Baichuan 7B
1.0.0
Modelscope?
Chinês |
O Baichuan-7b é um modelo de idioma pré-treinado em larga escala disponível comercialmente disponível em larga escala desenvolvido pela Baichuan Intelligent. Com base na estrutura do transformador, o modelo de 7 bilhões de parâmetros treinado em aproximadamente 1,2 trilhão de tokens suporta bilíngüe chinês e inglês, e o comprimento da janela de contexto é 4096. Os melhores resultados do mesmo tamanho são alcançados no benchmark chinês e inglês padrão (C-EVAL/MMLU).
O conjunto de dados C-EVAL é um conjunto de dados abrangente de avaliação de modelo básico chinês que abrange 52 disciplinas e quatro níveis de dificuldade. Utilizamos o conjunto de dev desse conjunto de dados como fonte de poucos anos e realizamos um teste 5-shot no conjunto de testes. Execute o seguinte comando executando:
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| Modelo 5-shot | Média | AVG (difícil) | TRONCO | Ciências sociais | Humanidades | Outros |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| Chatgpt | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-V1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-Instant-V1.0 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| Bloomz-7b | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| Chatglm-6b | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| Ziya-llama-13b-pré-trail | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| Moss-Moon-003-Base (16b) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| LLAMA-7B-HF | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7b | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| Tigerbot-7b-Base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7b * | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-llama-V2-Preserin (7b) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| Bloom-7b | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7b | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
Gaokao é um conjunto de dados que usa questões de exame de entrada da faculdade chinesa como um conjunto de dados para avaliar a capacidade de grandes modelos de idiomas de avaliar a capacidade de linguagem e a capacidade de raciocínio lógico do modelo. Mantemos apenas as perguntas de escolha única e realizamos um teste 5-shot unificado em todos os modelos após a divisão aleatória.
Aqui estão os resultados do teste.
| Modelo | Média |
|---|---|
| Bloomz-7b | 28.72 |
| Llama-7b | 27.81 |
| Bloom-7b | 26.96 |
| Tigerbot-7b-Base | 25.94 |
| Falcon-7b | 23.98 |
| Ziya-llama-13b-pré-trail | 23.17 |
| Chatglm-6b | 21.41 |
| Open-llama-V2-Prain | 21.41 |
| Aquila-7b * | 24.39 |
| Baichuan-7b | 36.24 |
A Agieval tem como objetivo avaliar as habilidades gerais do modelo em tarefas cognitivas e de solução de problemas. Mantemos apenas quatro deles e realizamos um teste unificado 5-shot em todos os modelos após a divisão aleatória.
| Modelo | Média |
|---|---|
| Bloomz-7b | 30.27 |
| Llama-7b | 28.17 |
| Ziya-llama-13b-pré-trail | 27.64 |
| Falcon-7b | 27.18 |
| Bloom-7b | 26.55 |
| Aquila-7b * | 25.58 |
| Tigerbot-7b-Base | 25.19 |
| Chatglm-6b | 23.49 |
| Open-llama-V2-Prain | 23.49 |
| Baichuan-7b | 34.44 |
* O modelo Aquila vem do site oficial de Zhiyuan (https://model.baai.ac.cn/model-detail/100098) apenas para referência
Além do chinês, o Baichuan-7b também testou o efeito do modelo em inglês. Adotamos um esquema de avaliação de código aberto e os resultados finais 5-shot são os seguintes:
| Modelo | Humanidades | Ciências sociais | TRONCO | Outro | Média |
|---|---|---|---|---|---|
| Chatglm-6b 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| Bloomz-7b 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| MPT-7B 1 | - | - | - | - | 35.6 |
| LLAMA-7B 2 | 34.0 | 38.3 | 30.5 | 38.1 | 35.1 |
| Falcon-7b 1 | - | - | - | - | 35.0 |
| Moss-Moon-003-SFT (16b) 0 | 30.5 | 33.8 | 29.3 | 34.4 | 31.9 |
| Bloom-7b 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25.5 |
| Moss-moon-003-Base (16b) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7b 0 | 38.4 | 48.9 | 35.6 | 48.1 | 42.3 |
0: reapareça
1: https://huggingface.co/spaces/huggingfaceh4/open_llm_leaderboard
2: https://paperswithcode.com/sota/multi-task-language-undestanding-on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7BOs indicadores detalhados específicos das 57 tarefas no MMLU são os seguintes:
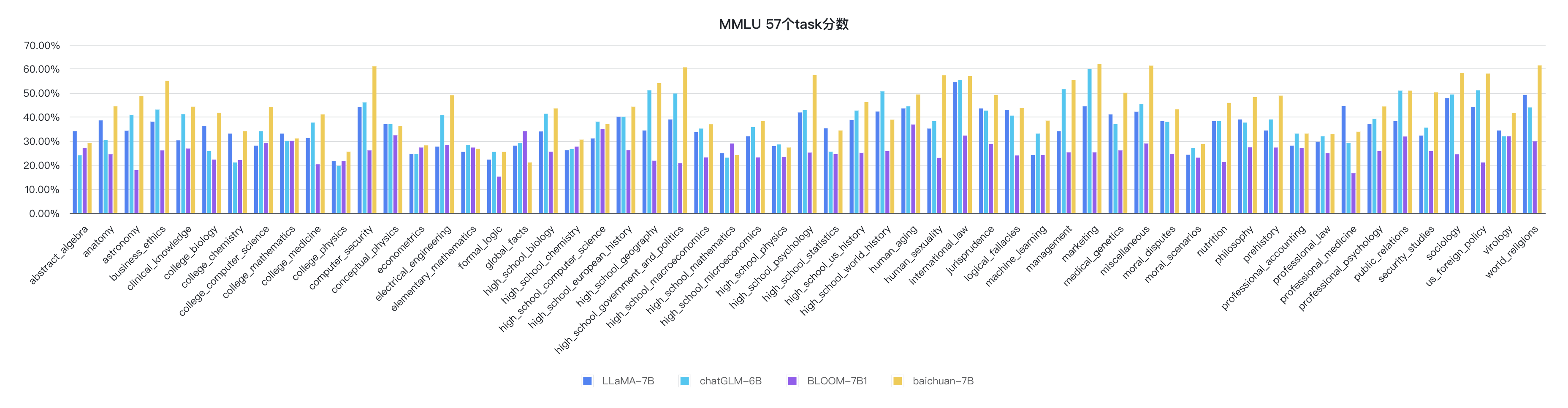
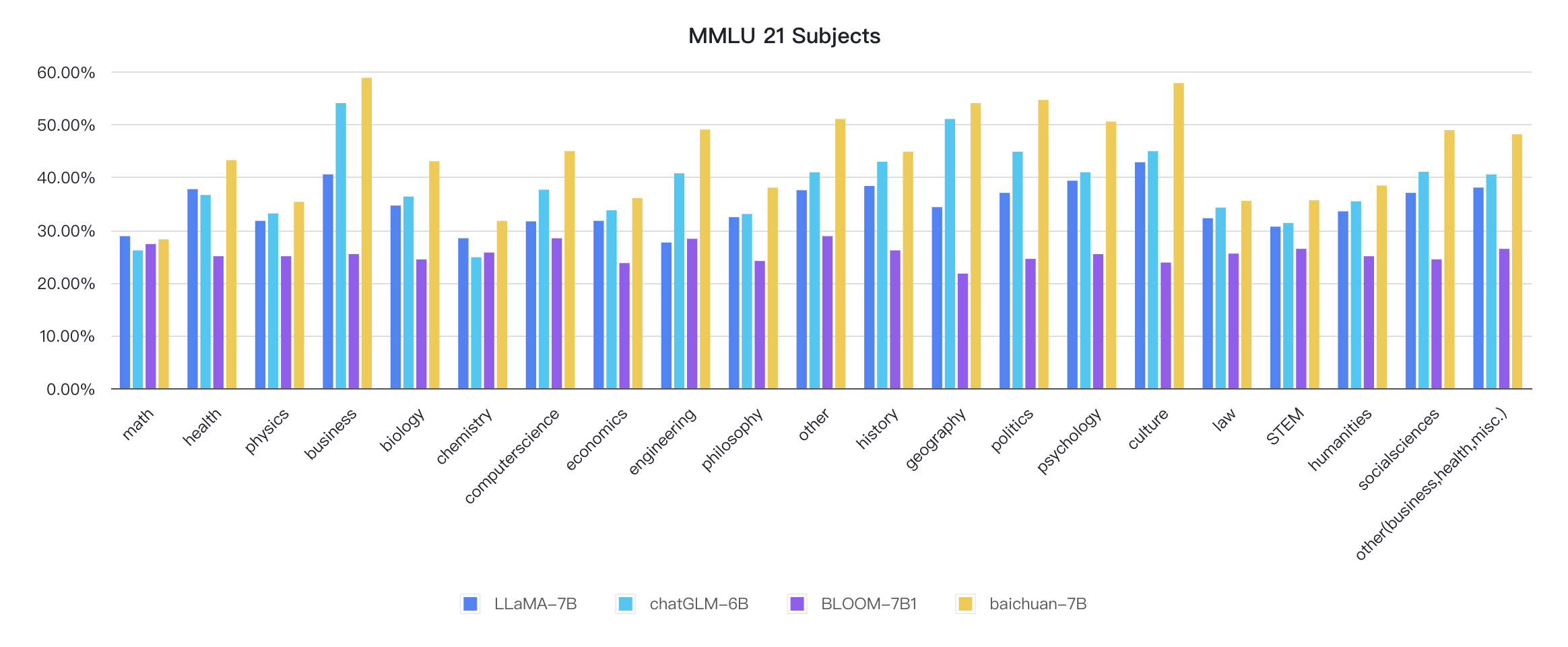
Os indicadores de cada disciplina são os seguintes:
O código de raciocínio já está na biblioteca oficial do Huggingface
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
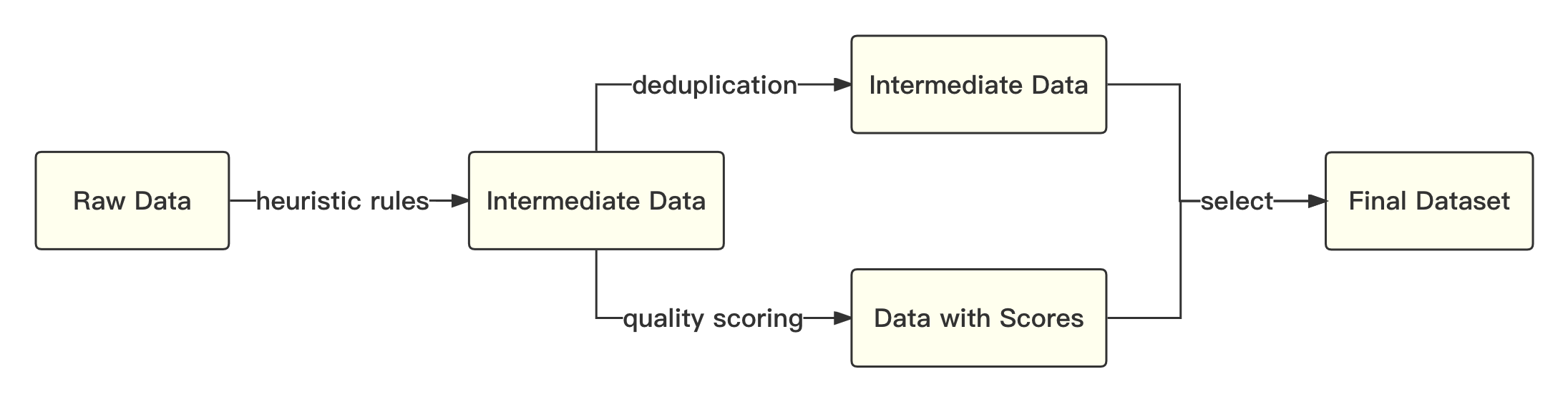
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))O processo geral é o seguinte:
Nós nos referimos à solução acadêmica para usar a codificação de pares de bytes (BPE) na peça de sentença como o algoritmo de segmentação de palavras e executamos as seguintes otimizações:
| Modelo | Baichuan-7b | Lhama | Falcão | MPT-7B | Chatglm | Moss-Moon-003 |
|---|---|---|---|---|---|---|
| Taxa de compactação | 0,737 | 1.312 | 1.049 | 1.206 | 0,631 | 0,659 |
| Tamanho do vocabulário | 64.000 | 32.000 | 65.024 | 50.254 | 130.344 | 106.029 |
O modelo geral é baseado na estrutura padrão do transformador e adotamos o mesmo design de modelo que a llama.
Fizemos muitas modificações na estrutura original da LLAMA para melhorar a taxa de transferência durante o treinamento, incluindo:
Com base nas tecnologias de otimização acima, alcançamos a taxa de transferência do 7B Modelo 182 TFLOPS na placa gráfica Kilocard A800, e a taxa de utilização de potência de computação de pico da GPU é tão alta quanto 58,3%.
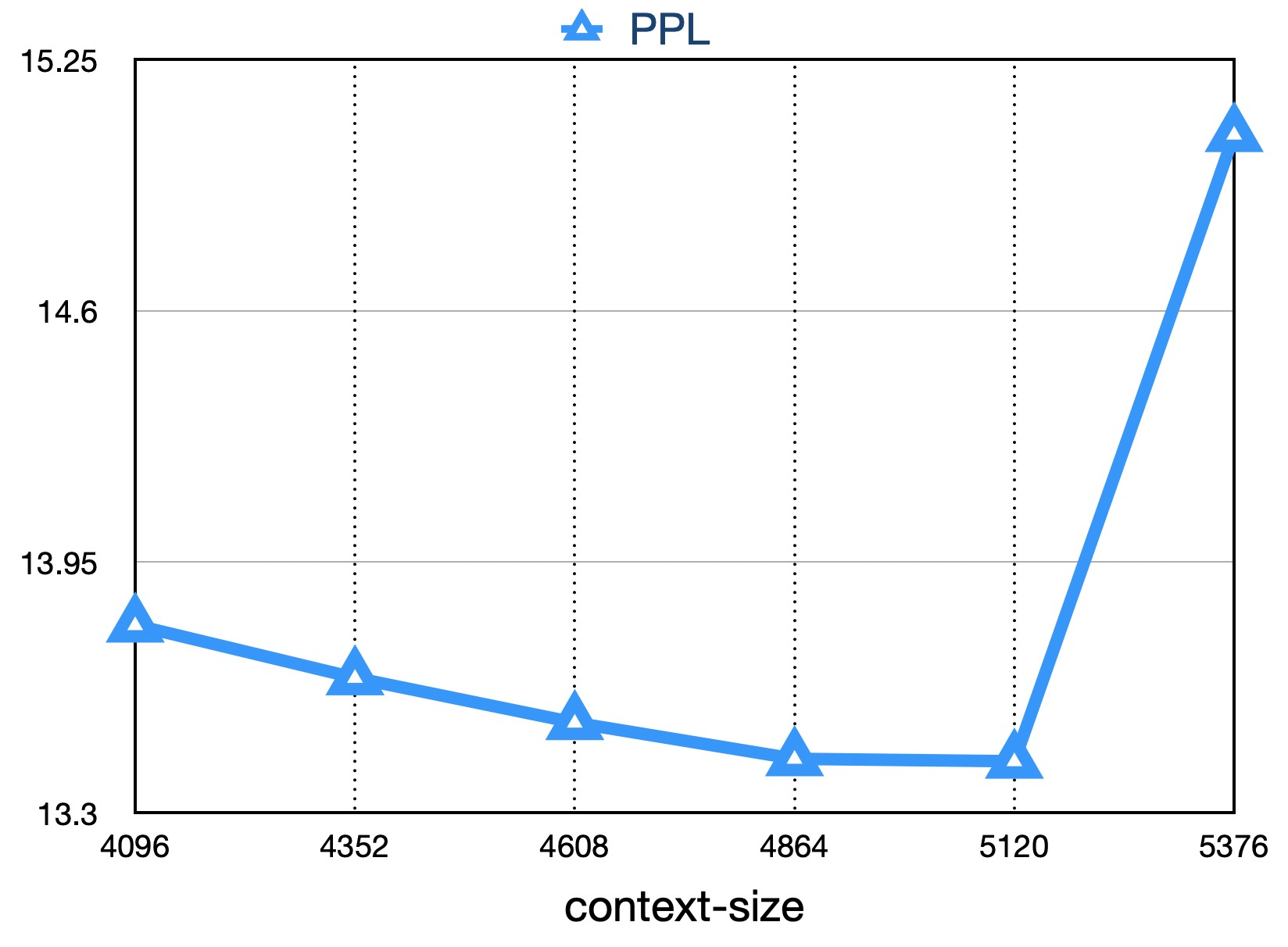
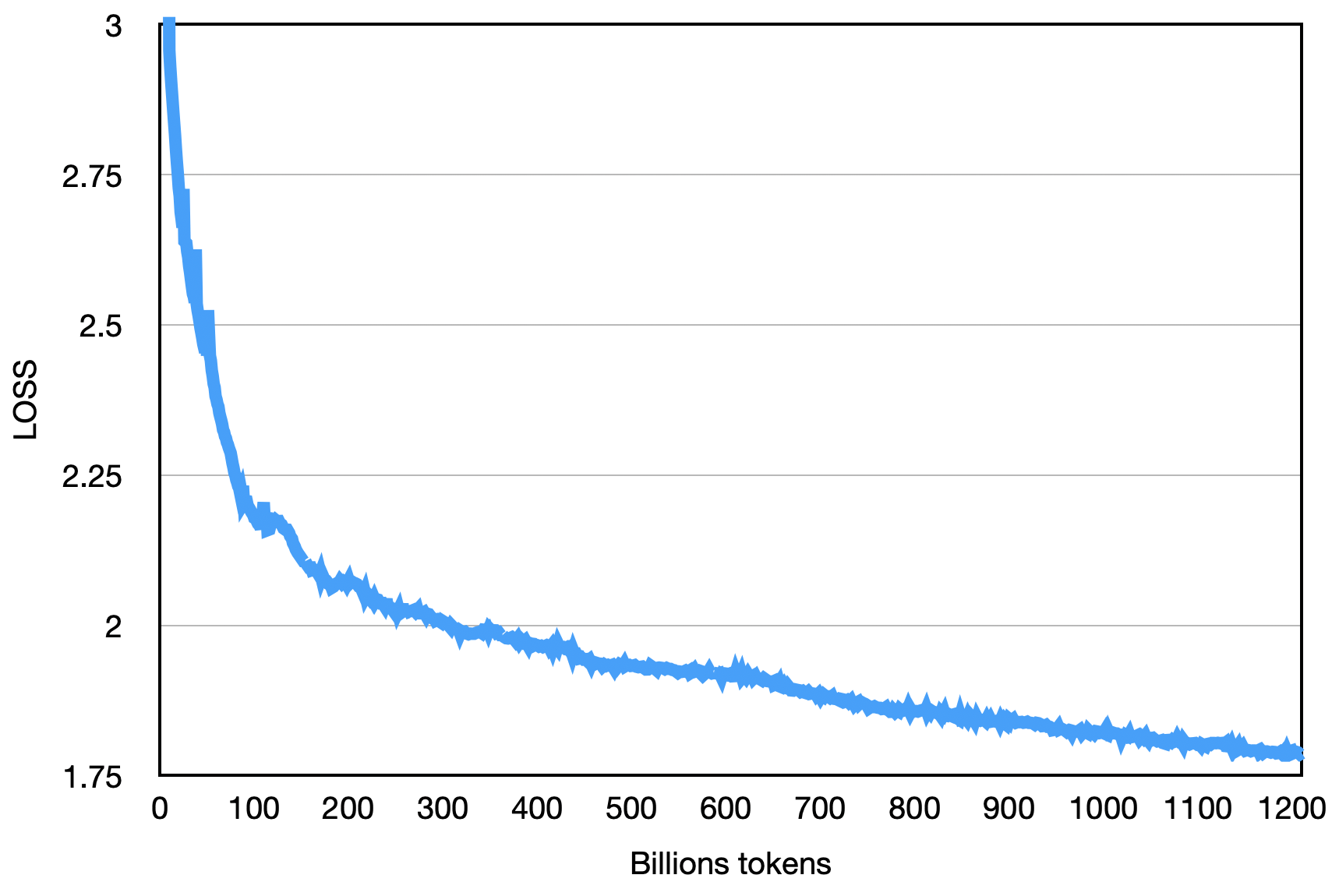
A perda final é como mostrado abaixo:
pip install -r requirements.txt O usuário divide uniformemente o corpus de treinamento em vários arquivos de texto UTF-8 de acordo com os múltiplos do número total de classificação e o coloca no diretório corpus (o padrão é data_dir ). Cada processo de classificação lerá diferentes arquivos no diretório corpus e, depois de todos os carregando na memória, ele iniciará o processo de treinamento subsequente. O acima é um processo de demonstração simplificado.
Faça o download do Tokenizer Model File Tokenizer.model e coloque -o no diretório do projeto.
Este código de demonstração é treinado usando a estrutura DeepSpeed. Os usuários precisam modificar config/hostfile de acordo com a situação do cluster. Para detalhes, consulte as instruções oficiais de velocidade profunda.
scripts / train . shO uso desse código -fonte do repositório está sujeito ao contrato de licença de código aberto Apache 2.0.
Baichuan-7b está disponível comercialmente. Se o modelo Baichuan-7b ou seus derivados forem usados para fins comerciais, entre em contato com o licenciador, como segue para se registrar e solicitar a autorização por escrito do Licenciante: Entre em contato com o e-mail: [email protected].


