Baichuan 7B
1.0.0
?
Китайский |
Baichuan-7b является коммерчески доступной крупномасштабной предварительно обученной языковой модели, разработанной Baichuan Intellent. Основываясь на структуре трансформатора, модель параметров 7 миллиардов, обученная приблизительно 1,2 триллиона токенов, поддерживает китайский и английский двуязычный, а длина окна контекста составляет 4096. Лучшие результаты в одинаковом размере достигаются как на стандартном китайском, так и на английском языке (C-Eval/MMLU).
Набор данных C-Eval представляет собой комплексный китайский набор данных базовой модели, охватывающий 52 дисциплины и четыре уровня сложности. Мы использовали набор DEV этого набора данных в качестве источника нескольких выстрелов и выполнили 5-shot в тестовом наборе. Выполнить следующую команду, выполнив:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| Модель 5-выстрел | Средний | Avg (жесткий) | КОРЕНЬ | Социальные науки | Гуманитарные науки | Другие |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54,9 | 67.1 | 77.6 | 64,5 | 67.8 |
| Чатгпт | 54.4 | 41.4 | 52,9 | 61.8 | 50,9 | 53,6 |
| Claude-V1.3 | 54.2 | 39,0 | 51.9 | 61.7 | 52,1 | 53,7 |
| Claude-Instant-V1.0 | 45,9 | 35,5 | 43.1 | 53,8 | 44.2 | 45,4 |
| Bloomz-7b | 35,7 | 25.8 | 31.3 | 43,5 | 36.6 | 35,6 |
| Чатглм-6B | 34,5 | 23.1 | 30.4 | 39,6 | 37.4 | 34,5 |
| Ziya-Llama-13b-Pretrain | 30.2 | 22.7 | 27.7 | 34.4 | 32,0 | 28.9 |
| МОСС-МУН-003-База (16B) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| Llama-7b-Hf | 27.1 | 25.9 | 27.1 | 26.8 | 27,9 | 26.3 |
| Falcon-7b | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| Tigerbot-7b-баз | 25,7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7b * | 25,5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-Llama-V2-Pretrain (7b) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| Блум-7b | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7b | 42,8 | 31.5 | 38.2 | 52,0 | 46.2 | 39,3 |
Gaokao - это набор данных, который использует вопросы вступительного экзамена в китайском колледже в качестве набора данных для оценки способности крупных языковых моделей оценивать языковую способность и способность к логическим рассуждениям модели. Мы сохранили только вопросы по одному выбору и провели единый 5-shot на всех моделях после случайного деления.
Вот результаты теста.
| Модель | Средний |
|---|---|
| Bloomz-7b | 28.72 |
| Лама-7B | 27.81 |
| Блум-7b | 26.96 |
| Tigerbot-7b-баз | 25,94 |
| Falcon-7b | 23.98 |
| Ziya-Llama-13b-Pretrain | 23.17 |
| Чатглм-6B | 21.41 |
| Open-Llama-V2-Pretrain | 21.41 |
| Aquila-7b * | 24.39 |
| Baichuan-7b | 36.24 |
Agival стремится оценить общие способности модели в когнитивных и решениях задач. Мы сохранили только четыре из них и провели единый 5-shot на всех моделях после случайного деления.
| Модель | Средний |
|---|---|
| Bloomz-7b | 30.27 |
| Лама-7B | 28.17 |
| Ziya-Llama-13b-Pretrain | 27.64 |
| Falcon-7b | 27.18 |
| Блум-7b | 26.55 |
| Aquila-7b * | 25.58 |
| Tigerbot-7b-баз | 25.19 |
| Чатглм-6B | 23.49 |
| Open-Llama-V2-Pretrain | 23.49 |
| Baichuan-7b | 34.44 |
* Модель Aquila поступает с официального веб-сайта Zhiyuan (https://model.baai.ac.cn/model-detail/100098) только для справки.
В дополнение к китайцам, Baichuan-7B также проверил эффект модели на английском языке. Мы приняли схему оценки с открытым исходным кодом, и окончательные результаты 5-shot следующие:
| Модель | Гуманитарные науки | Социальные науки | КОРЕНЬ | Другой | Средний |
|---|---|---|---|---|---|
| Chatglm-6b 0 | 35,4 | 41.0 | 31.3 | 40,5 | 36.9 |
| Bloomz-7b 0 | 31.3 | 42.1 | 34.4 | 39,0 | 36.1 |
| MPT-7B 1 | - | - | - | - | 35,6 |
| Лама-7b 2 | 34.0 | 38.3 | 30,5 | 38.1 | 35,1 |
| Сокол-7B 1 | - | - | - | - | 35,0 |
| Moss-Moon-003-SFT (16b) 0 | 30,5 | 33,8 | 29.3 | 34.4 | 31.9 |
| Bloom-7b 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25,5 |
| Moss-Moon-003-баз (16b) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7b 0 | 38.4 | 48.9 | 35,6 | 48.1 | 42.3 |
0: Повторно
1: https://huggingface.co/spaces/huggingfaceh4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-ersustanding-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7BКонкретные подробные показатели 57 задач на MMLU следующие:
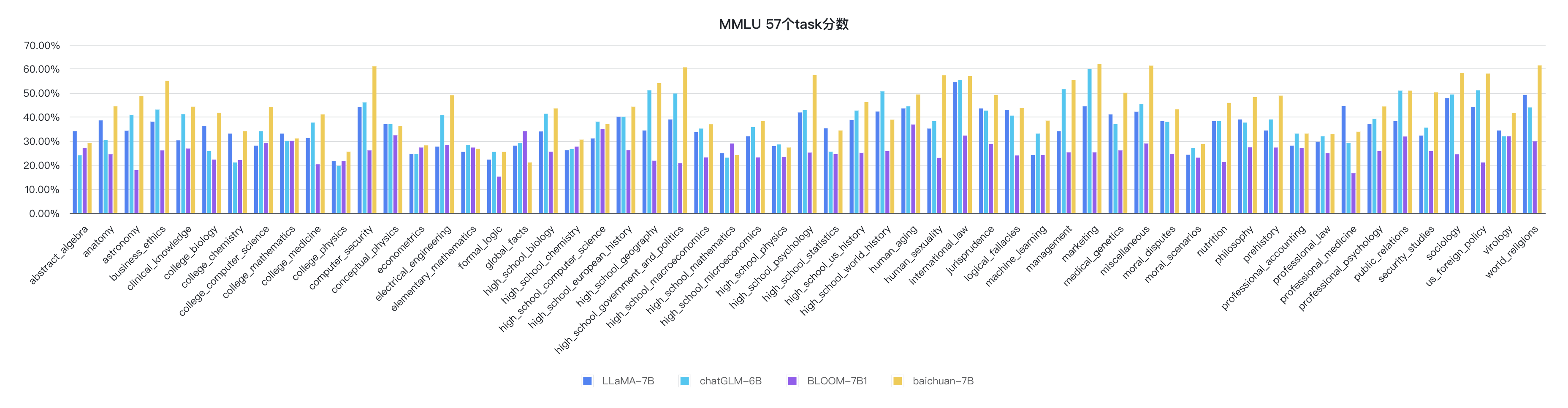
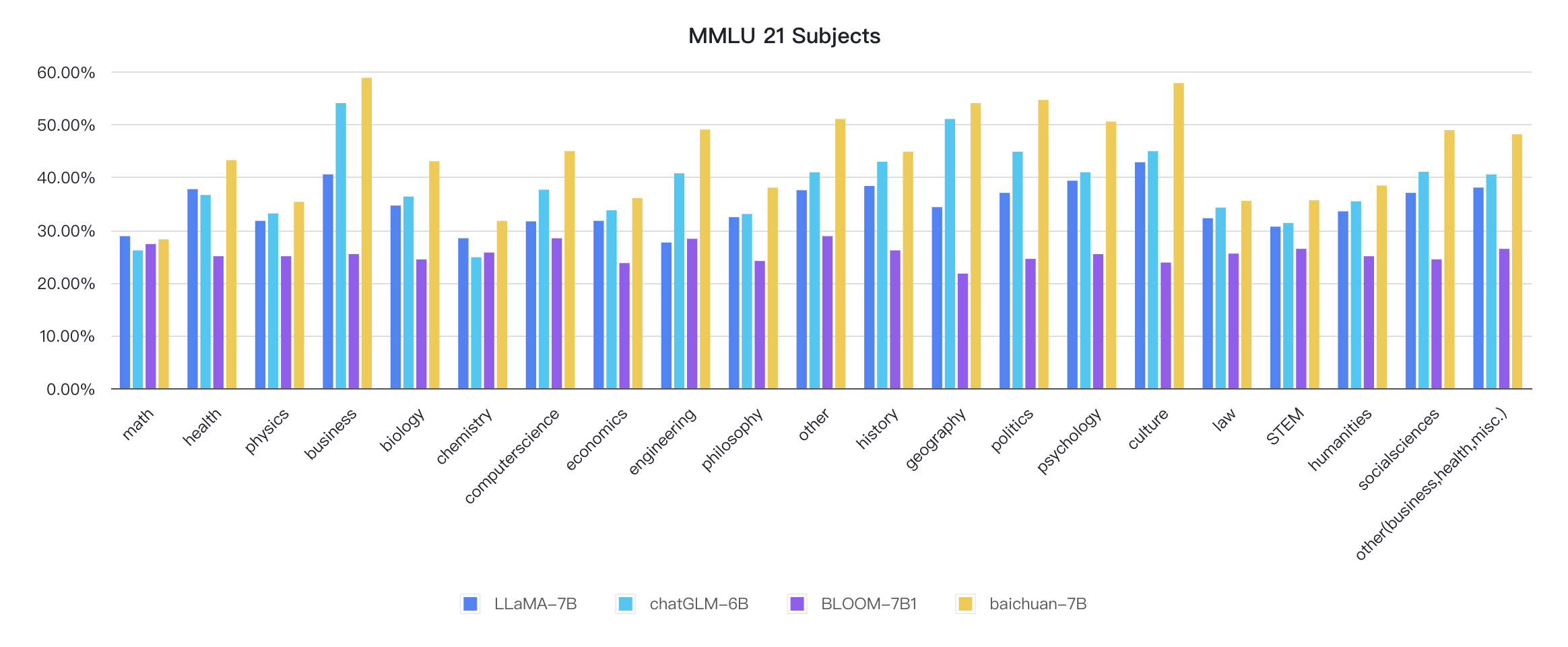
Индикаторы каждой дисциплины следующие:
Код рассуждения уже находится в официальной библиотеке Huggingfice
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Общий процесс заключается в следующем:
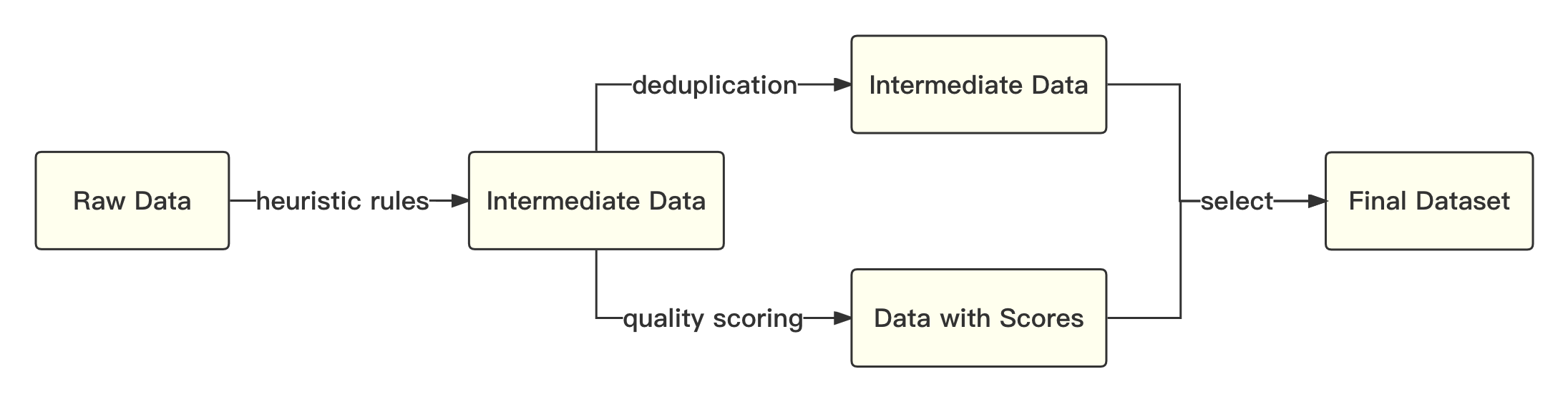
Мы называем академическое решение для использования кодировки байтовой пары (BPE) в предложении в качестве алгоритма сегментации слова и выполняем следующие оптимизации:
| Модель | Baichuan-7b | Лама | Сокол | MPT-7B | Чатглм | Мосс-Мун-003 |
|---|---|---|---|---|---|---|
| Скорость сжатия | 0,737 | 1.312 | 1.049 | 1.206 | 0,631 | 0,659 |
| Размер слока | 64 000 | 32 000 | 65,024 | 50,254 | 130,344 | 106 029 |
Общая модель основана на стандартной структуре трансформатора, и мы принимаем тот же дизайн модели, что и Llama.
Мы внесли много модификаций в оригинальной структуре Llama для повышения пропускной способности во время обучения, в том числе:
Основываясь на вышеуказанных технологиях оптимизации, мы достигли пропускной способности 7B Model 182 TFLOPS на графической карте Kilocard A800, а пиковая скорость использования вычислительной мощности GPU достигает 58,3%.
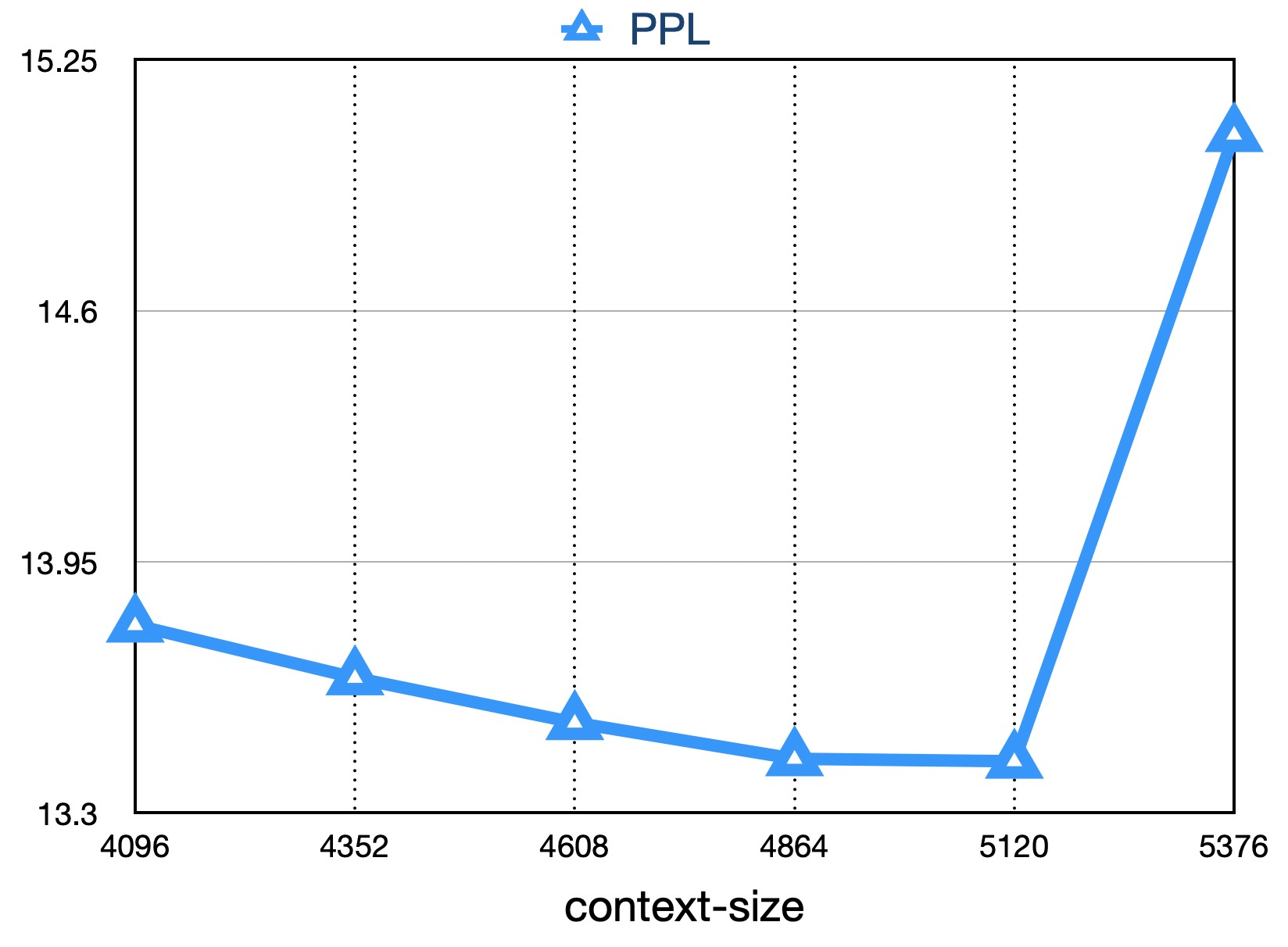
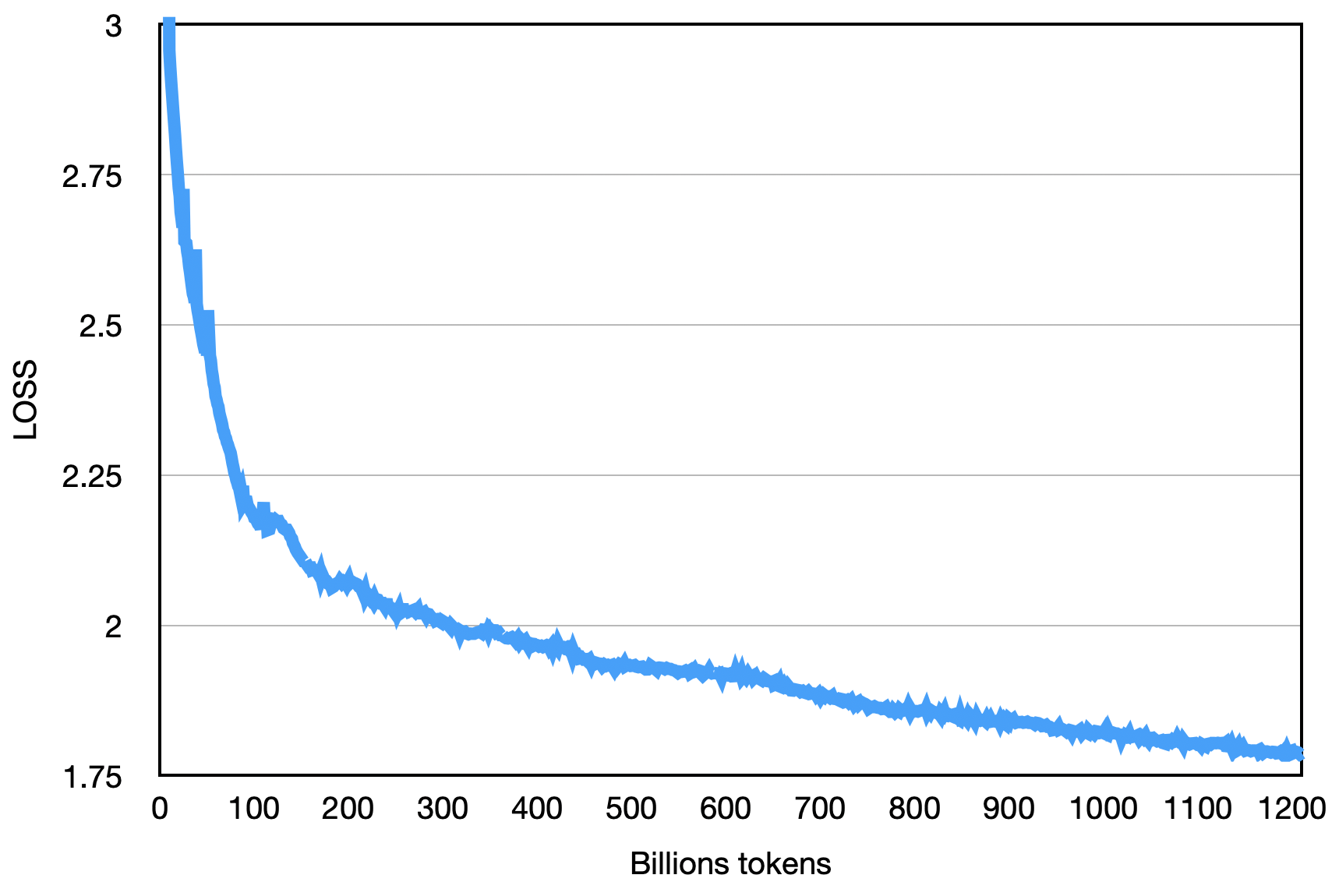
Окончательная потеря, как показано ниже:
pip install -r requirements.txt Пользователь равномерно делит учебный корпус на несколько текстовых файлов UTF-8 в соответствии с множеством общего числа ранга и помещает его в каталог корпуса (по умолчанию data_dir ). Каждый процесс ранга будет читать разные файлы в каталоге корпуса, и после того, как все загружают их в память, он начнет последующий процесс обучения. Приведенное выше - это упрощенный процесс демонстрации.
Загрузите Tokenizer Model File Tokenizer.Model и поместите его в каталог проектов.
Этот демонстрационный код обучается с использованием структуры DeepSpeed. Пользователи должны изменить config/hostfile в соответствии с ситуацией кластера. Для получения подробной информации, пожалуйста, обратитесь к официальным инструкциям DeepSpeed.
scripts / train . shИспользование этого исходного кода репозитория подлежит лицензионному соглашению с открытым исходным кодом Apache 2.0.
Baichuan-7b является коммерчески доступным. Если модель Baichuan-7B или ее производные используются для коммерческих целей, пожалуйста, свяжитесь с лицензиаром следующим образом, чтобы зарегистрироваться и подать заявку на письменное разрешение от лицензиата: Контактная электронная почта: [email protected].


