Baichuan 7B
1.0.0
? Hugging Face • ? ModelScope • WeChat
中文| English
Baichuan-7B 是由百川智能開發的一個開源可商用的大規模預訓練語言模型。基於Transformer 結構,在大約1.2 萬億tokens 上訓練的70 億參數模型,支持中英雙語,上下文窗口長度為4096。在標準的中文和英文benchmark(C-Eval/MMLU)上均取得同尺寸最好的效果。
C-Eval 數據集是一個全面的中文基礎模型評測數據集,涵蓋了52 個學科和四個難度的級別。我們使用該數據集的dev 集作為few-shot 的來源,在test 集上進行了5-shot測試。通過執行執行下面的命令:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| Model 5-shot | Average | Avg(Hard) | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| ChatGPT | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-v1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-instant-v1.0 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| BLOOMZ-7B | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| ChatGLM-6B | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| Ziya-LLaMA-13B-pretrain | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| moss-moon-003-base (16B) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| LLaMA-7B-hf | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7B | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| TigerBot-7B-base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7B * | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-LLaMA-v2-pretrain (7B) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| BLOOM-7B | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7B | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
Gaokao 是一個以中國高考題作為評測大語言模型能力的數據集,用以評估模型的語言能力和邏輯推理能力。 我們只保留了其中的單項選擇題,隨機劃分後對所有模型進行統一5-shot測試。
以下是測試的結果。
| Model | Average |
|---|---|
| BLOOMZ-7B | 28.72 |
| LLaMA-7B | 27.81 |
| BLOOM-7B | 26.96 |
| TigerBot-7B-base | 25.94 |
| Falcon-7B | 23.98 |
| Ziya-LLaMA-13B-pretrain | 23.17 |
| ChatGLM-6B | 21.41 |
| Open-LLaMA-v2-pretrain | 21.41 |
| Aquila-7B * | 24.39 |
| Baichuan-7B | 36.24 |
AGIEval 旨在評估模型的認知和解決問題相關的任務中的一般能力。 我們只保留了其中的四選一單項選擇題,隨機劃分後對所有模型進行了統一5-shot測試。
| Model | Average |
|---|---|
| BLOOMZ-7B | 30.27 |
| LLaMA-7B | 28.17 |
| Ziya-LLaMA-13B-pretrain | 27.64 |
| Falcon-7B | 27.18 |
| BLOOM-7B | 26.55 |
| Aquila-7B * | 25.58 |
| TigerBot-7B-base | 25.19 |
| ChatGLM-6B | 23.49 |
| Open-LLaMA-v2-pretrain | 23.49 |
| Baichuan-7B | 34.44 |
*其中Aquila 模型來源於智源官方網站(https://model.baai.ac.cn/model-detail/100098) 僅做參考
除了中文之外,Baichuan-7B也測試了模型在英文上的效果,MMLU 是包含57 個多選任務的英文評測數據集,涵蓋了初等數學、美國歷史、計算機科學、法律等,難度覆蓋高中水平到專家水平,是目前主流的LLM評測數據集。我們採用了開源的評測方案,最終5-shot結果如下所示:
| Model | Humanities | Social Sciences | STEM | Other | Average |
|---|---|---|---|---|---|
| ChatGLM-6B 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| BLOOMZ-7B 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| mpt-7B 1 | - | - | - | - | 35.6 |
| LLaMA-7B 2 | 34.0 | 38.3 | 30.5 | 38.1 | 35.1 |
| Falcon-7B 1 | - | - | - | - | 35.0 |
| moss-moon-003-sft (16B) 0 | 30.5 | 33.8 | 29.3 | 34.4 | 31.9 |
| BLOOM-7B 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25.5 |
| moss-moon-003-base (16B) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7B 0 | 38.4 | 48.9 | 35.6 | 48.1 | 42.3 |
0: 重新復現
1: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7B其中在MMLU 上57個任務的具體細指標如下圖:
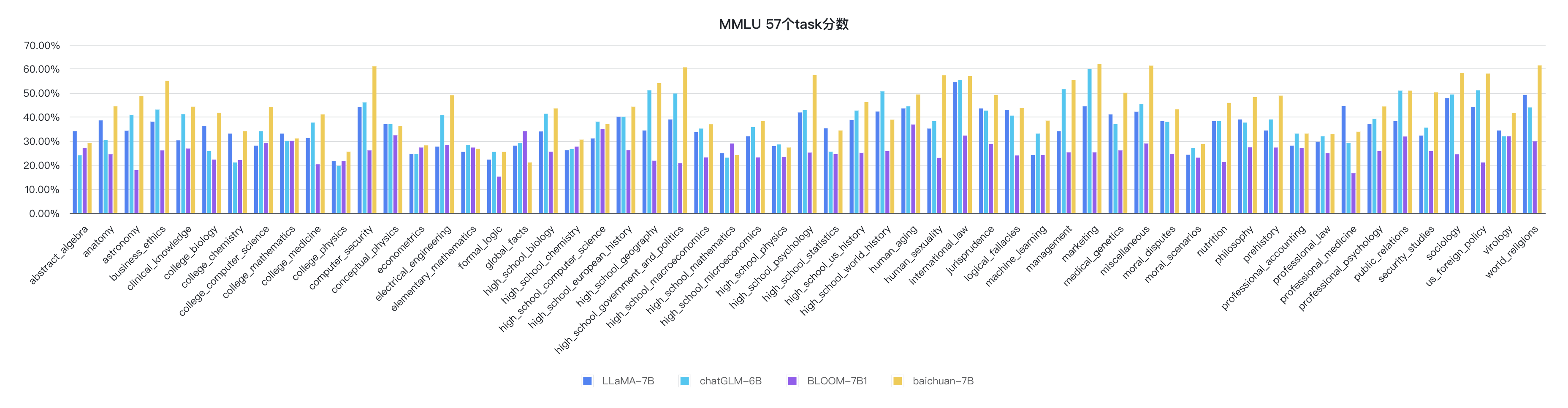
其中各個學科的指標如下圖:
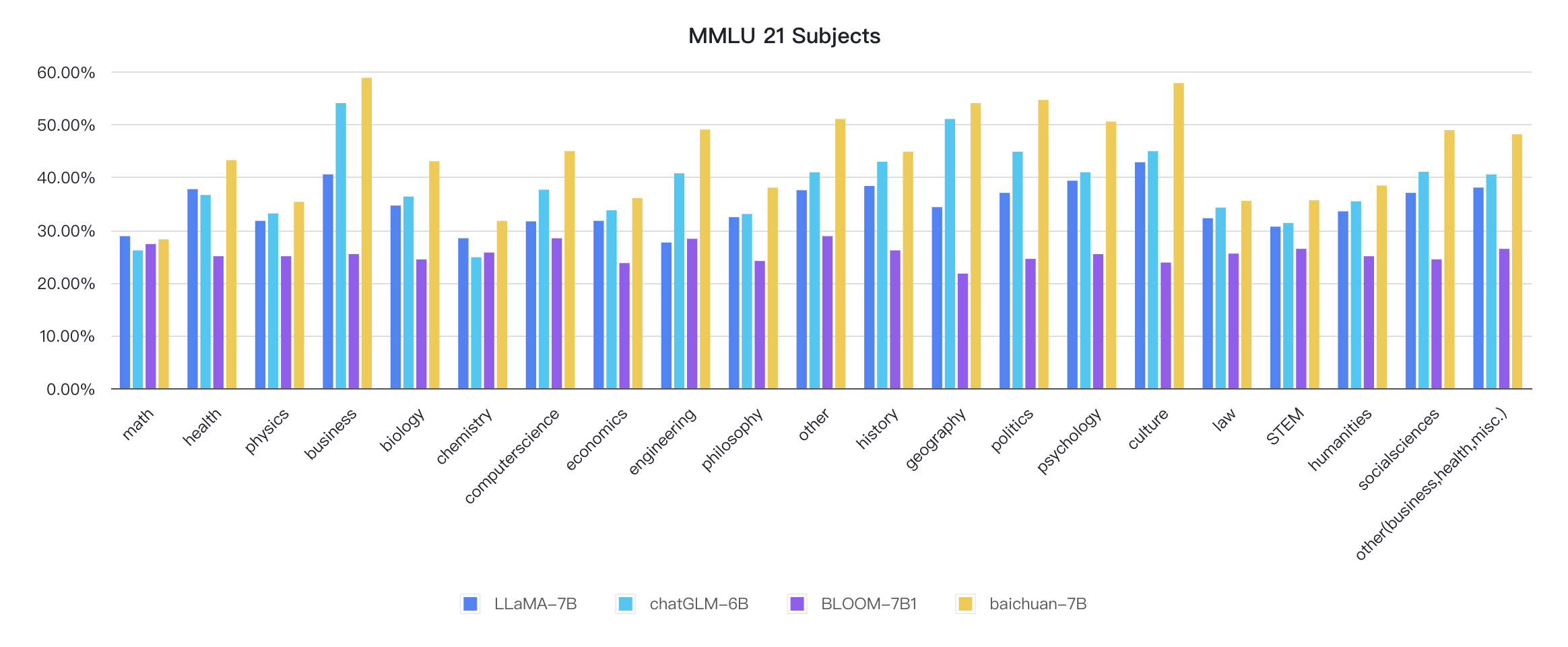
推理代碼已經在官方Huggingface 庫
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))整體流程如下所示:
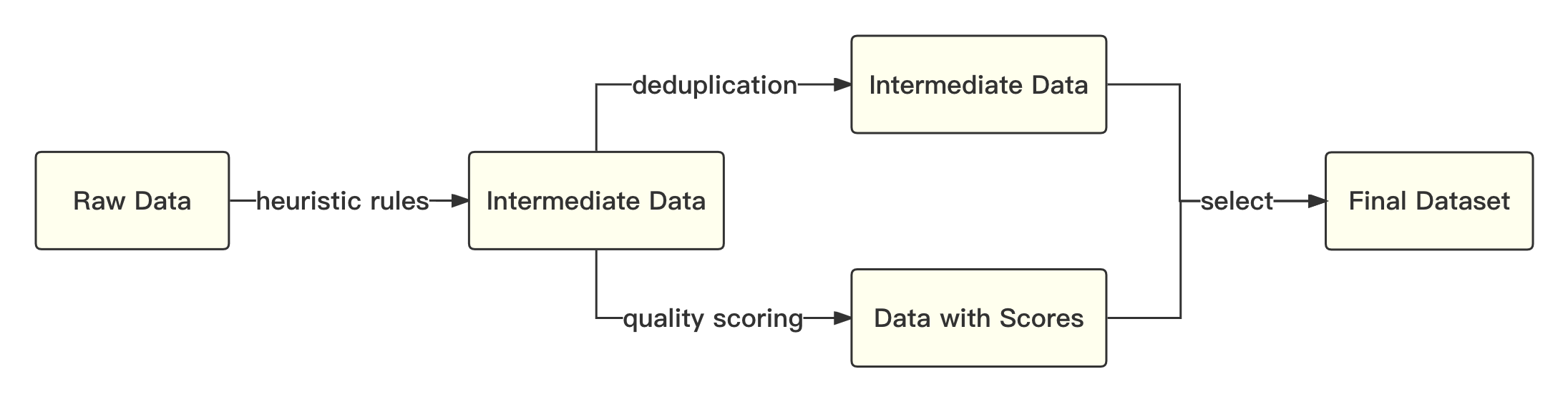
我們參考學術界方案使用SentencePiece 中的Byte-Pair Encoding (BPE) 作為分詞算法,並且進行了以下的優化:
| Model | Baichuan-7B | LLaMA | Falcon | mpt-7B | ChatGLM | moss-moon-003 |
|---|---|---|---|---|---|---|
| Compress Rate | 0.737 | 1.312 | 1.049 | 1.206 | 0.631 | 0.659 |
| Vocab Size | 64,000 | 32,000 | 65,024 | 50,254 | 130,344 | 106,029 |
整體模型基於標準的Transformer 結構,我們採用了和LLaMA 一樣的模型設計
我們在原本的LLaMA 框架上進行諸多修改以提升訓練時的吞吐,具體包括:
基於上述的幾個優化技術,我們在千卡A800 顯卡上達到了7B 模型182 TFLOPS 的吞吐,GPU 峰值算力利用率高達58.3%。
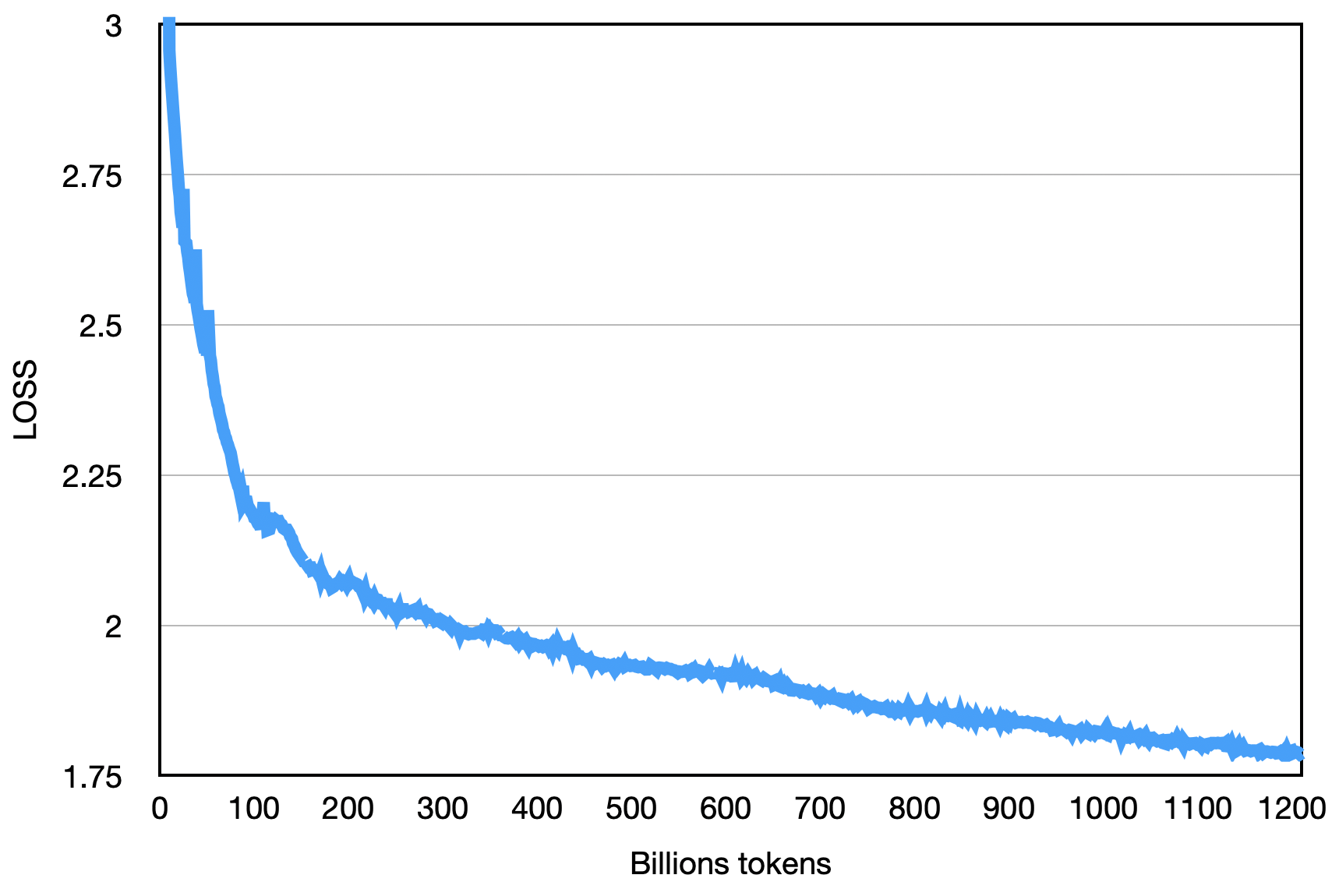
最終的loss如下圖:
pip install -r requirements.txt用戶將訓練語料按總rank數的倍數均勻切分成多個UTF-8 文本文件,放置在語料目錄(默認為data_dir )下。各個rank進程將會讀取語料目錄下的不同文件,全部加載到內存後,開始後續訓練過程。以上是簡化的示範流程,建議用戶在正式訓練任務中,根據需求調整數據生產邏輯。
下載tokenizer 模型文件tokenizer.model ,放置在項目目錄下。
本示范代碼採用DeepSpeed 框架進行訓練。用戶需根據集群情況,修改config/hostfile ,如果是多機多卡,需要修改ssh 中各個節點的IP 配置。具體可以參見DeepSpeed 官方說明。
scripts / train . sh對本倉庫源碼的使用遵循開源許可協議Apache 2.0。
Baichuan-7B 支持商用。如果將Baichuan-7B 模型或其衍生品用作商業用途,請您按照如下方式聯繫許可方,以進行登記並向許可方申請書面授權:聯繫郵箱:[email protected], 具體許可協議可見《Baichuan-7B 模型許可協議》。


