Demo de la fraise ouverte? Projet: https://huggingface.co/spaces/pseudotensor/open-trawberry
Une preuve de concept pour construire des traces de raisonnement pour construire une version open source d'Openai O1 comme inspiré par l'algorithme de fraises d'Openai.
Si vous souhaitez soutenir le projet, transformez ★ en (coin supérieur droit) et partagez-le avec vos amis.
Contributions très bienvenues!
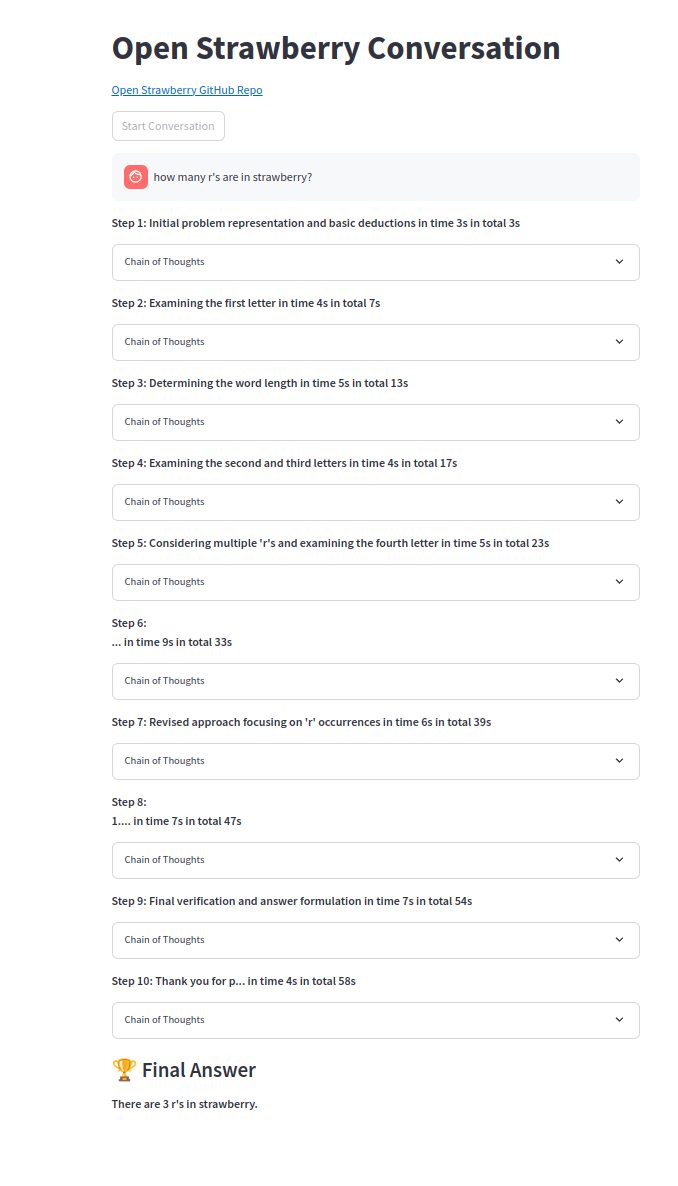
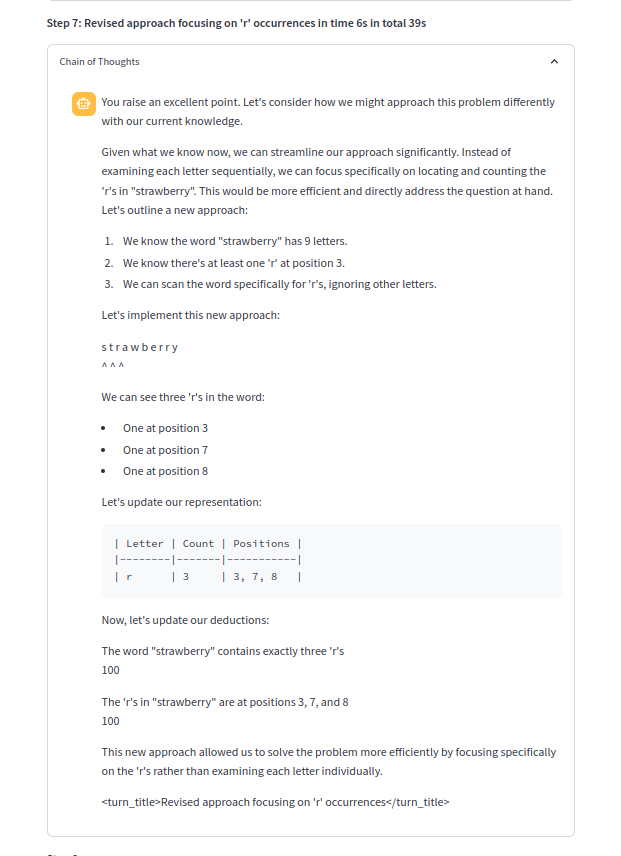
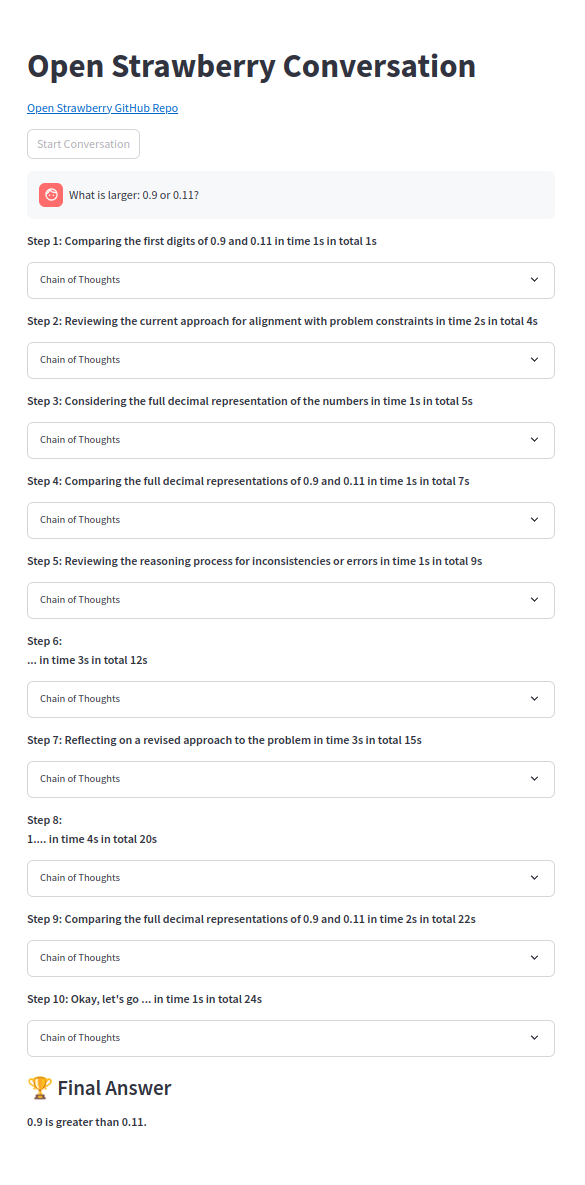
L'une des chaînes de pensée:
Installation
Python> = 3.10 devrait être bien, alors:
pip install -r requirements.txt
Usage
Remplissez .env avec les clés d'API requises, etc. ou définir env., Par exemple:
# OpenAI# Can be OpenAI key or vLLM or other OpenAI proxies:OPENAI_API_KEY=# only require below for vLLM or other OpenAI proxies:OPENAI_BASE_URL=# only require below for vLLM or other OpenAI proxies:OPENAI_MODEL_NAME=# ollamaOLLAMA_OPENAI_API_KEY=OLLAMA_OPENAI_BASE_URL=# quoted list of strings or stringOLLAMA_OPENAI_MODEL_NAME=# AzureAZURE_OPENAI_API_KEY=OPENAI_API_VERSION=AZURE_OPENAI_ENDPOINT=AZURE_OPENAI_DEPLOYMENT=# not requiredAZURE_OPENAI_MODEL_NAME=# Anthropic prompt caching very efficientANTHROPIC_API_KEY=GEMINI_API_KEY=# groq fast and long contextGROQ_API_KEY=# cerebras only 8k contextCEREBRAS_OPENAI_API_KEY=# WIP: not yet usedMISTRAL_API_KEY=HUGGING_FACE_HUB_TOKEN=REPLICATE_API_TOKEN=TOGETHERAI_API_TOKEN=
ollla
Pour Ollama, on peut utiliser le service OpenAI:
# Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve &> ollama.log &
ollama run mistral:v0.3
Ensuite, choisissez SET .env avec OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ et eg OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3 ou liste des modèles ollama: OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"]
Le projet est à ses premiers stades pour explorer la génération de traces de raisonnement pour des problèmes spécifiques comme preuve de concept.
Notez que l'invite de démonstration est des modèles simples et même Sonnet3.5 et GPT-4O ne peuvent pas trouver de solution même avec un COT standard. Seuls O1-MINI ou O1-Preview peuvent parfois obtenir, bien que les agents de code et le résoudre facilement.
Arrière-plan
Open-Strawberry est basé sur des spéculations sur la fraise d'Openai, un algorithme de génération de recherche raffiné pour la génération et la vérification des données de formation.
Ce projet vise à recréer un système similaire à l'aide d'outils et de méthodologies open source.
Définitions spéculatives
Q *: Un algorithme RL profond de la génération primordiale hypothétique développé par OpenAI pour générer des données de formation.
Strawberry : un algorithme de RL profond de génération de recherche avancée par OpenAI pour générer et vérifier les données de formation.
O1 : GPT-4O et GPT-4O-MINI mais affinés sur les données de fraises, y compris O1-Mini, O1-Preview, O1 et O1-IOI. [1]
Orion : Modèle basé sur GPT-5 qui intègre les données synthétiques de Strawberry et gère mieux les requêtes de raisonnement 0 et longue.
Génération de traces de raisonnement
L'amorçage est essentiel via un apprentissage progressif.
Bootstrap à partir de modèles réglés à réglage fin existant, réglées par instruction, en utilisant l'historique de chat multi-tours.
Implémentez un système rapide qui guide le LLM pour prendre des étapes incrémentielles vers une solution.
Invites de COT utiles randomisées de l'utilisateur (par exemple, pas seulement la prochaine, mais "êtes-vous sûr?" "Des erreurs?" "Comment vérifieriez-vous votre réponse?") À un raisonnement et à une introspection illicites.
Soulignez le LLM pour faire l'étape la plus minuscule vers la solution, par exemple, même une seule phrase ou phrase est préférée. Ce n'est qu'une fois que la réponse finale serait produite si une réponse complète prolongée était donnée.
Générer des traces de raisonnement de chat multi-tours
Demandez parfois si le modèle est confiant sur une réponse. Si c'est le cas, demandez-lui de placer cette réponse dans les balises XML <inforne_answer>. Si cela est fait, terminez la génération de trace de raisonnement.
Utilisez un système de vérification pour vérifier les erreurs dans l'historique du chat.
Générez plusieurs traces de raisonnement par problème.
Appliquez ce processus à un grand ensemble de problèmes avec des vérités au sol vérifiables.
Identifier les problèmes que le modèle d'instruct existant peut faire à peine avec un COT fort et une température élevée pour un certain nombre de répétitions fixes (par exemple 20).
Affineur sur les traces de raisonnement
Sélectionnez des traces de raisonnement correct et incorrectes pour chaque problème en fonction de la vérité du sol.
Affiner un modèle à l'aide des traces de raisonnement sélectionnées à l'aide de DPO ou NLHF, où la préférence est positive pour les traces correctes, négatives pour des traces incorrectes.
Plantez le poids de la préférence par le nombre de mesures prises, c'est-à-dire que si elles sont incorrectes, des traces négatives plus longues devraient obtenir une récompense négative plus grande. Les traces correctes qui sont plus courtes devraient obtenir une récompense plus positive.
Affinez le modèle sur ces traces de raisonnement avec le mélange d'autres données comme d'habitude.
Utilisez ce modèle pour générer des traces de raisonnement pour des problèmes légèrement plus difficiles que ce nouveau modèle peut à peine faire.
Répétez la génération de traces de raisonnement et le réglage fin jusqu'à ce que le modèle puisse faire les problèmes les plus difficiles, de sorte que la portée des traces de raisonnement a consommé plus de types de problèmes (mais pas tous les types car il n'est pas toujours nécessaire).
Spéculations
MCTS, TOT, AGENTS, etc. Non requis pour la formation ou le temps d'inférence.
L'étiquetage humain ou la vérification humaine des traces de raisonnement ne sont pas nécessaires.
Les modèles de vérification affinés ne sont pas nécessaires, quelle que soit la mesure.
RLHF n'est pas strictement requis, juste DPO.
OpenAI utilise Deep RL pour former les traces de raisonnement, mais je ne pense pas que cela soit nécessaire. L'auto-play est puissante, mais peut être imitée par DPO.
Deep RL est juste un moyen de générer des données de manière efficace, mais n'est pas requis et de tenir simplement des travaux antérieurs d'OpenAI à ce sujet.
Justifications
[P10] est un article récent qui valide notre proposition d'utiliser des données multi-virages auto-générées pour pousser légèrement le modèle vers l'auto-correction.
Objectifs du projet
Générez des traces de raisonnement en utilisant l'approche proposée.
Affiner un modèle sur les traces de raisonnement générées.
Évaluez les performances et comparez-la avec les modèles existants avec des coups de zéro, à quelques tirs, COT, etc.
Autres projets:
La principale différence avec la framboise est qu'elles se concentrent sur des invites dures, tandis que nous pensons qu'une approche d'apprentissage progressive avec un réglage fin répété se décollera vers O1.
La principale différence avec G1 est qu'ils se concentrent seuls sur le comportement de type O1, sans mettre l'accent sur la façon de s'adapter à l'O1.
La prise en charge de l'API anthropique et Google de la mise en cache rapide signifie beaucoup moins cher à exécuter. VLLM prend en charge la mise en cache des préfixes qui aide également cela.
État actuel
Ce projet en est à ses premiers stades. Des résultats et des comparaisons seront ajoutés à mesure qu'ils seront disponibles.
FAIRE:
Configuration du cas anthropique de base avec une mise en cache rapide
Configurer l'application de base de base pour surveiller facilement les sorties
Recherchez le soutien de la communauté
Toutes les (disons) 9 étapes, demandez si le modèle pense qu'il a une réponse finale, et si oui, demandez-lui de placer cette réponse dans les balises XML <instal_answer> pour l'extraction et la fin de la trace de raisonnement.
Ajouter un revers
Ajouter Olllama, Google, Azure, Openai, Groq, API anthropiques avec une mise en cache rapide pour Anthropic
Ajouter un résumé de haut niveau des blocs de texte comme O1
Améliorez l'invite du système, faites-le aussi bien ou séparément des invites à suivre pour l'utilisateur
Ajouter le vérificateur qui échantillonne la fenêtre de l'histoire et critique séparément la sortie de l'assistant
Utilisez des ensembles de données existants avec une vérité au sol pour identifier les problèmes pour lesquels le COT réussit après certains essais
Récolter des invites adaptées aux cotons et collecter des traces de raisonnement positives et négatives
Affiner avec DPO, y compris avec un mélange de données normales également avec une distribution similaire
Répétez le prochain tour d'invites pour les cotons à l'exclusion des invites originales, il en va de même pour bootstrap
Affinez-vous au-dessus de l'affaissement, y compris avec un mélange de données normales également avec une distribution similaire
Répétez globalement jusqu'à ce que Bootstrap-Repeat soit un modèle plus intelligent
Des problèmes plus difficiles sont toujours hors de portée, ce que O1-Preview n'obtient qu'environ 50% du temps (les agents du code obtiennent 90% du temps):
Les problèmes faciles sont résolus de manière fiable:
Contributif
Nous accueillons les contributions de la communauté. Veuillez consulter notre fichier contribution.md pour des directives sur la façon de participer.
Problèmes:
Le bouton Continuer dans l'application laisse de vieilles chats grisés, mieux s'il est démarré proprement
Le comptage de jetons n'apparaît qu'après le coup continue, le mieux si c'était à chaque tour
À propos de l'auteur
Jonathan McKinney est le directeur de la recherche chez H2O.ai avec une formation en astrophysique et en apprentissage automatique. Son expérience comprend:
Ancien professeur d'astrophysique à l'UMD [B1] [B2] [B3] [B4]
7 ans d'expérience avec les produits Automl à H2O.ai [B5] [B6]
Travaux récents sur les agents LLMS, RAG et AI à réglage fin (H2OGPT) [B7] [B8]
Voir mes autres projets comme H2ogpt et ingénierie rapide
Clause de non-responsabilité
Ce projet est spéculatif et basé sur des informations accessibles au public sur le travail d'Openai. Il n'est pas affilié ou approuvé par Openai.
[P0] L'incitation en chaîne-pensée suscite un raisonnement dans les modèles de grande langue: https://arxiv.org/abs/2201.11903
[P1] Star: Raisonnement de bootstrap avec raisonnement: https://arxiv.org/abs/2203.14465
[P2] Vérinons étape par étape: https://arxiv.org/abs/2305.20050
[P3] Quiet-Star: les modèles de langue peuvent s'apprendre à réfléchir avant de parler: https://arxiv.org/abs/2403.09629
[P4] Réfléchissez avant de parler: Modèles de langue de formation avec des jetons en pause: https://arxiv.org/abs/2310.02226
[P5] Nash Apprentissage de la rétroaction humaine: https://arxiv.org/abs/2312.00886
[P6] La composition de test de test LLM de mise à l'échelle peut être plus efficace que les paramètres du modèle de mise à l'échelle https://arxiv.org/abs/2408.03314
[P7] Amélioration de la résolution de problèmes LLM avec Reap: réflexion, déconstruction du problème explicite et invitation avancée https://arxiv.org/abs/2409.09415
[P8] Agent Q: raisonnement et apprentissage avancé pour les agents AI autonomes https://arxiv.org/abs//2408.07199
[P9] Échelle des lois sur l'échelle avec les jeux de société https://arxiv.org/abs/2104.03113
[P10] Formation des modèles de langue à s'auto-corriger via l'apprentissage du renforcement https://arxiv.org/abs/2409.12917
Projets connexes:
[Équipe OpenO1] Open-source O1
[Gair-NLP] O1 Journey de réplication: un rapport d'étape stratégique
[MAITRIX.ORG] LLM RESCONDANTS
[Bklieger-Groq] G1: Utilisation de LLAMA-3.1 70b sur le grooq pour créer des chaînes de raisonnement en forme d'O1
[O1-Chain-of-Thing Wought] Transcription des traces de raisonnement O1 à partir d'un article de blog OpenAI
[Toyberry] Toyberry: Une fin de fin de fin de fin du système de raisonnement O1 d'Openai en utilisant MCTS et LLM comme backend
Mais à mon humble avis, le LLM voit juste un jeton différent de <thinking> et maintenant c'est <reasoning> .
Ressource:
[Awsome-llm-strawberry]
Vidéos connexes:
https://www.youtube.com/watch?v=tpun1uokecc (invites en cascade avec lit de lit répété)
https://youtu.be/ey9ihse82hc?t=2742 (Noam Brown on self-play avec LLMS)
https://youtu.be/nvaxucibb-c?list=pldrirstud7wwjxhoi9vvxeo9ktufbxlhf (pourquoi vlad tenev et Tudor Achim de l'harmonique pense que l'AI est sur le point de changer les mathématiques - et pourquoi cela compte)
https://youtu.be/jplusxjpdra?si=yspkfx57t7eyel5o (Noam Brown d'Openai, Ilge Akkaya et Hunter Lightman sur O1 et enseignant LLMS à mieux raisonner)