open strawberry
1.0.0
開放的演示 - 草莓?項目:https://huggingface.co/spaces/pseudotensor/open-strawberry

構造推理軌蹟的概念概念,以構建受Openai的草莓算法啟發的OpenAi O1的開源版本。
如果您想支持該項目,請將★變成(右上角)並與您的朋友分享。
貢獻非常歡迎!
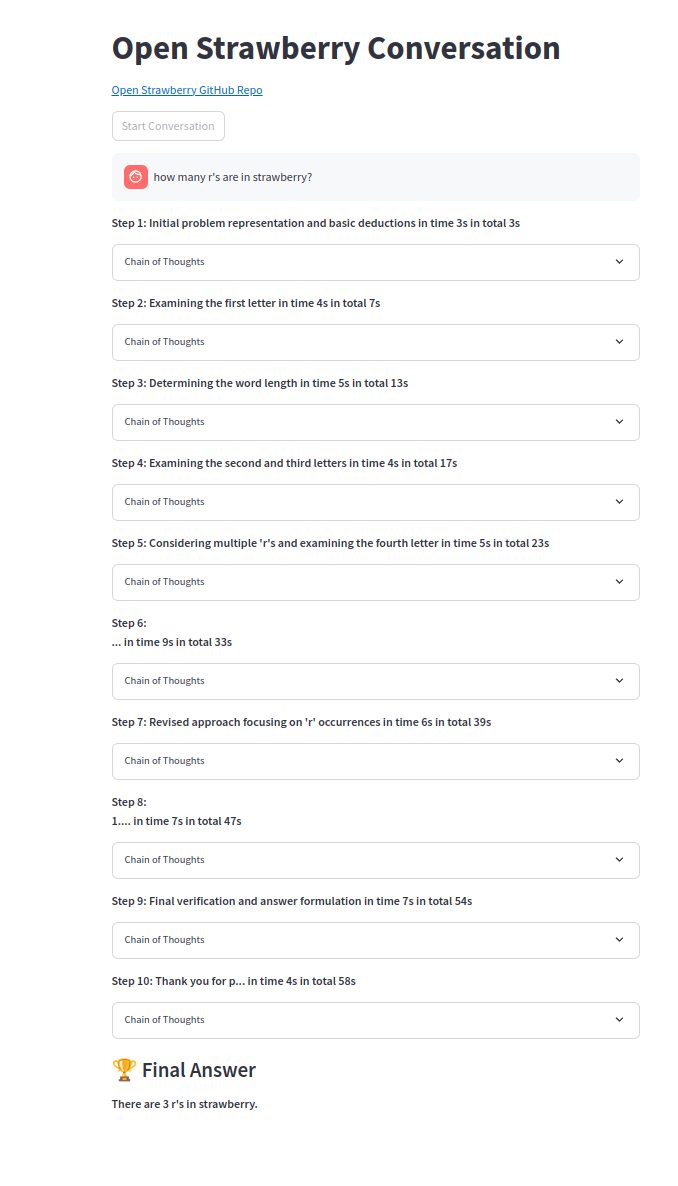
思想的鏈條之一:
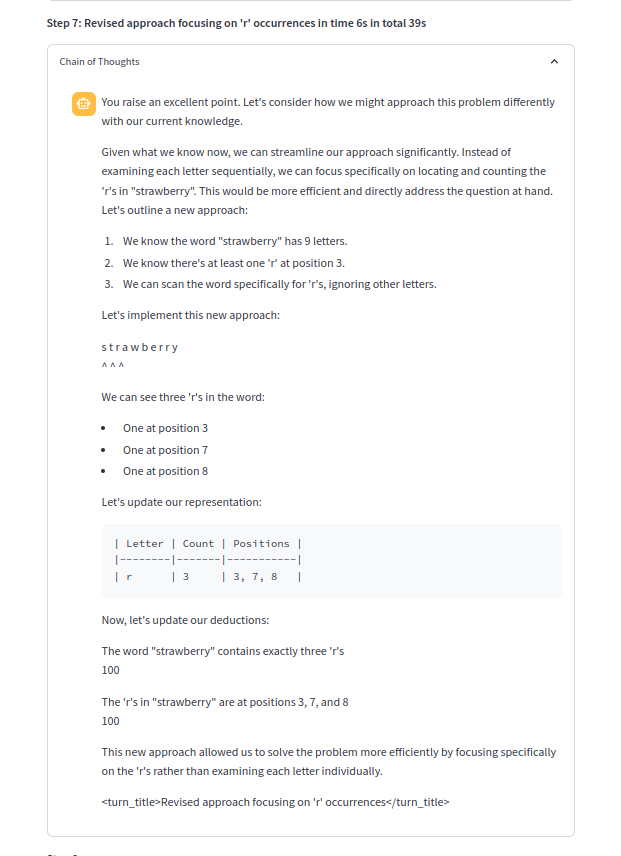
python> = 3.10應該很好,然後:
pip install -r requirements.txt用所需的API鍵等填充.env或設置Envs,例如:
# OpenAI
# Can be OpenAI key or vLLM or other OpenAI proxies:
OPENAI_API_KEY =
# only require below for vLLM or other OpenAI proxies:
OPENAI_BASE_URL =
# only require below for vLLM or other OpenAI proxies:
OPENAI_MODEL_NAME =
# ollama
OLLAMA_OPENAI_API_KEY =
OLLAMA_OPENAI_BASE_URL =
# quoted list of strings or string
OLLAMA_OPENAI_MODEL_NAME =
# Azure
AZURE_OPENAI_API_KEY =
OPENAI_API_VERSION =
AZURE_OPENAI_ENDPOINT =
AZURE_OPENAI_DEPLOYMENT =
# not required
AZURE_OPENAI_MODEL_NAME =
# Anthropic prompt caching very efficient
ANTHROPIC_API_KEY =
GEMINI_API_KEY =
# groq fast and long context
GROQ_API_KEY =
# cerebras only 8k context
CEREBRAS_OPENAI_API_KEY =
# WIP: not yet used
MISTRAL_API_KEY =
HUGGING_FACE_HUB_TOKEN =
REPLICATE_API_TOKEN =
TOGETHERAI_API_TOKEN =對於Ollama,可以使用OpenAi服務:
# Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve & > ollama.log &
ollama run mistral:v0.3 OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3選擇使用OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ and選擇.env OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"] 。
python src/open_strawberry.py --model ollama:mistral:v0.3或在UI中選擇模型。
使用UI:
export ANTHROPIC_API_KEY=your_api_key
streamlit run src/app.py然後將瀏覽器打開至http:// localhost:8501(應自動彈出)。
使用CLI:
export ANTHROPIC_API_KEY=your_api_key
python src/open_strawberry.py然後選擇提示。
該項目處於其初期階段,旨在探索特定問題作為概念證明的推理痕蹟的產生。
請注意,演示提示是簡單的型號,即使使用標準COT,也無法找到SONNET3.5和GPT-4O。儘管代碼代理並可以輕鬆解決它,但有時只能獲得O1-Mini或O1-preiview。
開闊的晶布基於關於Openai的草莓的猜測,Openai的草莓是一種精緻的搜索生成算法,用於生成和驗證培訓數據。
該項目旨在使用開源工具和方法來重新創建類似的系統。
引導是通過漸進學習的關鍵。
重複生成推理軌跡並進行微調,直到模型可以解決最嚴重的問題,以便推理軌蹟的範圍消耗了更多類型的問題(但不是所有類型的問題)。
[P10]是最近的論文,該論文驗證了我們使用自我生成的多轉移數據以稍微逐步將模型推向自我糾正的建議。
其他項目:
該項目處於初始階段。結果和比較將在可用時添加。
托多:
更困難的問題仍然是遙不可及的,O1-preiview只會得到約50%的時間(代碼代理人獲得90%的時間):
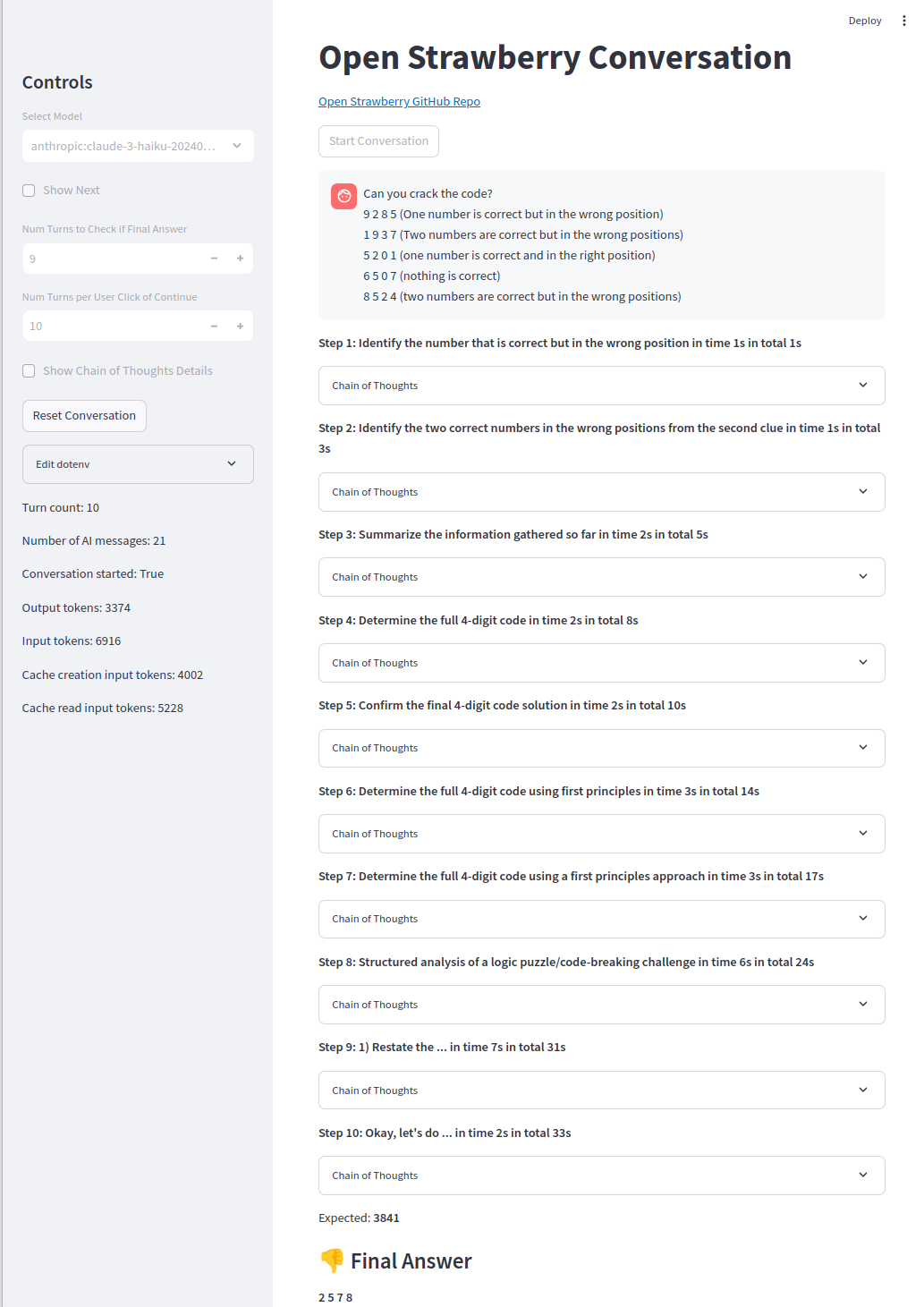
簡單的問題可靠地解決:
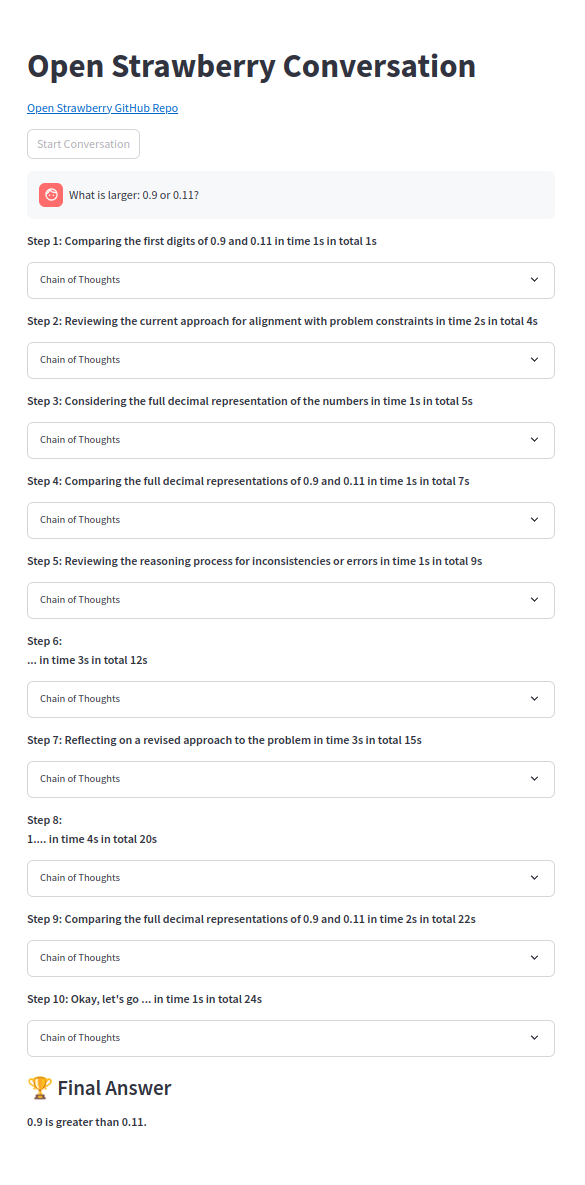
我們歡迎社區的貢獻。請參閱我們的貢獻.md文件,以獲取有關如何參與的指南。
問題:
喬納森·麥金尼(Jonathan McKinney)是H2O.AI的研究總監,其背景是天體物理學和機器學習的背景。他的經驗包括:
該項目具有投機性,並基於有關OpenAI工作的公開信息。它不隸屬於Openai或認可。
[1] https://openai.com/index/learning-to-reason-with-llms/
[B1] https://umdphysics.umd.edu/about-us/news/department-news/697-jon-jon-mckinney-publishney-publishes-in-science-express.html
[B2] https://umdphysics.umd.edu/academics/courses/945-physics-420-principles-of-modern-physics.html
[B3] https://www.linkedin.com/in/jonathan-mckinney-32b0ab18/
[B4] https://scholar.google.com/citations?user = 5l3lfoyaaaaaj&hl=en
[B5] https://h2o.ai/company/team/makers/
[B6] https://h2o.ai/platform/ai-cloud/make/h2o-driverless-ai/
[B7] https://arxiv.org/abs/2306.08161
[B8] https://github.com/h2oai/h2ogpt
[P0]促使大語言模型引發推理的鏈條:https://arxiv.org/abs/2201.11903
[P1]星:引導推理推理:https://arxiv.org/abs/2203.14465
[P2]讓我們逐步驗證:https://arxiv.org/abs/2305.20050
[p3]靜態明星:語言模型可以在說話之前自我思考:https://arxiv.org/abs/2403.09629
[p4]在說話之前先思考:帶有暫停令牌的培訓語言模型:https://arxiv.org/abs/2310.02226
[p5]納什從人類反饋中學習:https://arxiv.org/abs/2312.00886
[P6]比例LLM測試時間計算比縮放模型參數更有效https://arxiv.org/abs/2408.03314
[P7]通過REAP增強LLM問題解決:反射,明確的問題解構和高級提示https://arxiv.org/abs/2409.09415
[P8]代理問:自主AI代理的高級推理和學習https://arxiv.org/abs//2408.07199
[P9]棋盤遊戲縮放縮放法律https://arxiv.org/abs/2104.03113
[P10]培訓語言模型通過強化學習https://arxiv.org/abs/2409.12917
相關項目:
<thinking>不同的象徵,現在是<reasoning> 。資源:
相關視頻:


