Baichuan 7B
1.0.0
ใบหน้ากอด?
ภาษา จีน
Baichuan-7b เป็นแบบจำลองภาษาที่มีการฝึกอบรมล่วงหน้าขนาดใหญ่ที่พัฒนาโดย Baichuan Intelligent ขึ้นอยู่กับโครงสร้างของหม้อแปลงรุ่นพารามิเตอร์ 7 พันล้านที่ผ่านการฝึกอบรมบนโทเค็นประมาณ 1.2 ล้านล้านรองรับภาษาจีนและภาษาอังกฤษสองภาษาและความยาวของหน้าต่างบริบทคือ 4096 ผลลัพธ์ที่ดีที่สุดในขนาดเดียวกันนั้นสามารถทำได้ทั้งมาตรฐานจีนและภาษาอังกฤษมาตรฐาน (C-EVAL/MMLU)
ชุดข้อมูล C-Eval เป็นชุดข้อมูลการประเมินแบบจำลองพื้นฐานของจีนที่ครอบคลุมซึ่งครอบคลุม 52 สาขาและสี่ระดับของความยากลำบาก เราใช้ชุด dev ของชุดข้อมูลนี้เป็นแหล่งที่มาของการยิงไม่กี่นัดและทำการทดสอบ 5-shot ในชุดทดสอบ ดำเนินการคำสั่งต่อไปนี้โดยดำเนินการ:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| รุ่น 5-shot | เฉลี่ย | AVG (ยาก) | ลำต้น | สังคมศาสตร์ | มนุษยศาสตร์ | คนอื่น |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| CHATGPT | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-V1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-Instant-V1.0 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| Bloomz-7b | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| chatglm-6b | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| ziya-llama-13b-pretrain | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| Moss-Moon-003-base (16B) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| LLAMA-7B-HF | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7b | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| Tigerbot-7b-base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7b * | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-llama-V2-Pretrain (7B) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| Bloom-7b | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7b | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
Gaokao เป็นชุดข้อมูลที่ใช้คำถามการสอบเข้าวิทยาลัยจีนเป็นชุดข้อมูลเพื่อประเมินความสามารถของแบบจำลองภาษาขนาดใหญ่เพื่อประเมินความสามารถทางภาษาและความสามารถในการใช้เหตุผลเชิงตรรกะของแบบจำลอง เราเก็บคำถามทางเลือกเดียวเท่านั้นและทำการทดสอบ 5-shot แบบครบวงจรในทุกรุ่นหลังจากการแบ่งแบบสุ่ม
นี่คือผลลัพธ์ของการทดสอบ
| แบบอย่าง | เฉลี่ย |
|---|---|
| Bloomz-7b | 28.72 |
| LLAMA-7B | 27.81 |
| Bloom-7b | 26.96 |
| Tigerbot-7b-base | 25.94 |
| Falcon-7b | 23.98 |
| ziya-llama-13b-pretrain | 23.17 |
| chatglm-6b | 21.41 |
| Open-Llama-V2-Pretrain | 21.41 |
| Aquila-7b * | 24.39 |
| Baichuan-7b | 36.24 |
Agieval มีจุดมุ่งหมายเพื่อประเมินความสามารถทั่วไปของแบบจำลองในงานด้านความรู้ความเข้าใจและการแก้ปัญหา เราเก็บไว้เพียงสี่ของพวกเขาและทำการทดสอบ 5-shot แบบครบวงจรในทุกรุ่นหลังจากการแบ่งแบบสุ่ม
| แบบอย่าง | เฉลี่ย |
|---|---|
| Bloomz-7b | 30.27 |
| LLAMA-7B | 28.17 |
| ziya-llama-13b-pretrain | 27.64 |
| Falcon-7b | 27.18 |
| Bloom-7b | 26.55 |
| Aquila-7b * | 25.58 |
| Tigerbot-7b-base | 25.19 |
| chatglm-6b | 23.49 |
| Open-Llama-V2-Pretrain | 23.49 |
| Baichuan-7b | 34.44 |
* โมเดล Aquila มาจากเว็บไซต์ทางการของ Zhiyuan (https://model.baai.ac.cn/model-detail/100098) สำหรับการอ้างอิงเท่านั้น
นอกจากภาษาจีน Baichuan-7b ยังทดสอบผลของแบบจำลองในภาษาอังกฤษ เราใช้รูปแบบการประเมินโอเพนซอร์สและผลลัพธ์ 5-shot สุดท้ายมีดังนี้:
| แบบอย่าง | มนุษยศาสตร์ | สังคมศาสตร์ | ลำต้น | อื่น | เฉลี่ย |
|---|---|---|---|---|---|
| chatglm-6b 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| Bloomz-7b 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| MPT-7B 1 | - | - | - | - | 35.6 |
| LLAMA-7B 2 | 34.0 | 38.3 | 30.5 | 38.1 | 35.1 |
| Falcon-7b 1 | - | - | - | - | 35.0 |
| Moss-Moon-003-sft (16B) 0 | 30.5 | 33.8 | 29.3 | 34.4 | 31.9 |
| Bloom-7b 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25.5 |
| Moss-Moon-003-base (16B) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7b 0 | 38.4 | 48.9 | 35.6 | 48.1 | 42.3 |
0: ปรากฏขึ้นอีกครั้ง
1: https://huggingface.co/spaces/huggingfaceh4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7Bตัวบ่งชี้รายละเอียดเฉพาะของงาน 57 รายการใน MMLU มีดังนี้:
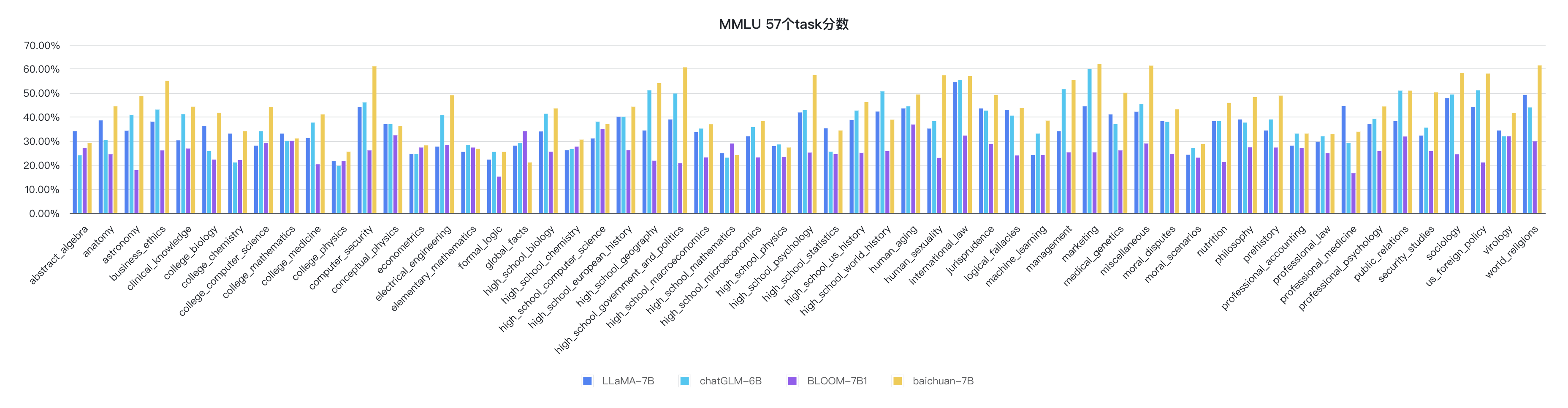
ตัวชี้วัดของแต่ละวินัยมีดังนี้:
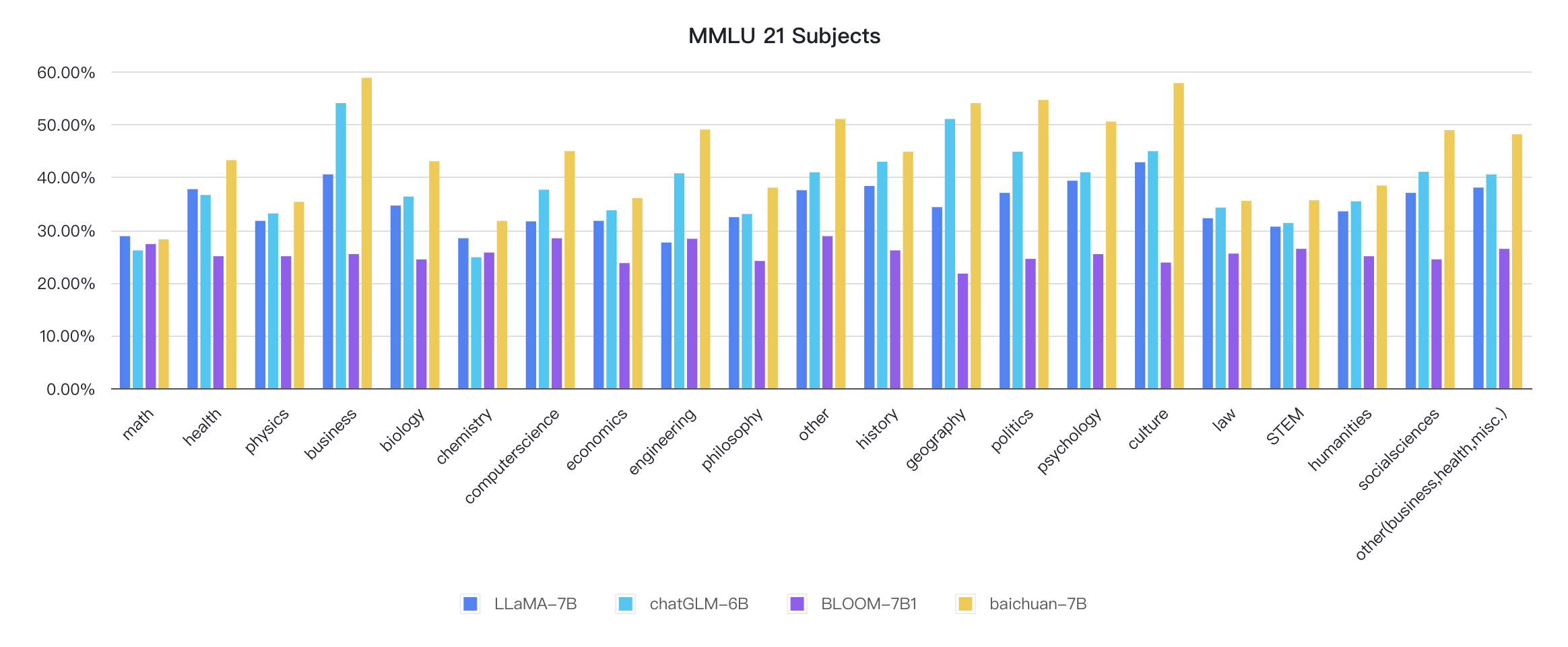
รหัสเหตุผลอยู่ในห้องสมุด HuggingFace อย่างเป็นทางการแล้ว
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))กระบวนการโดยรวมมีดังนี้:
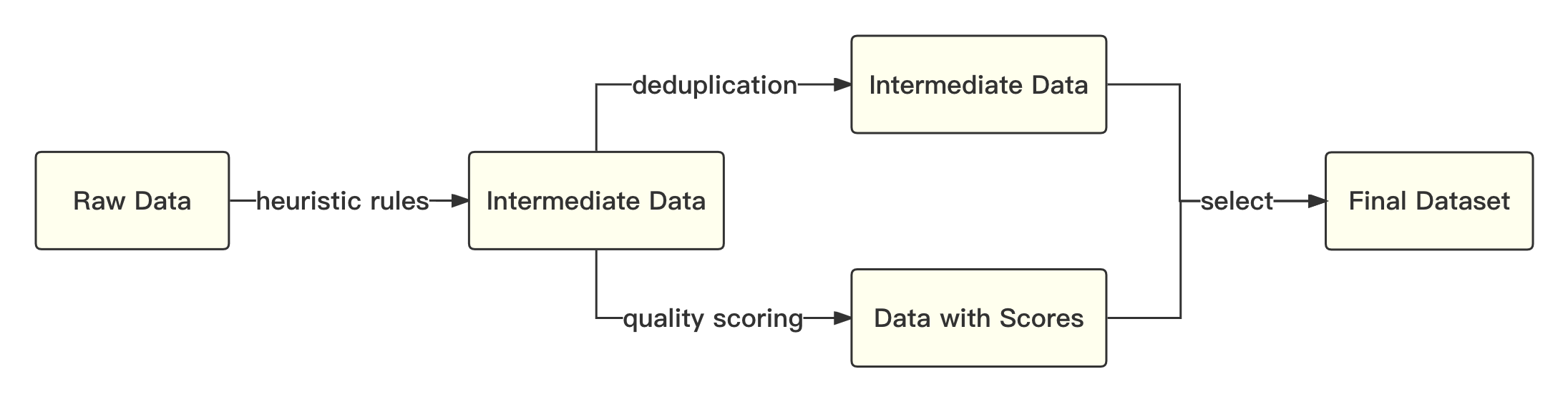
เราอ้างถึงโซลูชันทางวิชาการที่จะใช้การเข้ารหัสไบต์คู่ (BPE) ในประโยคพิเศษเป็นอัลกอริทึมการแบ่งส่วนคำและดำเนินการปรับให้เหมาะสมต่อไปนี้:
| แบบอย่าง | Baichuan-7b | ลาม่า | เหยี่ยว | MPT-7B | chatglm | Moss-Moon-003 |
|---|---|---|---|---|---|---|
| อัตราการบีบอัด | 0.737 | 1.312 | 1.049 | 1.206 | 0.631 | 0.659 |
| ขนาดคำศัพท์ | 64,000 | 32,000 | 65,024 | 50,254 | 130,344 | 106,029 |
โมเดลโดยรวมขึ้นอยู่กับโครงสร้างหม้อแปลงมาตรฐานและเราใช้การออกแบบโมเดลเดียวกับ Llama
เราทำการปรับเปลี่ยนมากมายเกี่ยวกับกรอบ Llama ดั้งเดิมเพื่อปรับปรุงปริมาณงานในระหว่างการฝึกอบรมรวมถึง:
จากเทคโนโลยีการเพิ่มประสิทธิภาพข้างต้นเราได้รับปริมาณงานของ 7B รุ่น 182 TFLOPS บนการ์ดกราฟิก Kilocard A800 และอัตราการใช้พลังงานสูงสุดของ GPU สูงถึง 58.3%
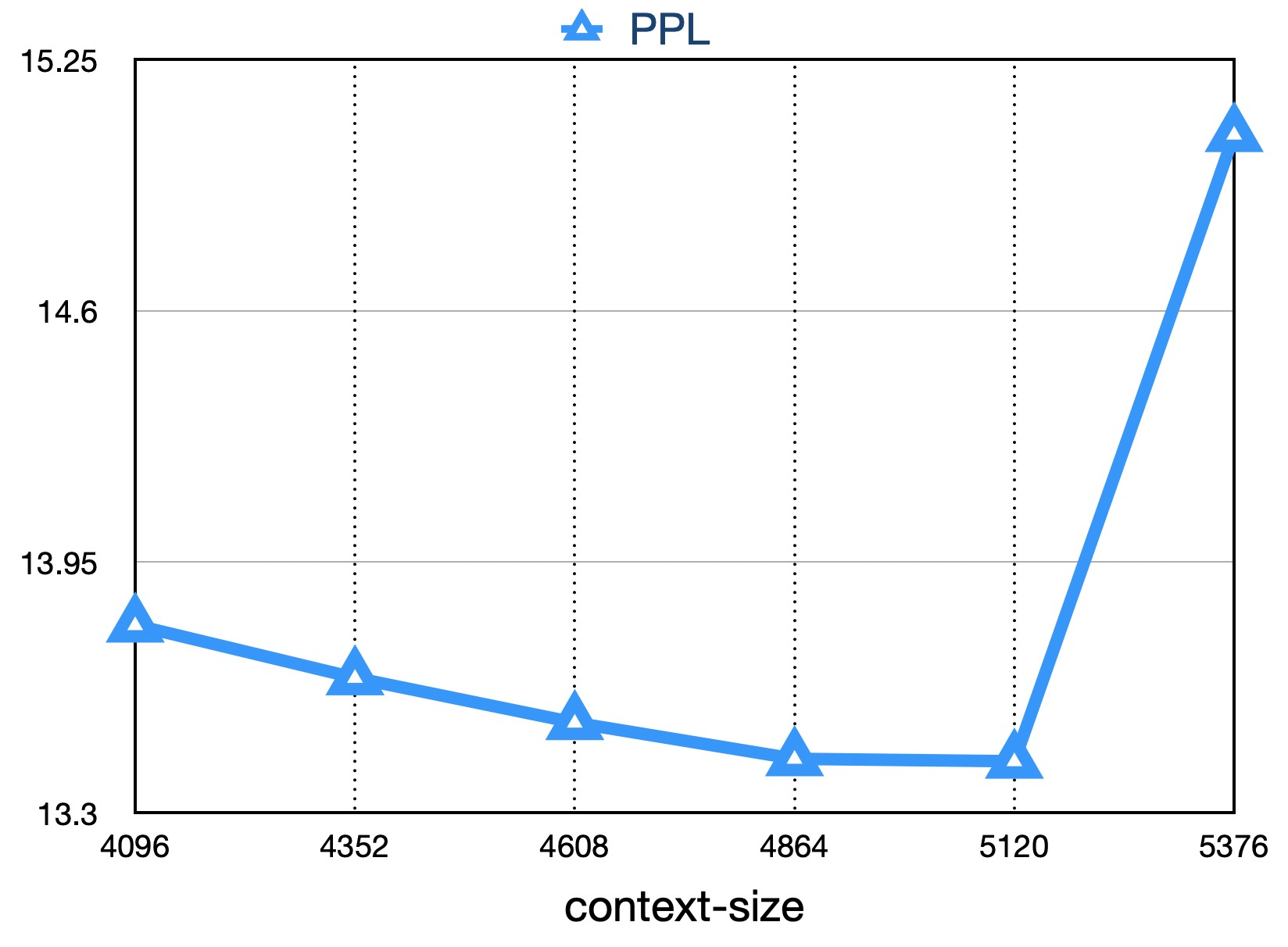
การสูญเสียครั้งสุดท้ายดังแสดงด้านล่าง:
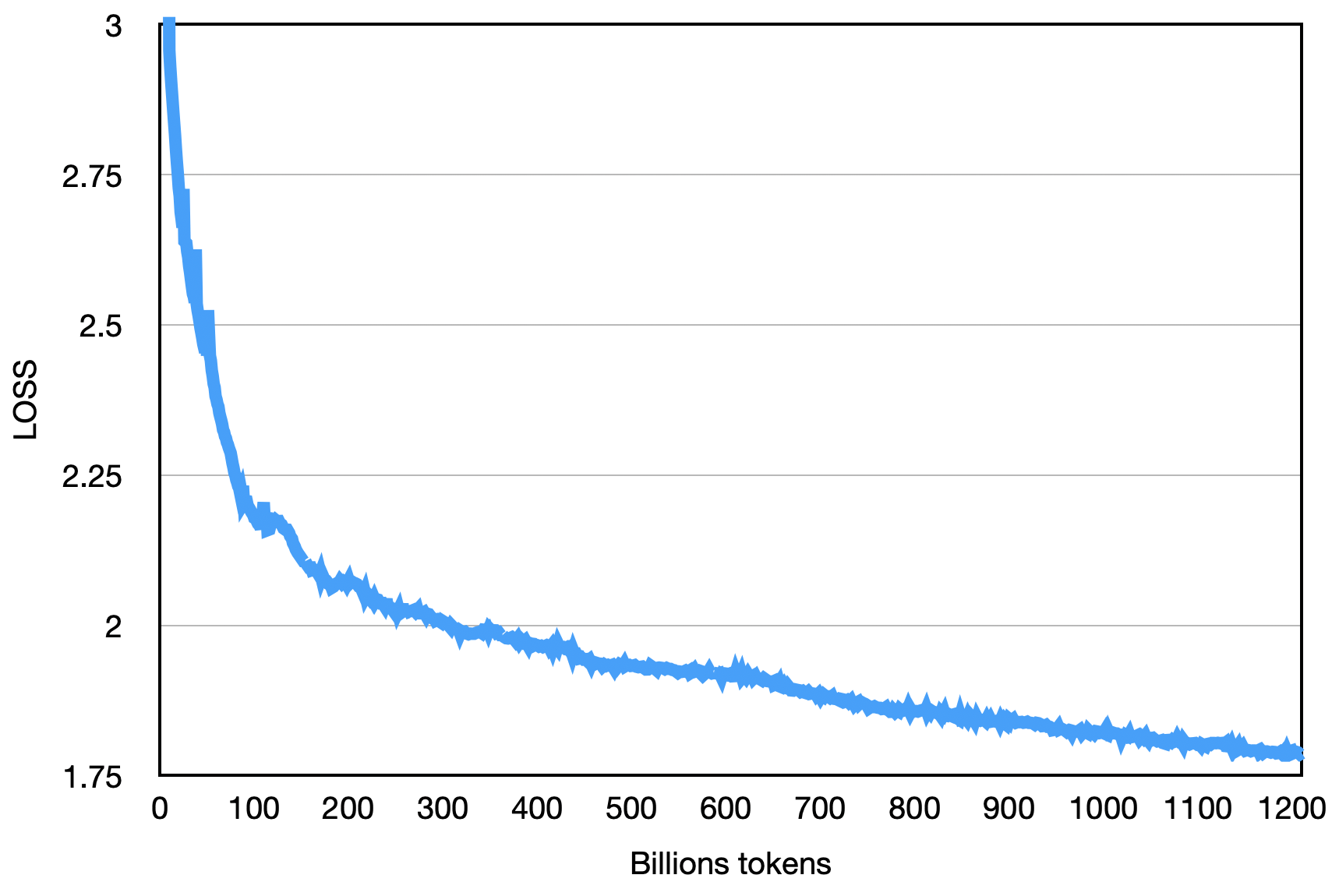
pip install -r requirements.txt ผู้ใช้แบ่งคลังข้อมูลการฝึกอบรมอย่างสม่ำเสมอเป็นไฟล์ข้อความ UTF-8 หลายไฟล์ตามทวีคูณของจำนวนอันดับทั้งหมดและวางไว้ในไดเรกทอรีคอร์ปัส (ค่าเริ่มต้นคือ data_dir ) กระบวนการจัดอันดับแต่ละครั้งจะอ่านไฟล์ที่แตกต่างกันในไดเรกทอรีคอร์ปัสและหลังจากทั้งหมดโหลดลงในหน่วยความจำมันจะเริ่มกระบวนการฝึกอบรมที่ตามมา ข้างต้นเป็นกระบวนการสาธิตที่ง่ายขึ้น
ดาวน์โหลดไฟล์ Tokenizer Model Tokenizer.model และวางไว้ในไดเรกทอรีโครงการ
รหัสสาธิตนี้ได้รับการฝึกฝนโดยใช้เฟรมเวิร์ก DeepSpeed ผู้ใช้จำเป็นต้องแก้ไข config/hostfile ตามสถานการณ์คลัสเตอร์ สำหรับรายละเอียดโปรดดูคำแนะนำอย่างเป็นทางการของ Deepspeed
scripts / train . shการใช้ซอร์สโค้ดที่เก็บนี้ขึ้นอยู่กับข้อตกลงใบอนุญาตโอเพ่นซอร์ส Apache 2.0
Baichuan-7b มีวางจำหน่ายทั่วไป หากโมเดล Baichuan-7B หรืออนุพันธ์ถูกใช้เพื่อวัตถุประสงค์ทางการค้าโปรดติดต่อผู้ออกใบอนุญาตดังต่อไปนี้เพื่อลงทะเบียนและสมัครเป็นลายลักษณ์อักษรจากผู้ออกใบอนุญาต: อีเมลติดต่อ: [email protected]


