Baichuan 7B
1.0.0
? Hugging Face • ? ModelScope • WeChat
Chinese | English
Baichuan-7B is an open source commercially available large-scale pre-trained language model developed by Baichuan Intelligent. Based on the Transformer structure, the 7 billion parameter model trained on approximately 1.2 trillion tokens supports Chinese and English bilingual, and the context window length is 4096. The best results in the same size are achieved on both standard Chinese and English benchmark (C-Eval/MMLU).
The C-Eval dataset is a comprehensive Chinese basic model evaluation dataset covering 52 disciplines and four levels of difficulty. We used the dev set of this dataset as the source of few-shot and performed a 5-shot test on the test set. Execute the following command by executing:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| Model 5-shot | Average | Avg(Hard) | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| ChatGPT | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-v1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-instant-v1.0 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| BLOOMZ-7B | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| ChatGLM-6B | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| Ziya-LLaMA-13B-pretrain | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| moss-moon-003-base (16B) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| LLaMA-7B-hf | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7B | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| TigerBot-7B-base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7B * | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-LLaMA-v2-pretrain (7B) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| BLOOM-7B | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7B | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
Gaokao is a data set that uses Chinese college entrance examination questions as a data set to evaluate the ability of large language models to evaluate the language ability and logical reasoning ability of the model. We only retained the single-choice questions and conducted a unified 5-shot test on all models after random division.
Here are the results of the test.
| Model | Average |
|---|---|
| BLOOMZ-7B | 28.72 |
| LLaMA-7B | 27.81 |
| BLOOM-7B | 26.96 |
| TigerBot-7B-base | 25.94 |
| Falcon-7B | 23.98 |
| Ziya-LLaMA-13B-pretrain | 23.17 |
| ChatGLM-6B | 21.41 |
| Open-LLaMA-v2-pretrain | 21.41 |
| Aquila-7B * | 24.39 |
| Baichuan-7B | 36.24 |
AGIEval aims to evaluate the general abilities of the model in cognitive and problem-solving tasks. We only retained four of them and performed a unified 5-shot test on all models after random division.
| Model | Average |
|---|---|
| BLOOMZ-7B | 30.27 |
| LLaMA-7B | 28.17 |
| Ziya-LLaMA-13B-pretrain | 27.64 |
| Falcon-7B | 27.18 |
| BLOOM-7B | 26.55 |
| Aquila-7B * | 25.58 |
| TigerBot-7B-base | 25.19 |
| ChatGLM-6B | 23.49 |
| Open-LLaMA-v2-pretrain | 23.49 |
| Baichuan-7B | 34.44 |
* The Aquila model comes from Zhiyuan's official website (https://model.baai.ac.cn/model-detail/100098) for reference only
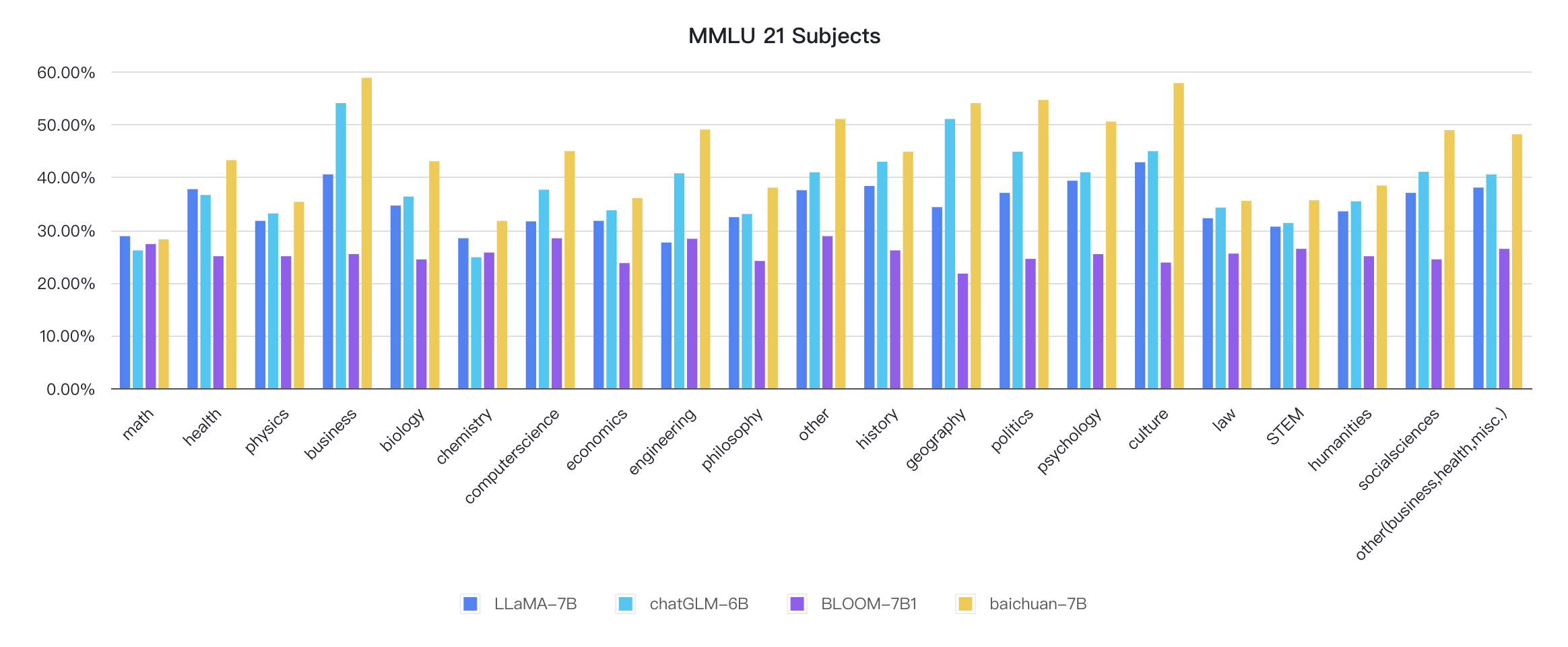
In addition to Chinese, Baichuan-7B also tested the effect of the model in English. MMLU is an English evaluation dataset containing 57 multi-select tasks, covering elementary mathematics, American history, computer science, law, etc. The difficulty covers high school level to expert level. It is currently the mainstream LLM evaluation dataset. We adopted an open source evaluation scheme, and the final 5-shot results are as follows:
| Model | Humanities | Social Sciences | STEM | Other | Average |
|---|---|---|---|---|---|
| ChatGLM-6B 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| BLOOMZ-7B 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| mpt-7B 1 | - | - | - | - | 35.6 |
| LLaMA-7B 2 | 34.0 | 38.3 | 30.5 | 38.1 | 35.1 |
| Falcon-7B 1 | - | - | - | - | 35.0 |
| moss-moon-003-sft (16B) 0 | 30.5 | 33.8 | 29.3 | 34.4 | 31.9 |
| BLOOM-7B 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25.5 |
| moss-moon-003-base (16B) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7B 0 | 38.4 | 48.9 | 35.6 | 48.1 | 42.3 |
0: Reappear
1: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7BThe specific detailed indicators of the 57 tasks on MMLU are as follows:
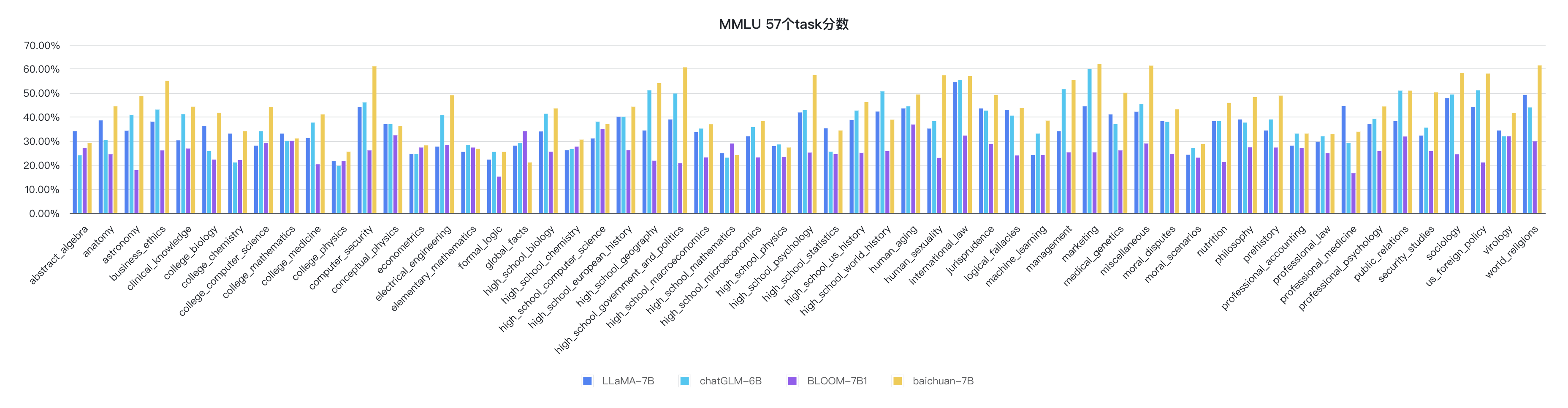
The indicators of each discipline are as follows:
The reasoning code is already in the official Huggingface library
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))The overall process is as follows:
We refer to the academic solution to use Byte-Pair Encoding (BPE) in SentencePiece as the word segmentation algorithm and perform the following optimizations:
| Model | Baichuan-7B | LLaMA | Falcon | mpt-7B | ChatGLM | moss-moon-003 |
|---|---|---|---|---|---|---|
| Compress Rate | 0.737 | 1.312 | 1.049 | 1.206 | 0.631 | 0.659 |
| Vocab Size | 64,000 | 32,000 | 65,024 | 50,254 | 130,344 | 106,029 |
The overall model is based on the standard Transformer structure, and we adopt the same model design as LLaMA.
We made many modifications to the original LLaMA framework to improve throughput during training, including:
Based on the above optimization technologies, we have achieved the throughput of 7B model 182 TFLOPS on the kilocard A800 graphics card, and the peak computing power utilization rate of GPU is as high as 58.3%.
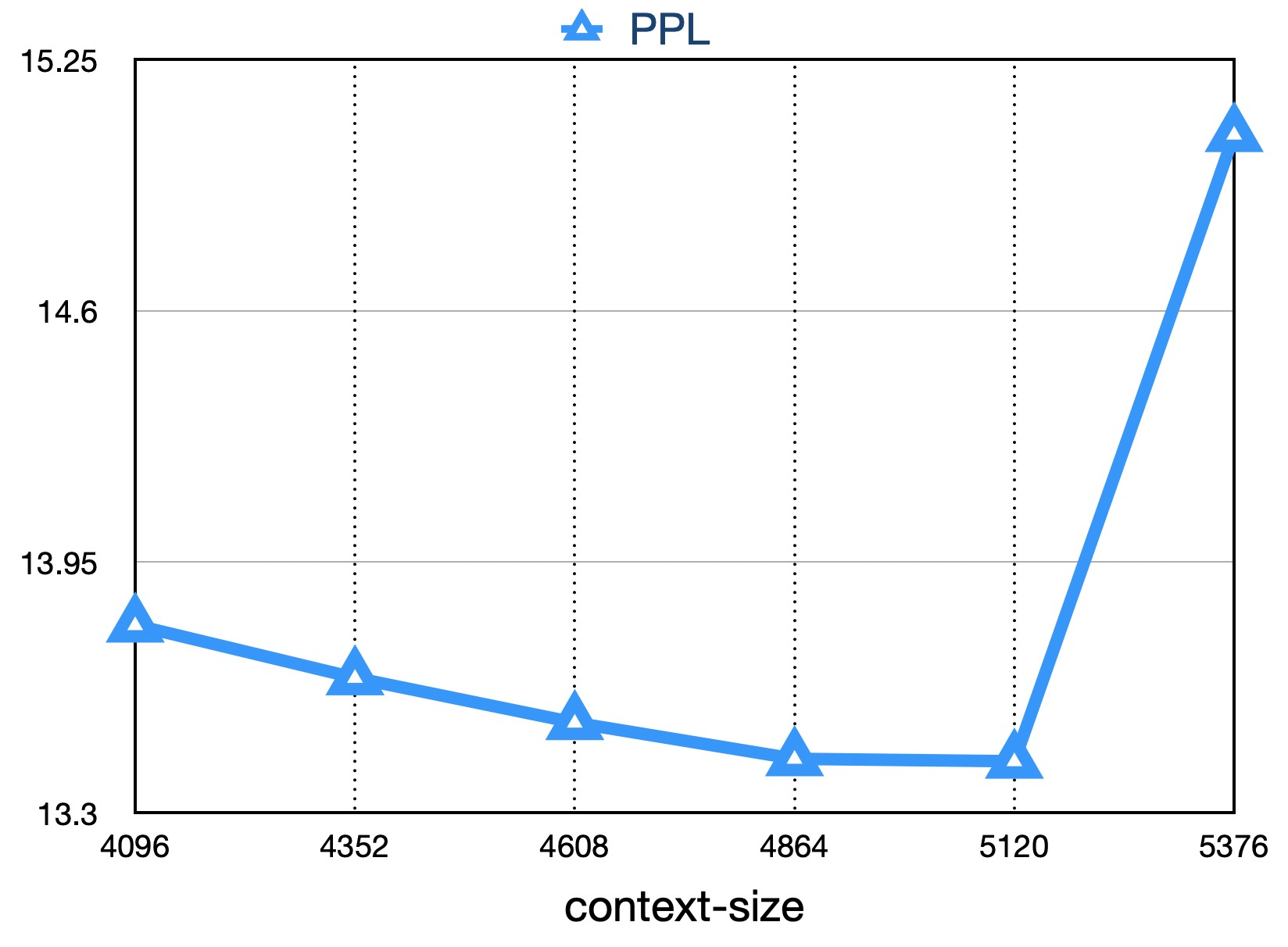
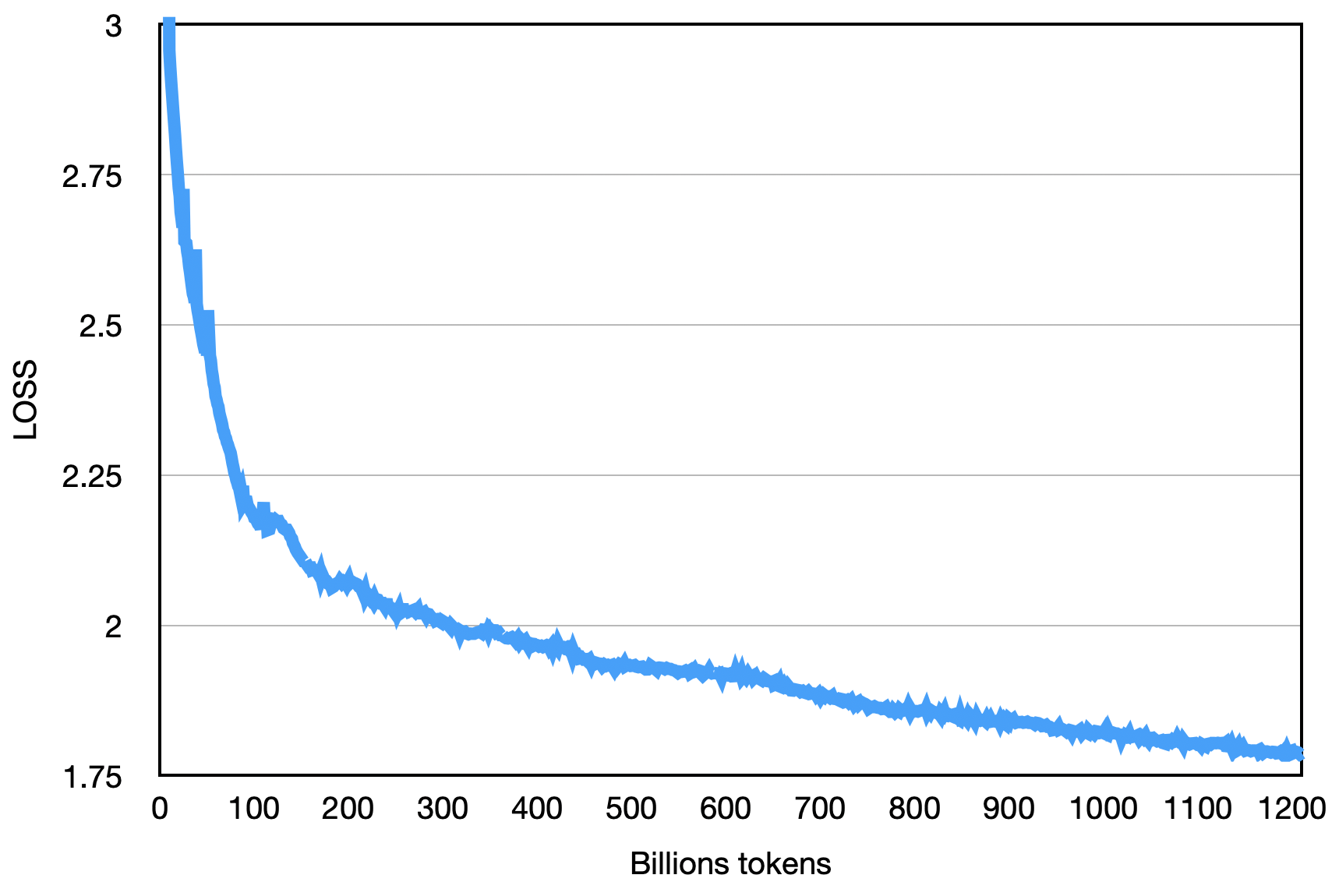
The final loss is as shown below:
pip install -r requirements.txt The user evenly divides the training corpus into multiple UTF-8 text files according to multiples of the total rank number and places it in the corpus directory (default is data_dir ). Each rank process will read different files in the corpus directory, and after all loading them into memory, it will start the subsequent training process. The above is a simplified demonstration process. It is recommended that users adjust the data production logic according to their needs during formal training tasks.
Download the tokenizer model file tokenizer.model and place it in the project directory.
This demonstration code is trained using the DeepSpeed framework. Users need to modify config/hostfile according to the cluster situation. If it is a multi-machine and multiple card, they need to modify the IP configuration of each node in ssh. For details, please refer to the official DeepSpeed instructions.
scripts / train . shThe use of this repository source code is subject to the open source license agreement Apache 2.0.
Baichuan-7B is commercially available. If the Baichuan-7B model or its derivatives are used for commercial purposes, please contact the licensor as follows to register and apply for written authorization from the licensor: Contact email: [email protected]. For the specific license agreement, please see the Baichuan-7B Model License Agreement.


