최적화, Arxiv, 2024 [종이]
- D2O : 대형 언어 모델의 효율적인 생성 추론을위한 동적 판별 작업, Arxiv, 2024 [종이]
- 퀘스트 : 효율적인 장기 텍스트 LLM 추론을위한 쿼리 인식 희소성, ICML, 2024 [종이]
- 크로스 층주의를 기준으로 변압기 키-값 캐시 크기 감소, Arxiv, 2024 [종이]
- Snapkv : LLM은 세대 전에 무엇을 찾고 있는지 알고 있습니다. Arxiv, 2024 [종이]
- 앵커 기반 대형 언어 모델, Arxiv, 2024 [종이]
- Kvquant : 1 천만 개의 컨텍스트 길이 LLM 추론 KV 캐시 양자화, Arxiv, 2024 [종이]
- GEAR : LLM의 거의 거친 생성 추론을위한 효율적인 KV 캐시 압축 레시피, Arxiv, 2024 [종이]
- 동적 메모리 압축 : 가속화 된 추론을위한 LLM을 개조, Arxiv, 2024 [종이]
- 남은 토큰 없음 : 중요성 인식 혼합 정밀 양자화를 통한 신뢰할 수있는 KV 캐시 압축, Arxiv, 2024 [종이]
- 더 적게 얻으십시오 : 효율적인 LLM 추론을 위해 KV 캐시 압축으로 재발 합성, Arxiv, 2024 [종이]
- wkvquant : 대형 언어 모델에 대한 양자 무게 및 키/가치 캐시를 더 많이 얻을 수 있습니다. Arxiv, 2024 [종이]
- 주요 값 제한적 생성 언어 모델 추론에 대한 퇴거 정책의 효능에 대해, Arxiv, 2024 [종이]
- Kivi : KV 캐시에 대한 튜닝이없는 비대칭 2 비트 양자화, Arxiv, 2024 [종이] [코드]
- 모델은 버릴 내용을 알려줍니다 : LLM의 적응 형 KV 캐시 압축, ICLR, 2024 [종이]
- Skipdecode : 효율적인 LLM 추론을위한 배치 및 캐싱으로 자동 회귀 스킵 디코딩, Arxiv, 2023 [종이]
- H2O : 대형 언어 모델의 효율적인 생성 추론을위한 Heavy-Hitter Oracle, Neurips, 2023 [종이]
- Scissorhands : 테스트 시간에 LLM KV 캐시 압축에 대한 중요성의 지속성을 악용, Neurips, 2023 [종이]
- 효율적이고 해석 가능한 자동 회귀 변압기를위한 동적 컨텍스트 가지 치기, Arxiv, 2023 [종이]
효율적인 아키텍처
효율적인 관심
기반주의를 공유합니다
- 로마 : 무손실 압축 메모리주의, Arxiv, 2024 [종이]
- MOBILELLM : 기기 사용 사례를위한 수십억 이하 매개 변수 언어 모델 최적화, Arxiv, 2024 [종이]
- GQA : 멀티 헤드 체크 포인트에서 일반화 된 다중 쿼리 변압기 모델 교육 Emnlp, 2023 [종이]
- 빠른 변압기 디코딩 : 하나의 쓰기 머리가 필요한 전부입니다. Arxiv, 2019 [종이]
기능 정보 감소
- Nyströmformer : 자체 변환을 근사화하기위한 Nyström 기반 알고리즘, AAAI, 2021 [종이] [코드]
- 유입 경로 변환기 : 효율적인 언어 처리를위한 순차적 중복성 필터링, Neurips, 2020 [종이] [코드]
- 세트 변압기 :주의 기반 순열 불변 신경 네트워크를위한 프레임 워크, ICML, 2019 [종이]
커널 화 또는 낮은 순위
- Loki : 효율적인 희소주의를위한 저급 키, ICML 워크숍, 2023 [종이]
- Sumformer : 효율적인 변압기의 범용 근사치, ICML 워크숍, 2023 [종이]
- Flurka : 빠른 퓨즈 저 순위 및 커널 관심, Arxiv, 2023 [종이]
- Scatterbrain : 희소하고 낮은 순위의 주목을 통합, Neurlps, 2021 [종이] [코드]
- 공연자들과의 관심을 다시 생각하고 ICLR, 2021 [종이] [코드]
- 임의의 기능주의, ICLR, 2021 [종이]
- Linformer : 선형 복잡성에 대한 자체 변환, Arxiv, 2020 [종이] [코드]
- 저 순위 변압기를 사용한 가볍고 효율적인 엔드 투 엔드 음성 인식, ICASSP, 2020 [종이]
- 트랜스포머는 RNN입니다 : 선형주의를 기울인 빠른 자동 회귀 변압기, ICML, 2020 [종이] [코드]
고정 된 패턴 전략
- 간단한 선형주의 언어 모델 Arxiv, 2024 [종이]
- Lightning Interection-2 : 대형 언어 모델에서 무제한 시퀀스 길이를 처리하기위한 무료 점심, Arxiv, 2024 [종이] [코드]
- 희소 플래시주의를 통해 큰 시퀀스에 대한 더 빠른 인과 관계, ICML 워크숍, 2023 [종이]
- Poolingformer : 풀링주의가있는 긴 문서 모델링, ICML, 2021 [종이]
- Big Bird : 더 긴 시퀀스를위한 변압기, Neurips, 2020 [종이] [코드]
- Longformer : Long-Document Transformer, Arxiv, 2020 [종이] [코드]
- 오랜 문서 이해를위한 블록 동의 자체 변환, Emnlp, 2020 [종이] [코드]
- 드문 트랜스포머로 긴 시퀀스를 생성하고 Arxiv, 2019 [종이]
학습 가능한 패턴 전략
- MOA : 자동 대형 언어 모델 압축을위한 희소주의의 혼합, Arxiv, 2024 [종이]
- 과학자 : 근거리 시간에 긴 컨텍스트 관심, Arxiv, 2023 [종이] [코드]
- Clusterformer : 효율적이고 효과적인 변압기를위한 신경 군집주의, ACL, 2022 [종이]
- 개혁자 : 효율적인 변압기, ICLR, 2022 [종이] [코드]
- 드문 싱크 뿔의 관심, ICML, 2020 [종이]
- 클러스터 된 주의력이있는 빠른 변압기, Neurips, 2020 [종이] [코드]
- 라우팅 변압기를 사용한 효율적인 컨텐츠 기반 스파 스주의, TACL, 2020 [종이] [코드]
전문가의 혼합
MOE 기반 LLM
- Self-Moe : 자체 전문가 전문가와 함께 구성적인 대형 언어 모델을 향해, Arxiv, 2024 [종이]
- Lory : 자동 회귀 언어 모델 사전 훈련을위한 완전히 차별화 가능한 혼합, 2024 [종이]
- Jetmoe : 2024 년 0.1M 달러로 LLAMA2 성능에 도달 [종이]
- 전문가는 하나의 토큰 가치가 있습니다 : 전문가 토큰 라우팅을 통해 일반인으로서 여러 전문가 LLM을 상승시켜 2024 [종이]
- 혼합 내심 : 변압기 기반 언어 모델에 동적으로 컴퓨팅을 할당, 2024 [종이]
- Branch-Train-Mix : Expert LLM을 혼합 Experts LLM에 혼합하여 2024 [종이]
- 전문가의 Mixtral, Arxiv, 2024 [종이] [코드]
- Mistral 7B, Arxiv, 2023 [종이] [코드]
- Pangu-σ : 희소 이기종 컴퓨팅을 가진 3 조 매개 변수 언어 모델을 향해, Arxiv, 2023 [종이]
- 스위치 변압기 : 간단하고 효율적인 희소성으로 진동 매개 변수 모델로 스케일링, JMLR, 2022 [종이] [코드]
- 전문가의 혼합물을 사용한 효율적인 대규모 언어 모델링, Emnlp, 2022 [종이] [코드]
- 기본 레이어 : 크고 희소 한 모델의 훈련 단순화, ICML, 2021 [종이] [코드]
- GSHARD : 조건부 계산 및 자동 샤딩으로 거대한 모델 스케일링, ICLR, 2021 [종이]
알고리즘 수준 MOE 최적화
- SEER-MOE : 혼합 경험을위한 정규화를 통한 드문 전문가 효율성, Arxiv, 2024/ins> [종이]
- 전문가의 세분화 된 혼합에 대한 법률 스케일링, Arxiv, 2024/ins> [종이]
- 배포 전문가와 함께 평생 언어 사전 여부, ICML, 2023 [종이]
- 믹스 엑스퍼트는 교육 튜닝을 충족합니다 : 대형 언어 모델의 승리 조합, Arxiv, 2023 [종이]
- 전문가 선택 라우팅과 함께 믹스 러프, Neurips, 2022 [종이]
- Stablemoe : 전문가의 혼합을위한 안정적인 라우팅 전략, ACL, 2022 [종이] [코드]
- 전문가의 희소 혼합 혼합물의 표현 붕괴에 Neurips, 2022 [종이]
긴 맥락 llms
외삽 및 보간
- 두 개의 돌이 한 마리의 새를 쳤다 : 더 나은 길이의 외삽을위한 이끼 위치 인코딩, ICML, 2024 [종이]
- ∞ 벤치 : 100k 토큰을 넘어 긴 컨텍스트 평가 확장, Arxiv, 2024 [종이]
- 공명 로프 : 대형 언어 모델의 상황 길이 일반화 개선, Arxiv, 2024 [종이] [코드]
- Longrope : LLM 컨텍스트 창을 2 백만 개의 토큰 이상으로 확장 Arxiv, 2024 [종이]
- e^2-llm : 대형 언어 모델의 효율적이고 극단적 인 길이 확장, Arxiv, 2024 [종이]
- 로프 기반 외삽 법률 스케일링 법률, Arxiv, 2023 [종이]
- 길이가 우수한 변압기, ACL, 2023 [종이] [코드]
- 위치 보간을 통해 대형 언어 모델의 컨텍스트 확장 창, Arxiv, 2023 [종이]
- NTK 보간, 블로그, 2023 [Reddit Post]
- 원사 : 대형 언어 모델의 효율적인 컨텍스트 창 확장, Arxiv, 2023 [종이] [코드]
- Clex : 대형 언어 모델의 연속 길이 외삽, Arxiv, 2023 [종이] [코드]
- 포즈 : 위치 건너 뛰기 훈련을 통한 LLM의 효율적인 컨텍스트 윈도우 확장, Arxiv, 2023 [종이] [코드]
- 상대적 위치에 대한 기능 보간은 긴 컨텍스트 변압기를 향상시키고, Arxiv, 2023 [종이]
- 짧게 열차, 테스트 오랫동안 : 선형 바이어스를 사용한 주의력은 입력 길이 외삽을 가능하게합니다. ICLR, 2022 [종이] [코드]
- 큰 언어 모델에서 길이 일반화 탐색, Neurips, 2022 [종이]
반복 구조
- Ententive Network : 대형 언어 모델의 변압기의 후임자, Arxiv, 2023 [종이] [코드]
- 반복 메모리 변압기, Neurips, 2022 [종이] [코드]
- 블록 재생 변압기, Neurips, 2022 [종이] [코드]
- ∞-전수 : 무한 메모리 변압기, ACL, 2022 [종이] [코드]
- Memformer : 시퀀스 모델링을위한 메모리-구분 변압기, AACL-Findings, 2020 [종이] [코드]
- Transformer-XL : 고정 길이의 컨텍스트를 넘어 세심한 언어 모델, ACL, 2019 [종이] [코드]
세분화 및 슬라이딩 윈도우
- XL3M : 세그먼트 별 추론을 기반으로 한 LLM 길이 확장에 대한 교육 프리 프레임 워크, Arxiv, 2024 [종이]
- TransformerFam : 피드백주의는 작업 메모리이며 Arxiv, 2024 [종이]
- 대형 언어 모델에 대한 순진한 베이에 기반 컨텍스트 확장, Naacl, 2024 [종이]
- 컨텍스트를 남기지 마십시오 : Infini-intention을 가진 효율적인 무한 컨텍스트 변압기, Arxiv, 2024 [종이]
- 신경 압축 텍스트에 대한 LLM을 훈련 Arxiv, 2024 [종이]
- LM-Infinite : 대형 언어 모델의 제로 샷 극한 길이 일반화, Arxiv, 2024 [종이]
- 대형 언어 모델의 교육이없는 장기 텍스트 스케일링, Arxiv, 2024 [종이] [코드]
- 병렬 컨텍스트 인코딩을 사용한 긴 컨텍스트 언어 모델링, Arxiv, 2024 [종이] [코드]
- 4K에서 400K로 급증 : 활성화 비콘으로 LLM의 컨텍스트 확장, Arxiv, 2024 [종이] [코드]
- LLM 아마도 Longlm : 튜닝없이 Selfextend LLM 컨텍스트 창, Arxiv, 2024 [종이] [코드]
- 시맨틱 압축을 통해 대형 언어 모델의 컨텍스트 확장 창, Arxiv, 2023 [종이]
- 주의 싱크대가있는 효율적인 스트리밍 언어 모델, Arxiv, 2023 [종이] [코드]
- 큰 언어 모델의 병렬 컨텍스트 창, ACL, 2023 [종이] [코드]
- Longnet : 변압기 스케일링 1,000,000,000 토큰으로, Arxiv, 2023 [종이] [코드]
- 짧은 텍스트 모델을 사용한 효율적인 긴 텍스트 이해, TACL, 2023 [종이] [코드]
메모리-레트리어 확대
- Infllm : 훈련이없는 메모리로 매우 긴 시퀀스를 이해하기위한 LLM의 고유 용량을 공개합니다. Arxiv, 2024 [종이]
- Landmark Attention: Random-Access Infinite Context Length for Transformers, arXiv, 2023 [Paper] [Code]
- Augmenting Language Models with Long-Term Memory, NeurIPS, 2023 [종이]
- Unlimiformer: Long-Range Transformers with Unlimited Length Input, NeurIPS, 2023 [Paper] [Code]
- Focused Transformer: Contrastive Training for Context Scaling, NeurIPS, 2023 [Paper] [Code]
- Retrieval meets Long Context Large Language Models, arXiv, 2023 [종이]
- Memorizing Transformers, ICLR, 2022 [Paper] [Code]
Transformer Alternative Architecture
State Space Models
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, arXiv, 2024 [종이]
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts, arXiv, 2024 [종이]
- DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models, arXiv, 2024 [Paper] [Code]
- MambaByte: Token-free Selective State Space Model, arXiv, 2024 [종이]
- Sparse Modular Activation for Efficient Sequence Modeling, NeurIPS, 2023 [Paper] [Code]
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv, 2023 [Paper] [Code]
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models, ICLR 2023 [Paper] [Code]
- Long Range Language Modeling via Gated State Spaces, ICLR, 2023 [종이]
- Block-State Transformers, NeurIPS, 2023 [종이]
- Efficiently Modeling Long Sequences with Structured State Spaces, ICLR, 2022 [Paper] [Code]
- Diagonal State Spaces are as Effective as Structured State Spaces, NeurIPS, 2022 [Paper] [Code]
Other Sequential Models
- Differential Transformer, arXiv, 2024 [종이]
- Scalable MatMul-free Language Modeling, arXiv, 2024 [종이]
- You Only Cache Once: Decoder-Decoder Architectures for Language Models, arXiv, 2024 [종이]
- MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length, arXiv, 2024 [종이]
- DiJiang: Efficient Large Language Models through Compact Kernelization, arXiv, 2024 [종이]
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models, arXiv, 2024 [종이]
- PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation, arXiv, 2023 [종이]
- RWKV: Reinventing RNNs for the Transformer Era, EMNLP-Findings, 2023 [종이]
- Hyena Hierarchy: Towards Larger Convolutional Language Models, arXiv, 2023 [종이]
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, arXiv, 2023 [종이]
? Data-Centric Methods
Data Selection
Data Selection for Efficient Pre-Training
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models, arXiv, 2024 [종이]
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, NeurIPS, 2023 [종이]
- Data Selection for Language Models via Importance Resampling, NeurIPS, 2023 [Paper] [Code]
- NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, ICML, 2022 [Paper] [Code]
- Span Selection Pre-training for Question Answering, ACL, 2020 [Paper] [Code]
Data Selection for Efficient Fine-Tuning
- Show, Don't Tell: Aligning Language Models with Demonstrated Feedback, arXiv, 2024 [종이]
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models, arXiv, 2024 [종이]
- AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts, arXiv, 2024 [Paper] [Code]
- What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR, 2024 [Paper] [Code]
- How to Train Data-Efficient LLMs, arXiv, 2024 [종이]
- LESS: Selecting Influential Data for Targeted Instruction Tuning, arXiv, 2024 [Paper] [Code]
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning, arXiv, 2024 [Paper] [Code]
- One Shot Learning as Instruction Data Prospector for Large Language Models, arXiv, 2023 [종이]
- MoDS: Model-oriented Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, arXiv, 2023 [Paper] [Code]
- Instruction Mining: When Data Mining Meets Large Language Model Finetuning, arXiv, 2023 [종이]
- Data-Efficient Finetuning Using Cross-Task Nearest Neighbors, ACL, 2023 [Paper] [Code]
- Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values, ACL SRW, 2023 [Paper] [Code]
- Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning, arXiv, 2023 [종이]
- AlpaGasus: Training A Better Alpaca with Fewer Data, arXiv, 2023 [Paper] [Code]
- LIMA: Less Is More for Alignment, arXiv, 2023 [종이]
Prompt Engineering
Few-Shot Prompting
Demonstration Organization
Demonstration Selection
- Unified Demonstration Retriever for In-Context Learning, ACL, 2023 [Paper] [Code]
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning, NeurIPS, 2023 [Paper] [Code]
- In-Context Learning with Iterative Demonstration Selection, arXiv, 2022 [종이]
- Dr.ICL: Demonstration-Retrieved In-context Learning, arXiv, 2022 [종이]
- Learning to Retrieve In-Context Examples for Large Language Models, arXiv, 2022 [종이]
- Finding Supporting Examples for In-Context Learning, arXiv, 2022 [종이]
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering, ACL, 2023 [Paper] [Code]
- Selective Annotation Makes Language Models Better Few-Shot Learners, ICLR, 2023 [Paper] [Code]
- What Makes Good In-Context Examples for GPT-3? DeeLIO, 2022 [종이]
- Learning To Retrieve Prompts for In-Context Learning, NAACL-HLT, 2022 [Paper] [Code]
- Active Example Selection for In-Context Learning, EMNLP, 2022 [Paper] [Code]
- Rethinking the Role of Demonstrations: What makes In-context Learning Work? EMNLP, 2022 [Paper] [Code]
Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL, 2022 [종이]
Template Formatting
Instruction Generation
- Large Language Models as Optimizers, arXiv, 2023 [종이]
- Instruction Induction: From Few Examples to Natural Language Task Descriptions, ACL, 2023 [Paper] [Code]
- Large Language Models Are Human-Level Prompt Engineers, ICLR, 2023 [Paper] [Code]
- TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design, arXiv, 2023 [종이]
- Self-Instruct: Aligning Language Model with Self Generated Instructions, ACL, 2023 [Paper] [Code]
Multi-Step Reasoning
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, arXiv, 2024 [종이]
- Learning to Reason with LLMs, Website, 2024 [Html]
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, arXiv, 2024 [종이]
- From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, ICLR, 2024 [종이]
- Automatic Chain of Thought Prompting in Large Language Models, ICLR, 2023 [Paper] [Code]
- Measuring and Narrowing the Compositionality Gap in Language Models, EMNLP, 2023 [Paper] [Code]
- ReAct: Synergizing Reasoning and Acting in Language Models, ICLR, 2023 [Paper] [Code]
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, ICLR, 2023 [종이]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, NeurIPS, 2023 [Paper] [Code]
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, ICLR, 2023 [종이]
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, arXiv, 2023 [Paper] [Code]
- Contrastive Chain-of-Thought Prompting, arXiv, 2023 [Paper] [Code]
- Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation, arXiv, 2023 [종이]
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS, 2022 [종이]
Parallel Generation
- Better & Faster Large Language Models via Multi-token Prediction, arXiv, 2023 [종이]
- Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, arXiv, 2023 [Paper] [Code]
Prompt Compression
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, arXiv, 2024 [종이]
- PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models, arXiv, 2024 [종이]
- Compressed Context Memory For Online Language Model Interaction, ICLR, 2024 [종이]
- Learning to Compress Prompts with Gist Tokens, arXiv, 2023 [종이]
- Adapting Language Models to Compress Contexts, EMNLP, 2023 [Paper] [Code]
- In-context Autoencoder for Context Compression in a Large Language Model, arXiv, 2023 [Paper] [Code]
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, arXiv, 2023 [Paper] [Code]
- Discrete Prompt Compression with Reinforcement Learning, arXiv, 2023 [종이]
- Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models, arXiv, 2023 [종이]
Prompt Generation
- TempLM: Distilling Language Models into Template-Based Generators, arXiv, 2022 [Paper] [Code]
- PromptGen: Automatically Generate Prompts using Generative Models, NAACL Findings, 2022 [종이]
- AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP, 2020 [Paper] [Code]
? System-Level Efficiency Optimization and LLM Frameworks
System-Level Efficiency Optimization
System-Level Pre-Training Efficiency Optimization
- MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs, arXiv, 2024 [종이]
- CoLLiE: Collaborative Training of Large Language Models in an Efficient Way, EMNLP, 2023 [Paper] [Code]
- An Efficient 2D Method for Training Super-Large Deep Learning Models, IPDPS, 2023 [Paper] [Code]
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel, VLDB, 2023 [종이]
- Bamboo: Making Preemptible Instances Resilient for Affordable Training, NSDI, 2023 [Paper] [Code]
- Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates, SOSP, 2023 [Paper] [Code]
- Varuna: Scalable, Low-cost Training of Massive Deep Learning Models, EuroSys, 2022 [Paper] [Code]
- Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization, OSDI, 2022 [Paper] [Code]
- Tesseract: Parallelize the Tensor Parallelism Efficiently, ICPP, 2022 , [종이]
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning, OSDI, 2022 , [Paper][Code]
- Maximizing Parallelism in Distributed Training for Huge Neural Networks, arXiv, 2021 [종이]
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv, 2020 [종이]
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC, 2021 [Paper] [Code]
- ZeRO-Infinity: breaking the GPU memory wall for extreme scale deep learning, SC, 2021 [종이]
- ZeRO-Offload: Democratizing Billion-Scale Model Training, USENIX ATC, 2021 [Paper] [Code]
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, SC, 2020 [Paper] [Code]
System-Level Serving Efficiency Optimization
Serving System Design
- LUT TENSOR CORE: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration, arXiv, 2024 [종이]
- TurboTransformers: an efficient GPU serving system for transformer models, PPoPP, 2021 [종이]
- Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI, 2022 [종이]
- FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU, ICML, 2023 [Paper] [Code]
- Efficiently Scaling Transformer Inference, MLSys, 2023 [종이]
- DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale, SC, 2022 [종이]
- Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP, 2023 [Paper] [Code]
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters, arXiv, 2023 [Paper] [Code]
- Petals: Collaborative Inference and Fine-tuning of Large Models, arXiv, 2023 [종이]
- SpotServe: Serving Generative Large Language Models on Preemptible Instances, arXiv, 2023 [종이]
Serving Performance Optimization
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation, arXiv, ICML [종이]
- CacheGen: KV Cache Compression and Streaming for Fast Language Model Serving, arXiv, 2024 [종이]
- Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding, TMLR, 2024 [종이]
- Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity, arXiv, 2023 [종이]
- S3: Increasing GPU Utilization during Generative Inference for Higher Throughput, arXiv, 2023 [종이]
- Fast Distributed Inference Serving for Large Language Models, arXiv, 2023 [종이]
- Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline, arXiv, 2023 [종이]
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, arXiv, 2023 [종이]
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, arXiv, 2023 [종이]
- Prompt Cache: Modular Attention Reuse for Low-Latency Inference, arXiv, 2023 [종이]
- Fairness in Serving Large Language Models, arXiv, 2023 [종이]
Algorithm-Hardware Co-Design
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, arXiv, 2024 [종이]
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS, 2022 [Paper] [Code]
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, arXiv, 2023 [Paper] [Code]
- Flash-Decoding for Long-Context Inference, Blog, 2023 [Blog]
- FlashDecoding++: Faster Large Language Model Inference on GPUs, arXiv, 2023 [종이]
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU, arXiv, 2023 [Paper] [Code]
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, arXiv, 2023 [종이]
- Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models, arXiv, 2023 [종이]
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models, arXiv, 2022 [종이]
LLM Frameworks
| Efficient Training | Efficient Inference | Efficient Fine-Tuning |
|---|
| DeepSpeed [Code] | ✅ | ✅ | ✅ |
| Megatron [Code] | ✅ | ✅ | ✅ |
| ColossalAI [Code] | ✅ | ✅ | ✅ |
| Nanotron [Code] | ✅ | ✅ | ✅ |
| MegaBlocks [Code] | ✅ | ✅ | ✅ |
| FairScale [Code] | ✅ | ✅ | ✅ |
| Pax [Code] | ✅ | ✅ | ✅ |
| Composer [Code] | ✅ | ✅ | ✅ |
| OpenLLM [Code] | | ✅ | ✅ |
| LLM-Foundry [Code] | | ✅ | ✅ |
| vLLM [Code] | | ✅ | |
| TensorRT-LLM [Code] | | ✅ | |
| TGI [Code] | | ✅ | |
| RayLLM [Code] | | ✅ | |
| MLC LLM [Code] | | ✅ | |
| Sax [Code] | | ✅ | |
| Mosec [Code] | | ✅ | |


