Baichuan 7B
1.0.0
? Embrasser le modèle •?
Chinois |
Baichuan-7b est un modèle de langue pré-formé à grande échelle disponible dans le commerce open source développé par Baichuan Intelligent. Sur la base de la structure du transformateur, le modèle de paramètres de 7 milliards formé sur environ 1,2 billion de jetons prend en charge le bilingue chinois et anglais, et la longueur de la fenêtre de contexte est 4096. Les meilleurs résultats de la même taille sont obtenus à la fois sur la référence chinoise et anglaise standard (C-Eval / MMLU).
L'ensemble de données C-Eval est un ensemble complet de données d'évaluation du modèle de base chinois couvrant 52 disciplines et quatre niveaux de difficulté. Nous avons utilisé l'ensemble de développement de cet ensemble de données comme source de quelques tirs et effectué un test 5-shot sur l'ensemble de tests. Exécutez la commande suivante en exécutant:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| Modèle 5-Shot | Moyenne | AVG (dur) | TIGE | Sciences sociales | Sciences humaines | Autres |
|---|---|---|---|---|---|---|
| Gpt-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| Chatte | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-V1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-Instant-V1.0 | 45.9 | 35,5 | 43.1 | 53.8 | 44.2 | 45.4 |
| Bloomz-7b | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| Chatglm-6b | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| Ziya-lelama-13b-prétraitement | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| Moss-moon-003-base (16b) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| Lama-7b-hf | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7B | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| Tigerbot-7b-base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7b * | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-Llama-V2-prétraigne (7b) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| Bloom-7b | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7b | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
Gaokao est un ensemble de données qui utilise des questions d'examen de l'entrée du collège chinois comme ensemble de données pour évaluer la capacité des modèles de grande langue à évaluer la capacité linguistique et la capacité de raisonnement logique du modèle. Nous n'avons conservé les questions à choix unique et effectué un test unifié 5-shot sur tous les modèles après une division aléatoire.
Voici les résultats du test.
| Modèle | Moyenne |
|---|---|
| Bloomz-7b | 28.72 |
| Lama-7b | 27.81 |
| Bloom-7b | 26.96 |
| Tigerbot-7b-base | 25.94 |
| Falcon-7B | 23.98 |
| Ziya-lelama-13b-prétraitement | 23.17 |
| Chatglm-6b | 21.41 |
| Open-Llama-V2-prétraitement | 21.41 |
| Aquila-7b * | 24.39 |
| Baichuan-7b | 36.24 |
Agieval vise à évaluer les capacités générales du modèle dans les tâches cognitives et de résolution de problèmes. Nous n'avons conservé que quatre d'entre eux et effectué un test unifié 5-shot sur tous les modèles après une division aléatoire.
| Modèle | Moyenne |
|---|---|
| Bloomz-7b | 30.27 |
| Lama-7b | 28.17 |
| Ziya-lelama-13b-prétraitement | 27.64 |
| Falcon-7B | 27.18 |
| Bloom-7b | 26.55 |
| Aquila-7b * | 25.58 |
| Tigerbot-7b-base | 25.19 |
| Chatglm-6b | 23.49 |
| Open-Llama-V2-prétraitement | 23.49 |
| Baichuan-7b | 34.44 |
* Le modèle Aquila provient du site officiel de Zhiyuan (https://model.baai.ac.cn/model-detail/100098) pour référence uniquement
En plus du chinois, Baichuan-7b a également testé l'effet du modèle en anglais. Nous avons adopté un schéma d'évaluation open source et les résultats finaux 5-shot sont les suivants:
| Modèle | Sciences humaines | Sciences sociales | TIGE | Autre | Moyenne |
|---|---|---|---|---|---|
| Chatglm-6b 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| Bloomz-7b 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| MPT-7B 1 | - | - | - | - | 35.6 |
| Lama-7b 2 | 34.0 | 38.3 | 30.5 | 38.1 | 35.1 |
| Falcon-7b 1 | - | - | - | - | 35.0 |
| moss-moon-003-sft (16b) 0 | 30.5 | 33.8 | 29.3 | 34.4 | 31.9 |
| Bloom-7b 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25.5 |
| Moss-moon-003-base (16b) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7b 0 | 38.4 | 48.9 | 35.6 | 48.1 | 42.3 |
0: réapparaître
1: https://huggingface.co/spaces/huggingfaceh4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-udgetanding-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7BLes indicateurs détaillés spécifiques des 57 tâches sur MMLU sont les suivants:
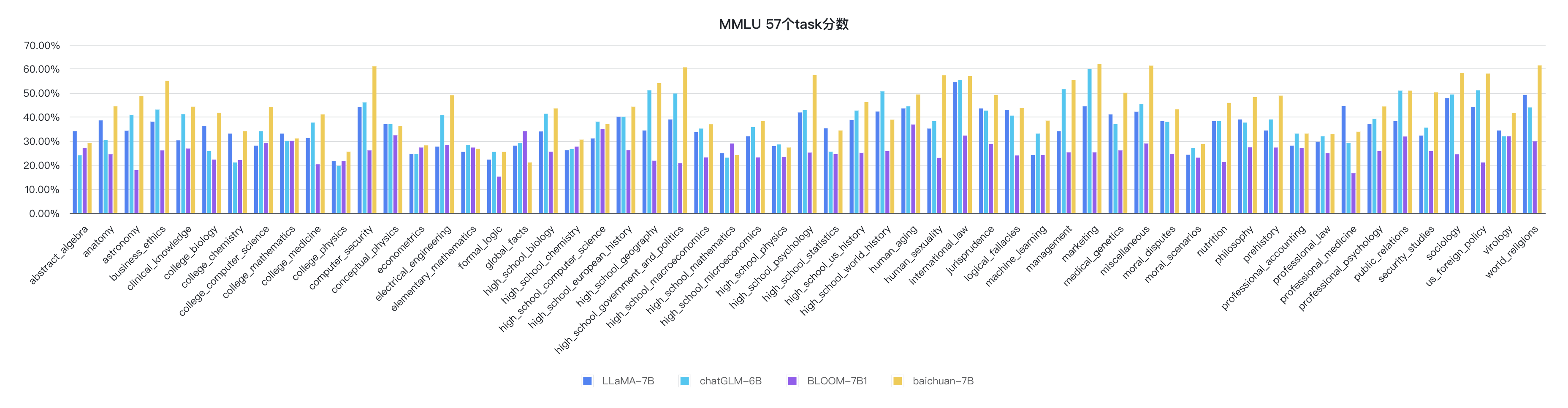
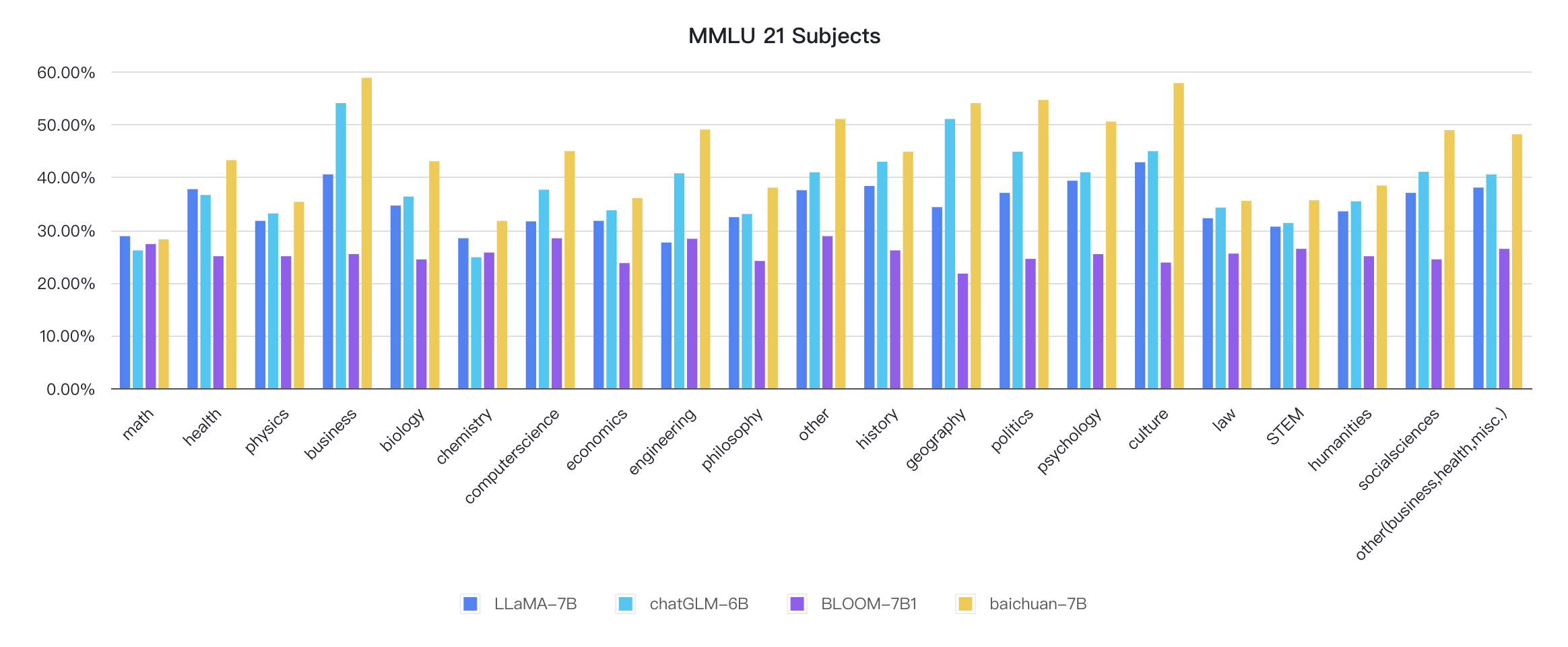
Les indicateurs de chaque discipline sont les suivants:
Le code de raisonnement est déjà dans la bibliothèque officielle des étreintes
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
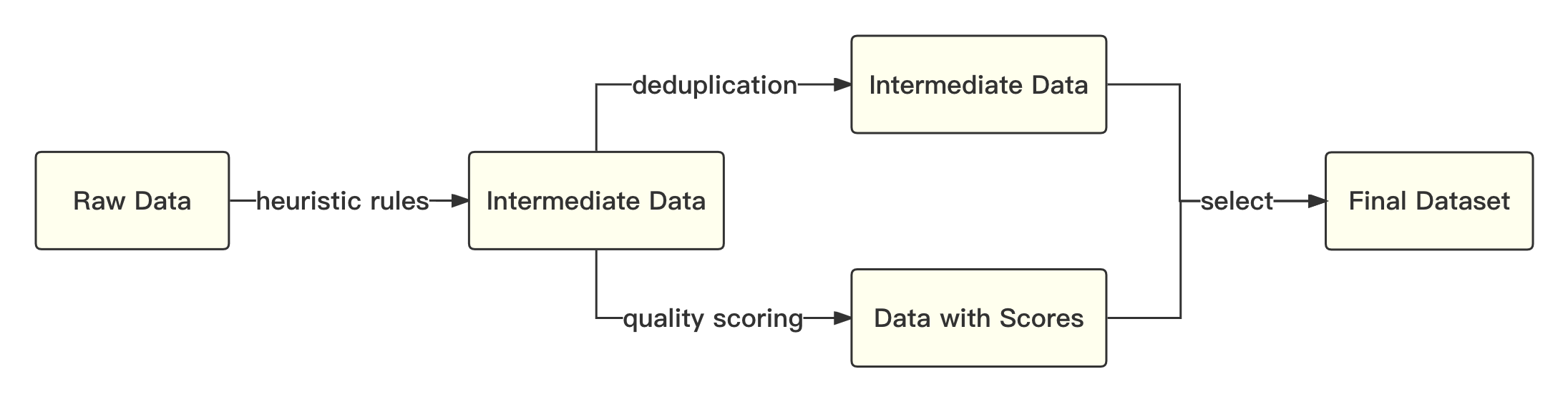
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Le processus global est le suivant:
Nous nous référons à la solution académique pour utiliser le codage des paires d'octets (BPE) dans la phrase comme algorithme de segmentation de mots et effectuer les optimisations suivantes:
| Modèle | Baichuan-7b | Lama | Faucon | MPT-7B | Chatglm | Moss-moon-003 |
|---|---|---|---|---|---|---|
| Taux de compression | 0,737 | 1.312 | 1.049 | 1.206 | 0,631 | 0,659 |
| Taille du vocab | 64 000 | 32 000 | 65 024 | 50 254 | 130 344 | 106 029 |
Le modèle global est basé sur la structure du transformateur standard, et nous adoptons le même modèle de conception que LLAMA.
Nous avons apporté de nombreuses modifications au cadre original de lama pour améliorer le débit pendant la formation, notamment:
Sur la base des technologies d'optimisation ci-dessus, nous avons atteint le débit de TFLOP 7B modèle 182 sur la carte graphique Kilocard A800, et le taux d'utilisation de puissance de calcul de pointe du GPU est élevé que 58,3%.
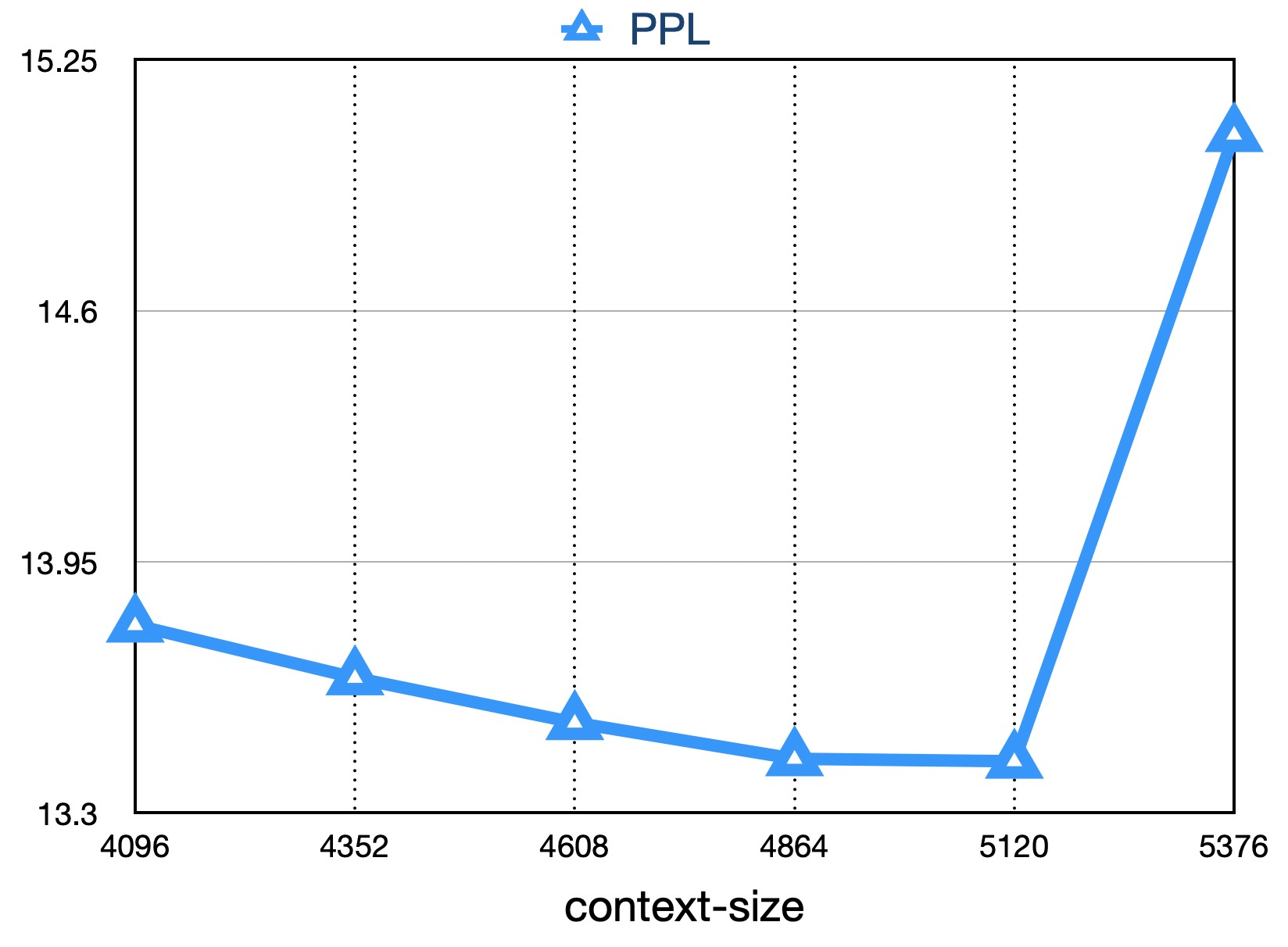
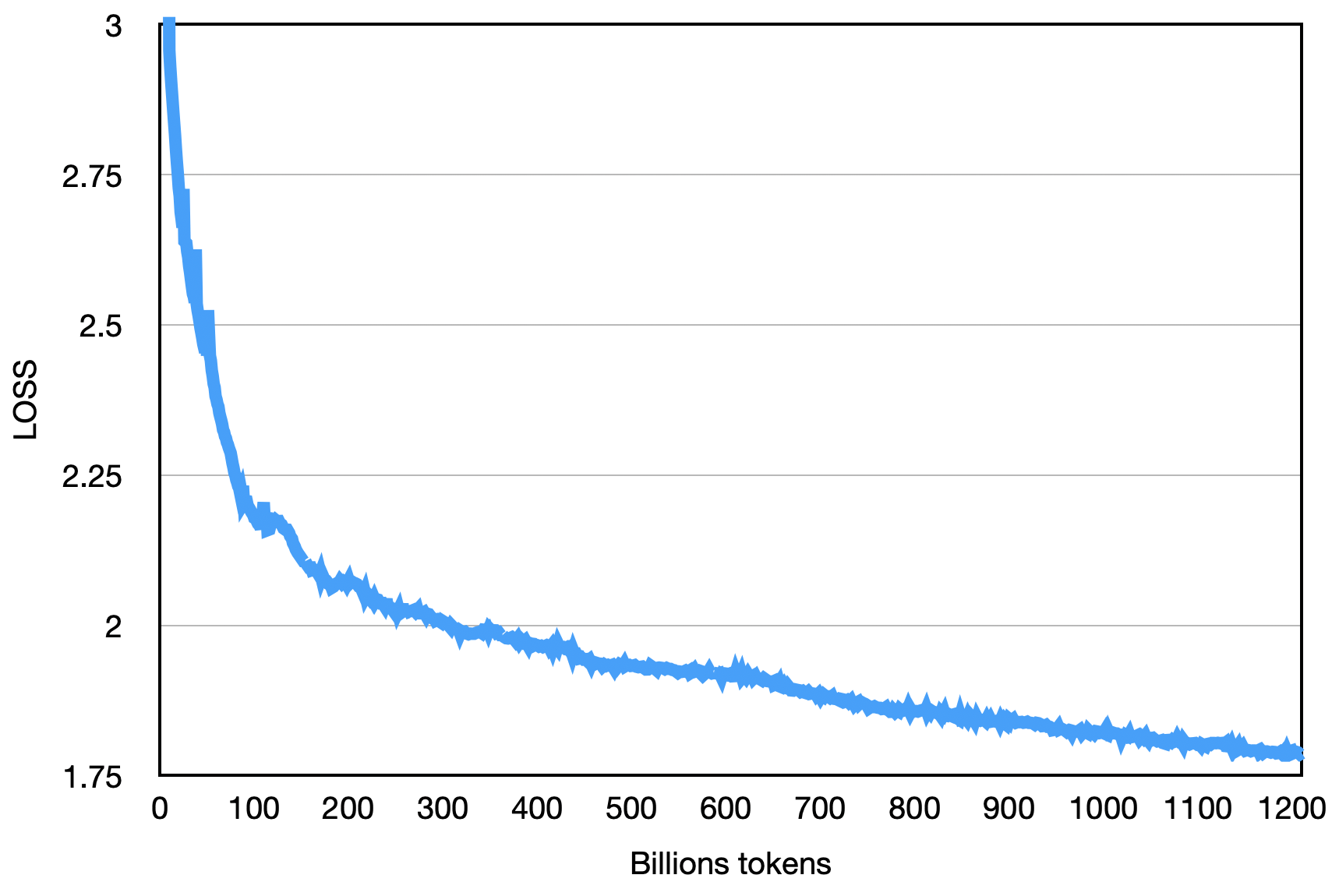
La perte finale est comme indiqué ci-dessous:
pip install -r requirements.txt L'utilisateur divise uniformément le corpus de formation en plusieurs fichiers texte UTF-8 en fonction des multiples du numéro de rang total et le place dans le répertoire Corpus (la valeur par défaut est data_dir ). Chaque processus de classement lira différents fichiers dans le répertoire Corpus, et après tout les charger en mémoire, il commencera le processus de formation ultérieur. Ce qui précède est un processus de démonstration simplifié.
Téléchargez le fichier Tokenizer Fichier Tokenizer.Model et placez-le dans le répertoire du projet.
Ce code de démonstration est formé à l'aide du cadre Deeppeed. Les utilisateurs doivent modifier config/hostfile en fonction de la situation du cluster. Pour plus de détails, veuillez vous référer aux instructions officielles Deeppeed.
scripts / train . shL'utilisation de ce code source de référentiel est soumise au contrat de licence open source Apache 2.0.
Baichuan-7b est disponible dans le commerce. Si le modèle Baichuan-7B ou ses dérivés sont utilisés à des fins commerciales, veuillez contacter le concédant de licence comme suit pour s'inscrire et demander l'autorisation écrite du concédant: Contactez Email: [email protected].


