Baichuan 7B
1.0.0
?
Chinesisch |
Baichuan-7b ist ein im Handel erhältlicher Open-Source-Modell, das von Baichuan Intelligent entwickelt wurde. Basierend auf der Transformatorstruktur unterstützt das 7 -Milliarden -Parametermodell, das auf ungefähr 1,2 Billionen Token ausgebildet ist, die zweisprachigen chinesischen und englischen und die Kontextfensterlänge 4096. Die besten Ergebnisse in der gleichen Größe werden sowohl für die chinesische als auch für englische Benchmark (C-Eval/MMLU) erzielt.
Der C-Eval-Datensatz ist ein umfassender Datensatz für chinesische Basismodellbewertungen, der 52 Disziplinen und vier Schwierigkeitsgrade abdeckt. Wir haben den Dev-Set dieses Datensatzes als Quelle für wenige Schüsse verwendet und einen 5-shot -Test für den Testsatz durchgeführt. Führen Sie den folgenden Befehl durch Ausführung aus:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| Modell 5-Shot | Durchschnitt | Avg (hart) | STÄNGEL | Sozialwissenschaften | Geisteswissenschaften | Andere |
|---|---|---|---|---|---|---|
| GPT-4 | 68,7 | 54.9 | 67.1 | 77,6 | 64,5 | 67,8 |
| Chatgpt | 54.4 | 41,4 | 52.9 | 61,8 | 50.9 | 53.6 |
| Claude-V1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-Instant-V1.0 | 45,9 | 35.5 | 43.1 | 53,8 | 44,2 | 45,4 |
| Bloomz-7b | 35.7 | 25.8 | 31.3 | 43,5 | 36.6 | 35.6 |
| Chatglm-6b | 34.5 | 23.1 | 30.4 | 39.6 | 37,4 | 34.5 |
| Ziya-LLLAMA-13B-Vorstrain | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| Moos-Moon-003-Base (16b) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| LAMA-7B-HF | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7b | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| Tigerbot-7b-Base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7b * | 25,5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-LLAMA-V2-Vorstrain (7B) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| Bloom-7b | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7b | 42,8 | 31.5 | 38.2 | 52.0 | 46,2 | 39.3 |
Gaokao ist ein Datensatz, der Fragen zur Prüfung der chinesischen Hochschulen als Datensatz verwendet, um die Fähigkeit großer Sprachmodelle zu bewerten, die Sprachfähigkeit und die logische Argumentationsfähigkeit des Modells zu bewerten. Wir behielten nur die Fragen der Einzelauswahl bei und führten nach der zufälligen Aufteilung einen einheitlichen 5-shot -Test für alle Modelle durch.
Hier sind die Ergebnisse des Tests.
| Modell | Durchschnitt |
|---|---|
| Bloomz-7b | 28.72 |
| Lama-7b | 27.81 |
| Bloom-7b | 26.96 |
| Tigerbot-7b-Base | 25.94 |
| Falcon-7b | 23.98 |
| Ziya-LLLAMA-13B-Vorstrain | 23.17 |
| Chatglm-6b | 21.41 |
| Open-LLAMA-V2-Vorstrain | 21.41 |
| Aquila-7b * | 24.39 |
| Baichuan-7b | 36.24 |
Agieval zielt darauf ab, die allgemeinen Fähigkeiten des Modells bei kognitiven und Problemlösungsaufgaben zu bewerten. Wir haben nur vier davon beibehalten und nach der zufälligen Division einen einheitlichen 5-shot -Test für alle Modelle durchgeführt.
| Modell | Durchschnitt |
|---|---|
| Bloomz-7b | 30.27 |
| Lama-7b | 28.17 |
| Ziya-LLLAMA-13B-Vorstrain | 27.64 |
| Falcon-7b | 27.18 |
| Bloom-7b | 26.55 |
| Aquila-7b * | 25.58 |
| Tigerbot-7b-Base | 25.19 |
| Chatglm-6b | 23.49 |
| Open-LLAMA-V2-Vorstrain | 23.49 |
| Baichuan-7b | 34.44 |
* Das Aquila-Modell stammt von der offiziellen Website von Zhiyuan (https://model.baai.ac.cn/model-detail/100098) nur als Referenz
Zusätzlich zu Chinesen hat Baichuan-7b die Wirkung des Modells in englischer Sprache getestet. Wir haben ein Open-Source-Bewertungsschema übernommen, und die endgültigen 5-shot -Ergebnisse sind wie folgt:
| Modell | Geisteswissenschaften | Sozialwissenschaften | STÄNGEL | Andere | Durchschnitt |
|---|---|---|---|---|---|
| Chatglm-6b 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| Bloomz-7b 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| MPT-7B 1 | - - | - - | - - | - - | 35.6 |
| Lama-7b 2 | 34.0 | 38.3 | 30,5 | 38.1 | 35.1 |
| Falcon-7b 1 | - - | - - | - - | - - | 35.0 |
| Moss-moon-003-sft (16b) 0 | 30,5 | 33.8 | 29.3 | 34.4 | 31.9 |
| Bloom-7b 0 | 25.0 | 24.4 | 26,5 | 26.4 | 25,5 |
| Moss-Moon-003-Base (16B) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7b 0 | 38,4 | 48,9 | 35.6 | 48.1 | 42.3 |
0: Wieder auftauchen
1: https://huggingface.co/spaces/huggingfaceH4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-verstand-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7BDie spezifischen detaillierten Indikatoren der 57 Aufgaben auf MMLU sind wie folgt:
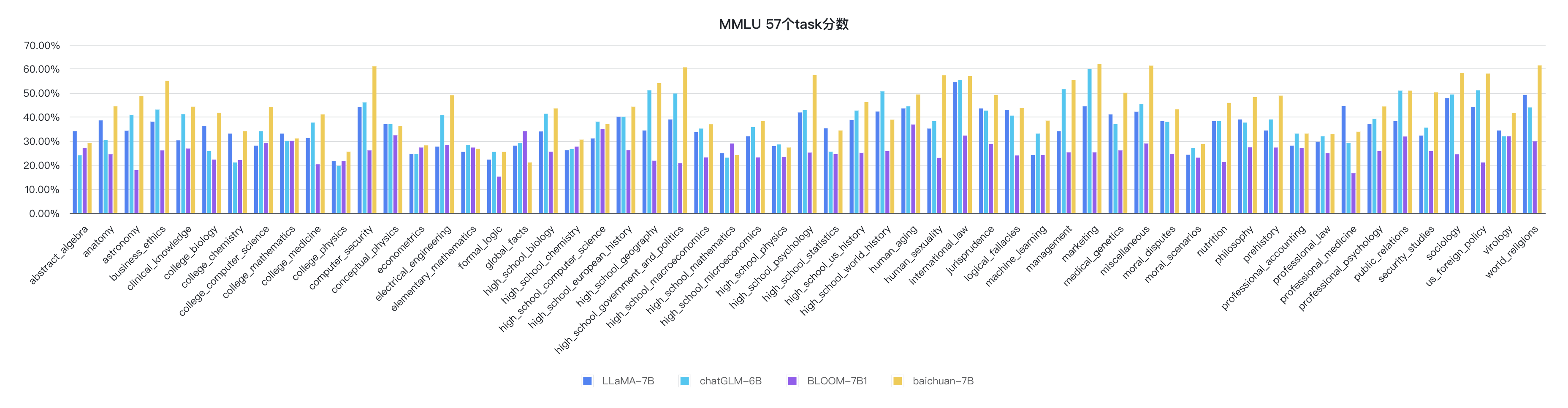
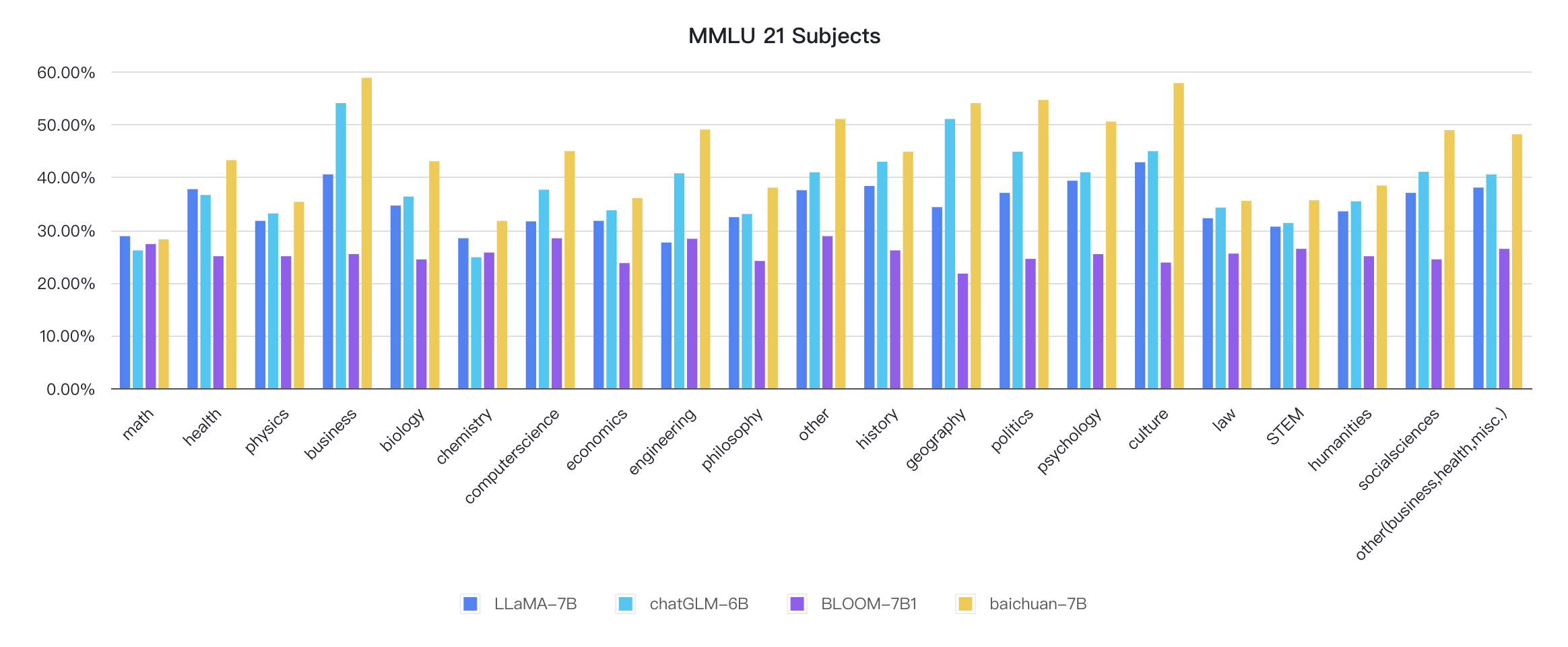
Die Indikatoren für jede Disziplin sind wie folgt:
Der Argumentationscode befindet sich bereits in der offiziellen Umarmungsbibliothek
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
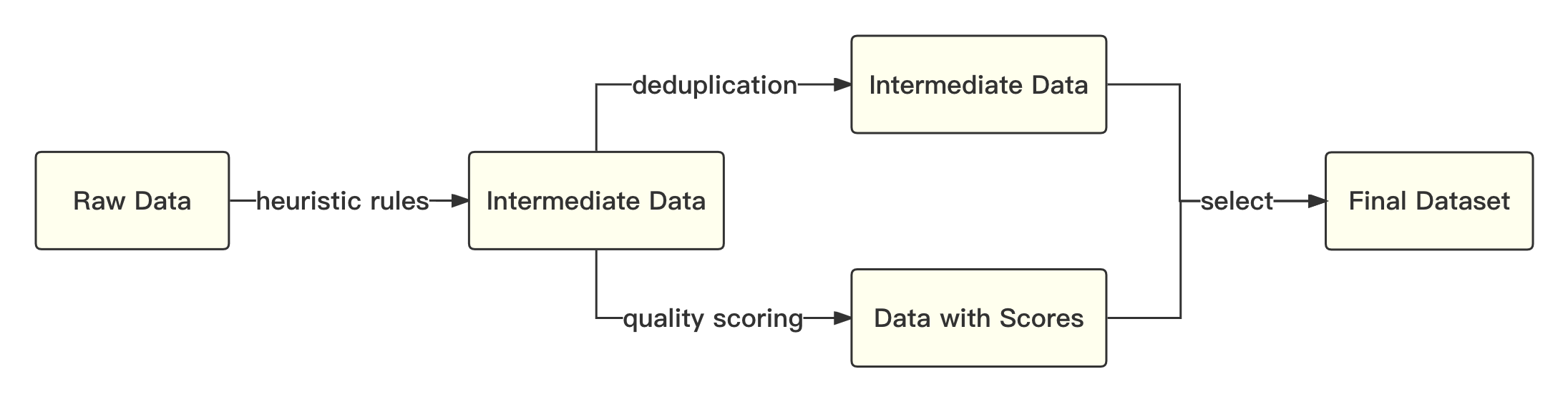
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Der Gesamtprozess ist wie folgt:
Wir beziehen uns auf die akademische Lösung, um die Byte-Pair-Codierung (BPE) im Satzstück als Word-Segmentierungsalgorithmus zu verwenden und die folgenden Optimierungen durchzuführen:
| Modell | Baichuan-7b | Lama | Falke | MPT-7B | Chatglm | Moss-moon-003 |
|---|---|---|---|---|---|---|
| Druckrate | 0,737 | 1.312 | 1.049 | 1.206 | 0,631 | 0,659 |
| Wortschatzgröße | 64.000 | 32.000 | 65.024 | 50.254 | 130.344 | 106.029 |
Das Gesamtmodell basiert auf der Standard -Transformatorstruktur, und wir übernehmen das gleiche Modelldesign wie Lama.
Wir haben viele Änderungen am ursprünglichen Lama -Framework vorgenommen, um den Durchsatz während des Trainings zu verbessern, einschließlich:
Basierend auf den oben genannten Optimierungstechnologien haben wir den Durchsatz von 7B -Modell 182 TFLOPS auf der Kilocard A800 -Grafikkarte erreicht, und die Peak -Rechennutzungsrate von GPU beträgt 58,3%.
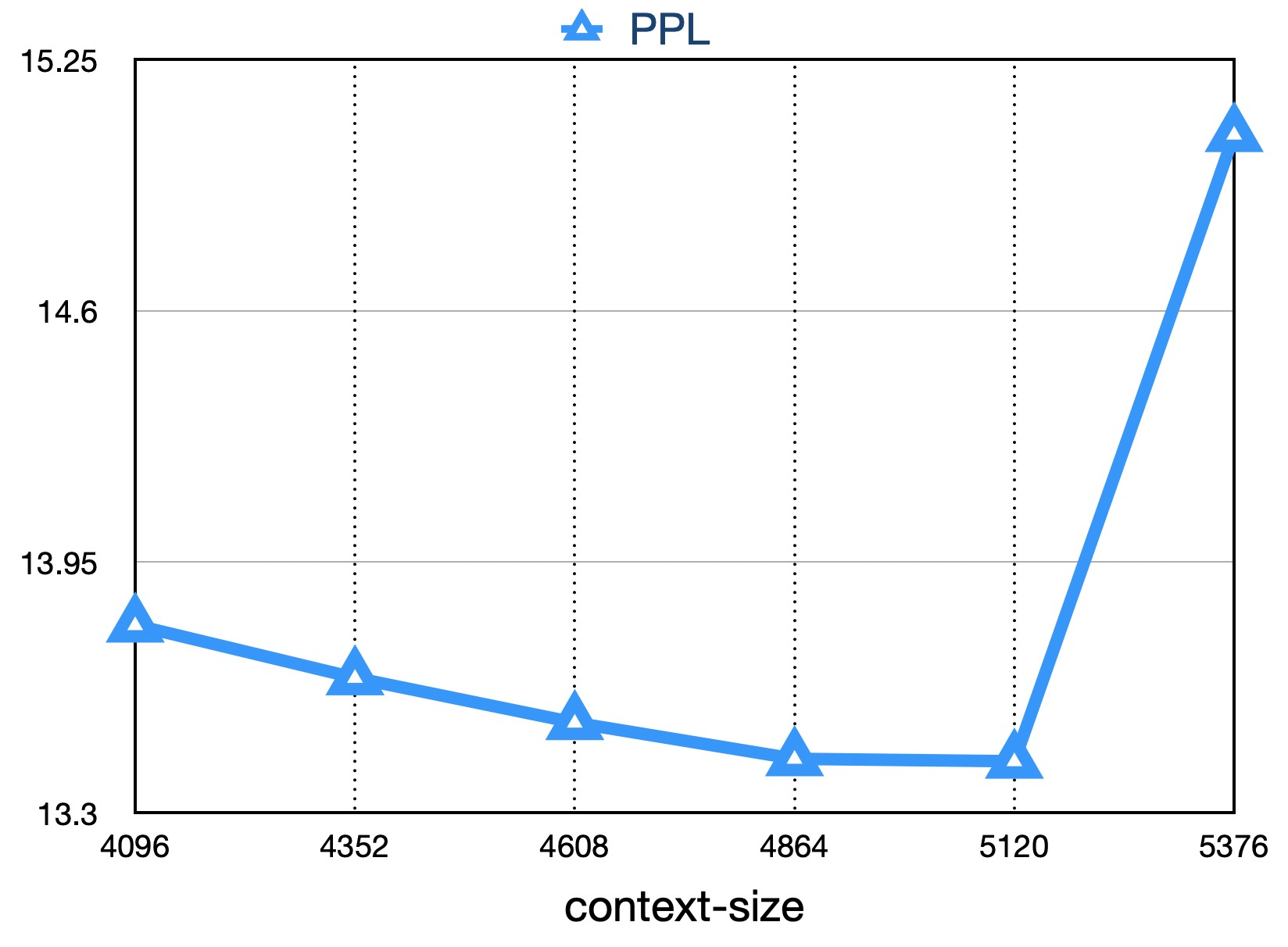
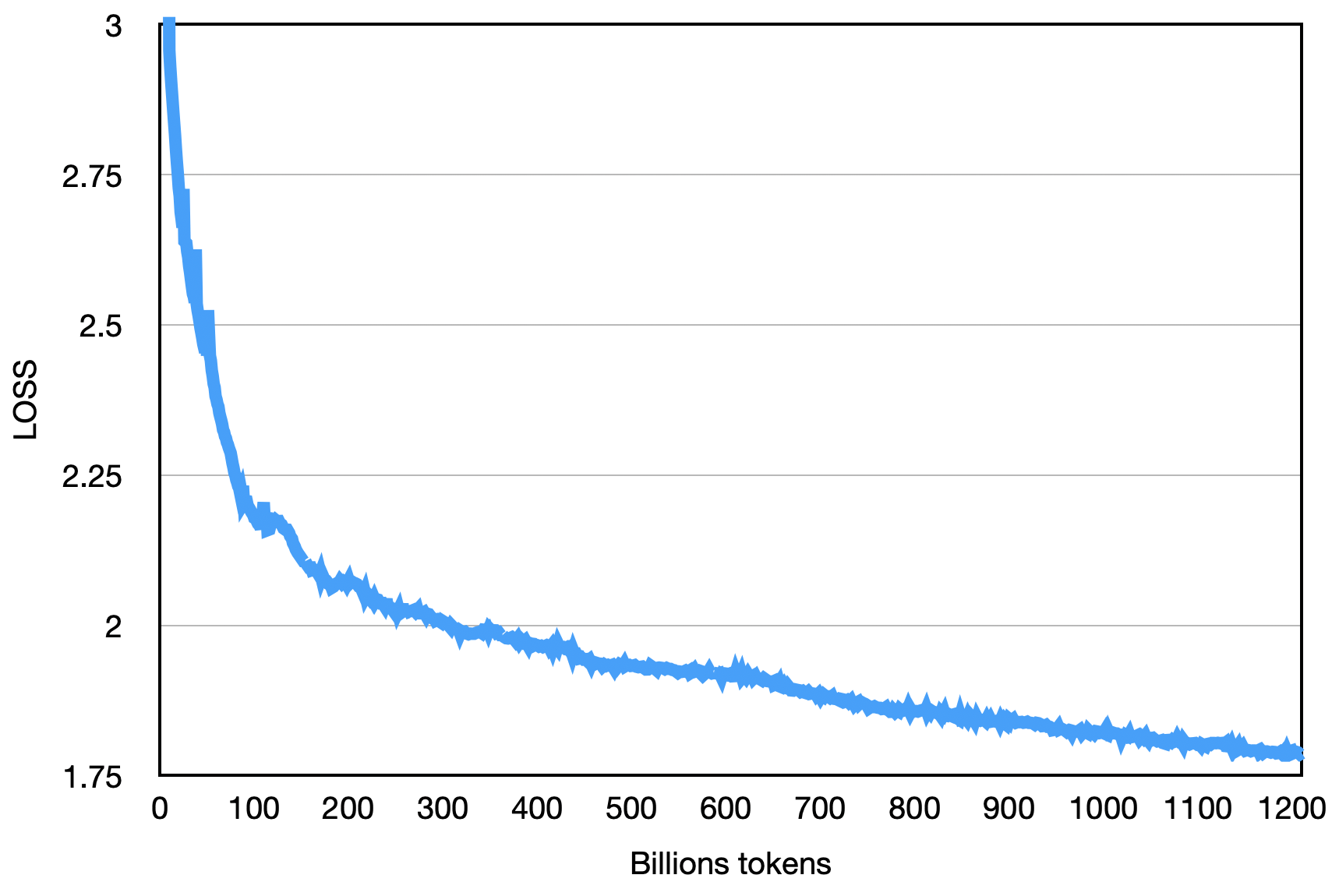
Der endgültige Verlust ist wie unten gezeigt:
pip install -r requirements.txt Der Benutzer unterteilt das Trainingskorpus gleichmäßig in mehrere UTF-8-Textdateien gemäß den Multiplikaten der Gesamtrangnummer und platziert ihn in das Corpus-Verzeichnis (Standard ist data_dir ). In jedem Rangprozess werden verschiedene Dateien im Corpus -Verzeichnis gelesen und schließlich in den Speicher geladen, den nachfolgenden Trainingsprozess. Das obige ist ein vereinfachter Demonstrationsprozess.
Laden Sie den Tokenizer Model Datei Tokenizer.model herunter und platzieren Sie sie in das Projektverzeichnis.
Dieser Demonstrationscode wird mit dem DeepSpeed -Framework trainiert. Benutzer müssen config/hostfile gemäß der Cluster-Situation ändern. Weitere Informationen finden Sie in den offiziellen Anweisungen für Deepspeed.
scripts / train . shDie Verwendung dieses Repository -Quellcodes unterliegt der Open -Source -Lizenzvereinbarung Apache 2.0.
Baichuan-7b ist im Handel erhältlich. Wenn das Baichuan-7b-Modell oder seine Derivate für kommerzielle Zwecke verwendet werden, wenden Sie sich bitte an den Lizenzgeber, um sich vom Lizenzgeber zu registrieren und eine schriftliche Genehmigung zu beantragen.


