Baichuan 7B
1.0.0
?
Bahasa Inggris |
Baichuan-7b adalah open source open yang tersedia secara komersial model bahasa pra-terlatih skala besar yang dikembangkan oleh Baichuan Intelligent. Berdasarkan struktur transformator, model parameter 7 miliar yang dilatih pada sekitar 1,2 triliun token mendukung bilingual bahasa Cina dan Inggris, dan panjang jendela konteksnya adalah 4096. Hasil terbaik dalam ukuran yang sama dicapai pada tolok ukur Cina dan Inggris standar (C-eval/MMLU).
Dataset C-Eval adalah dataset evaluasi model dasar Tiongkok yang komprehensif yang mencakup 52 disiplin ilmu dan empat tingkat kesulitan. Kami menggunakan set dev dari dataset ini sebagai sumber beberapa-shot dan melakukan tes 5-shot pada set tes. Jalankan perintah berikut dengan mengeksekusi:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| Model 5-shot | Rata-rata | Rata -rata (keras) | TANGKAI | Ilmu sosial | Sastra | Yang lain |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| Chatgpt | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-V1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-Instant-V1.0 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| Bloomz-7b | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| Chatglm-6b | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| Ziya-llama-13b-pretrain | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| Moss-Moon-003-Base (16B) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| Llama-7b-hf | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7b | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| Tigerbot-7b-base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7b * | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-Llama-V2-Pretrain (7B) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| Bloom-7b | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7b | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
Gaokao adalah kumpulan data yang menggunakan pertanyaan ujian masuk perguruan tinggi Cina sebagai kumpulan data untuk mengevaluasi kemampuan model bahasa besar untuk mengevaluasi kemampuan bahasa dan kemampuan penalaran logis model. Kami hanya mempertahankan pertanyaan pilihan tunggal dan melakukan uji 5-shot terpadu pada semua model setelah divisi acak.
Berikut adalah hasil tes.
| Model | Rata-rata |
|---|---|
| Bloomz-7b | 28.72 |
| Llama-7b | 27.81 |
| Bloom-7b | 26.96 |
| Tigerbot-7b-base | 25.94 |
| Falcon-7b | 23.98 |
| Ziya-llama-13b-pretrain | 23.17 |
| Chatglm-6b | 21.41 |
| Open-llama-V2-pretrain | 21.41 |
| Aquila-7b * | 24.39 |
| Baichuan-7b | 36.24 |
Ageval bertujuan untuk mengevaluasi kemampuan umum model dalam tugas kognitif dan pemecahan masalah. Kami hanya mempertahankan empat dari mereka dan melakukan tes 5-shot terpadu pada semua model setelah divisi acak.
| Model | Rata-rata |
|---|---|
| Bloomz-7b | 30.27 |
| Llama-7b | 28.17 |
| Ziya-llama-13b-pretrain | 27.64 |
| Falcon-7b | 27.18 |
| Bloom-7b | 26.55 |
| Aquila-7b * | 25.58 |
| Tigerbot-7b-base | 25.19 |
| Chatglm-6b | 23.49 |
| Open-llama-V2-pretrain | 23.49 |
| Baichuan-7b | 34.44 |
* Model Aquila berasal dari situs web resmi Zhiyuan (https://model.baai.ac.cn/model-detail/100098) hanya untuk referensi referensi
Selain Cina, Baichuan-7b juga menguji pengaruh model dalam bahasa Inggris. Kami mengadopsi skema evaluasi sumber terbuka, dan hasil 5-shot akhir adalah sebagai berikut:
| Model | Sastra | Ilmu sosial | TANGKAI | Lainnya | Rata-rata |
|---|---|---|---|---|---|
| Chatglm-6b 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| Bloomz-7b 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| MPT-7B 1 | - | - | - | - | 35.6 |
| Llama-7b 2 | 34.0 | 38.3 | 30.5 | 38.1 | 35.1 |
| Falcon-7b 1 | - | - | - | - | 35.0 |
| Moss-Moon-003-SFT (16B) 0 | 30.5 | 33.8 | 29.3 | 34.4 | 31.9 |
| Bloom-7b 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25.5 |
| Moss-moon-003-base (16b) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7b 0 | 38.4 | 48.9 | 35.6 | 48.1 | 42.3 |
0: Airilahkan
1: https://huggingface.co/spaces/huggingfaceH4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7BIndikator rinci spesifik dari 57 tugas pada MMLU adalah sebagai berikut:
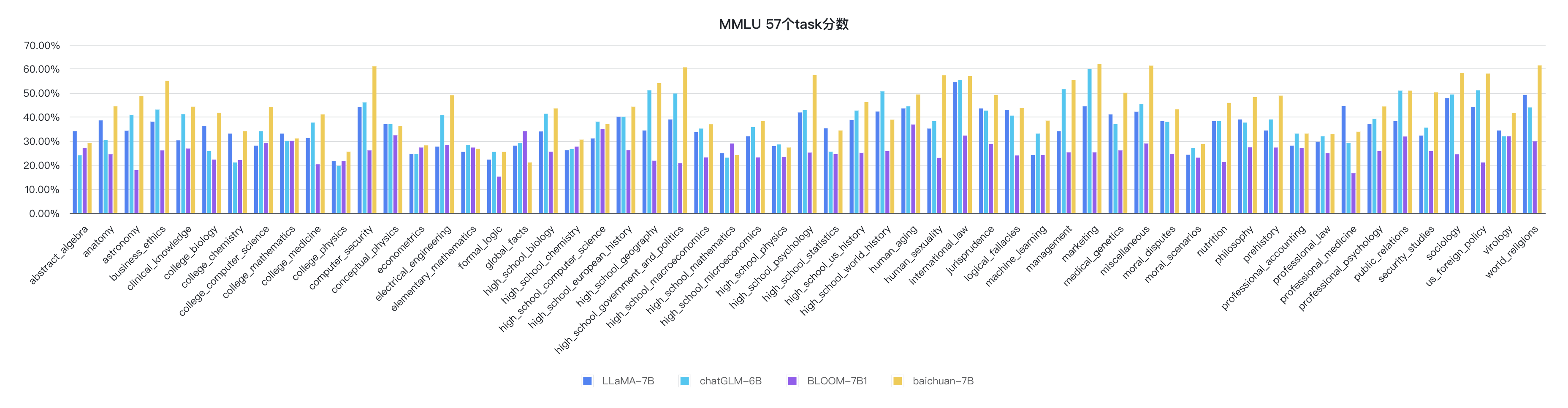
Indikator setiap disiplin adalah sebagai berikut:
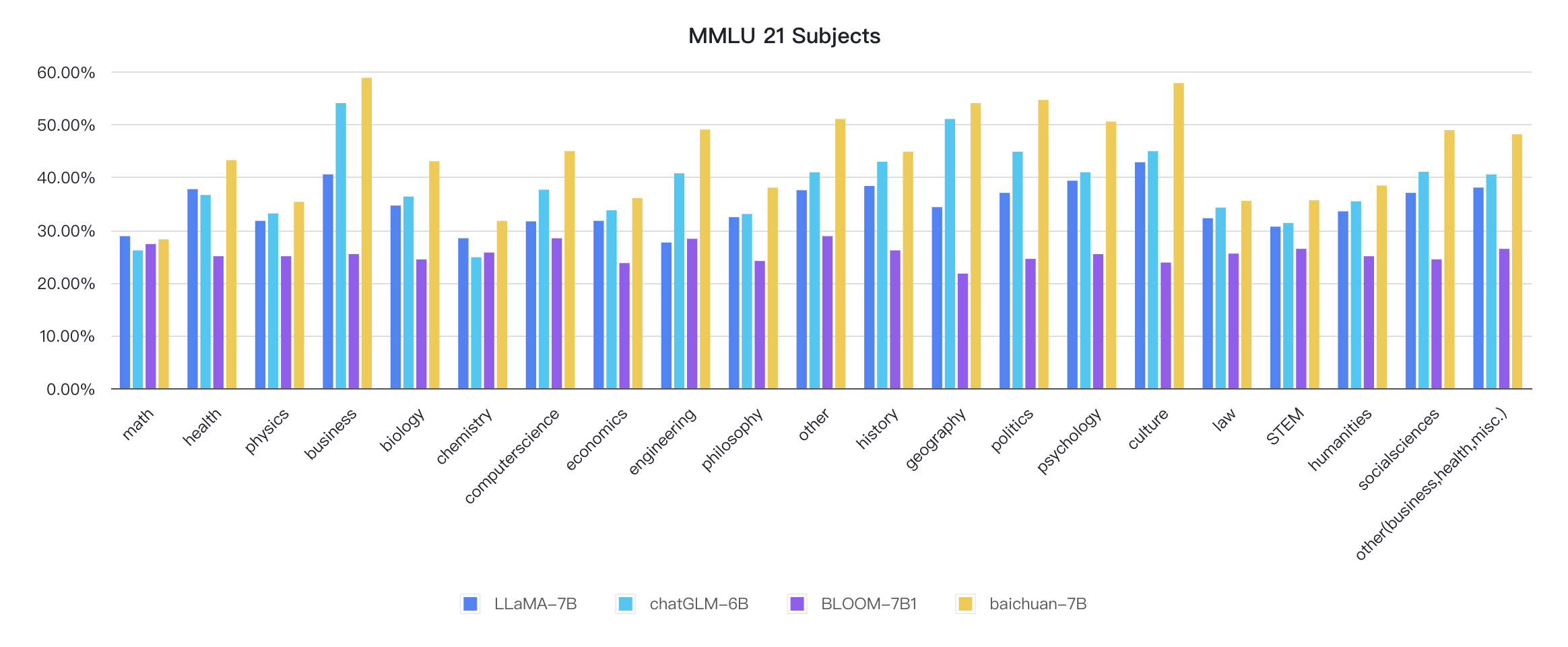
Kode alasan sudah ada di perpustakaan pelukan resmi
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Proses keseluruhannya adalah sebagai berikut:
Kami merujuk pada solusi akademik untuk menggunakan encoding-pair encoding (BPE) dalam kalimat sebagai algoritma segmentasi kata dan melakukan optimasi berikut:
| Model | Baichuan-7b | Llama | Elang | MPT-7B | Chatglm | Moss-Moon-003 |
|---|---|---|---|---|---|---|
| Laju kompres | 0.737 | 1.312 | 1.049 | 1.206 | 0.631 | 0.659 |
| Ukuran Vocab | 64.000 | 32.000 | 65.024 | 50.254 | 130.344 | 106.029 |
Model keseluruhan didasarkan pada struktur transformator standar, dan kami mengadopsi desain model yang sama dengan llama.
Kami membuat banyak modifikasi pada kerangka kerja LLAMA asli untuk meningkatkan throughput selama pelatihan, termasuk:
Berdasarkan teknologi optimasi di atas, kami telah mencapai throughput 7b model 182 TFLOPS pada kartu grafis Kilocard A800, dan tingkat pemanfaatan daya komputasi puncak GPU setinggi 58,3%.
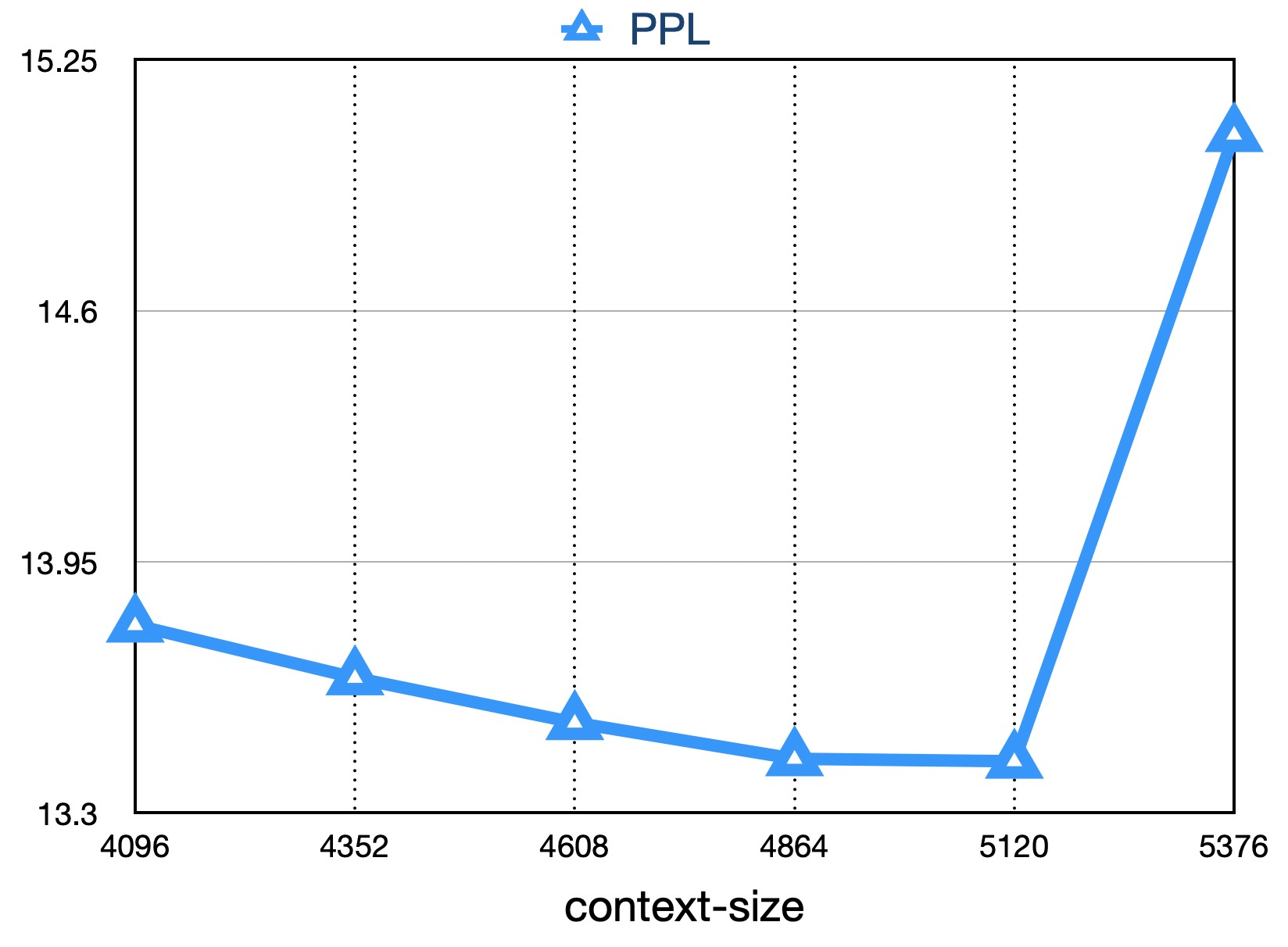
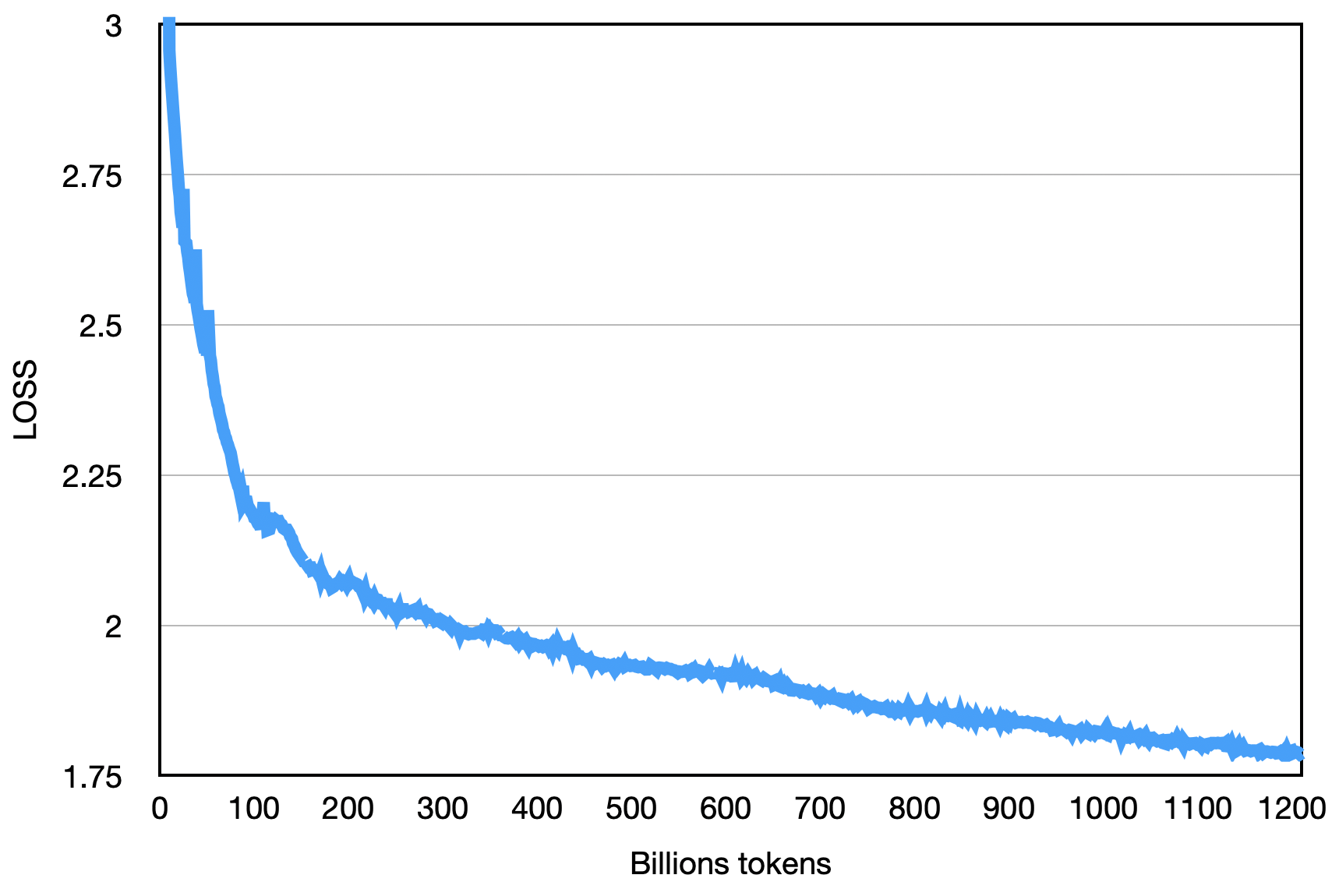
Kerugian akhir adalah seperti yang ditunjukkan di bawah ini:
pip install -r requirements.txt Pengguna secara merata membagi korpus pelatihan menjadi beberapa file teks UTF-8 sesuai dengan kelipatan dari jumlah total peringkat dan menempatkannya di direktori corpus (default adalah data_dir ). Setiap proses peringkat akan membaca file yang berbeda di direktori corpus, dan setelah semua memuatnya ke dalam memori, itu akan memulai proses pelatihan berikutnya. Di atas adalah proses demonstrasi yang disederhanakan. Disarankan agar pengguna menyesuaikan logika produksi data sesuai dengan kebutuhan mereka selama tugas pelatihan formal.
Unduh file model tokenizer Tokenizer.model dan letakkan di direktori proyek.
Kode demonstrasi ini dilatih menggunakan kerangka kerja Deepspeed. Pengguna perlu memodifikasi config/hostfile sesuai dengan situasi cluster. Untuk detailnya, silakan merujuk pada instruksi Deeppeed resmi.
scripts / train . shPenggunaan kode sumber repositori ini tunduk pada perjanjian lisensi sumber terbuka Apache 2.0.
Baichuan-7b tersedia secara komersial. Jika model Baichuan-7b atau derivatifnya digunakan untuk tujuan komersial, silakan hubungi pemberi lisensi sebagai berikut untuk mendaftar dan mengajukan permohonan otorisasi tertulis dari Lisensi: Hubungi Email: [email protected].


