Demoção de Strawberry Open? Projeto: https://huggingface.co/spaces/pseudotetensor/open-strawberry
Uma prova de conceito à construção de traços de raciocínio para construir uma versão de código aberto do OpenAi O1, inspirado no algoritmo Strawberry da Openai.
Se você deseja apoiar o projeto, transforme ★ em (canto superior direito) e compartilhe-o com seus amigos.
Contribuições muito bem -vindas!
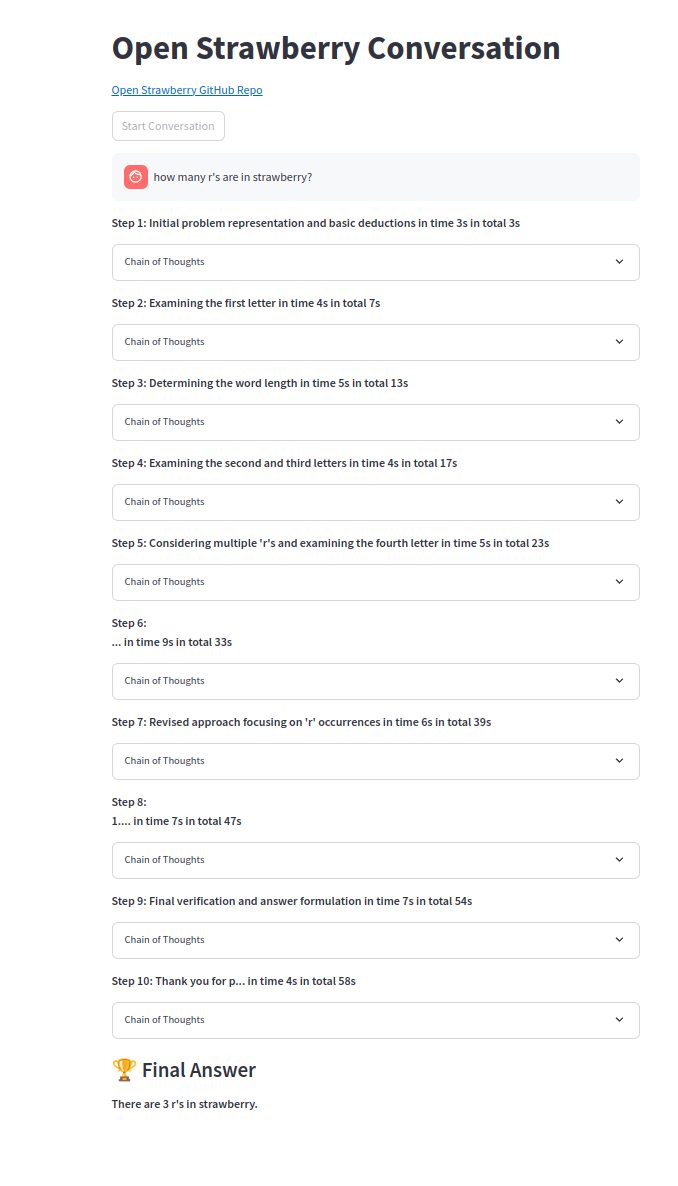
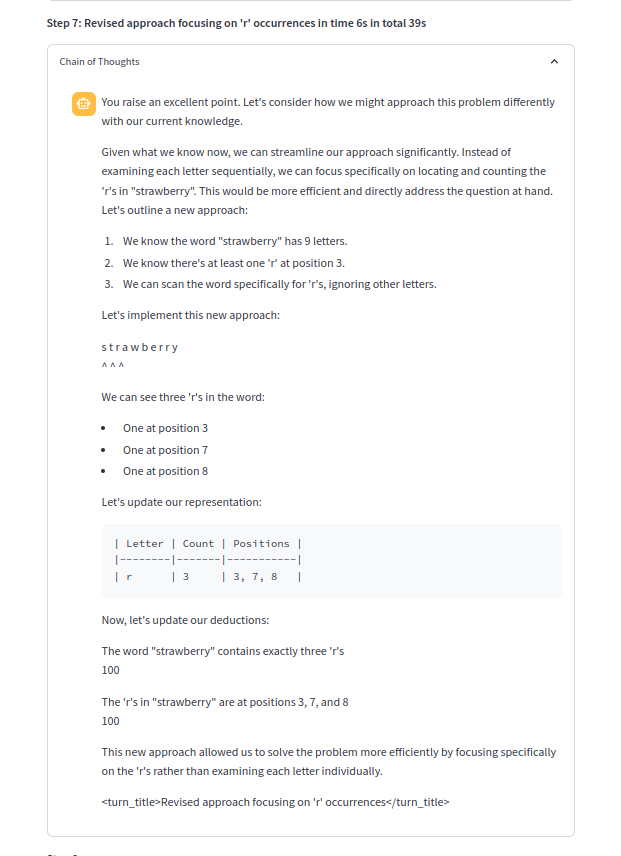
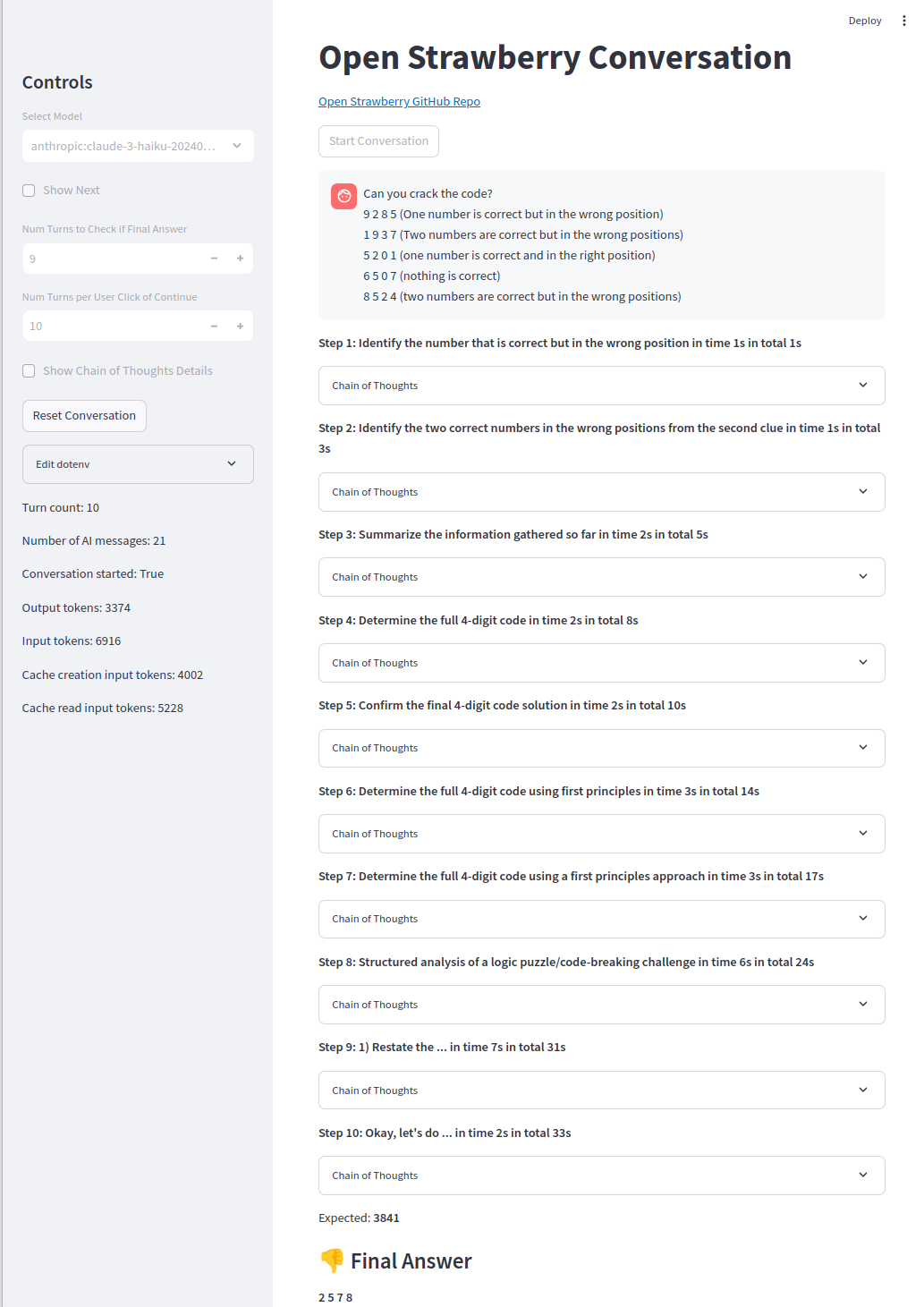
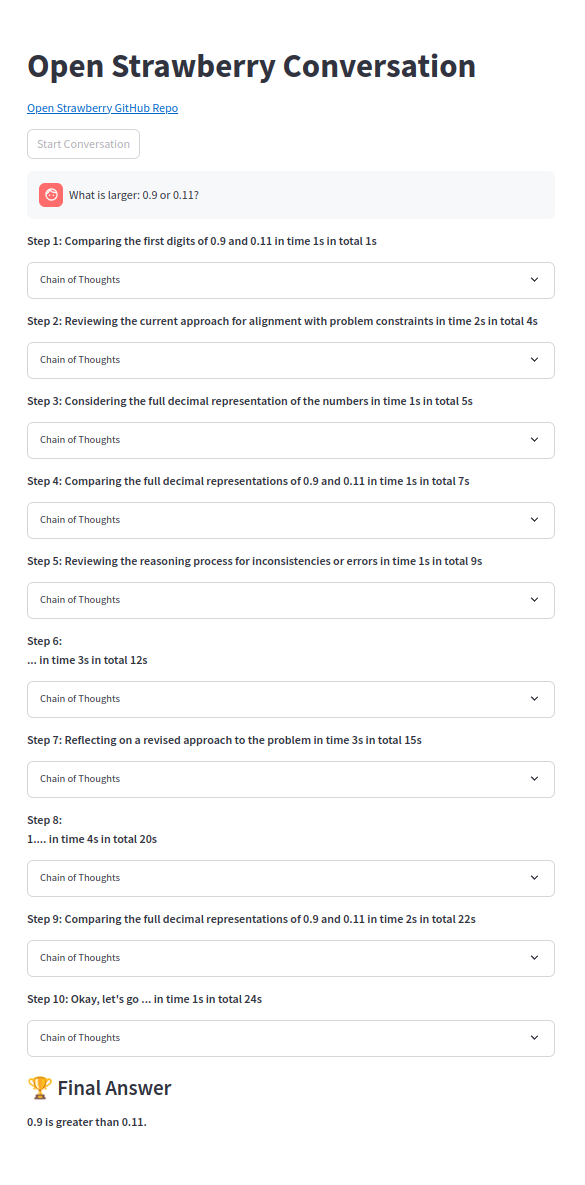
Uma das cadeias de pensamento:
Instalação
Python> = 3.10 deve estar bem, então:
pip install -r requirements.txt
Uso
Preencha .env com as chaves da API necessárias etc ou defina Envs, por exemplo:
# OpenAI# Can be OpenAI key or vLLM or other OpenAI proxies:OPENAI_API_KEY=# only require below for vLLM or other OpenAI proxies:OPENAI_BASE_URL=# only require below for vLLM or other OpenAI proxies:OPENAI_MODEL_NAME=# ollamaOLLAMA_OPENAI_API_KEY=OLLAMA_OPENAI_BASE_URL=# quoted list of strings or stringOLLAMA_OPENAI_MODEL_NAME=# AzureAZURE_OPENAI_API_KEY=OPENAI_API_VERSION=AZURE_OPENAI_ENDPOINT=AZURE_OPENAI_DEPLOYMENT=# not requiredAZURE_OPENAI_MODEL_NAME=# Anthropic prompt caching very efficientANTHROPIC_API_KEY=GEMINI_API_KEY=# groq fast and long contextGROQ_API_KEY=# cerebras only 8k contextCEREBRAS_OPENAI_API_KEY=# WIP: not yet usedMISTRAL_API_KEY=HUGGING_FACE_HUB_TOKEN=REPLICATE_API_TOKEN=TOGETHERAI_API_TOKEN=
Ollama
Para Ollama, pode -se usar o serviço Openai:
# Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve &> ollama.log &
ollama run mistral:v0.3
Em seguida, escolha definir .env com OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ e por exemplo OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3 ou list of ollama: OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"]
O projeto está em seus estágios iniciais para explorar a geração de traços de raciocínio para problemas específicos como prova de conceito.
Observe que o prompt de demonstração são modelos simples e até o Sonnet3.5 e o GPT-4O não conseguem encontrar uma solução mesmo com o berço padrão. Somente o O1-mini ou o O1-PREVIED às vezes pode obter, embora os agentes de código e resolvam facilmente.
Fundo
O Aberto-Streanwberry é baseado em especulações sobre o Strawberry da Openai, um algoritmo refinado de geração de pesquisa para gerar e verificar dados de treinamento.
Este projeto tem como objetivo recriar um sistema semelhante usando ferramentas e metodologias de código aberto.
Definições especulativas
Q *: Um hipotético algoritmo de RL profundo de geração de pesquisa primordial desenvolvido pelo OpenAI para gerar dados de treinamento.
Strawberry : Um algoritmo RL profundo de geração de pesquisa avançada pelo OpenAI para gerar e verificar dados de treinamento.
O1 : GPT-4O e GPT-4O-MINI, mas ajustados nos dados de morango, incluindo O1-mini, O1-Preview, O1 e O1-IOI. [1]
Orion : modelo baseado em GPT-5 que incorpora os dados sintéticos do Strawberry e gerencia melhor as consultas de raciocínio de 0-shot vs. Long.
Gerando raciocínio traços
O bootstrapping é fundamental via aprendizado progressivo.
Bootstrap, a partir dos modelos existentes, ajustados e ajustados de instruções e de instruções existentes usando o histórico de bate-papo com várias turnos.
Implemente um sistema rápido que orienta o LLM a tomar etapas incrementais em direção a uma solução.
Puxações de COT úteis randomizadas do usuário (por exemplo, não é o próximo, mas "você tem certeza?" "Algum erro?" "Como você verificaria sua resposta?") Para ilícito raciocínio e introspecção ilícitos.
Enfatize o LLM para fazer o passo mais minúsculo em direção à solução, por exemplo, mesmo uma única frase ou frase é preferida. Somente quando a resposta final seria produzida, uma resposta completa estendida for dada.
Gerar traços de raciocínio de bate-papo com várias turnos
Às vezes pergunte se o modelo está confiante em uma resposta. Nesse caso, peça para colocar essa resposta em tags <final_answer> xml. Se for feito, encerre a geração de rastreamento de raciocínio.
Empregue um sistema de verificação para verificar se há erros no histórico de bate -papo.
Gerar vários traços de raciocínio por problema.
Aplique esse processo a um grande conjunto de problemas com verdades verificáveis.
Identifique problemas que o modelo de instrução existente pode fazer apenas com berço forte e alta temperatura para algumas repetições de número fixo (por exemplo, 20).
Tuneamento fino em traços de raciocínio
Selecione traços de raciocínio corretos e incorretos para cada problema com base na verdade do solo.
Tune um modelo usando os rastreamentos de raciocínio selecionados usando DPO ou NLHF, onde a preferência é positiva para traços corretos, negativos para traços incorretos.
Distorce o peso da preferência por número de etapas tomadas, ou seja, se incorretas, então traços negativos mais longos devem obter uma recompensa negativa maior. Rastreios corretos mais curtos devem obter uma recompensa mais positiva.
Tune o modelo nesses raciocínio traços com a mistura de outros dados, como de costume.
Use este modelo para gerar traços de raciocínio para problemas um pouco mais difíceis que esse novo modelo mal pode fazer.
Repita a geração de traços de raciocínio e ajuste fino até que o modelo possa causar problemas mais difíceis, de modo que o escopo do raciocínio traça como consumido mais tipos de problemas (mas nem todos os tipos, pois nem sempre é necessário).
Especulações
MCTS, TOT, agentes, etc. Não são necessários no tempo de treinamento ou inferência.
A rotulagem humana ou a verificação humana de traços de raciocínio não são necessários.
Os modelos de verificação ajustados para verificação não são necessários, qualquer que seja a etapa.
O RLHF não é estritamente necessário, apenas DPO.
O Openai está usando o Deep RL para treinar os traços de raciocínio, mas não acho que isso seja necessário. A jogada é poderosa, mas pode ser imitada pelo DPO.
O Deep RL é apenas uma maneira de gerar dados de maneira eficiente, mas não é necessária e apenas se mantém do trabalho anterior do OpenAI.
Justificativas
[P10] é um artigo recente que valida nossa proposta de uso de dados de várias turnos auto-gerados para empurrar um pouco progressivamente o modelo para a auto-corrigir.
Objetivos do projeto
Gerar traços de raciocínio usando a abordagem proposta.
Tune um modelo nos traços de raciocínio gerados.
Avalie o desempenho e compare-o com os modelos existentes com zero tiro, poucos tiro, berço, etc.
Outros projetos:
A principal diferença com a Raspberry é que eles estão focados em avisos difíceis, enquanto achamos que uma abordagem de aprendizado progressivo com repetida ajuste fino será destacado em direção ao O1.
A principal diferença com o G1 é que eles estão focados apenas no comportamento do tipo O1, sem ênfase como ajustar o O1.
API antrópica e do Google Suporte de cache imediato significa muito mais barato para executar. O VLLM suporta cache de prefixo que também ajuda isso.
Status atual
Este projeto está em seus estágios iniciais. Resultados e comparações serão adicionados à medida que estiverem disponíveis.
PENDÊNCIA:
Configure estojo antrópico básico com cache imediato
Configure o aplicativo básico de streamlit para monitorar facilmente as saídas
Procure apoio da comunidade
Cada (digamos) 9 etapas, pergunte se o modelo pensa que tem uma resposta final e, se assim for, peça que ele coloque essa resposta em tags XML para extração e rescisão do rastreamento de raciocínio.
Adicione o retorno
Adicione Ollama, Google, Azure, OpenI, Groq, APIs antrópicas com cache rápido para antropia
Adicione o resumo de alto nível de blocos de texto como O1
Melhore o prompt do sistema, varie -o também ou separadamente dos próximos avisos do usuário
Adicione o verificador que amostras da janela da história e critica separadamente a saída do assistente
Use os conjuntos de dados existentes com a verdade do solo para identificar problemas para os quais o COT alcança o sucesso após alguns ensaios
Colheita de avisos amigáveis ao berço e colete traços de raciocínio positivo e negativo
Ajuste com DPO, incluindo a mistura de dados normais, bem com distribuição semelhante
Repita na próxima rodada de avisos que amigam o berço, excluindo os avisos originais, assim como o Bootstrap
Tune em cima do tune fine
Repita no geral até o bootstrap-repetir o caminho para um modelo mais inteligente
Problemas mais difíceis ainda estão fora de alcance, que a previsão O1 recebe apenas cerca de 50% do tempo (os agentes do código recebem 90% do tempo):
Problemas fáceis são resolvidos de maneira confiável:
Contribuindo
Congratulamo -nos com contribuições da comunidade. Consulte nosso arquivo contribuinte.md para obter diretrizes sobre como participar.
Problemas:
Continue o botão no aplicativo deixa bate-papos antigos acinzentados, melhor se iniciado de maneira limpa
Contagem de tokens só aparece após o golpe, continue, melhor se fosse a cada turno
Sobre o autor
Jonathan McKinney é o diretor de pesquisa da H2O.AI com formação em astrofísica e aprendizado de máquina. Sua experiência inclui:
Ex -professor de astrofísica da UMD [B1] [B2] [B3] [B4]
7 anos de experiência com produtos Automl em H2O.ai [B5] [B6]
Trabalhos recentes sobre agentes de Tuneing LLMS, RAG e AI (H2OGPT) [B7] [B8]
Veja meus outros projetos como H2OGPT e engenharia rápida
Isenção de responsabilidade
Este projeto é especulativo e baseado em informações publicamente disponíveis sobre o trabalho da OpenAI. Não é afiliado ou endossado pelo Openai.
[P0] Cadeia de pensamento provocando o raciocínio em grandes modelos de idiomas: https://arxiv.org/abs/2201.11903
[P1] Estrela: Raciocínio de Bootstrapping com Raciocínio: https://arxiv.org/abs/2203.14465
[P2] Vamos verificar passo a passo: https://arxiv.org/abs/2305.20050
[P3] Quiet-Star: Modelos de idiomas podem se ensinar a pensar antes de falar: https://arxiv.org/abs/2403.09629
[P4] Pense antes de falar: modelos de idiomas de treinamento com tokens de pausa: https://arxiv.org/abs/2310.022226
[P5] Nash Aprendendo com o feedback humano: https://arxiv.org/abs/2312.00886
[P6] A computação de tempo de teste Scaling LLM de maneira ideal pode ser mais eficaz do que os parâmetros do modelo de escala https://arxiv.org/abs/2408.03314
[P7] Aprimorando a solução de problemas do LLM com a REAP: reflexão, desconstrução explícita do problema e promoção avançada https://arxiv.org/abs/2409.09415
[P8] Agente Q: Raciocínio e aprendizado avançados para agentes de IA autônomos https://arxiv.org/abs//2408.07199
[P9] Leis de escala de escala com jogos de tabuleiro https://arxiv.org/abs/2104.03113
[P10] Modelos de linguagem de treinamento para se autocorreção por meio de aprendizado de reforço https://arxiv.org/abs/2409.12917
Projetos relacionados:
[Equipe Openo1] Open Source O1
[Gair-NLP] Jornada de replicação O1: um relatório de progresso estratégico
[Maitrix.org] LLM Razoners
[BKLIEGER-GROQ] G1: Usando LLAMA-3.1 70B no GROQ para criar cadeias de raciocínio do tipo O1
[O1-Chain-of-Thought] Transcrição de raciocínio de O1 Rastreio da postagem do blog Openai
[Toyberry] Toyberry: uma minúscula implementação de ponta a ponta do sistema de raciocínio de OpenAi O1 usando MCTS e LLM como back -end
Mas o IMHO, o LLM vê um token diferente do que <thinking> e agora é <reasoning> .
Recurso:
[Awome-llm-Strawberry] Awome-llm-Strawberry
Vídeos relacionados:
https://www.youtube.com/watch?v=tpun1uokecc (prompts em cascata com berço repetido)
https://youtu.be/ey9ihse82hc?t=2742 (Noam Brown no auto-jogo com LLMS)
https://youtu.be/nvaxucibb-c?list=pldrirStud7wwjxhoi9VVXEO9KTUFBXLHF (Por que Vlad Tenev e Tudor Achim do Harmonic pensam que a IA está prestes a mudar de matemática-e por que importa)
https://youtu.be/jplusxjpdra?si=ysPKFX57T7T7EYEL5O (Noam Brown, Ilge Akkaya e Hunter Lightman, do Openai, na O1 e no ensino, para raciocinar melhor)