open strawberry
1.0.0
การสาธิตเปิด-สตรอเบอร์รี่? โครงการ: https://huggingface.co/spaces/pseudotensor/open-strawberry

การพิสูจน์แนวคิดในการสร้างร่องรอยการใช้เหตุผลเพื่อสร้าง OpenAI O1 เวอร์ชันโอเพนซอร์ซซึ่งได้รับแรงบันดาลใจจากอัลกอริทึมสตรอเบอร์รี่ของ OpenAI
หากคุณต้องการสนับสนุนโครงการให้เปิด★เป็น (มุมบนขวา) และแบ่งปันกับเพื่อนของคุณ
ยินดีต้อนรับอย่างมาก!
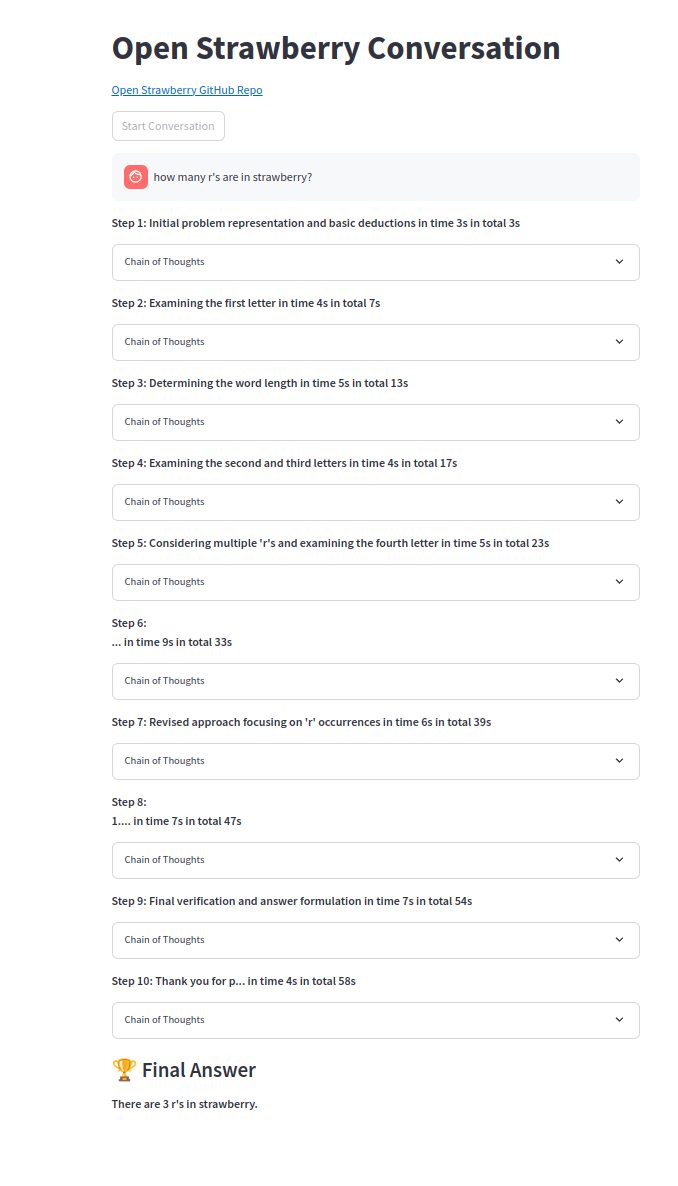
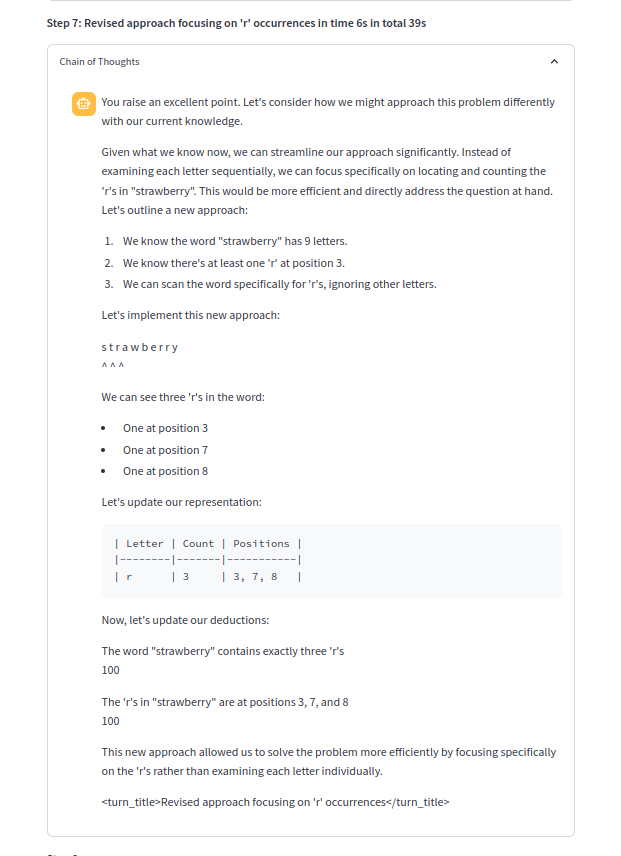
หนึ่งในโซ่แห่งความคิด:
Python> = 3.10 ควรจะดีแล้ว:
pip install -r requirements.txt เติม .env ด้วยปุ่ม API ที่จำเป็น ฯลฯ หรือตั้งค่า envs เช่น:
# OpenAI
# Can be OpenAI key or vLLM or other OpenAI proxies:
OPENAI_API_KEY =
# only require below for vLLM or other OpenAI proxies:
OPENAI_BASE_URL =
# only require below for vLLM or other OpenAI proxies:
OPENAI_MODEL_NAME =
# ollama
OLLAMA_OPENAI_API_KEY =
OLLAMA_OPENAI_BASE_URL =
# quoted list of strings or string
OLLAMA_OPENAI_MODEL_NAME =
# Azure
AZURE_OPENAI_API_KEY =
OPENAI_API_VERSION =
AZURE_OPENAI_ENDPOINT =
AZURE_OPENAI_DEPLOYMENT =
# not required
AZURE_OPENAI_MODEL_NAME =
# Anthropic prompt caching very efficient
ANTHROPIC_API_KEY =
GEMINI_API_KEY =
# groq fast and long context
GROQ_API_KEY =
# cerebras only 8k context
CEREBRAS_OPENAI_API_KEY =
# WIP: not yet used
MISTRAL_API_KEY =
HUGGING_FACE_HUB_TOKEN =
REPLICATE_API_TOKEN =
TOGETHERAI_API_TOKEN =สำหรับ Ollama เราสามารถใช้บริการ OpenAI:
# Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve & > ollama.log &
ollama run mistral:v0.3 จากนั้นเลือกชุด .env ด้วย OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ และเช่น OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3 หรือรายการ ollama: OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"]
python src/open_strawberry.py --model ollama:mistral:v0.3หรือเลือกแบบจำลองใน UI
ใช้ UI:
export ANTHROPIC_API_KEY=your_api_key
streamlit run src/app.pyจากนั้นเปิดเบราว์เซอร์เป็น http: // localhost: 8501 (ควรป๊อปอัพโดยอัตโนมัติ)
ใช้ CLI:
export ANTHROPIC_API_KEY=your_api_key
python src/open_strawberry.pyจากนั้นเลือกพรอมต์
โครงการอยู่ในช่วงเริ่มต้นเพื่อสำรวจการสร้างร่องรอยการใช้เหตุผลสำหรับปัญหาเฉพาะเพื่อเป็นหลักฐานของแนวคิด
โปรดทราบว่าพรอมต์การสาธิตเป็นรุ่นที่เรียบง่ายและแม้แต่ SONNET3.5 และ GPT-4O ไม่สามารถหาวิธีแก้ปัญหาได้แม้จะมีเปลมาตรฐาน บางครั้งเท่านั้นที่มีเฉพาะ O1-MINI หรือ O1-Preview เท่านั้นแม้ว่าจะเป็นตัวแทนโค้ดและแก้ปัญหาได้อย่างง่ายดาย
Open-Strawberry ขึ้นอยู่กับการคาดเดาเกี่ยวกับ Strawberry ของ OpenAI ซึ่งเป็นอัลกอริทึมการค้นหารุ่นที่ละเอียดอ่อนสำหรับการสร้างและตรวจสอบข้อมูลการฝึกอบรม
โครงการนี้มีจุดมุ่งหมายเพื่อสร้างระบบที่คล้ายกันโดยใช้เครื่องมือและวิธีการแบบโอเพ่นซอร์ส
Bootstrapping เป็นกุญแจสำคัญผ่านการเรียนรู้แบบก้าวหน้า
การสร้างร่องรอยการใช้เหตุผลซ้ำ ๆ และการปรับแต่งจนกว่าโมเดลจะสามารถทำปัญหาที่ยากที่สุดเช่นขอบเขตของการให้เหตุผลตามร่องรอยซึ่งเป็นปัญหาที่ใช้มากขึ้น (แต่ไม่ใช่ทุกประเภทเนื่องจากไม่จำเป็นเสมอไป)
[P10] เป็นบทความล่าสุดที่ตรวจสอบข้อเสนอของเราในการใช้ข้อมูลหลายเทิร์นที่สร้างขึ้นเองเพื่อผลักดันแบบจำลองไปสู่การแก้ไขตนเองเล็กน้อย
โครงการอื่น ๆ :
โครงการนี้อยู่ในระยะเริ่มต้น ผลลัพธ์และการเปรียบเทียบจะถูกเพิ่มตามที่มีอยู่
สิ่งที่ต้องทำ:
ปัญหาที่ยากขึ้นยังไม่สามารถเข้าถึงได้ซึ่ง O1-Preview จะได้รับประมาณ 50% ของเวลา (ตัวแทนรหัสได้รับ 90% ของเวลา):
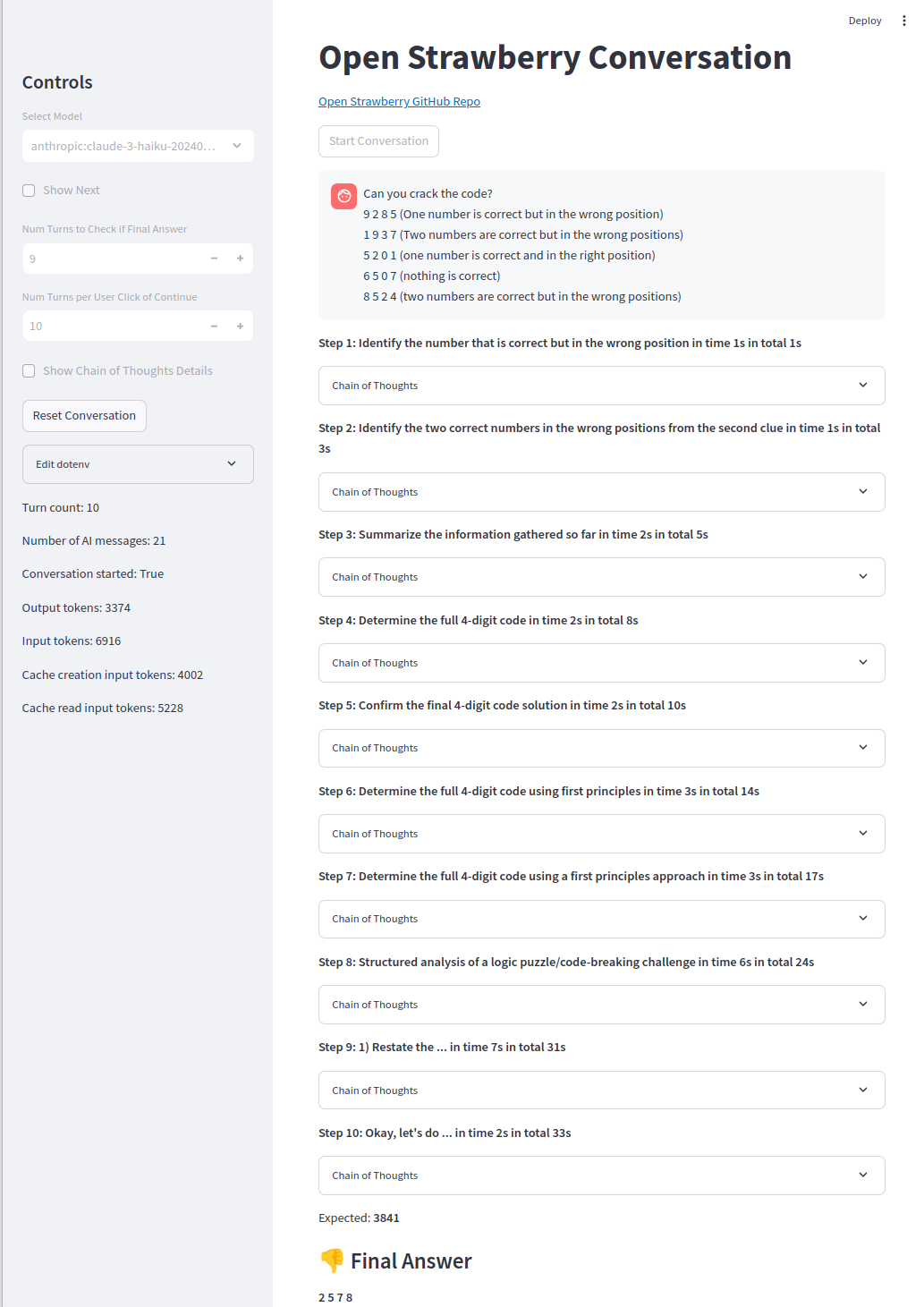
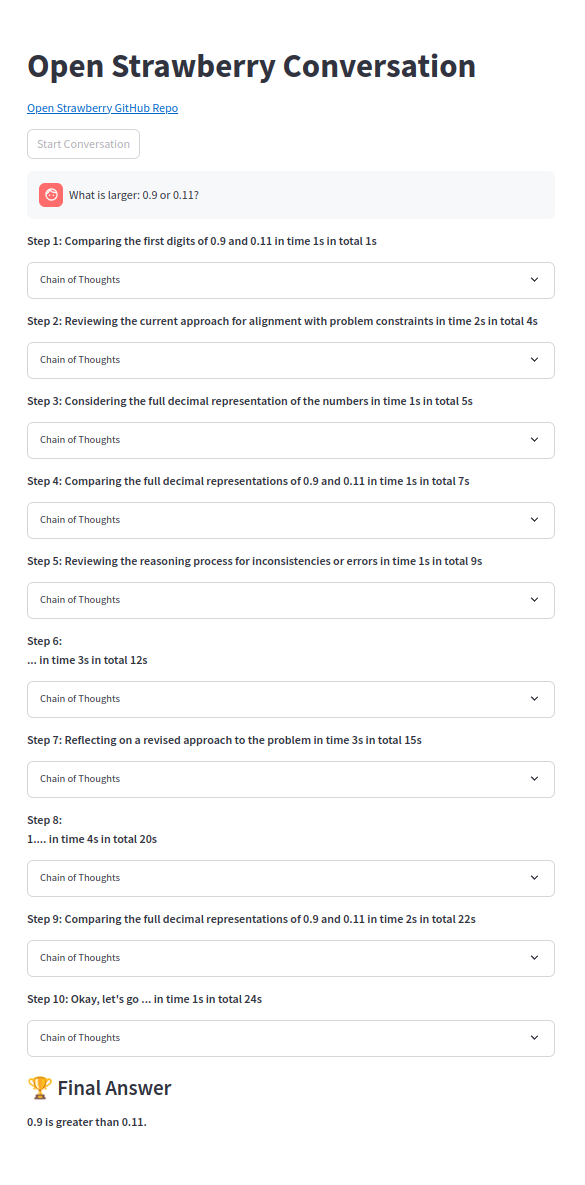
ปัญหาง่าย ๆ ได้รับการแก้ไขอย่างน่าเชื่อถือ:
เรายินดีต้อนรับการมีส่วนร่วมจากชุมชน โปรดดูไฟล์ MD ของเราสำหรับแนวทางเกี่ยวกับวิธีการเข้าร่วม
ปัญหา:
Jonathan McKinney เป็นผู้อำนวยการฝ่ายวิจัยที่ H2O.AI ที่มีพื้นฐานด้านการเรียนรู้ทางดาราศาสตร์และการเรียนรู้ของเครื่องจักร ประสบการณ์ของเขารวมถึง:
โครงการนี้มีการเก็งกำไรและขึ้นอยู่กับข้อมูลที่เปิดเผยต่อสาธารณะเกี่ยวกับงานของ Openai มันไม่ได้เป็นพันธมิตรกับหรือรับรองโดย Openai
[1] https://openai.com/index/learning-to-reason-with-llms/
[b1] https://umdphysics.umd.edu/about-us/news/department-news/697-jon-mckinney-publishes-in-science-express.html
[b2] https://umdphysics.umd.edu/academics/courses/945-physics-420-principles-of-modern-physics.html
[b3] https://www.linkedin.com/in/jonathan-mckinney-32b0ab18/
[b4] https://scholar.google.com/citations?user=5l3lfoyaaaaaj&hl=en
[b5] https://h2o.ai/company/team/makers/
[b6] https://h2o.ai/platform/ai-cloud/make/h2o-driverless-ai/
[b7] https://arxiv.org/abs/2306.08161
[b8] https://github.com/h2oai/h2ogpt
[P0] ห่วงโซ่ของความคิดกระตุ้นการใช้เหตุผลในรูปแบบภาษาขนาดใหญ่: https://arxiv.org/abs/2201.11903
[P1] Star: Bootstrapping การใช้เหตุผลด้วยเหตุผล: https://arxiv.org/abs/2203.14465
[P2] ตรวจสอบทีละขั้นตอน: https://arxiv.org/abs/2305.20050
[P3] Suiet-Star: แบบจำลองภาษาสามารถสอนตัวเองให้คิดก่อนพูด: https://arxiv.org/abs/2403.09629
[P4] คิดก่อนที่คุณจะพูด: โมเดลภาษาการฝึกด้วยโทเค็นหยุดชั่วคราว: https://arxiv.org/abs/2310.02226
[P5] NASH เรียนรู้จากข้อเสนอแนะของมนุษย์: https://arxiv.org/abs/2312.00886
[P6] การคำนวณการคำนวณ LLM-Time การคำนวณอย่างดีที่สุดอาจมีประสิทธิภาพมากกว่าพารามิเตอร์การปรับขนาดพารามิเตอร์ https://arxiv.org/abs/2408.03314
[P7] การเพิ่มปัญหา LLM ด้วยการแก้ปัญหา: การไตร่ตรองการรื้อฟื้นปัญหาที่ชัดเจนและการแจ้งเตือนขั้นสูง https://arxiv.org/abs/2409.09415
[P8] Agent Q: การใช้เหตุผลและการเรียนรู้ขั้นสูงสำหรับตัวแทน AI อิสระ https://arxiv.org/abs//2408.07199
[P9] การปรับขนาดกฎหมายกับเกมกระดาน https://arxiv.org/abs/2104.03113
[P10] แบบจำลองภาษาการฝึกอบรมเพื่อแก้ไขตนเองผ่านการเรียนรู้การเสริมแรง https://arxiv.org/abs/2409.12917
โครงการที่เกี่ยวข้อง:
<thinking> และตอนนี้มันก็คือ <reasoning>ทรัพยากร:
วิดีโอที่เกี่ยวข้อง:


