Baichuan 7B
1.0.0
?
中国語|
Baichuan-7Bは、Baichuan Intelligentが開発したオープンソース市販の大規模な事前訓練モデルです。トランス構造に基づいて、約1.2兆トークンでトレーニングされた70億パラメーターモデルは、中国と英語のバイリンガルをサポートし、コンテキストウィンドウの長さは4096です。同じサイズの最良の結果は、標準的な中国と英語のベンチマーク(C-EVAL/MMLU)の両方で達成されます。
C-Evalデータセットは、52の分野と4つのレベルの難易度をカバーする包括的な中国の基本モデル評価データセットです。このデータセットの開発セットを少数のショットのソースとして使用し、テストセットで5-shotテストを実行しました。実行して次のコマンドを実行します。
cd evaluation
python evaluate_zh.py --model_name_or_path ' your/model/path '| モデル5ショット | 平均 | AVG(ハード) | 幹 | 社会科学 | 人文科学 | その他 |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| chatgpt | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-V1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| claude-instant-v1.0 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| Bloomz-7B | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| chatglm-6b | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| ziya-llama-13b-pretrain | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| Moss-moon-003-base(16b) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| llama-7b-hf | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| ファルコン-7b | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| TigerBot-7Bベース | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7b * | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| オープンラマ-V2-プレトレン(7B) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| Bloom-7B | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7b | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
Gaokaoは、中国の大学入学試験の質問をデータセットとして使用して、モデルの言語能力と論理的推論能力を評価する能力を評価するデータセットです。 単一選択の質問のみを保持し、ランダムな分割後にすべてのモデルで統一された5-shotテストを実施しました。
これがテストの結果です。
| モデル | 平均 |
|---|---|
| Bloomz-7B | 28.72 |
| llama-7b | 27.81 |
| Bloom-7B | 26.96 |
| TigerBot-7Bベース | 25.94 |
| ファルコン-7b | 23.98 |
| ziya-llama-13b-pretrain | 23.17 |
| chatglm-6b | 21.41 |
| オープンラマ-V2-プレーン | 21.41 |
| Aquila-7b * | 24.39 |
| Baichuan-7b | 36.24 |
Agievalは、認知および問題解決タスクにおけるモデルの一般的な能力を評価することを目指しています。 それらのうち4つだけを保持し、ランダムな分割後にすべてのモデルで統一された5-shotテストを実行しました。
| モデル | 平均 |
|---|---|
| Bloomz-7B | 30.27 |
| llama-7b | 28.17 |
| ziya-llama-13b-pretrain | 27.64 |
| ファルコン-7b | 27.18 |
| Bloom-7B | 26.55 |
| Aquila-7b * | 25.58 |
| TigerBot-7Bベース | 25.19 |
| chatglm-6b | 23.49 |
| オープンラマ-V2-プレーン | 23.49 |
| Baichuan-7b | 34.44 |
* Aquilaモデルは、Zhiyuanの公式Webサイト(https://model.ac.ac.cn/model-detail/100098)からのみ参照のみです。
中国語に加えて、Baichuan-7Bは、英語のモデルの効果もテストしました。オープンソースの評価スキームを採用しましたが、最終的な5-shot結果は次のとおりです。
| モデル | 人文科学 | 社会科学 | 幹 | 他の | 平均 |
|---|---|---|---|---|---|
| chatglm-6b 0 | 35.4 | 41.0 | 31.3 | 40.5 | 36.9 |
| Bloomz-7b 0 | 31.3 | 42.1 | 34.4 | 39.0 | 36.1 |
| MPT-7B 1 | - | - | - | - | 35.6 |
| llama-7b 2 | 34.0 | 38.3 | 30.5 | 38.1 | 35.1 |
| Falcon-7B 1 | - | - | - | - | 35.0 |
| Moss-moon-003-sft(16b) 0 | 30.5 | 33.8 | 29.3 | 34.4 | 31.9 |
| Bloom-7b 0 | 25.0 | 24.4 | 26.5 | 26.4 | 25.5 |
| Moss-moon-003-base(16b) 0 | 24.2 | 22.8 | 22.4 | 24.4 | 23.6 |
| Baichuan-7b 0 | 38.4 | 48.9 | 35.6 | 48.1 | 42.3 |
0:再び現れます
1:https://huggingface.co/spaces/huggingfaceh4/open_llm_leaderboard
2:https://paperswithcode.com/sota/multi-task-language-understanding on-mmlu
git clone https://github.com/hendrycks/test
cd test
wget https://people.eecs.berkeley.edu/~hendrycks/data.tar
tar xf data.tar
mkdir results
cp ../evaluate_mmlu.py .
python evaluate_mmlu.py -m /path/to/Baichuan-7BMMLUの57のタスクの特定の詳細な指標は次のとおりです。
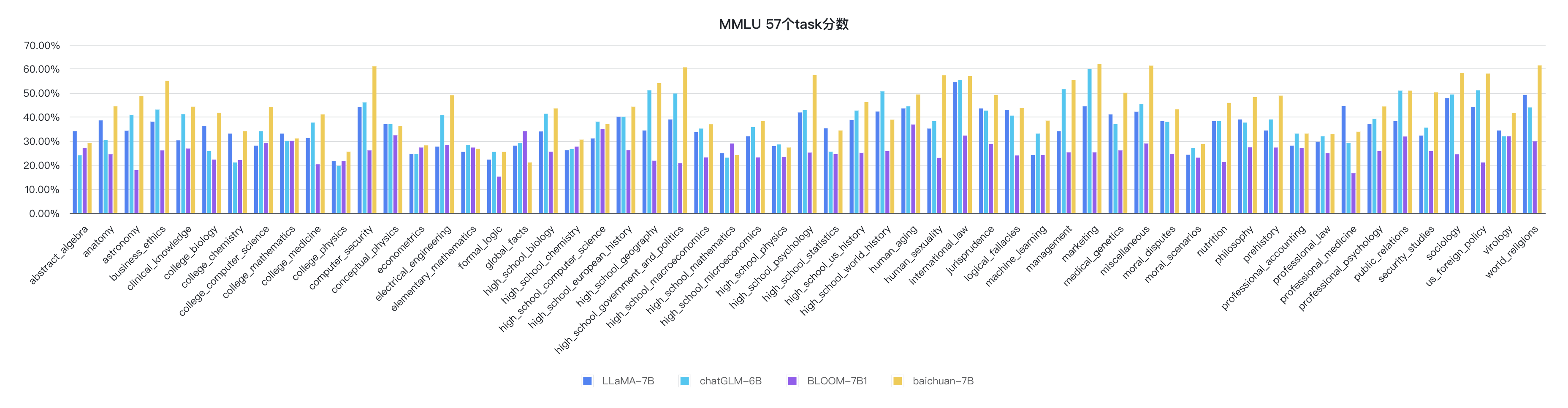
各規律の指標は次のとおりです。
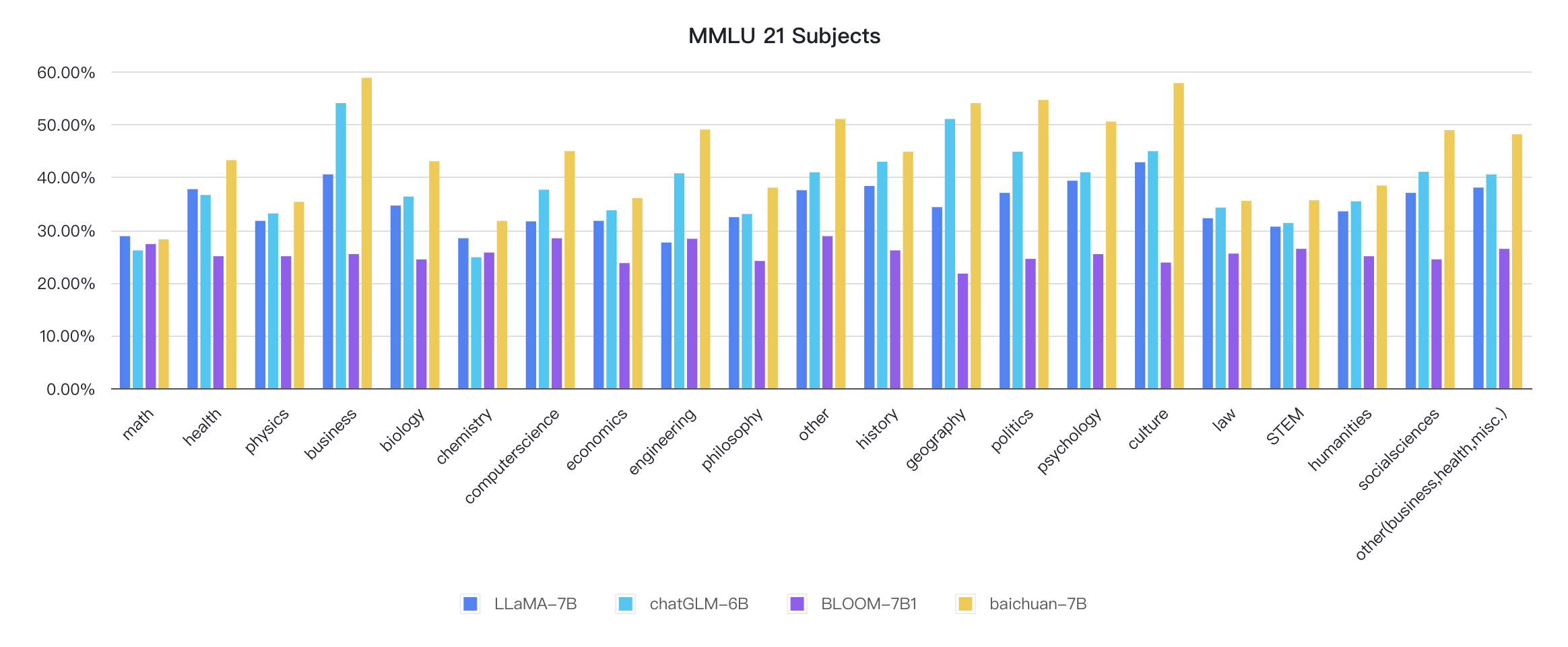
推論コードはすでに公式のハギングフェイスライブラリにあります
from transformers import AutoModelForCausalLM , AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "baichuan-inc/Baichuan-7B" , trust_remote_code = True )
model = AutoModelForCausalLM . from_pretrained ( "baichuan-inc/Baichuan-7B" , device_map = "auto" , trust_remote_code = True )
inputs = tokenizer ( '登鹳雀楼->王之涣n夜雨寄北->' , return_tensors = 'pt' )
inputs = inputs . to ( 'cuda:0' )
pred = model . generate ( ** inputs , max_new_tokens = 64 , repetition_penalty = 1.1 )
print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))全体的なプロセスは次のとおりです。
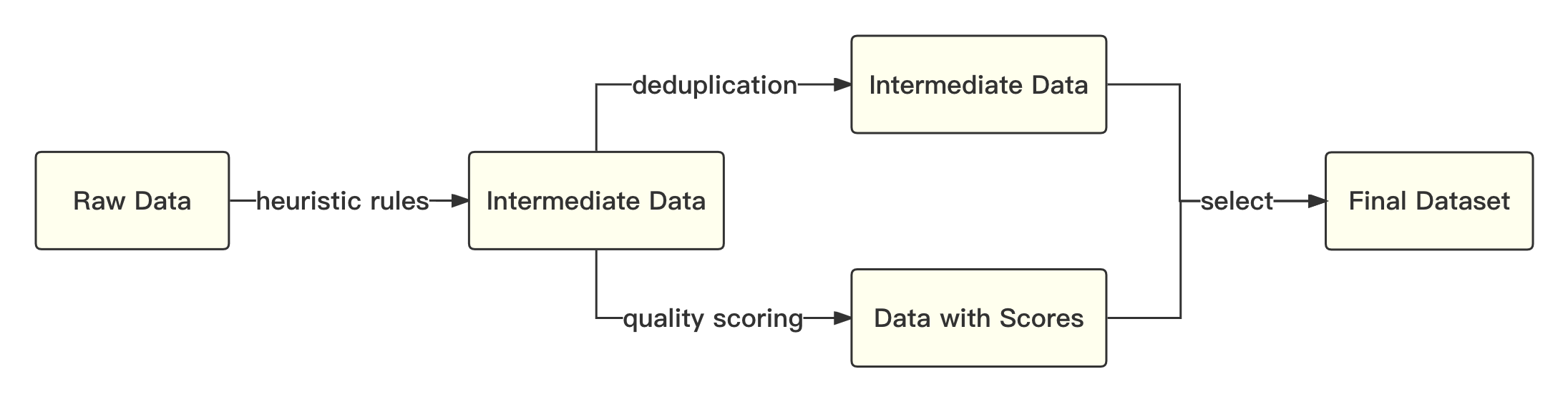
Academic Solutionを参照して、byte-pairエンコード(bpe)をtentepieceで使用してセグメンテーションアルゴリズムを使用し、次の最適化を実行します。
| モデル | Baichuan-7b | ラマ | ファルコン | MPT-7B | chatglm | Moss-Moon-003 |
|---|---|---|---|---|---|---|
| 圧縮率 | 0.737 | 1.312 | 1.049 | 1.206 | 0.631 | 0.659 |
| 音声サイズ | 64,000 | 32,000 | 65,024 | 50,254 | 130,344 | 106,029 |
モデル全体は標準の変圧器構造に基づいており、Llamaと同じモデル設計を採用しています。
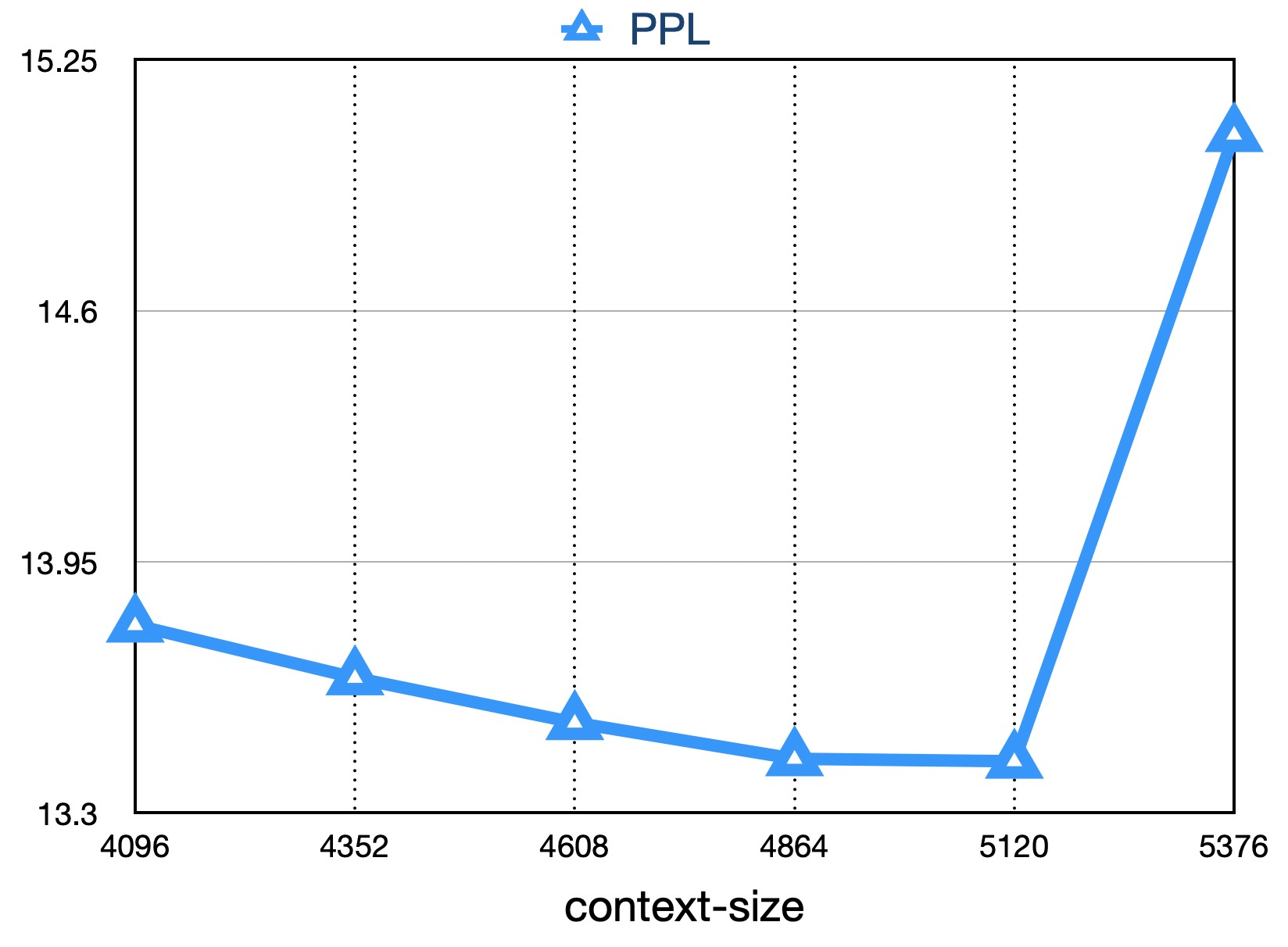
トレーニング中のスループットを改善するために、元のLlamaフレームワークに多くの変更を加えました。
上記の最適化技術に基づいて、Kilocard A800グラフィックスカードの7Bモデル182 TFLOPSのスループットを達成し、GPUのピークコンピューティングパワー利用率は58.3%です。
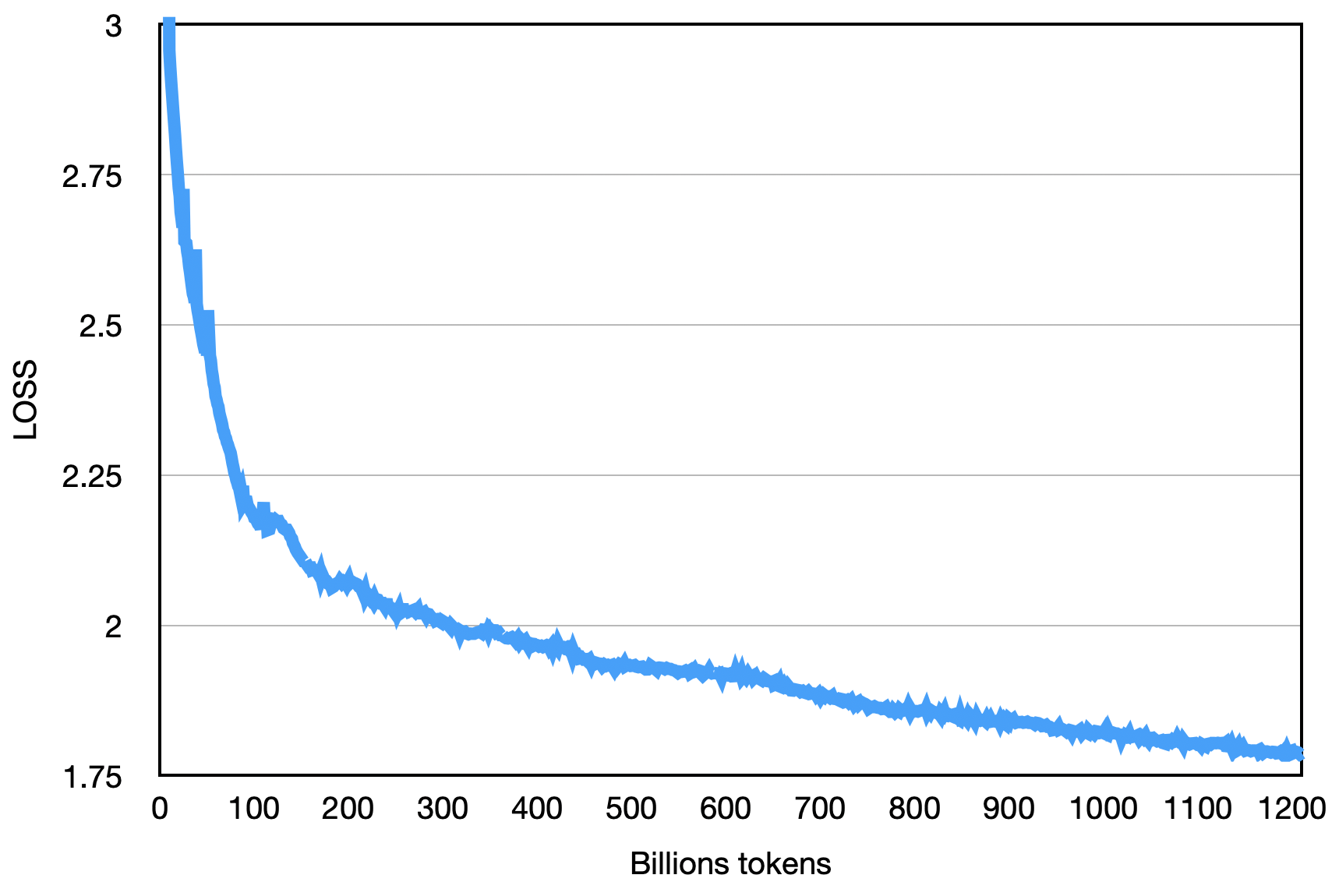
最終的な損失は以下に示すように、次のとおりです。
pip install -r requirements.txtユーザーは、トレーニングコーパスを合計ランク数の倍数に従って複数のUTF-8テキストファイルに均等に分割し、Corpusディレクトリに配置します(デフォルトはdata_dir )。各ランクプロセスは、Corpusディレクトリ内の異なるファイルを読み取り、結局メモリにロードすると、後続のトレーニングプロセスが開始されます。上記は、単純化されたデモンストレーションプロセスです。
Tokenizer Modelファイルtokenizer.modelをダウンロードして、プロジェクトディレクトリに配置します。
このデモコードは、DeepSpeedフレームワークを使用してトレーニングされています。ユーザーは、クラスターの状況に応じてconfig/hostfileを変更する必要があります。詳細については、公式のディープスピードの指示を参照してください。
scripts / train . shこのリポジトリソースコードの使用は、オープンソースライセンス契約Apache 2.0の対象となります。
Baichuan-7Bは市販されています。 Baichuan-7Bモデルまたはそのデリバティブが商業目的で使用されている場合は、ライセンサーに登録し、ライセンサーから書面による認可を申請してください。


