Baichuan 7B
1.0.0
?
Chino |
Baichuan-7b es un modelo de lenguaje previamente a gran escala disponible comercialmente de código abierto desarrollado por Baichuan Intelligent. Basado en la estructura del transformador, el modelo de parámetros de 7 mil millones entrenado en aproximadamente 1.2 billones de tokens admite bilingüe chino e inglés, y la longitud de la ventana de contexto es 4096. Los mejores resultados en el mismo tamaño se logran en el punto de referencia chino e inglés estándar (C-EVAL/MMLU).
El conjunto de datos C-EVAL es un conjunto integral de datos de evaluación del modelo básico chino que cubre 52 disciplinas y cuatro niveles de dificultad. Utilizamos el conjunto de desarrollo de este conjunto de datos como fuente de pocos disparos y realizamos una prueba 5-shot en el conjunto de pruebas. Ejecutar el siguiente comando ejecutando:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| Modelo 5 | Promedio | AVG (duro) | PROVENIR | Ciencias sociales | Humanidades | Otros |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| Chatgpt | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-V1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-Instant-V1.0 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| BOOMZ-7B | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| Chatglm-6b | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| Ziya-llama-13b pretratina | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| Moss-moon-003-base (16B) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| LLAMA-7B-HF | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7b | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| Tigerbot-7b-base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7b * | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Pretrain Open-Llama-V2 (7b) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| Bloom-7b | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7b | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
Gaokao es un conjunto de datos que utiliza preguntas de examen de ingreso de la universidad china como un conjunto de datos para evaluar la capacidad de los modelos de idiomas grandes para evaluar la capacidad del lenguaje y la capacidad de razonamiento lógico del modelo. Solo conservamos las preguntas de opción única y realizamos una prueba unificada 5-shot en todos los modelos después de la división aleatoria.
Aquí están los resultados de la prueba.
| Modelo | Promedio |
|---|---|
| BOOMZ-7B | 28.72 |
| Llama-7b | 27.81 |
| Bloom-7b | 26.96 |
| Tigerbot-7b-base | 25.94 |
| Falcon-7b | 23.98 |
| Ziya-llama-13b pretratina | 23.17 |
| Chatglm-6b | 21.41 |
| Pretratina de Llama-V2 | 21.41 |
| Aquila-7b * | 24.39 |
| Baichuan-7b | 36.24 |
AGIEVAL tiene como objetivo evaluar las habilidades generales del modelo en tareas cognitivas y de resolución de problemas. Solo conservamos cuatro de ellos y realizamos una prueba unificada 5-shot en todos los modelos después de la división aleatoria.
| Modelo | Promedio |
|---|---|
| BOOMZ-7B | 30.27 |
| Llama-7b | 28.17 |
| Ziya-llama-13b pretratina | 27.64 |
| Falcon-7b | 27.18 |
| Bloom-7b | 26.55 |
| Aquila-7b * | 25.58 |
| Tigerbot-7b-base | 25.19 |
| Chatglm-6b | 23.49 |
| Pretratina de Llama-V2 | 23.49 |
| Baichuan-7b | 34.44 |
* El modelo Aquila proviene del sitio web oficial de Zhiyuan (https://model.baai.ac.cn/model-detail/100098) solo para referencia
Además del chino, Baichuan-7b también probó el efecto del modelo en inglés. Adoptamos un esquema de evaluación de código abierto, y los resultados finales 5-shot son los siguientes:
| Modelo | Humanidades | Ciencias sociales | PROVENIR | Otro | Promedio |
|---|---|---|---|---|---|
| Chatglm-6b 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| BOOMZ-7B 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| MPT-7B 1 | - | - | - | - | 35.6 |
| Llama-7b 2 | 34.0 | 38.3 | 30.5 | 38.1 | 35.1 |
| Falcon-7b 1 | - | - | - | - | 35.0 |
| Moss-moon-003-sft (16b) 0 | 30.5 | 33.8 | 29.3 | 34.4 | 31.9 |
| Bloom-7b 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25.5 |
| Moss-moon-003-base (16b) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7b 0 | 38.4 | 48.9 | 35.6 | 48.1 | 42.3 |
0: reaparecer
1: https://huggingface.co/spaces/huggingfaceh4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-indandanding-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7BLos indicadores detallados específicos de las 57 tareas en MMLU son los siguientes:
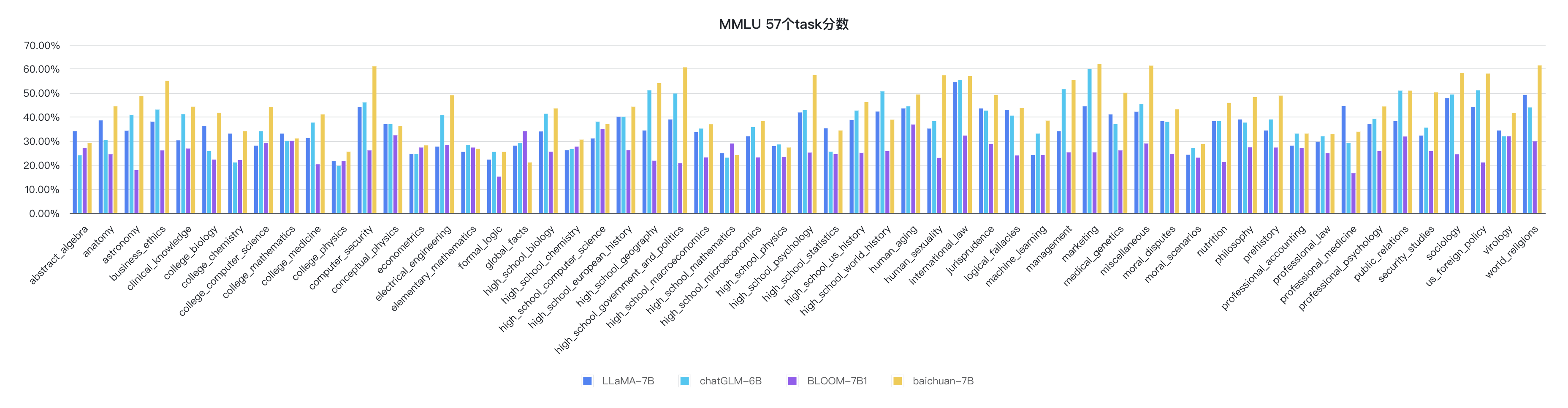
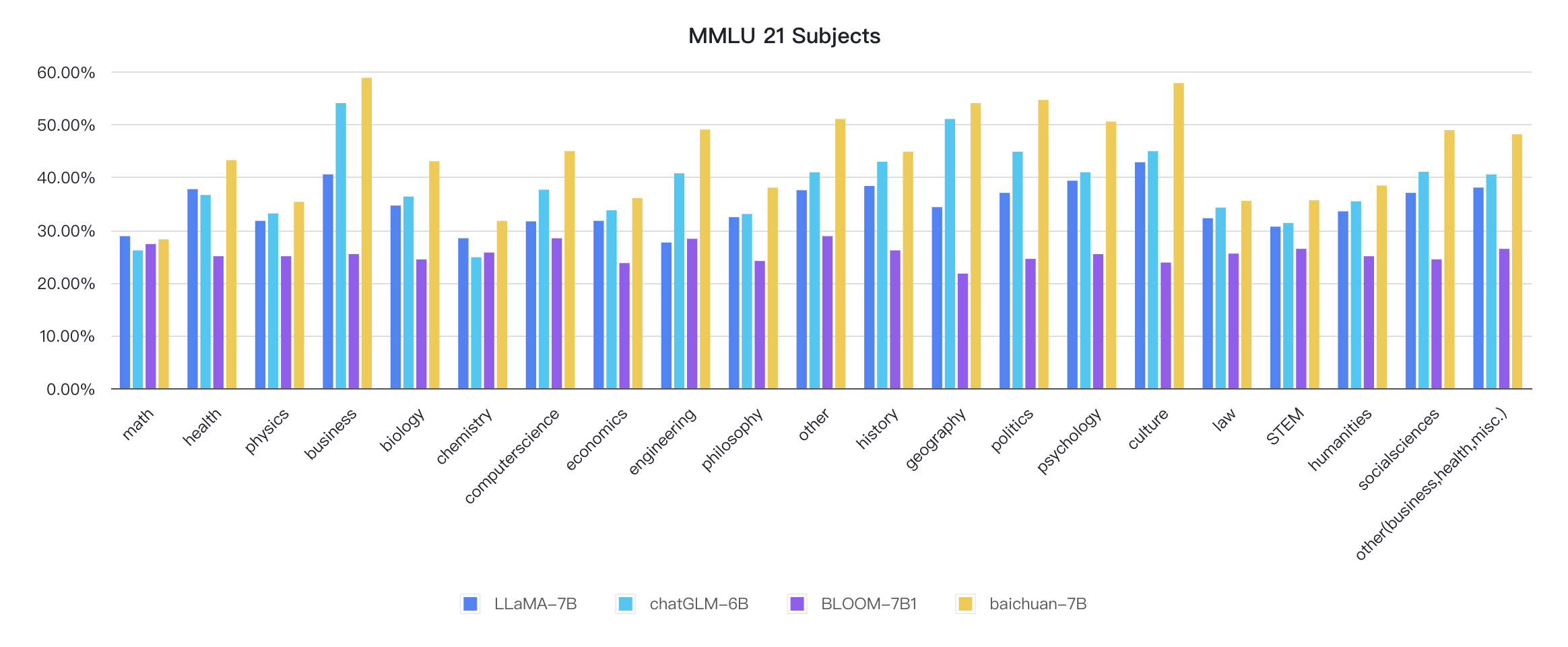
Los indicadores de cada disciplina son los siguientes:
El código de razonamiento ya está en la biblioteca oficial de Huggingface
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
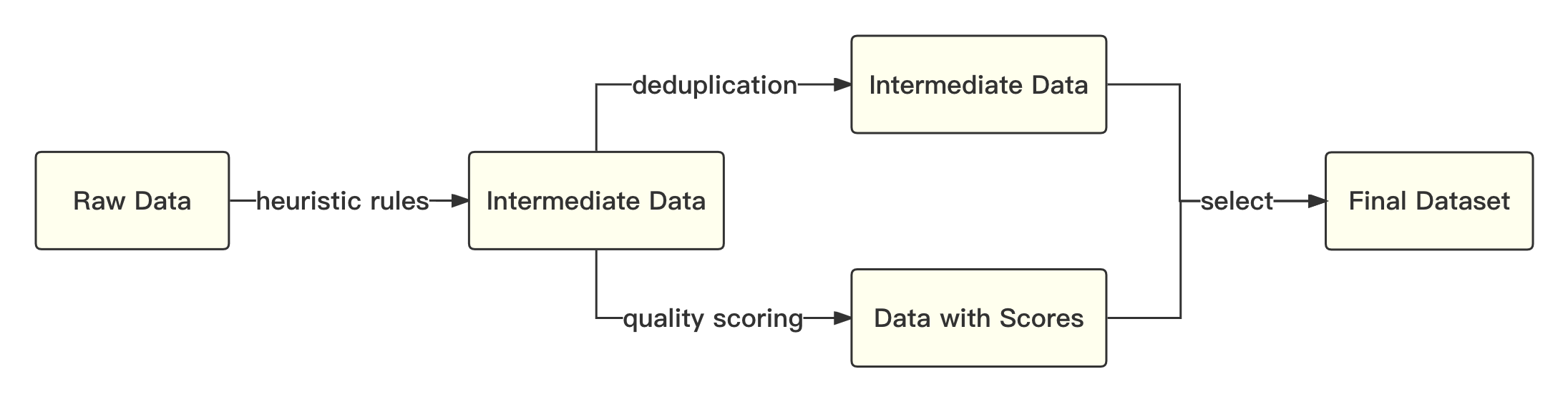
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))El proceso general es el siguiente:
Nos referimos a la solución académica para usar la codificación de par de bytes (BPE) en la pieza de oración como algoritmo de segmentación de palabras y realizar las siguientes optimizaciones:
| Modelo | Baichuan-7b | Llama | Halcón | MPT-7B | Chatglm | Moss-moon-003 |
|---|---|---|---|---|---|---|
| Tasa de compresa | 0.737 | 1.312 | 1.049 | 1.206 | 0.631 | 0.659 |
| Tamaño de vocabul | 64,000 | 32,000 | 65,024 | 50,254 | 130,344 | 106,029 |
El modelo general se basa en la estructura del transformador estándar, y adoptamos el mismo diseño del modelo que la LLAMA.
Hicimos muchas modificaciones en el marco de la llama original para mejorar el rendimiento durante la capacitación, incluida:
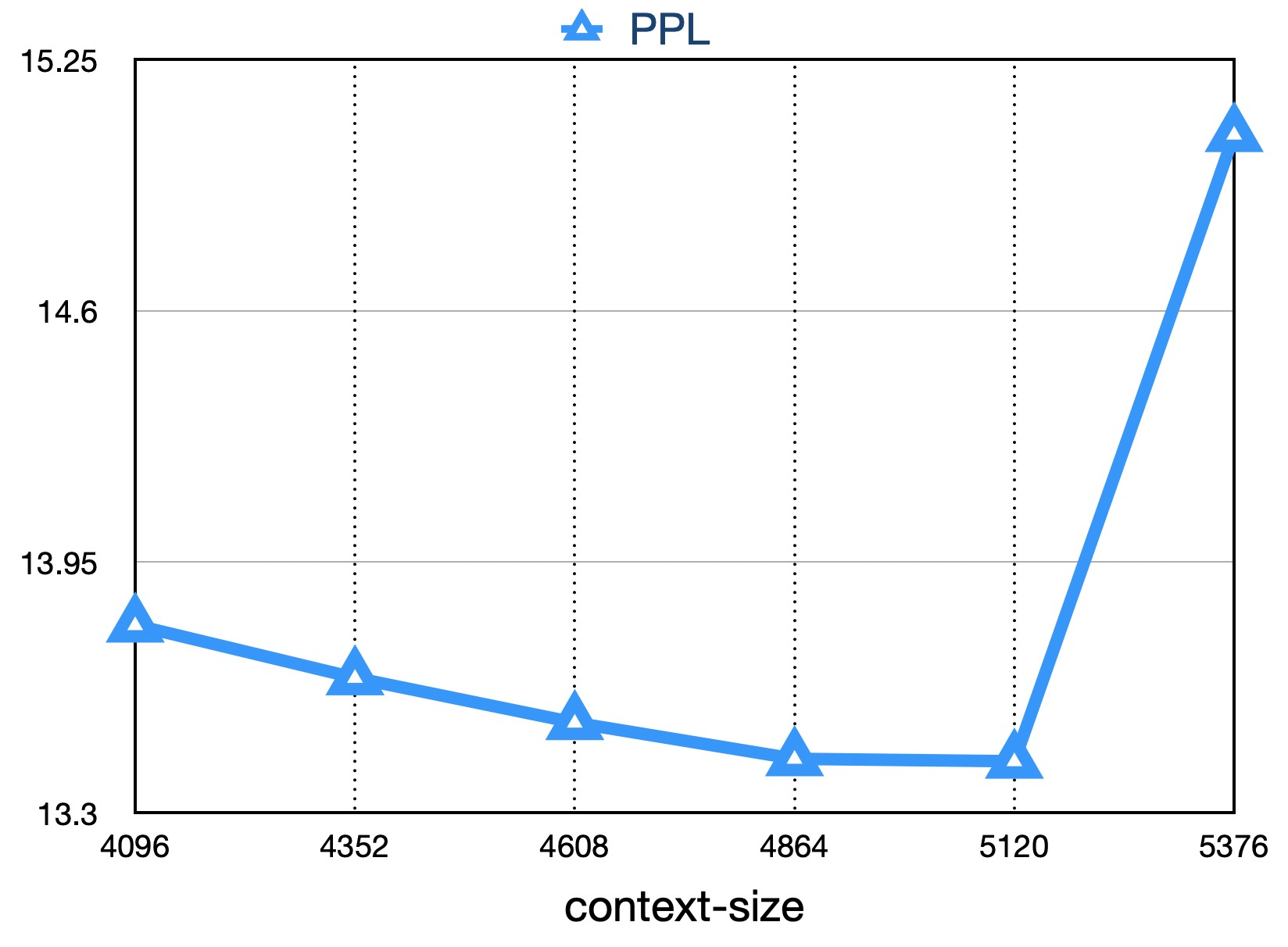
Según las tecnologías de optimización anteriores, hemos logrado el rendimiento del modelo 7b 182 Tflops en la tarjeta gráfica Kilocard A800, y la tasa de utilización de potencia informática máxima de GPU es tan alta como 58.3%.
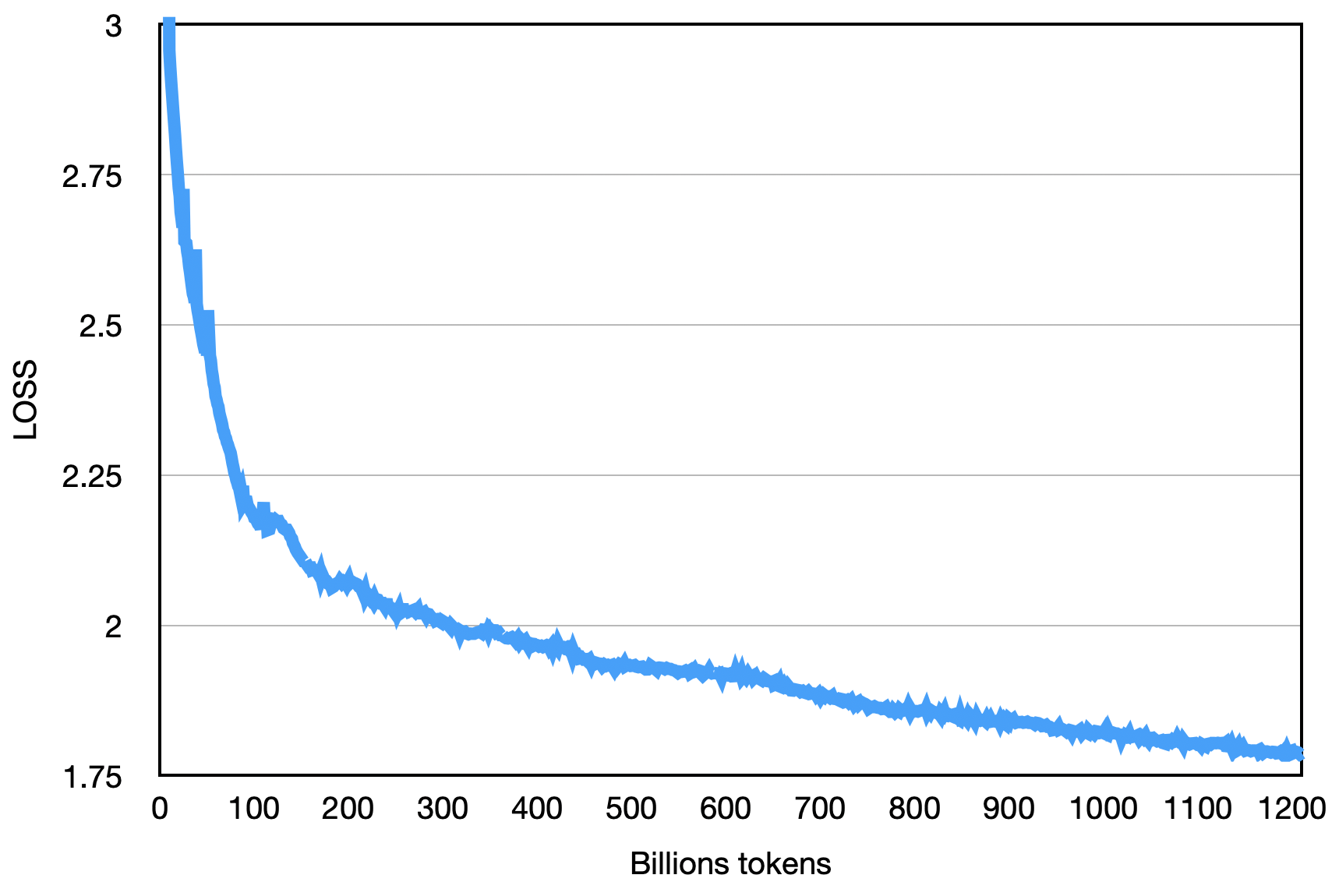
La pérdida final es la que se muestra a continuación:
pip install -r requirements.txt El usuario divide uniformemente el corpus de entrenamiento en múltiples archivos de texto UTF-8 de acuerdo con los múltiplos del número de rango total y lo coloca en el directorio de Corpus (predeterminado es data_dir ). Cada proceso de rango leerá diferentes archivos en el directorio de Corpus, y después de todo cargarlos en la memoria, comenzará el proceso de capacitación posterior. Lo anterior es un proceso de demostración simplificado.
Descargue el modelo Tokenizer.model del archivo Tokenizer y colóquelo en el directorio del proyecto.
Este código de demostración está entrenado utilizando el marco Deepspeed. Los usuarios deben modificar config/hostfile de acuerdo con la situación del clúster. Para más detalles, consulte las instrucciones oficiales de DeepSpeed.
scripts / train . shEl uso de este código fuente del repositorio está sujeto al acuerdo de licencia de código abierto Apache 2.0.
Baichuan-7b está disponible comercialmente. Si el modelo Baichuan-7B o sus derivados se utilizan para fines comerciales, comuníquese con el licenciatura de la siguiente manera para registrarse y solicitar la autorización por escrito del licenciante: Póngase en contacto con el correo electrónico: [email protected].


